


II. Chapitre 2 - Définition des données : types, domaines, valeurs et NULL▲
Toute base de données repose sur un formalisme de données très important. Parce qu'elle est censée stocker des données, une base de données doit posséder un typage fort qui permet de définir au mieux la façon dont les valeurs vont être placées dans les objets de la base.
Nous allons voir les types et les domaines ainsi que la spécification de valeurs (c'est à dire comment on « assigne » une valeur à un objet typé). Nous montrerons aussi le typage et le marqueur NULL qui indique l'absence de valeur. Nous donnerons un aperçu des apports de la norme SQL:1999 en matière de définition des données, qui s'est tournée vers le relationnel objet, mais pêne à s'implanter dans les SGBDR.
On utilise les définitions de données dans la plupart des objets SQL : les tables SQL et les vues sont constituées en majeure partie d'une collection de colonnes ayant chacune un type de données. Dans une requête on peut spécifier une valeur et la typer à l’aide de la fonction CAST à des fins de comparaison. Enfin, l'assignation est réservée aux requêtes d'insertion et de mise à jour.
II-1. Types SQL▲
Les types SQL sont regroupés dans quatre grandes familles : chaînes de caractères, nombres, temporels et binaires. Ces grandes familles faisant l’objet de plusieurs sous-familles…
|
Chaines de caractères |
Nombres |
Temporels |
Binaires |
||
|
ASCII fixe : |
ASCII variable : |
Exacts : |
Entiers : |
Datation : |
Booléen : |
|
UNICODE fixe : |
UNICODE variable : |
DCB : |
Chaine fixe : |
||
|
Approchés : |
REAL
|
Durée : |
Chaine variable : |
||
|
Tableau 2.1 - Présentation des types SQL les plus courants exceptés les LOBs (Large OBjects). |
|||||
II-1-1. Types chaîne de caractères▲
SQL permet de codifier les chaînes de caractères dans des formats où chaque caractère s'exprime sur une base de 1 octet (ASCII, EBCDIC) ou bien 2 octets (UNICODE).
II-1-1-1. ASCII▲
L’ASCII est un format d'encodage de caractères sur 8 bits, soit 1 octet. Il permet donc 256 combinaisons de signes. Les codes de 0 à 127 représentent toujours les mêmes signes dans lesquels on trouve les lettres de « a » à « z » aussi bien en minuscule qu'en majuscule, les chiffres de « 0 » à « 9 », divers signes typographiques et de ponctuation et des signaux destinés à piloter les imprimantes (retour chariot, tabulation...). Étant donné que certaines langues admettent des caractères diacritiques (accents, cédille, tilde, ligature...) et que la plage de codes allant de 128 à 255 ne permettait pas de les représenter tous, il a fallu inventer un stratagème pour obtenir une telle représentation. C'est la fameuse « page de code », qui permet de charger un panel de signes différents dans les codes 128 à 255, panel spécifique à la langue de l'utilisateur. Ces pages de codes ont fait l'objet d'une standardisation, on y trouve les versions les plus courantes numérotées 437 (américain, graphique) ou 850 (multilingue Européen)... ASCII est un standard des éditeurs de matériel typographique américains qui a été établi à l'origine pour les télétypes. Ce standard a fait l'objet d'une norme ANSI (American National Standard Institute) largement reprise en informatique dans le monde entier.
II-1-1-2. EBCDIC▲
EBCDIC est un codage semblable à ASCII, mais propre à la société IBM. EBCDIC n'est maintenant gardé que pour la compatibilité descendante, afin que les fichiers informatiques des ordinateurs des années 60 à 90, produit sur des machines IBM, puissent encore être lus. Ce format d’encodage, décliné en six variantes et d’autres sous variantes, était censé être optimal pour la saisie des cartes perforées… En fait, il s’agissait d’un coup marketing et pour IBM de ferrer le client afin que sa migration vers d’autres systèmes soit plus difficile !
II-1-1-3. UNICODE▲
L’UNICODE (norme ISO 10646) est une évolution importante de la problématique de communication et d'échange mondial. En effet, pour l'ASCII, du fait de l'emploi d'une page de code spécifique, la communication de documents électroniques entre utilisateurs ayant des pages de code différentes provoquait l'apparition de caractères étranges et souvent incompréhensibles dans les fichiers. Il fut alors décidé d'étudier un nouveau format d'encodage des chaînes de caractères permettant de codifier l'ensemble des alphabets les plus représentatifs de la planète et de toutes leurs spécificités. La dernière version, UNICODE 15.0, a été publiée en septembre 2022 et comporte 149 186 caractères, couvrant plus de 150 écritures alphabétiques ou idéographiques, chaque caractère est codé sur 4, cinq ou 6 octets. On y trouve entre autres, les alphabets latin, grec, cyrillique, hébreu, arabe, thaï, ainsi que les idéogrammes unifiés chinois, japonais et coréens. Bien que l’UNICODE définisse les codes des différents caractères, cette norme n’est pas utilisée directement, mais par le biais d’encodages spécifiques tels que l’UTF-8, l’UTF-16 (Unicode Transformation Format) ou l’UCS.
|
Type |
Chaine de caractères |
|---|---|
|
CHARACTER [ (n) ] |
taille fixe de longueur n, dont les caractères sont codés sur 1 octets (ASCII, EBCDIC), |
|
CHARACTER VARYING [ (n) ] |
taille variable de longueur maximale n, dont les caractères sont codés sur 1octets (ASCII, EBCDIC) |
|
NATIONAL CHARACTER [ (n) ] |
taille fixe de longueur n, dont les caractères sont codés sur 2 octets (UNICODE) |
|
NATIONAL CHARACTER VARYING [ (n) ] |
taille variable de longueur maximale n, dont les caractères sont codés sur 2 octets (UNICODE) |
|
CHARACTER LARGE OBJECT (n [u]) |
taille variable limitée dont les caractères sont codés sur 1 octets (ASCII ou EBCDIC), fait partie des « LOBs » |
|
NATIONAL CHARACTER LARGE OBJECT [(n [u])] |
taille variable limitée dont les caractères sont codés sur 2 octets (UNICODE), fait partie des « LOBs » |
|
n est un numérique entier spécifiant la taille |
|
|
Tableau 2.2 – Types chaines de caractères |
|
Les chaines de taille fixe sont complétées à blanc, dans le sens de l’écriture (qui varie selon la langue) lorsque la donnée saisie est d’une taille inférieure à la taille du type. Par exemple, la chaine de caractères « SQL » inscrite dans un CHAR(6) sera complétée par 3 caractères « blanc » à droite.
|
|
NOTE |

II-1-1-4. UTF-8▲
L’UTF-8 est un encodage dont les caractères ont des tailles différentes selon le type de caractères et variant de 1 à 4 octets. Ainsi, les signes de base, les nombres et les lettres simples sont encodés sur un octet dont le bit de poids fort vaut 0, ce qui permet 128 caractères strictement équivalents aux 128 premiers caractères de l’ASCII (lettres de A à Z en majuscules et minuscules, nombres, signes de ponctuation, espace, caractères non imprimables…). Les principaux signes diacritiques et alphabets proches du latin (grec, cyrillique…) sont codés sur 2 octets dont les 2 bits de poids fort sont à 1 ce qui permet 16 256 caractères. Les principaux idéogrammes sont encodés sur 3 octets dont les 3 bits de poids fort valent 1, ce qui permet de représenter 2 080 768 symboles. Enfin des symboles exotiques (note de musique, émoticon…) sont représentés sur 4 octets, avec 4 bits de poids fort à 1, ce qui laisse 266 338 304 combinaisons possibles.
Si cet encodage est censé présenter un avantage pour Internet, il favorise essentiellement l’anglais et complexifie de nombreux algorithmes comme le tri ou la comparaison. La difficulté étant de traiter des chaines de caractères dont les différents caractères n’ont pas la même longueur. Cela s’en ressent sur les performances de certaines opérations dans le cadre des SGBDR…
II-1-1-5. UTF-16▲
L’UTF-16 est un encodage dont les caractères ont des tailles différentes selon le type de caractères et utilise 2 ou 4 octets. Sur deux octets 1024 caractères sont disponibles et correspondent aux 128 premiers caractères de l’ASCII ainsi qu’aux caractères diacritiques et alphabets cyrillique et grec. Sur 4 octets sont encodés la plupart des autres alphabets comptant jusqu’à 1 048 576 symboles.
II-1-1-6. UCS-2▲
L’UCS-2 est un encodage qui utilise 2 octets pour tout caractère et représente les 32 768 premiers caractères de l’UTF-16.
Quel que soit l’encodage UNICODE (UTF ou UCS) tous les codes ne sont pas utilisés par des symboles, certains étant réservés, et d’autres sont des codes de contrôle comme les fameux BiDi (Bi Directionnels) permettant d’indiquer si les caractères se lisent de gauche à droite ou l’inverse et donc opérer un changement de direction de la lecture des caractères de la chaine en fonction de l’alphabet qui y est présent.
|
|
ATTENTION |

Dans un but de simplification, SQL admet des synonymes aux noms des types de chaînes de caractères
|
Type |
Synonymes |
|---|---|
|
CHARACTER |
CHAR |
|
CHARACTER VARYING |
VARCHAR |
|
NATIONAL CHARACTER |
NCHAR, NATIONAL CHAR |
|
NATIONAL CHARACTER VARYING |
NVARCHAR, NATIONAL VARCHAR |
|
CHARACTER LARGE OBJECT |
CLOB |
|
NATIONAL CHARACTER LARGE OBJECT |
NCLOB |
|
Tableau 2.3 – Synonymes pour les types de chaines de caractères |
|
|
|
NOTE
|
Exemples 2.1 – Types littéraux :
NCHAR (200) => Chaîne de 200 caractères UNICODE
CHARACTER VARYING => Chaîne de caractères ASCII ou EBCDIC d'au plus 32 caractères
NCLOB (2M) => Chaîne de caractères UNICODE de taille maximale limitée à 2 Méga octets
CHARACTER LARGE OBJECT (32765) => Chaîne de caractères ASCII ou EBCDIC d'au plus 32765 caractères|
|
CONSEIL |

|
|
ATTENTION |
Dans le cas d’omission de la taille du littéral et à titre d’exemple, l’expression d’un type CHAR sans spécification de taille vaut 1 caractère ASCII pour Microsoft SQL Server, Oracle Database comme pour PostGreSQL.
II-1-2. Types temporels▲
Les types temporels comprennent la datation, la mesure du temps, l'horodatation et la durée (intervalle de temps).
Types temporels SQL
|
Type |
Description |
|
|---|---|---|
|
DATE |
Date allant de 1/1/1 à 31/12/9999 |
|
|
TIME [(s)] |
Heure allant de 00:00:00 à 23:59:61.9999999… |
|
|
TIMESTAMP [(s)] |
Combiné date + heure |
|
|
TIME WITH TIME ZONE [(s)] |
Heure avec encapsulation du fuseau horaire spécifié en décalage relatif par rapport au temps universel sous la forme : { + | – } HH:MM |
|
|
TIMESTAMP WITH TIME ZONE [(s)] |
Combiné date + heure avec encapsulation du fuseau horaire |
|
|
INTERVAL |
Intervalle de temps (durée), spécifiable parmi : |
|
|
s est la précision en nombre de chiffres après la virgule pour les tantièmes de seconde et cette précision diffère selon les différents SGBDR
|
||
|
|
NOTE – La seconde intercalaire |
|
|
ATTENTION – La seconde intercalaire |
|
|
NOTE – Le type INTERVAL |
|
|
ATTENTION – Limites des dates |
|
|
ATTENTION – Ne pas utiliser le type « epoch » |
|
|
|
Figure 2.1 – Fuseaux horaires dans la région indo-iranienne (extrait de Wikipedia) |
|
|
NOTE – Fuseaux horaires |
Le calendrier grégorien
Au cours de l'Histoire et compte tenu de la précision accrue des calculs astronomiques, on constate que le calendrier julien (datant de Jules César) souffre d'un manque de précision. Celui-ci s’établissait à 365 jours plus une journée intercalaire tous les 4 ans. Néanmoins la durée de l'année julienne est trop longue d'un peu plus de 11 minutes (365,25 jours au lieu de 365,2425) et au fil du temps, le calendrier finit par retarder de plusieurs jours. C'est le pape Grégoire XIII qui entreprend de réformer le calendrier : pour cela, 10 jours furent supprimés de l'année 1582, où le 4 octobre fut immédiatement suivi par le 15 octobre. Pour éviter de nouvelles dérives, la surévaluation de l'année julienne fut corrigée par la suppression de 3 jours tous les 400 ans. On ignore donc la règle des années bissextiles les années séculaires, sauf pour celles qui sont divisibles par 400. Il y a donc 97 années bissextiles par période de 400 ans et la durée moyenne d'une année grégorienne est 365 + 97/100, c'est-à-dire 365,2425 jours.
