


III. Chapitre 3 - Création des objets :schémas, tables, vues, assertions▲
Si la modélisation conduit à la structuration de la base, le type des données, comme la composition des objets et les règles de validation par contraintes sont une composante fondamentale de la qualité d'une base de données :
- une qualité de données de plus en plus demandée notamment pour couvrir les besoins du décisionnel (analyse de cubes OLAP en particulier, BI (Business Intelligence) temps réel…) ;
- une structuration de plus en plus précise pour coller à la réalité des objets procéduraux (mapping relationnel objet par exemple) ;
- des règles de validation de plus en plus sophistiquées se rapprochant de la logique « métiers » des applicatifs.
La création des objets SQL répond donc à cette triple approche.
Dans ce chapitre nous allons nous intéresser à la construction des tables (CREATE TABLE), à leurs interdépendances au travers de l'intégrité référentielle, et nous montrerons l'intérêt des vues. Nous terminerons par la modification et la suppression des objets existants (ordre SQL ALTER et DROP) et finalement présenterons un moyen de créer des tables à la volée. Pour cela nous aurons besoin de définir ce que sont les contraintes parmi lesquelles nous avons déjà mentionné au chapitre précédent celles de domaines et nous découvrirons les assertions qui sont des contraintes générales exprimées au niveau de la base de données. Tous ces éléments, et les types du chapitre précédent, composent le DDL (Data Definition Language), la subdivision du SQL qui s'occupe de créer, modifier et supprimer les schémas et les objets qu'ils contiennent.
Mais avant tout cela il nous faut porter un regard attentif à la règle de formation des noms des objets SQL ainsi qu’à la façon dont on se connecte à un serveur de bases de données relationnelles…
III-1. Règles de nommage▲
SQL impose un certain nombre de règles concernant les noms des objets d'une base de données. Ces noms sont appelés identifiants SQL, dans le sens où ils doivent être uniques de manière relative à leur conteneur et donc servir d’identifiant pour tout objet : nom de table, nom de colonne, nom de contrainte...
Un nom d'objet (table, colonne, contrainte, vue...) doit avoir les caractéristiques suivantes :
- ne pas dépasser 128 caractères ;
- ne pas commencer par un chiffre ;
- être composé de lettres basiques(17), de chiffres et du caractère blanc souligné ;
- ne pas être un mot réservé de SQL(18) sauf à être entouré de guillemets.
En outre les noms d'objet SQL sont insensibles à la casse sauf pour ceux délimités.
Même si certains SGBDR permettent des noms exotiques, comportant des accents ou des blancs, il ne faudrait jamais utiliser de caractères diacritiques ou non autorisés dans un nom d'objet SQL, en effet les caractères de bits supérieurs à 128 dans le jeu ASCII étant dépendants des pages de codes, il se peut que la correspondance ne s'établisse pas correctement entre la base de données et l'application cliente. Notez en outre que l'espace, le point, le tiret et l'apostrophe sont interdits.
Le tableau suivant présente quelques identifiants SQL bien et mal formés :
|
Valable |
Interdit |
|---|---|
|
T_CLIENT |
TAB CLIENT |
|
Xyz123 |
123xyz |
|
IBM_COM |
ibm.com |
|
"SELECT" |
SELECT |
|
CLI_NUM |
CLI# |
|
MS_sql_Server |
Microsoft/SQLserver |
|
Tableau 3.1 – identifiants SQL bien et mal formés |
|
|
|
ATTENTION
|

|
|
CONSEIL |

III-2. Création d'une base : connexion, session, catalogue et schéma…▲
Nous avons regroupé ces concepts car ils sont très dépendants des spécificités de chaque éditeur de SGBDR. Ce n'est donc que pour le principe que nous étudierons rapidement ces éléments.