Mais cette réforme nécessaire n'a pas été adoptée à la même date dans tous les pays :
- L'Italie, l’Espagne, le Portugal et la Pologne sont passées du 4 octobre 1582 au 15 octobre 1582.
- La France (sauf l’Alsace et la Lorraine) est passée du 9 décembre 1582 au 20 décembre 1582. Entre 1793 et 1806, le calendrier républicain, né de la Révolution française, est utilisé. Il se compose de douze mois de 30 jours et de 5 à 6 jours supplémentaires.
- Le Luxembourg est passé du 14 décembre 1582 au 25 décembre 1582.
- La Belgique (alors province des Pays-Bas) est passée du 21 décembre 1582 au 1er janvier 1583.
- Le Valais Suisse est passé du 28 février 1655 au 11 mars 1655.
- L'Alsace est passée du 4 février 1682 au 16 février 1682.
- Zurich, Berne, Bâle et Genève sont passées du 31 décembre 1700 au 12 janvier 1701.
- L'Angleterre est passée du 2 septembre 1752 au 14 septembre 1752.
- La Lorraine est passée du 16 février 1760 au 28 février 1760.
- L'URSS est passée du 31 janvier 1917 au 14 février 1917, mais une réforme révolutionnaire entra en vigueur de 1930 à 1932 avec un calendrier dans lequel chaque mois avait trente jours. Les cinq ou six jours en excès étaient des congés (à la manière du calendrier de la Révolution française).
Exemples 2.2 – types temporels :
DATE --> dates
TIME WITH TIME ZONE + 02:00 --> heure avec décalage de 2h
--> par rapport au fuseau horaire d'origine
--> (Premier méridien, dit « Greenwich »)
INTERVAL YEAR (4) TO MONTH --> intervalle an/mois pouvant aller de zéro an
--> et zéro mois à 999 ans et 11 mois
INTERVAL SECOND (2,3) --> intervalle permettant d'exprimer des secondes
--> allant de 0 à 62 secondes et 999 millièmes
TIME (2) --> Valeur de temps allant de 00:00 à 23:59:59.99II-1-3. Types numériques▲
Les types numériques comprennent des types exacts et des types approchés. Parmi les types exacts, on distingue deux sous-familles : les types entiers et les types réels à représentation décimale exacte (DCB : Décimal Codé Binaire). Les types approchés sont constitués par des types réels à représentation binaire. Ils ne sont pas exacts par rapport à la numération décimale du fait que la représentation de nombres fractionnaires dans un système de calcul binaire tombe rarement juste en décimal.
II-1-3-1. Types entiers (exacts)▲
Les entiers sont des valeurs numériques discrètes signées.
|
Type SQL |
Plage de valeurs |
|---|---|
|
INTEGER (ou INT synonyme) |
entier 32 bits signé [ -231 à 231-1 ] |
|
SMALLINT |
entier 16 bits signé [ -215 à 215-1 ] |
|
BIGINT |
entier 64 bits signé [ -263 à 263-1 ] |
|
Tableau 2.5 – Types numériques entiers |
|
II-1-3-2. Types réels▲
Ils se subdivisent en deux catégories : les types flottants, qui sont des approximations de réels décimaux codés en binaire et les décimaux, qui sont une représentation exacte de réels exprimés en base 10.
II-1-3-2-1. Types flottants (approchés)▲
Les types réels flottants sont encodés en binaires et sont donc des valeurs approchées de la spécification décimale. En effet, il n'est pas possible de représenter dans une machine calculant en binaire les valeurs exactes de la plupart des chiffres décimaux à virgule. Par exemple, le chiffre décimal 3,875 (soit 8/31) ne peut être représenté par une composition finie de puissances inverses de 2. En effet, 3,875 se décompose en une série infinie de puissances inverses de 2 :
|
|
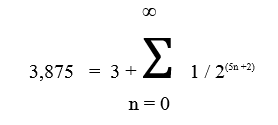
Pour l'ordinateur, machine finie donc limitée au calcul binaire, cette approximation successive basée sur les puissances inverses de deux ne permettra pas de représenter la valeur exacte de l'occurrence. Elle sera donc stockée sous forme binaire induisant un arrondi possible. Lorsque la valeur sera restituée, il se peut qu'il y ait une erreur d'écart d'arrondi due à la reconversion en base dix.
|
Type réel flottant SQL |
Description |
|---|---|
|
FLOAT [(n)] |
réel signé dont la mantisse n peut être précisée en incluant le bit de signe. |
|
REAL |
réel signé |
|
DOUBLE PRECISION |
réel signé dont les valeurs sont supérieures au REAL |
|
Valeurs maximale et minimale spécifiques au SGBDR |
|
|
Tableau 2.6 - Types réels flottants approchés |
|
II-1-3-2-2. Types décimaux (exacts)▲
Ce sont des réels dont l'encodage décimal restitue l'exacte valeur.
|
Types réels décimaux SQL |
Description |
|---|---|
|
NUMERIC [ (p [, s] ) ] |
réel signé représentant exactement un nombre décimal. |
|
DECIMAL [ (p [, s] ) ] |
idem au NUMERIC, dont les valeurs sont supérieures au NUMERIC |
|
p étant la précision (nombre de chiffres significatifs incluant les chiffres après la virgule) |
|
|
Tableau 2.7 - Types réels décimaux exacts |
|
De manière interne, la représentation du NUMERIC ou du DECIMAL est constituée par deux entiers. Le premier représente le nombre dépourvu de décimale, le second contient la valeur de l’échelle, c’est-à-dire le nombre de chiffres significatifs après la virgule. Par exemple pour un nombre tel que 123.45 codé en DECIMAL(8,4), la représentation interne sera : 1234500(4).
|
|
NOTE
|
Exemples 2.3 – types numériques :
INT un entier allant de -231 à 231-1
DECIMAL (1) un réel représentant exactement un nombre décimal pouvant aller de -9 à +9
DECIMAL un réel représentant exactement un nombre décimal pouvant aller de -9 à +9II-1-4. Types binaires▲
Les types binaires ne sont autres que des chaînes de bits. Comme pour les littéraux, on distingue les chaînes de taille fixe et celles de taille variable.
|
Type |
Description |
|---|---|
|
BIT [(n)] |
Une chaîne de bits de taille fixe de longueur n bits |
|
BIT VARYING [(n)] |
Une chaîne de bits de taille variable limitée au maximum à n bits |
|
BOOLEAN |
Booléen égal à un bit et valant 0 ou 1 |
|
BINARY LARGE OBJECT [(l [u])] |
Une chaîne binaire de grande taille limitée à l octets. |
|
UNIQUIDENTIFIER / |
Binaire de 16 octets dont les valeurs sont aléatoires |
|
n étant le nombre de bits |
|
|
Tableau 2.9 – types binaires |
|
|
|
NOTE
|
|
|
ATTENTION |
II-1-5. Les types « larges » (LOB)▲
Outre les types CHARACTER LARGE OBJECT (ou CLOB), NATIONAL CHARACTER LARGE OBJECT (ou NCLOB) et BINARY LARGE OBJECT (ou BLOB), SQL dispose de nombreux types « larges », pour stocker des objets de grandes dimensions, comme :
- XML pour le stockage de fragments XML valides ;
- JSON pour le stockage de données JSON ;
- GEOMETRY pour le stockage des données géométriques d’un SIG ;
- GEOGRAPHY pour le stockage des données géographiques d’un SIG.
La limite de longueur de ces types est spécifique aux éditeurs.
II-2. Problématique d'expression des littéraux▲
L'expression des valeurs typées répond à quelques règles simples dans la majeure partie des cas. Mais pour la chaîne de caractères, SQL introduit quelques spécificités qui donnent une grande souplesse de traitement. Cette faculté de souplesse est donnée par les mécanismes SQL de jeu de caractères et de collations, afin de faire correspondre les données littérales à l'usage que l'on en fait en non à la logique de la machine.
II-2-1. Encodage et classement▲
Si nous supposons maîtriser l'alphabet et son ordre dit alphabétique, qu'en est-il de l'ordinateur et de son jeu de caractères sous-jacent ?
La table de correspondance des codes de caractères du jeu 850 (multilingue Européen) est la suivante :
|
|
|
Figure 2.2 : table de caractères du jeu ASCII 850 (OEM Latin 1) – Source Wikipedia |
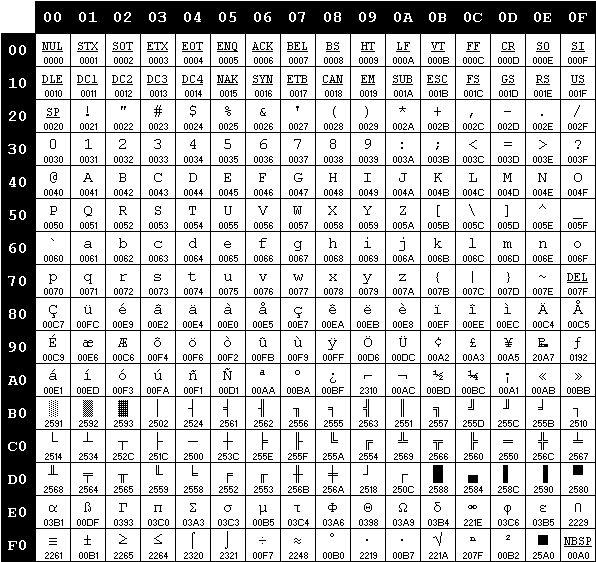
À chaque signe typographique est associé un code numérique. Pour autant, ce code ne permet pas le classement des lettres parce qu'il ne respecte pas un ordre alphabétique que nous estimerions naturel... Prenons quelques mots : béton, Mâcon, maçon, BÊTES, bedon, masse, BUTIN, MATOU et analysons leur ordonnancement en fonction du code de caractères :
|
Mot |
Code décimal |
Rang calculé |
|---|---|---|
|
béton |
098 130 116 111 110 |
6 |
|
Mâcon |
077 131 099 111 110 |
4 |
|
maçon |
109 097 135 111 110 |
8 |
|
BÊTES |
066 210 084 069 083 |
2 |
|
bedon |
098 101 100 111 110 |
5 |
|
masse |
109 097 115 115 101 |
7 |
|
BUTIN |
066 085 084 073 078 |
1 |
|
MATOU |
077 065 084 079 085 |
3 |
Si nous acceptions l'ordre induit par ce code, alors nous classerions ces mots comme suit : BUTIN, BÊTES, MATOU, Mâcon, bedon, béton, masse, maçon. C'est un ordre logique pour la machine et insensé pour notre esprit.
C'est pourquoi les éditeurs de systèmes d'exploitation ont ajouté à leur programme des bibliothèques de classement spécifiques à une ou plusieurs langues en correspondance avec les jeux de caractères sous-jacents. Dans l'ordre alphabétique dit « latin », nos mots sont donc classés de la façon suivante : bedaine, BÊTE, béton, BUTIN, Mâcon, maçons, massons, MATONS, ce qui ressemble plus à ce que nous attendions intuitivement. Le seul inconvénient des classements proposés par les éditeurs d'OS est qu'ils sont souvent spécifiques et parfois interprétés tant les combinaisons sont grandes et les normes imprécises. De manière à proposer un mécanisme de classement inter plateformes, SQL a imposé l'ajout la notion de collation.
II-2-2. Collations▲
Une collation est une énumération de signes typographiques et leurs équivalences afin d’en déduire le comportement des traitements des chaînes de caractères notamment dans les opérations de comparaison et de tri spécifiques à une langue.
Une collation SQL permet de définir la position ordinale des caractères de base et des caractères particuliers que sont :
- les caractères diacritiques : accents, cédille, tilde...
- les ligatures: æ ç, œ, ß...
Mais le mécanisme de collation offre quelques attraits supplémentaires, comme la possibilité de définir :
- l'équivalence ou non entre majuscules et minuscules ('a' <=> 'A') autrement dit, la sensibilité à la casse ;
- l'équivalence ou non entre caractères diacritiques et caractères simples ('à' <=> 'a') autrement dit, la sensibilité aux accents et autres caractères diacritiques ;
- l'équivalence ou non de la largeur du caractère ('2' <=> '²') autrement dit la sensibilité à la largeur du caractère ;
- l’équivalence entre les formes Katakana et Hiragana des caractères du japonais () autrement dit la sensibilité aux kanatypes (équivalente aux écritures cursives et d’imprimerie – lettres capitales – de notre langue).
En fonction de la collation, les expressions suivantes donneront des résultats différents :
|
comportement |
expression |
sensibilité |
insensibilité |
|---|---|---|---|
|
Casse |
'a' = 'A' |
CS |
CI |
|
Diacritiques |
'a' = 'à' |
AS |
AI |
|
Largeur |
'2' = '²' |
WS |
|
|
Kanatypes |
'か' = 'カ' |
KS |
|
|
Le symbole japonais utilisé dans notre exemple est le « KA » |
|||
|
Tableau 2.10 – paramètres du comportement des chaines de caractères |
|||
En outre, la collation définit la langue dans laquelle le tri des lettres doit s’effectuer. Si cet ordre parait trivial pour les lettres de A à Z que présente notre alphabet français, qu’en est-il si l’on distingue les majuscules des minuscules ?
- Quelle est la place des caractères accentués face aux caractères basiques ?
- Quel est l’ordre des différents accents ?
Les règles diffèrent d’une langue à l’autre. Pour le cas du français, l’ordre pour toutes les formes de la première lettre de notre alphabet est le suivant :
|
a, A, á, Á, à, À, â, Â, ä, Ä, æ, Æ |
Où l’on voit que les lettres minuscules précèdent les lettres majuscules et que l’ordre des accents est : aigu, grave, circonflexe, tréma, suivi en dernier par la ligature « æ » qui figure notamment dans les mots cæcum, ex æquo et le prénom Lætitia.
Mais la langue française complique la chose lorsque plusieurs accents figurent dans le mot et pour les mots composés…
Dans le cas d’accents multiples dans des littéraux homographes, alors le premier accent rencontré dans l’ordre de lecture classe le littéral après et le second avant… Le cas classique, présenté dans l’exemple 2.4 est celui de l’élève…
Exemple 2.4 – Classement des littéraux homographes comprenant des caractères diacritiques différents :
|
élève, élevé |
Pour les mots composés, par exemple ceux contenant un tiret, le tri ne porte que sur les lettres dont les caractères de séparation ont été expurgés…
Exemple 2.5 – Classement des littéraux avec des mots composés ou non :
|
vicelard, vice-président, vices |
Dans l’exemple 2.5, le classement des différents mots ignore le tiret et place le vice-président entre un vicelard et les vices !
Pour les ligatures, le classement est effectué comme si la ligature était décomposée en deux lettres…
Exemple 2.6 – Classement des littéraux ayant des ligatures ou non :
|
coercitif, cœur, coexistant |
Ainsi, le nom d’une collation est constitué généralement du nom de la langue suivi des paramètres indiquant le traitement de la casse, des diacritiques, de la largeur et des kanatypes, certains paramètres pouvant être ignorés.
L’exemple 2.7 montre une requête de contrôle effectuée sur le SGBDR Microsoft SQL Server.
Exemple 2.7 – Requête de contrôle :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
WITH T AS
(SELECT *
FROM (VALUES ('À'), ('A'), ('a'), ('à'),
('élève'), ('élevé'),
('vice-président'), ('vicelard'), ('vices'),
('cœur'),
('coercitif'),
('coexistant'))
AS W(m))
SELECT m AS mot
FROM T
ORDER BY m COLLATE French_CS_AS;
Dont le résultat est :
mot
--------------
a
A
à
À
coercitif
cœur
coexistant
élève
élevé
vicelard
vice-président
vicesPour exécuter la requête de l’exemple 2.7 sur différents SGBDR, changez le nom de la collation (ici French_CS_AS) par une collation disponible sur le SGBDR visé.
II-2-3. La solution SQL▲
SQL offre la possibilité de définir le jeu de caractères utilisable et, dans ce jeu de caractères, de définir la collation.
L'implémentation normative de SQL offre le choix entre les jeux de caractères suivants :
- SQL_TEXT
- SQL_CHARACTER
- GRAPHIC_IRV (aussi appelé ASCII_GRAPHIC)
- LATIN1
- ISO8BIT (aussi appelé ASCII_FULL)
- CODEPAGE_0437
- CODEPAGE_0850
- CODEPAGE_1250
- CODEPAGE_1251
- CODEPAGE_1253
- CODEPAGE_1254
- CODEPAGE_1257
- UNICODE (aussi appelé ISO10646)
Les collations prédéfinies par la norme SQL possèdent le même nom que le jeu de caractères auquel ils se réfèrent.
SQL utilise les mots clefs CHARACTER SET et COLLATE pour définir le jeu de caractères et la collation sous-jacente à un littéral. Lorsque l'on utilise un type littéral, il est possible de définir en même temps son jeu de caractères et/ou sa collation. Il y a toujours un jeu de caractères et une collation par défaut, soit au niveau du schéma (la base de données), soit au niveau du SGBDR.
Ainsi un littéral de type CHARACTER peut s'exprimer de la façon suivante :
CHARACTER (n)
| CHARACTER VARYING (n)
| NATIONAL CHARACTER (n)
| NATIONAL CHARACTER VARYING (n)
[ CHARACTER SET jeu_de_caractères ]
[ COLLATE collation ]Exemples 2.8 – définition d’un jeu de caractères et de sa collation selon la norme SQL :
CHARACTER (32) CHARACTER SET LATIN1 COLLATE LATIN1
-- Littéral codé sur trente-deux octets, de taille fixe 32 caractères,
-- basé sur jeu de caractères LATIN1 et collation LATIN1II-2-4. La solution des éditeurs▲
Les éditeurs ont généralement travaillé à l’envers de ce que la norme propose en imposant d’abord de préciser la collation et par ce choix d’imposer le jeu qui caractères pour supporter une telle collation (collations sémantiques), ou bien encore offrir des collations qui représentent des jeux de caractères précis (collations techniques). Ceci parce que tous les OS(16) ne permettent pas d’implémenter tous les jeux de caractères…
|
|
|
Figure 2.3 – liste partielle des collations disponibles dans Microsoft SQL Server 2022 |
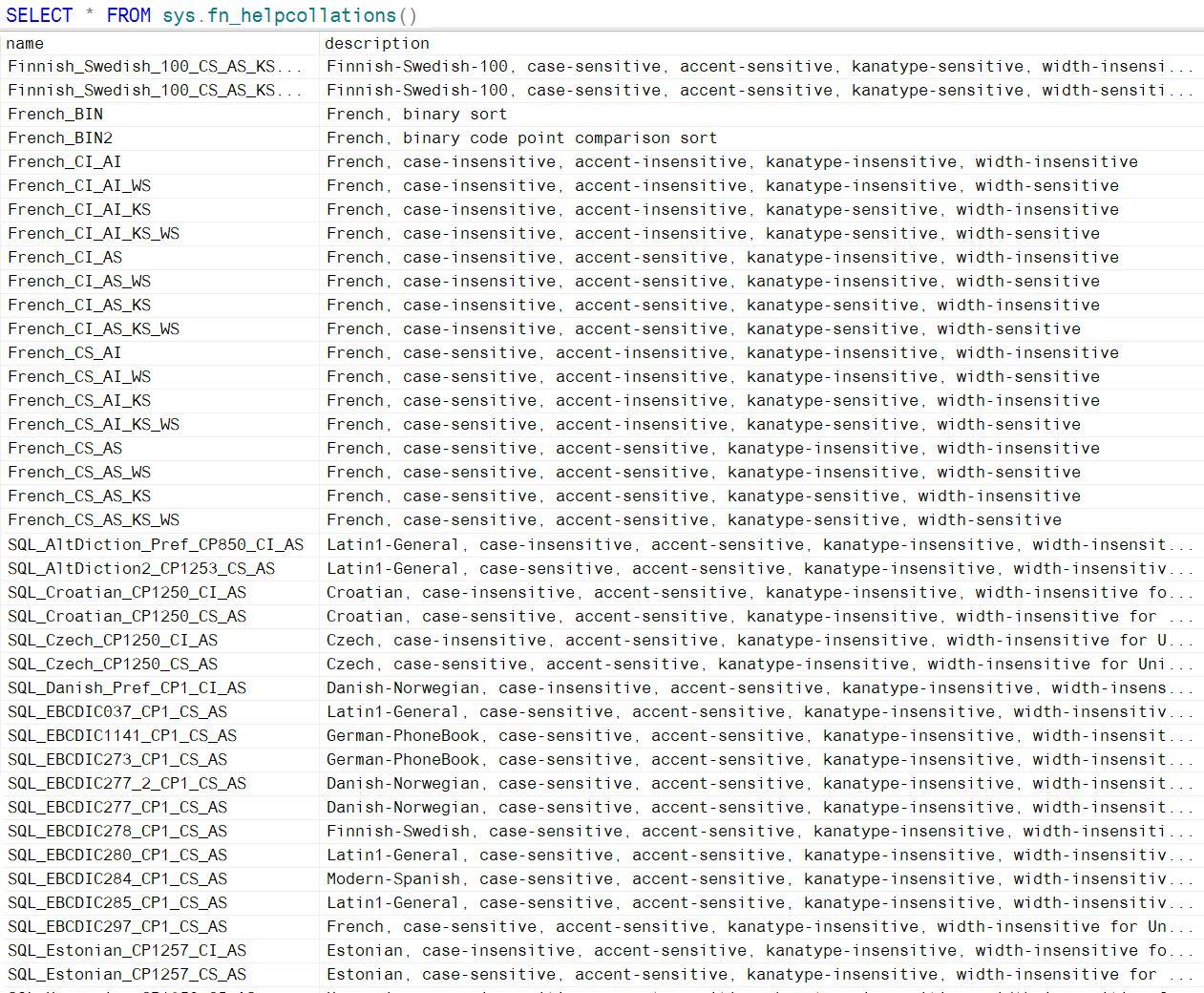
La figure 2.3 montre quelques-unes des 5 502 collations disponibles dans la version 2022 de Microsoft SQL Server. On y distingue des collations purement sémantiques dont celle consacrée aux français avec ses nombreuses dérivations et quelques collations techniques dont celles représentant le jeu de caractères EBCDIC d’IBM et ses dérivés.
En règle générale, le serveur de base de données est installé avec une collation qui deviendra celle de toutes les bases de données à défaut de précision.
Pour appliquer une collation par défaut au niveau de la base, il convient de la spécifier dans la commande de création de la base, généralement CREATE DATABASE.
La collation de chaque colonne littérale des tables est à défaut celle de la base. Sinon, il faut préciser cette collation dans la commande décrivant la création de la table, pour la colonne considérée, ou lors du rajout d’une colonne à une table existante. Cela se fait juste après mention du type ou du domaine de la colonne.
Enfin, l’opérateur COLLATE peut être appliqué à n’importe quelle expression littérale figurant à n’importe quel endroit d’une requête afin d’appliquer une collation différente à une opération, ou bien résoudre un problème de conflit de collation, lorsqu’un tel problème apparait quand est appliquée une comparaison de deux littéraux ayant des collations différentes.
II-2-5. Remarque sur la complétion des littéraux▲
Nous avons dit que les chaines de caractères de longueur fixe se voyaient compléter par le caractère "blanc" dès lors que l'information était moins longue que la longueur de la chaine. Mais ce n'est pas pour autant que les chaines de longueur variable sont dénuées de caractère de complétion. Ce dernier n'est pas ajouté automatiquement à la chaine, mais il peut être présent dans la saisie... Et cela provoque des effets de bords que nous allons voir.
Exemple 2.9 – Effet du caractère de complétion sur différentes opérations
-- Avec la table suivante :
CREATE TABLE T_STR (STR_ID INT, STR_1 VARCHAR(16), STR_2 VARCHAR(16));
INSERT INTO T_STR VALUES (1, 'chaine', 'chaine');
INSERT INTO T_STR VALUES (2, 'chaine', 'chaine ');
INSERT INTO T_STR VALUES (3, 'chaine ', 'chaine ');
INSERT INTO T_STR VALUES (4, '', '');
INSERT INTO T_STR VALUES (5, '', NULL);
INSERT INTO T_STR VALUES (6, NULL, NULL);
-- Dont le contenu est :
STR_ID STR_1 STR_2
----------- ---------------- ----------------
1 chaine chaine
2 chaine chaine
3 chaine chaine
4
5 NULL
6 NULL NULL
-- À la lecture, les paires de requêtes suivantes
-- semble donner le même résultat ; or il n'en est rien...
SELECT * FROM T_STR WHERE CHARACTER_LENGTH(STR_1) = CHARACTER_LENGTH(STR_2);
SELECT * FROM T_STR WHERE OCTET_LENGTH(STR_1) = OCTET_LENGTH(STR_2);
-- La fonction CHARACTER_LENGTH donne la longueur en nombre de caractères
-- La fonction OCTET_LENGTH donne la longueur en nombre d’octets
STR_ID STR_1 STR_2
----------- ---------------- ----------------
1 chaine chaine
2 chaine chaine
3 chaine chaine
4
STR_ID STR_1 STR_2
----------- ---------------- ----------------
1 chaine chaine
3 chaine chaine
4
SELECT * FROM T_STR WHERE STR_1 LIKE 'chaine_'
SELECT * FROM T_STR WHERE STR_1 = 'chaine '
-- L’opérateur LIKE recherche un motif dans une chaine :
-- le caractère « blanc souligné » indique qu’un caractère quelconque
-- doit impérativement être présent
STR_ID STR_1 STR_2
----------- ---------------- ----------------
3 chaine chaine
STR_ID STR_1 STR_2
----------- ---------------- ----------------
1 chaine chaine
2 chaine chaine
3 chaine chaine
SELECT * FROM T_STR WHERE SUBSTRING(STR_1 FROM 7 FOR 1) = ' ';
SELECT * FROM T_STR WHERE STR_1 LIKE '______ '
-- La fonction SUBSTRING renvoie une sous-chaine de la chaine de caractères,
-- commençant à (FROM) pour une longueur de (TO)
STR_ID STR_1 STR_2
----------- ---------------- ----------------
1 chaine chaine
2 chaine chaine
3 chaine chaine
4
5 NULL
STR_ID STR_1 STR_2
----------- ---------------- ----------------
3 chaine chaineAutrement dit, deux chaînes de caractères peuvent avoir la même valeur (égalités) sans pour autant être identiques !
II-3. Expression des valeurs de données▲
Nous allons maintenant voir comment une valeur doit être spécifiée pour correspondre à un type SQL.
II-3-1. Expression des littéraux▲
Un littéral s'exprime sous la forme d'une suite de caractères délimitée par une paire d'apostrophes. Si une chaîne de caractères comporte une apostrophe, il convient de la doubler.
Tout littéral est implicitement typé par défaut sous forme de VARCHAR.
Si vous désirez spécifier un encodage UNICODE, il convient de préfixer la chaîne avec la lettre N (en majuscule).
Exemple 2.10 – Expression de littéraux :
'BONJOUR'
-- Chaîne VARCHAR contenant "BONJOUR"
'AUJOURD''HUI'
-- Chaîne VARCHAR contenant "AUJOURD'HUI"
N'Mercredi 3 septembre'
-- Chaîne NVARCHAR contenant "Mercredi 3 septembre"
'Un' 'grand' 'pas' 'pour' 'l''humanité'
-- cinq chaînes de caractères VARCHARII-3-2. Expression des nombres▲
Les nombres s'expriment sans espaces, le point servant de séparateur décimal. Les puissances de dix nécessitent l'usage du symbole E. Les signes + et - sont utilisables.
Exemple 2.11 – Expression des nombres :
123 entier 123
1E2 entier 10
1.0 réel 1,0
1.0E7 réel 10000000,0
-2.78E-3 réel -0,00278Plus récemment, la norme SQL:2023 introduit la possibilité d’utiliser comme séparateur entre les caractères numériques le blanc souligné (underscore) à tout endroit entre deux chiffres. Ainsi un nombre exprimé comme suit : 123_45_6.25_1 est valide.
II-3-3. Expression des chaînes binaires▲
Les chaînes binaires sont délimitées par des apostrophes et se composent soit d'une suite de zéro préfixée B, soit d'une suite de symboles hexadécimaux préfixée X. Toute chaîne binaire est implicitement typée sous forme de VARBINARY.
Exemple 2.12 – Expression des chaines binaires :
X'FF3A00' -- valeur hexadécimale du binaire du chiffre décimal16726528
B'111111110011101000000000' -- valeur binaire du chiffre décimal16726528Plus récemment, la norme SQL:2023 a défini trois nouvelles expressions pour les chaines binaires, composées d’un préfixe de deux caractères (le premier étant toujours le zéro) suivi de la chaine exprimée par des symboles (liste de caractères autorisés) limités au type que le préfixe indique :
|
préfixe |
type |
symboles |
|---|---|---|
|
0x |
héxadécimal |
0 à 9 puis A, B, C, D, E, F |
|
0o |
octal |
0 à 7 |
|
0b |
binaire |
0 à 1 |
Ainsi que la possibilité d’utiliser le caractère blanc souligné (underscore) comme séparateur entre les chiffres comme cité au §2.3.2 en complément avec les préfixes 0x, 0o et 0b. Par exemple, la chaine numérique binaire 0x123_ABF est un binaire valide.
II-3-4. Expression des données temporelles▲
SQL fixe comme principe que les dates et heures doivent être spécifiées dans l'ordre logique de la plus grande composante de temps à la plus petite sous la forme d’un littéral :
- une date s'exprime en commençant par l'année sur quatre chiffres (de 1 à 9999), suivie du mois sur deux chiffres (de 01 à 12) et du jour sur deux chiffres (de 01 à 31) ;
- un temps, commence par l'heure sur deux chiffres allant de 00 à 23, suivie de la minute sur deux chiffres allant de 00 à 59, de la seconde sur deux chiffres allant de 00 à 61 * et les éventuelles décimales (tantièmes de secondes) sur 1 à n positions en fonction de la précision n ;
- le séparateur des éléments de date est le tiret (« - ») et pour le temps, le deux-points (« : ») ou le point (« . ») pour les fractions de décimales ;
- le séparateur entre la partie date et la partie heure, si besoin,est l’espace ou le caractère T en majuscule. La partie heure d’un composé date + temps est toujours facultative, l’heure par défaut étant 0 ;
- le fuseau horaire est exprimé sous forme du signe + ou – suivi de l’heure sur deux chiffres (de 00 à 14), puis du séparateur deux-points et enfin des minutes sur deux chiffres (de 00 à 59).
Les formes possibles d’expression des temporels sont :
- Date seule :
'AAAA-MM-JJ'- Temps seul :
'hh:mm'
'hh:mm:ss'
'hh:mm:ss.n'
'hh:mm:ss.nn'
…- Temps seul avec fuseau horaire
'hh:mm:ss ±hh:mm'
'hh:mm:SS.n ±hh:mm'
'hh:mm:SS.nn ±hh:mm'
...- Combiné Date + Temps (horodatage) :
'AAAA-MM-JJ hh:mm'
'AAAA-MM-JJ hh:mm:ss'
'AAAA-MM-JJ hh:mm:ss.n'
'AAAA-MM-JJ hh:mm:ss.nn'
...… ou encore :
'AAAA-MM-JJThh:mm'
'AAAA-MM-JJThh:mm:ss'
'AAAA-MM-JJThh:mm:ss.n'
'AAAA-MM-JJThh:mm:ss.nn'
...- Combiné Date + Temps (horodatage) avec fuseau horaire :
'AAAA-MM-JJ hh:MM:ss ±hh:mm'
'AAAA-MM-JJ hh:mm:ss.n ±hh:mm'
'AAAA-MM-JJ hh:mm:ss.nn ±hh:mm'
...Le nombre de tantièmes de seconde possible (précision) dépend du SGBDR utilisé.
Ou :
- A représente un chiffre d’année ;
- M représente un chiffre de mois ;
- J représente un chiffre de jour ;
- h représente un chiffre d’heure ;
- m représente un chiffre de minute ;
- s représente un chiffre de seconde ;
- n représente un chiffre de tantièmes de secondes ;
- T est à prendre au sens littéral pour la séparation entre partie jour et partie heure.
Pour le type INTERVAL, les durées peuvent être exprimées en :
- années
- années et mois
- et toutes les composantes possibles entre Jours et secondes.
Le mot clef INTERVAL doit préciser la durée exprimée sous forme littérale, suivie d’un préfixe indiquant la précision, soit d’une seule composante, soit de la composante la plus grande à la plus petite, séparée avec le mot « TO » avec les mots clefs représentant les composantes (YEAR, MONTH, DAY, HOUR, MINUTE, SECOND).
Exemple 2.13 – Expression de données temporelles :
'2004-11-22' type DATE au 22 novembre 2004
'00:11:22.333' type TIME à 0h 11m 22s 333 millièmes de seconde
'2000-12-31 23:59:59.999' type TIMESTAMP pour le 31 décembre 2000 à 23h 59m 59s et 999 millièmes de seconde
'18:20:00+02:00' type TIME WITH TIMEZONE pour 18h 20m avec décalage de 2 heures sur UTC
INTERVAL '0003-04' YEAR TO MONTH type INTERVAL de durée 3 ans 4 mois
INTERVAL '-22 11:33' DAY TO MINUTE type INTERVAL de durée moins 22 jours, 11 heures et 33 minutes
INTERVAL '08' HOUR type INTERVAL de durée 8 heures
CAST('2004-11-22') AS TIMESTAMP type TIMESTAMP avec heure à 0II-3-5. Typage explicite avec la fonction CAST▲
Lorsqu’on exprime une valeur, on peut la transtyper de manière explicite en faisant appel à la fonction SQL CAST.
La syntaxe de la fonction CAST est la suivante :
CAST ( expression AS <type_sql> )
Ou expression est une expression SQL renvoyant une valeur et type_sql un type de données SQL.
Exemple 2.14 – Expression de données temporelles avec typage explicite :
CAST('2004-11-22' AS DATE) Conversion d'un littéral ASCII ou EBCDIC en date
CAST('123') AS INTEGER Conversion d'un littéral ASCII ou EBCDIC en entier
CAST('ABC' AS BINARY(3)) Conversion d'un littéral ASCII ou EBCDIC en chaîne binaire de longueur 3 octets
CAST(3.1416 AS VARCHAR(16)) Conversion d'un nombre réel en chaine de caractères de taille variables ASCII ou EBCDIC
CAST(N'ZOO' AS BINARY(6)) Conversion d'un littéral UNICODE en chaîne binaire de longueur 6 octets|
|
NOTE |
II-4. Domaines (DOMAIN) et autoincréments▲
Un domaine au sens SQL est un type SQL pouvant être doté d'une valeur par défaut prédéfinie, d'autant de contraintes dites « de domaine » qu'on le souhaite et d'éventuelles clauses CHARACTER SET et COLLATE s'il s'agit d'un type chaîne de caractères. Un domaine est alors utilisable partout dans le SQL ou l'on a besoin d'un type de données.
II-4-1. Syntaxe SQL de création d’un domaine▲
La syntaxe de création des domaines est la suivante :
CREATE DOMAIN [ nom_schema.]nom_domaine
[ AS ] <type_sql>
[ <valeur_par_defaut> ]
[ <liste_de_contraintes_de_domaine> ]
[ <collate clause> ]Avec :
<liste_de_contraintes_de_domaine> ::=
<definition_contrainte_1>
[, <definition_contrainte_2>
[, … <definition_contrainte_n> ] ]II-4-2. Syntaxe SQL de création des contraintes de domaine▲
La syntaxe des contraintes de domaine dans la liste est la suivante :
<definition_contrainte :: =
[ CONSTRAINT nom_contrainte ] CHECK ( prédicat ) [ <déférabilité> ]|
|
NOTE |
Une contrainte sert à valider la valeur de l'occurrence dans l'objet qui la reçoit et empêche toute pollution de l'objet par des données qui ne respecteraient pas le prédicat. Rappelons qu'un prédicat est une expression évaluable booléennement et qui dans ce cas doit être évaluée à Vrai.
On peut spécifier plusieurs contraintes. Dans le prédicat, le mot clef VALUE est utilisé comme référence à la valeur qu'induit le domaine. Il ne peut être utilisé que dans l'expression de validation.
Les valeurs par défaut peuvent être une expression de valeur, le marqueur NULL (absence de valeur), comme une fonction ou une expression SQL renvoyant une valeur de même type ou implicitement transtypable, mais obligatoirement déterministe. Pour empêcher l'absence de valeur dans le domaine, spécifiez une contrainte CHECK (VALUE IS NOT NULL).
Exemples 2.15 – Création de différents domaines :
Creation de différents domaines.sql
Création d'un domaine permettant la définition d'un nom de jour.
CREATE DOMAIN S_TYPE.D_JOUR_SEMAINE
AS CHAR(8)
DEFAULT 'Dimanche'
CONSTRAINT CK_D_JOUR CHECK
(VALUE COLLATE Latin_CI_AS
IN ('Lundi', 'Mardi', 'Mercredi', 'Jeudi', 'Vendredi',
'Samedi', 'Dimanche'));Création d'un domaine pour spécification d'un pourcentage par défaut à zéro
CREATE DOMAIN S_COM.D_POURCENT
AS FLOAT
DEFAULT 0
CONSTRAINT CK_D_PC CHECK (VALUE IS NOT NULL AND
VALUE BETWEEN 0 AND 100) ;Les mots clefs suivants peuvent être utilisés :
VALUE représente n’importe quelle valeur qui sera confrontée au domaine ;
IS NOT NULL signifie qu’aucune valeur ne pourra être absente ;
IN signifie que les valeurs seront comparées à une liste de valeurs autorisées figurant entre parenthèses ;
BETWEEN permet de définir une fourchette de valeurs bornes incluses.
En outre, les contraintes peuvent utiliser des fonctions. En voici quelques exemples :
Création d'un domaine pour spécifier une date de naissance
CREATE DOMAIN S_CALEND.D_DATE_NAISSANCE
AS DATE
DEFAULT CURRENT_DATE
CONSTRAINT CK_D_DN (VALUE <= CURRENT_DATE) ;Création d'un domaine à valeur obligatoire pour les noms spécifiés en majuscules
CREATE DOMAIN S_GENERIC.D_NOM
AS CHAR(16) COLLATE French_CI_AI
CONSTRAINT CK_D_NOM_LETTRES CHECK
(TRANSLATE(VALUE , 'ABCDEFGHIJKLMNOPQRSTUVWXYZ –''',
' ') = ''),
CONSTRAINT CK_D_NOM_COMMENCE CHECK
(LEFT(VALUE, 1) NOT IN (' ', '-' , '''')),
CONSTRAINT CK_D_NOM_COMMENCE CHECK
(RIGHT(VALUE, 1) NOT IN (' ', '-' , '''')),
CONSTRAINT CK_D_NOM_MAJ CHECK
(VALUE COLLATE French_CS_AI = UPPER(VALUE));|
|
NOTE |
Quel que soit le nombre de lignes visées par un ordre SQL (INSERT, UPDATE, DELETE), si une seule violation de contrainte intervient, alors tout le lot de lignes est rejeté, même si la violation de contrainte ne portait que sur une seule valeur.
Pour une syntaxe plus détaillée de la contrainte CHECK, veuillez vous reporter au chapitre suivant.
Il est possible de modifier un domaine à l'aide de l'ordre ALTER et de le supprimer à l'aide de l'ordre DROP.
L'avantage des domaines réside dans la standardisation des types : un même domaine est utilisable pour toutes les colonnes ayant une sémantique similaire (nom de client / nom d'employé par exemple). En outre, dans les SGBDR, le recours aux domaines minimise les entrées/sorties puisqu'un type et ses contraintes n'utilisent qu'un seul et même espace mémoire pour exécuter le code de validation des contraintes de domaine afférent aux différentes colonnes.
II-4-3. Les incréments ou décréments automatiques▲
Une technique assez classique pour définir automatiquement une valeur de clef consiste à utiliser un mécanisme d’incrémentation ou de décrementation automatique. Il existe pour ce faire, deux types d’objets normalisés que l’on retrouve dans la plupart des SGBDR : la propriété IDENTITY attachée à une colonne d’une table et l’objet SEQUENCE indépendant de toute table. Nous verrons ces deux mécanismes et comment les utiliser dans le chapitre 3 consacré aux commandes de création, modification et suppression des objets (tables, vues, contraintes…), c’est-à-dire dans la partie DDL (Data Definition Language) du langage SQL.
II-5. Les apports de typages de SQL:1999▲
La norme SQL:1999 a apporté les fondements du relationnel objet, c'est-à-dire l'introduction des principaux concepts objet au niveau des mécanismes relationnels. C'est ainsi que de nouveaux types de données sont apparus : tableaux, lignes, collections, références et méthodes, tous regroupés sous la forme de types abstraits incluant la notion d’héritage.
Notons cependant que ces types structurés sont contraires aux fondements des bases de données relationnelles et leur usage peut se révéler plus problématique qu'il n'apparait.
II-5-1. Les tableaux (ARRAY)▲
Le type ARRAY (tableau), n'est pas à proprement parler un type, mais un constructeur de types puisque l'on doit décrire sa structure. SQL limite le type tableau à une seule dimension, la limite pouvant être fermée ou ouverte (unbounded arrays). La première cellule du tableau est d’indice 1.
Par exemple PRS_ADRESSE CHAR(38) ARRAY [4] construit une colonne de nom PRS_ADRESSE contenant 4 cellules, numérotées de 1 à 4, chacune de 38 caractères.
Certaines opérations particulières sur les tableaux sont possibles : outre la lecture, la modification et l'écriture dans les cellules, vous pouvez concaténer des tableaux et obtenir la cardinalité d'un tableau (c'est à dire le nombre de cellules).
La concaténation de tableaux s'obtient à l'aide de la fonction CONCATENATE :
Exemple 2.16 – concaténation d’éléments à un tableau de deux façons différentes :
CONCATENATE('Monseigneur', ARRAY['Monsieur', 'Madame', 'Mademoiselle']);
CONCATENATE('Monseigneur' WITH ARRAY['Monsieur', 'Madame', 'Mademoiselle']);Rajoute en fin de tableau la cellule 4 contenant la valeur 'Monseigneur'.
La fonction CARDINALITY renseigne sur le nombre de cellules d'un tableau :
Exemple 2.17 – cardinalité d’un tableau :
CARDINALITY(ARRAY['Monsieur', 'Madame', 'Mademoiselle']);
donne : 3
L’exemple 2.18 montre comment manipuler des valeurs dans une colonne de type tableau :
Exemple 2.18* – manipulation de tableaux en SQL :
Manipulation de tableaux en SQL
CREATE TABLE T_PERSONNE_PRS
(PRS_ID INTEGER NOT NULL PRIMARY KEY,
PRS_NOM CHAR(32),
PRS_ADR CHAR(38) ARRAY[3]) ;
INSERT INTO T_PERSONNE_PRS (PRS_ID, PRS_NOM, PRS_ADR)
VALUES (1, 'DUPONT', ARRAY['1 rue de la liberté', 'bâtiment D', NULL]) ;
UPDATE T_PERSONNE_PRS
SET PRS_ADR[3] = 'BP 484' ;
SELECT PRS_ADR[1]
FROM T_PERSONNE_PRS ;Pour transformer un tableau en table à la volée, on peut utiliser indifféremment la fonction TABLE ou la fonction UNNEST. Le résultat est une table d’une seule colonne.
Exemple 2.19* – les deux façons de transformer un tableau en table :
Les deux façons de transformer un tableau en table
SELECT *
FROM TABLE(ARRAY[1, 7, 3]) AS T_TAB (COL);
COL
-----
1
7
3SELECT UNNSET(ARRAY['coeur', 'carreau', 'trèfle', 'pique'])
AS COULEUR_CARTE WITH OFFSET ORD;
COULEUR_CARTE ORD
------------- ------
cœur 1
carreau 2
trèfle3 3
pique 4La fonction UNNEST permet de rajouter l’ordre de prise en compte des lignes résultantes en ajoutant une colonne contenant la valeur ordinale.
La fonction inverse ARRAY_AGG permet de transformer un tableau multi entrées en un tableau d’une seule case agrégeant toutes les valeurs :
Exemple 2.20* – agrégation des entrées d’un tableau :
Agrégation des entrées d’un tableau
SELECT ARRAY_AGG(ARRAY['coeur', 'carreau', 'trèfle', 'pique'])[1] AS AAG;
AAG
--------------------------------------
"coeur", "carreau", "trèfle", "pique"Notons aussi l’existence de la fonction TRIM_ARRAY pour expurger les cellules vides de la fin du tableau.
II-5-2. Ligne (ROW)▲
Le type ligne, permettant de définir un sous-ensemble composite de données un peu à la manière des « record » de certains langages comme Pascal.
La syntaxe de la définition d'une ligne commence par le nom de type ROW :
ROW (<col1> [,<col2>...])
Coln ::= nom type [reference] [COLLATE collation]Exemple 2.21* – utilisation du type ROW au sein d’un table :
Utilisation du type ROW au sein d’un table
CREATE TABLE T_PERSONNE_PRS
(PRS_ID INTEGER NOT NULL PRIMARY KEY,
PRS_NOM CHAR(32),
PRS_ADR ROW (LIGNE CHAR(38) ARRAY[3],
VILLE CHAR(32),
CODE_POSTAL CHAR(5))) ;Définit une colonne de nom PRS_ADR de type ligne contenant un tableau de 3 lignes d'adresse, suivie d'une colonne contenant la ville et d'une colonne contenant le code postal.
Pour assigner des valeurs à une ligne, on peut utiliser la technique du constructeur de ligne valorisée (row value constructor) :
Exemple 2.22 – construction d’un objet ligne :
ROW (ARRAY['1 rue de la liberté', 'bâtiment D', NULL], 'PARIS', '75015') ;
Les comparaisons de lignes peuvent s'effectuer globalement :
Exemple 2.23 – comparaison de tableau :
...
WHERE PRS_ADR = ROW((ARRAY['1 rue de la liberté', 'bâtiment D', 'BP 484'], 'PARIS', '75015') ;On peut aussi utiliser une notation pointée pour accéder à une colonne d'une ligne :
Exemple 2.24 – comparaison d’éléments de tableau :
...
WHERE PRS_ADR.LIGNE[3] = 'BP 484' ;|
|
ATTENTION |
II-5-3. Le type MULTISET (collection)▲
Le MULTISET est une collection de valeurs atomiques ou de lignes (ROW).
Exemple 2.25 – deux multisets simples :
MULTISET ['Coeur', 'Carreau', 'Pique', 'Trefle']
MULTISET (SELECT DISTINCT USR_PRENOM
FROM T_UTILISATEUR_USR)Exemple 2.26 – un multiset composite :
MULTISET (SELECT ROW(USR_NOM, USR_PRENOM)
FROM T_UTILISATEUR_USR)L'emploi du mot clef MULTISET est obligatoire pour construire un MULTISET valorisé.
Ces types de données peuvent faire l’objet d’opérations ensemblistes : MULTISET UNION, MULTISET INTERSECT, MULTISET EXCEPT.
|
|
ATTENTION – ROW, ARRAY, MULTISET et inégalités |
II-5-4. Héritage de table▲
SQL:1999 permet de définir des tables héritées de tables. La table racine est dite « super table » et les tables héritées sont dites « sous-tables ». Voici un exemple de super table et de sous-table :
Exemple 2.27* – principe de l’héritage de table :
Principe de l’héritage de table
-- la super table
CREATE TABLE T_PERSONNE_PRS
(PRS_ID INTEGER NOT NULL PRIMARY KEY,
PRS_NOM CHAR(32) NOT NULL,
PRS_PRENOM VARCHAR(32),
PRS_DATE_NAISSANCE DATE);
-- une sous table
CREATE TABLE T_EMPLOYEE_EMP UNDER T_PERSONNE_PRS
(EMP_MATRICULE CHAR(8) NOT NULL);
-- une autre sous table
CREATE TABLE T_CLIENT_CLI UNDER T_PERSONNE_PRS
(CLI_REMISE_NEGOCIEE FLOAT);L’exemple 2.27 nous montre que la sous-table T_EMPLOYEE_EMP comporte les colonnes de la table T_PERSONNE_PRS auxquelles on a ajouté ses propres définitions de colonnes, ici EMP_MATRICULE.
|
|
ATTENTION |
II-5-5. Les types « utilisateur » ou UDT (User Data Type)▲
SQL:1999 introduit la possibilité de définir trois formes de nouveaux types : les types distincts (typage fort), les types hérités et les types abstraits. La syntaxe complète de la création d'un type ne comporte pas moins de sept clauses possédant pour la plupart de nombreuses options et spécifications.
Nous allons juste faire un aperçu par l'exemple de ces différents types.
II-5-5-1. Types DISTINCT▲
Un type DISTINCT est un type bâti depuis un type ordinaire de SQL comme le type INTEGER, avec cette particularité que, même dérivé d'un type de base comme INTEGER, il ne peut être combiné dans des opérations de calcul ou de comparaison qu'avec des types de même nature ou à l'aide d'opérations de transtypage. En un mot, il s'agit d'un typage fort.
Il s'agit de créer de toutes pièces de nouveaux types de données, ce qui n'était pas possible dans la notion de domaine qui couvrait un type existant restreint à des règles de validation.
La syntaxe pour exprimer un type DISTINCT est :
CREATE DISTINCT TYPE <nom_type>
AS <type_sql>
FINALLe mot clef FINAL indique que ce type est instanciable et peut donc être utilisé dans la définition d'une colonne de table. En revanche, il ne peut pas être utilisé pour servir d'ancêtre à un nouveau type hérité. Dans le cas du type DISTINCT, le mot clef FINAL est obligatoire... À contrario, un type non FINAL est utilisé comme définition intermédiaire afin de construire d'autres types (héritage de type).
Exemple 2.28* – création de types :
CREATE DISTINCT TYPE MONNAIE_DOLLAR AS DECIMAL(16,2) FINAL;CREATE DISTINCT TYPE MONNAIE_EURO AS DECIMAL(16,2) FINAL;
Dès lors, l'utilisateur dispose d'un typage fort lié au type de colonne de la table. On utilise un tel type, comme un type SQL habituel dans la définition d'une table.
Exemple 2.29* – utilisation de type dans la définition d’une table :
Utilisation de type dans la définition d’une table.sql
CREATE TABLE T_COMPTABILITE_CPT
(CPT_ID INTEGER NOT NULL PRIMARY KEY,
CPT_LIBELLE_ECRITURE VARCHAR(32) NOT NULL,
CPT_DATE DATE NOT NULL DEFAULT CURRENT_DATE,
CPT_DEBIT_US MONNAIE_DOLLAR NOT NULL DEFAULT 0
CHECK VALUE >=0,
CPT_DEBIT_UE MONNAIE_EURO NOT NULL DEFAULT 0
CHECK VALUE >=0,
CPT_CREDIT_US MONNAIE_DOLLAR NOT NULL DEFAULT 0
CHECK VALUE >=0,
CPT_CREDIT_UE MONNAIE_EURO NOT NULL DEFAULT 0
CHECK VALUE >=0,
CPT_COURS_DOLLAR_EURO FLOAT) ;Désormais, toute comparaison ou opération entre types distincts différents est impossible.
Exemple 2.30* – utilisation de colonnes ayant des types distincts dans une requête :
Utilisation de colonnes ayant des types distincts dans une requête
SELECT *
FROM T_COMPTABILITE_CPT
WHERE CPT_DEBIT_US * CPT_COURS_DOLLAR_EURO = CPT_DEBIT_UEAinsi, la requête de l’exemple 2.28 génère une exception, cela afin de ne pas mélanger les serviettes et les torchons !
En effet, on ne peut comparer que ce qui est comparable. L'adition de litre d'essence avec des heures de vol n'ayant aucun sens, la comparaison directe de valeurs financières de différentes monnaies n'a pas non plus de sens... à moins que vous ne spécifiiez dans votre requête une conversion explicite...
Exemple 2.31* – utilisation de colonnes ayant des types distincts dans une requête à l’aide d’un transtypage :
Utilisation de colonnes ayant des types distincts dans une requête à l’aide d’un transtypage
SELECT *
FROM T_COMPTABILITE_CPT
WHERE CAST(CPT_DEBIT_FRANC AS FLOAT) * 6.55957 = CAST(CPT_DEBIT_EURO AS FLOAT)La norme SQL:1999 précise qu'un type utilisateur peut être construit avec des méthodes (type abstrait), dont certaines peuvent servir à définir des opérations de transtypage.
II-5-5-2. Type hérité▲
Un type hérité est un type qui prend pour référence un type parent et lui ajoute ses propres éléments. Il s'agit de l'héritage classique que l'on trouve dans la plupart des langages de programmation actuels, connus sous le terme générique « langage objet ».
Dans un type hérité, le mot clef INSTANTIABLE signifie que le type peut servir à la définition d'une variable comme d'une colonne de table. Dans le cas contraire (NOT INSTANTIABLE) il ne peut en aucun cas être utilisé pour y recevoir des valeurs et ne sert qu'à la définition d'autres types (en un sens il s'agit d'un objet abstrait). Comme évoqué précédemment, FINAL signifie que le type ne peut qu'être distinct. Un type héritable ne peut donc qu'être NOT FINAL !
|
|
NOTE |
L’exemple 2.30 montre les concepts de type hérité, de « super type » et de « sous type » :
Exemple 2.32* – types hérités, super-type et sous-type :
Types hérités, super-type et sous-type
CREATE TYPE oeuvre
AS (titre VARCHAR(256),
date_creation DATE))
NOT INSTANTIABLE
NOT FINAL;
CREATE TYPE original UNDER oeuvre
INSTANTIABLE
NOT FINAL;
CREATE TYPE objet UNDER oeuvre
AS (longueur FLOAT,
largeur FLOAT,
hauteur FLOAT,
poids FLOAT)
NOT INSTANTIABLE
NOT FINAL;
CREATE TYPE peinture UNDER objet
AS (support VARCHAR(64))
INSTANTIABLE
NOT FINAL;
CREATE TYPE sculpture UNDER objet
AS (matière VARCHAR(32))
INSTANTIABLE
FINAL;
CREATE TYPE livre UNDER oeuvre
AS (date_premiere_edition DATE,
langue varchar(32))
INSTANTIABLE
FINAL;Quelques remarques concernant ce script SQL :
- « oeuvre » est un super type. C'est l'ancêtre de tous les types que nous allons dériver. Notons que « œuvre » n'est pas instanciable. C'est une coquille qui sert de « moule » pour réaliser nos autres types ;
- ainsi « original" est un type instanciable, c'est-à-dire que l'on peut s'en servir pour y placer une œuvre dotée des seuls attributs titre et date_creation ;
- « objet » est à nouveau un titre non instanciable dans le sens où il sert de moule complémentaire à œuvre, en lui adjoignant de nouvelles caractéristiques ;
- « peinture » est un type instanciable dont les caractéristiques sont, en définitive : titre, date_creation, longueur, largeur, hauteur, poids et support ;
- de même, « sculpture » est aussi un type instanciable dont les caractéristiques sont, en définitive : titre, date_creation, longueur, largeur, hauteur, poids et matière. Notez qu'il ne peut pas être repris pour créer un nouveau sous type du fait du mot clef FINAL ;
- enfin, « livre » est un type instanciable construit à partir du type générique œuvre. Il possède donc les caractéristiques suivantes : titre, date_creation, date_premiere_edition, langue. Notez, comme dans le cas de « sculpture » qu'il ne peut pas être repris pour créer un nouveau sous type du fait du mot clef FINAL ;
- « original », « objet », « peinture », « sculpture » et « livre » sont des sous types ;
- « sculpture » et « livre » sont en outre des types distincts à cause du mot clef FINAL.
Voici une syntaxe de base pour la définition d'un type SQL :
CREATE TYPE <nom_type> [ UNDER nom_super_type ]
[ <external_java_type_clause> ]
[ AS représentation ]
[ [ NOT ] INSTANTIABLE ]
[ [ NOT ] FINAL ][ <external java type clause> ]permet d'utiliser un type d'après les types du langage Java ;[ AS représentation ]définition de la liste des attributs et de leurs types ;[ [ NOT ]INSTANTIABLE ] peut (ou ne peut pas) être utilisé pour la définition d'une colonne (objet abstrait) ;[ [ NOT ]FINAL ] ne peut pas (ou peut) être repris pour la définition d'un sous type.
II-5-5-3. Types abstraits▲
Un type abstrait (ADT Abstract Data Type) peut être construit sous la forme d'une structure de données (attributs) et posséder des routines qui lui sont applicables (méthodes). Le type abstrait peut aussi être construit par héritage.
On décrit donc une structure de type abstrait au niveau des attributs, d'une manière semblable à la liste des colonnes d'une table.
Exemple 2.33* – un type abstrait :
CREATE TYPE ADT_ADRESSE
AS
(ADR_LIGNE1 VARCHAR(38),
ADR_LIGNE2 VARCHAR(38),
ADR_LIGNE3 VARCHAR(38),
ADR_CODE_POSTAL CHAR(5),
ADR_VILLE CHAR(32))
NOT FINAL;Bien entendu, on peut composer un type abstrait à partir d’un autre type abstrait et ainsi de suite...
Exemple 2.34* – types abstraits emboités :
CREATE TYPE ADT_PERSONNE
AS
(PRS_NOM CHAR(32),
PRS_PRENOM VARCHAR(32),
PRS_DATE_NAISSANCE DATE,
PRS_SEXE CHAR(1),
PRS_ADRESSE ADT_ADRESSE,
METHOD PRS_AGE() RETURNS FLOAT)
NOT FINAL;Dans cet exemple de types abstraits « gigogne », on trouve une adresse dans la définition du type abstrait de la personne !
Pour implémenter une méthode applicable à un attribut, SQL:1999 se sert de la notion « d'attribut virtuel ». Cela nécessite la définition d'une fonction qui sera greffée sur le type abstrait. Ainsi, pour donner l'âge de notre personne, nous pouvons créer une méthode comme le montre l’exemple 2.33.
Exemple 2.35* – ajout d’une méthode à un type abstrait :
Ajout d’une méthode à un type abstrait
CREATE METHOD AGE() FOR ADT_PERSONNE
RETURNS INT
SELF AS RESULT
LANGUAGE SQL
DETERMINISTIC
CONTAINS SQL
RETURN NULL ON NULL INPUT
RETURN INTERVAL YEAR (CURRENT_DATE - ADT_PERSONNE.PSR_DATE_NAISSANCE) -
CASE WHEN EXTRACT(MONTH FROM ADT_PERSONNE.PSR_DATE_NAISSANCE)
> EXTRACT(MONTH CURENT_DATE) THEN 1
WHEN EXTRACT(MONTH FROM ADT_PERSONNE.PSR_DATE_NAISSANCE)
= EXTRACT(MONTH CURENT_DATE) AND
EXTRACT(DAY FROM ADT_PERSONNE.PSR_DATE_NAISSANCE)
> EXTRACT(DAY CURENT_DATE) THEN 1
ELSE 0
END;Étant donné que le type abstrait est souvent une structure de données complexe, il n'est pas toujours possible d'utiliser un classement implicite. C'est pourquoi SQL a défini la possibilité de créer le schéma d'ordonnancement des données du type à l'aide de l'ordre CREATE ORDERING qui permet de définir soit le comportement de l'opérateur d'égalité, soit le comportement du tri à l'aide d'une routine.
|
|
NOTE |
II-5-6. Type TABLE ou table objet▲
Il est possible de créer une table à partir d'un type utilisateur. En fait, plutôt que de parler d'un type TABLE, on devrait parler de table « type » (un modèle de table), ou encore de table objet, car elle est définie à partir d'un type abstrait.
L’exemple 2.34 va permettre de mieux comprendre l'utilité de ce type et sa syntaxe. Supposons que nous voulons créer un type disque (contenant des chansons) :
Exemple 2.36* – type TABLE instanciable :
type TABLE instanciablel-la-synthese/scripts/
CREATE TYPE DISQUE
AS (titre VARCHAR(256),
date_creation DATE,
nombre_plage INTEGER)
INSTANTIABLE
NOT FINAL
REF IS SYSTEM GENERATED;Comme ce type va servir à générer des sous-types, il est indispensable de préciser comment la référence à une ligne de ce type est générée. Ici c'est le SGBDR qui s'occupe de générer la valeur de référence, le « pointeur » en quelque sorte (REF IS SYSTEM GENERATED).
À partir de ce type, nous pouvons créer le type CD :
Exemple 2.37* – création d’une table d’après un type table père :
Création d’une table d’après un type table père
CREATE TYPE CD UNDER DISQUE
AS (editeur VARCHAR(32),
numero_serie CHAR(16)))
INSTANTIABLE
NOT FINAL;Dès lors, notre CD comporte 5 colonnes : celles du disque et celles propres au CD.
Maintenant, voyons comment créer des tables à partir de ces types :
Exemple 2.38* – création d’une table d’après un type, table :
création d’une table d’après un type, tablegage-sql-la-synthese/scripts/
CREATE TABLE T_CD OF CD
(REF IS CD_ID SYSTEM_GENERATED);Notez le mot clef OF qui permet à partir d'un type d'instancier une table.
Le mécanisme de référence permet de créer une colonne particulière dont la valeur « transparente » est unique et peut servir de référence à la manière d'un pointeur. Dans le présent cas, la colonne CD_ID de type REF possède une valeur générée par le SGBDR...
Créons maintenant une table permettant de spécifier des CD « courts » (des « single » ne comportant pas plus de deux titres !) :
Exemple 2.39* - création d’une table d’après un type table avec colonnes supplémentaires :
création d’une table d’après un type table avec colonnes supplémentaires
CREATE TABLE T_SINGLE_CD OF CD
UNDER T_CD
( nombre_plage WITH OPTIONS
CONSTRAINT pas_plus_de_deux_titres CHECK (nombre_plage <= 2 ));Cette nouvelle table emprunte sa structure à la table T_CD depuis le type CD et ajoute une contrainte à la colonne nombre_plage.
T_CD est une table « type ». Notons qu'à ce stade une table « type » ne peut qu'être ancêtre, jamais sous table et doit toujours comporter une déclaration de référence.
II-5-7. Type référence▲
Nous avons vu dans les exemples 2.34 et 2.36, un nouveau concept avec le mot clef REF…
Un type référence (REF) est une colonne qui permet de pointer directement vers un objet ligne d'une autre table. Cela permet d'automatiser le principe des tables de référence (par exemple une table des codes postaux). Mais contrairement à l'intégrité référentielle, la valeur n'est pas contenue dans la table qui comporte la colonne référencée.
Une référence se déclare lors de la création de la table. La table référencée doit être définie au préalable.
Exemple 2.40* – utilisation du type REF :
-- création des UDT
CREATE TYPE UDT_CP_VILLE
AS
(CODE_POSTAL CHAR(5) NOT NULL,
VILLE VARCHAR(32) NOT NULL)
NOT FINAL ;
CREATE TYPE UDT_PAYS
AS
(CODE_PAYS VARCHAR(2) DEFAULT 'F' NOT NULL,
NOM_PAYS VARCHAR(64) NOT NULL)
NOT FINAL ;
-- création des tables de référence
CREATE TABLE TR_CODE_POSTAL_CPL
(CPL UDT_CP_VILLE) ;
CREATE TABLE TR_PAYS_PAY
(PAY UDT_PAYS) ;
-- création de la table adresse utilisant les références
CREATE TABLE T_ADRESSE_ADR
(ADR_ID INTEGER NOT NULL PRIMARY KEY,
ADR_LIGNE1 VARCHAR(38),
ADR_LIGNE2 VARCHAR(38),
ADR_LIGNE3 VARCHAR(38),
ADR_CP_VILLE REF UDT_CP_VILLE SCOPE TR_CODE_POSTAL_CPL
REFERENCES ARE NOT CHECKED
ON DELETE SET NULL,
ADR_PAYS REF UDT_PAYS SCOPE TR_PAYS_PAY
REFERENCES ARE CHECKED
ON DELETE SET DEFAULT) ;
-- remplissage des tables de référence avec des valeurs pré établies
INSERT INTO TR_PAYS_PAY (PAY..CODE_PAYS, PAY..NOM_PAYS)
VALUES ('F', 'France') ;
INSERT INTO TR_PAYS_PAY (PAY..CODE_PAYS, PAY..NOM_PAYS)
VALUES ('US', 'États Unis d''Amérique') ;
INSERT INTO TR_CODE_POSTAL_CPL (CPL..CODE_POSTAL, CPL..VILLE)
VALUES ('75001', 'Paris, 1er arrondissement') ;
INSERT INTO TR_CODE_POSTAL_CPL (CPL..CODE_POSTAL, CPL..VILLE)
VALUES ('06000', 'Nice') ;
-- exemple d’insertion d’une adresse ...
INSERT INTO T_ADRESSE_ADR
VALUES (423, '1 rue de la Paix', NULL, NULL,
(SELECT REF(CPL)
FROM TR_CODE_POSTAL_CPL CPL
WHERE CPL.CODE_POSTAL = '06000'),
(SELECT REF(PAY)
FROM TR_PAYS_PAY PAY
WHERE PAY.CODE_PAY = 'F'));REF est un opérateur qui renvoie l'adresse de la ligne de la table référencée.
Pour obtenir la valeur du type cible d'une ligne référencée, il faut utiliser l'opérateur DEREF ou le symbole ->. Dans le cas contraire on obtiendrait simplement la valeur du pointeur (adresse de la ligne), ce qui ne présente à priori par d'intérêt !
Exemple 2.41* – valeur de référence et pointeur REF :
valeur de référence et pointeur REF
-- obtention des données
SELECT ADR_ID, DEREF(ADR).ADR_CP_VILLE
FROM T_ADRESSE_ADR ADR
WHERE ADR_ID = 423;
ADR_ID ADR_CP_VILLE..CODE_POSTAL ADR_CP_VILLE..VILLE
--------------- ------------------------- -------------------------
423 06000 NICE
-- obtention du pointeur
SELECT ADR_ID, ADR.ADR_CP_VILLE
FROM T_ADRESSE_ADR ADR
WHERE ADR_ID = 423;
ADR_ID ADR_CP_VILLE
--------------- ----------------
423 51A0245154F3C681
SELECT ADR_ID, ADR->ADR_CP_VILLE
FROM T_ADRESSE_ADR ADR
WHERE ADR_ID = 423
ADR_ID ADR_CP_VILLE..CODE_POSTAL ADR_CP_VILLE..VILLE
--------------- ------------------------- -------------------------
423 06000 NICEII-5-8. Pointeur (LOCATOR)▲
Afin de faciliter la migration de données de très fort volume, la norme SQL:1999 a prévu l'utilisation d'un attribut pointeur (LOCATOR) que toute colonne peut posséder, permettant de stocker les données côté client, un peu à la manière de ce que fait un navigateur Web en plaçant les ressources sur le poste client afin de minimiser les flux sur le réseau. Mais le mécanisme n'est pas automatique et c'est au développeur de monter les ressources avant toute requête SQL utilisant un tel pointeur.
À l’exception de IBM DB2 aucun autre SGBDR n’utilise ce type particulier.
II-5-9. Datalink▲
Le type DATALINK est une référence à un fichier externe, permettant par exemple de stocker des images, de la vidéo, des sons et des fichiers binaires. Les fichiers ainsi référencés restent sur un disque quelconque du système informatique. Les données sont donc externes à la base, mais il est possible de maintenir une intégrité de manière à interdire modifications et suppressions des fichiers autrement que par un ordre SQL de la base.
Un tel type de données se déclare de la sorte :
DATALINK [ <options_de_contrôle> ]
<options_de_contrôle> ::=
NO LINK CONTROL | FILE LINK CONTROL <option_de_contrôle_fichier>
<option_de_contrôle_fichier> ::=
<option_intégrité> <autorisation_lecture> <autorisation_écriture>
<option_récupération> [ <option_détachement> ]
<option_intégrité> ::=
INTEGRITY ALL
| INTEGRITY SELECTIVE
| INTEGRITY NONE
<autorisation_lecture> ::=
READ PERMISSION FS
| READ PERMISSION DB
<autorisation_écriture> ::=
WRITE PERMISSION FS
| WRITE PERMISSION BLOCKED
<option_récupération> ::=
RECOVERY NO
| RECOVERY YES
<option_détachement> ::=
ON UNLINK RESTORE
| ON UNLINK DELETE
| ON UNLINK NONEVoici la description des principaux paramètres du DATALINK :
- NO LINK CONTROL signifie que les liens ne sont connus par la base que par leurs noms (URI : Uniform Ressource Identifier).
Dans le cas contraire, FILE LINK CONTROL, il est possible de piloter les liens par les options de la base de données décrites ci dessous : - INTEGRITY ALL : seul un ordre SQL peut supprimer ou modifier les fichiers afférents au lien ;
- INTEGRITY SELECTIVE : un ordre SQL, comme le système de fichier de l'OS, peut supprimer ou modifier les fichiers afférents au lien ;
- INTEGRITY NONE : seul le système de fichiers de l'OS peut supprimer ou modifier les fichiers afférents au lien ;
- READ PERMISSION FS : les droits en lecture sont définis par le système de fichiers ;
- READ PERMISSION DB : les droits en lecture sont définis par la base de données ;
- WRITE PERMISSION FS : les droits en écriture sont définis par le système de fichiers ;
- WRITE PERMISSION BLOCKED : aucun droit en écriture n'est autorisé ;
- RECOVERY YES : sauvegarde et restauration possible dans le cadre de la base de données ;
- RECOVERY NO : sauvegarde et restauration impossible dans le cadre de la base de données ;
- ON UNLINK RESTORE : restaure les droits et le propriétaire système originels si le lien est détaché de la base ;
- ON UNLINK DELETE : suppression du fichier en cas de détachement de la base ;
- ON UNLINK NONE : en cas de détachement de la base, le fichier n'est pas supprimé et les droits restent pendants (des droits systèmes sont appliqués par défaut si cela est possible).
Exemple 2.42* – table avec DATLINK pour stoker des vidéos :
table avec DATLINK pour stoker des vidéos
CREATE TABLE T_FILM_FLM
(FLM_ID INT NOT NULL PRIMARY KEY,
FLM_TITRE VARCHAR(256),
FLM_FILM DATALINK FILE LINK CONTROL
INTEGRITY ALL
READ PERMISSION DB
WRITE PERMISION BLOCKED
RECOVERY YES
ON UNLINK NONE,
FLM_ANNEE INT);SQL fournit en outre des fonctions afin de piloter l'insertion, la restitution, comme l'extraction de certaines parties de l'URI :
- DLVALUE : instancie la valeur de l'URI pour la colonne de type DATALINK (constructeur) ;
- DLURLCOMPLETE : restitue la valeur de l'URI contenue dans la colonne de type DATALINK ;
- DLURLPATH : restitue le chemin de l'URI, avec son origine ;
- DLURLPATHONLY : restitue le chemin de l'URI, sans son origine ;
- DLURLSCHEME : restitue le mode de flux (http ou file) de l'URI ;
- DLURLSERVER : restitue la ressource de l'URI.
Exemple 2.43* – Insertion d’un vidéo dans une colonne DATALINK :
Insertion d’un vidéo dans une colonne DATALINK-sql-la-synthese/scripts/
INSERT INTO T_FILM_FLM (FLM_ID, FLM_TITRE, FLM_FILM, FLM_ANNEE)
VALUES (178, 'West Side Story',
DLVALUE('file://srvmed/films/WesSideStory.mpeg'),
1960)L’exemple 2.41 montre l’insertion d’une ligne dans la table T_FILM_FLM construite dans l’exemple 2.40, avec enregistrement du fichier vidéo du film « West Side Story ». L’exemple 2.42 montre comment récupérer l’accès au fichier :
Exemple 2.42* – accéder à un fichier à travers le DATALINK :
accéder à un fichier à travers le DATALINK
SELECT FLM_TITRE, FML_ANNEE, DRURLCOMPLETE(FLM_FILM) AS FLM_MPEG
FROM T_FILM_FLM
WHERE FLM_ID = 178
FLM_TITRE FML_ANNEE FLM_MPEG
----------------- ------------ ---------------------------------------
West Side Story 1960 file://srvmed/films/WesSideStory.mpeg|
|
NOTE |
II-5-10. Pour conclure sur les types « objet »▲
Même si certains types objets simples comme les types tableau ou mutisets (collection), paraissent séduisants, il ne faut pas oublier qu’il n’est pas possible d’en indexer la totalité du contenu… Et d’ailleurs, qu’est-ce qu’un type tableau ? Ne serait-ce pas une table ? Pourquoi utiliser un tableau à l’intérieur d’une colonne de table alors qu’une table sera plus performante et mieux documentée ? Quant au type multisets, même combat… Mieux vaut dans ces deux cas utiliser une table.
Concernant le type REF, il semble que nous soyons revenus aux temps anciens des pointeurs et du COBOL !
Si l’on peut comprendre l’intérêt d’intégrer parfois des objets sophistiqués au sein d’une table dans un SGBD relationnel, il ne faut pas perdre de vue l’objectif final qui consiste à brasser le plus rapidement possible des quantités importantes de données. Ces objets ne pouvant être indexés globalement, il faudra externaliser certaines des données de l’objet dans des colonnes atomiques et indexer ces dernières afin de pouvoir retrouver rapidement les informations contenues dans ces objets, ce qui ajoute de la redondance à la base…
II-6. Marqueur NULL▲
NULL est un mot clef de SQL qui spécifie l'absence de valeur. NULL n'est donc en aucun cas une valeur et ne peut être comparé à aucune valeur. Il faut comprendre que NULL est un « marqueur » qui indique qu'aucune assignation n'a encore été effectuée, ou bien que l'on a « vidé » l'objet de sa valeur.
Ce marqueur ne pouvant être de fait comparé à aucun autre élément (l’inexistence conférant l’impossibilité de tout rapprochement), des opérateurs spécialisés comme IS NULL, IS NOT NULL et des fonctions ou opérateurs comme COALESCE permettent de rechercher ces valeurs manquantes ou bien de les contourner. Nous verrons cela au chapitre 4.
La présence du NULL provoque parfois des résultats qui peuvent surprendre au premier abord parce que parfois contre intuitifs dans certains prédicats. Voici quelques exemples des problématiques dont il faut avoir conscience...
Exemple 2.45* – influence du NULL…
-- Avec la table suivante :
CREATE TABLE T_NUL (NUL_X INT, NUL_Y INT);
INSERT INTO T_NUL VALUES (1, 1);
INSERT INTO T_NUL VALUES (1, 2);
INSERT INTO T_NUL VALUES (NULL, 2);
INSERT INTO T_NUL VALUES (1, NULL);
INSERT INTO T_NUL VALUES (NULL, NULL);
-- dont le contenu est :
NUL_X NUL_Y
----------- -----------
1 1
1 2
NULL 2
1 NULL
NULL NULL
-- À la lecture, les paires de requêtes suivantes
-- semblent donner le même résultat ; or il n'en est rien...
SELECT * FROM T_NUL WHERE NUL_X = NUL_Y OR NOT (NUL_X = NUL_Y);
SELECT * FROM T_NUL;
NUL_X NUL_Y
----------- -----------
1 1
1 2
NUL_X NUL_Y
----------- -----------
1 1
1 2
NULL 2
1 NULL
NULL NULL
SELECT SUM(NUL_X) + SUM(NUL_Y) AS N FROM T_NUL;
SELECT SUM(NUL_X + NUL_Y) AS N FROM T_NUL;
N
-----------
8
N
-----------
5
SELECT CASE WHEN NUL_X = NUL_Y THEN 1 ELSE 0 END AS TRUTH FROM T_NUL;
SELECT CASE WHEN NOT(NUL_X=NUL_Y) THEN 1 ELSE 0 END AS TRUTH FROM T_NUL;
TRUTH
-----------
1
0
0
0
0
TRUTH
-----------
0
1
0
0
0II-7. Commentaire dans les requêtes▲
À tout moment, il est possible d’ajouter au code SQL du commentaire. Il existe deux formes de commentaires :
- le commentaire en ligne ;
- le commentaire en bloc.
Tout commentaire incorporé à une requête est passé au moteur SQL qui l’ignore.
Plusieurs de nos exemples précédents (2.38, 2.39…) sont ornés de commentaires.
II-7-1. Commentaire en ligne▲
Le commentaire en ligne commence par deux tirets -- (signe « moins ») et tout ce qui suit jusqu’à la fin de la ligne est considéré comme commentaire et donc non interprété en langage SQL.
Exemple 2.46* – Commentaire en ligne :
SELECT EMP_ID, EMP_NOM, EMP_DATE_ENTREE, EMP_SALAIRE_NA, EMP_INDICE
FROM S_RH.T_EMPLOYE_EMP
WHERE EMP_NOM = 'DUFOUR' -- le nom recherché est DUFOUR
AND EMP_DATE_ENTREE > '2001-12-31' -- entré à partir de 2002
OR (EMP_SALAIRE_NA > 23456-- ou bien ayant un salaire supérieur à 231456
AND (EMP_INDICE < 450 OR EMP_INDICE IS NULL));
--et un indice inférieur à 450 ou non renseignéII-7-2. Commentaire en bloc▲
Le commentaire en bloc commence par les symboles /* (barre oblique à droite + étoile) et se termine par la combinaison inverse */ (étoile + barre oblique à droite). Ce type de commentaires peut sauter de nombreuses lignes…
Exemple 2.47* – Commentaire en bloc :
SELECT EMP_ID, EMP_NOM, EMP_DATE_ENTREE, EMP_SALAIRE_NA, EMP_INDICE
FROM S_RH.T_EMPLOYE_EMP
/* on recherche les employés dont le nom est DUFOUR, entrés à partir de 2002 ou bien ayant un salaire supérieur à 231456 et un indice inférieur à 450 ou non rensigné*/
WHERE EMP_NOM = 'DUFOUR'
AND EMP_DATE_ENTREE > '2001-12-31'
OR (EMP_SALAIRE_NA > 23456
AND (EMP_INDICE < 450 OR EMP_INDICE IS NULL));II-8. Le « point-virgule » comme terminaison d’une commande SQL▲
Bien que cela ne soit pas obligatoire, il est courant de terminer toutes les commandes du SQL avec le symbole « ; » (point-virgule). C’est une bonne pratique qui élimine toute confusion.
II-9. Références pour ce chapitre▲
- Data & Databases: Concepts in Practice - Joe Celko - Morgan Kaufmann – 1999
- SQL Développement - Frédéric Brouard - Campus Press – 2001
- SQL-99 Complete Really - Peter Gulutzan & Trudy Pelzer - R&D Books (Miller Freeman) – 1999
- SQL:1999, Understanding Relational Language Components - Jim Melton, Alan R. Simon - Morgan Kaufmann – 2002
- Advanced SQL:1999, Understandig Object-Relational and Other Advanced Features - Jim Melton - Morgan Kaufmann – 2003
- Data, Measurements and Standards - Joe Celko - Morgan Kaufmann – 2010
- SQL, collection Synthex - 4e édition – Frédéric Brouard, Christian Soutou, Rudi Bruchez – 2012
- SQL and the Relational Theory, How to Write Accurate SQL Code - 3re Edition - Christopher J. Date - O'Reilly – 2015
- Practical SQL, A Beginner's Guide to Storytelling with Data - Anthony DeBarros - No Starch Press – 2018
- SQL Queries for Mere Mortals - 4th Edition - John L. Viescas - Pearson – 2018
- Learning SQL, Generate, Manipulate, and Retrieve Data - 3rd Edition - Alan Beaulieu - O'Reilly - 2021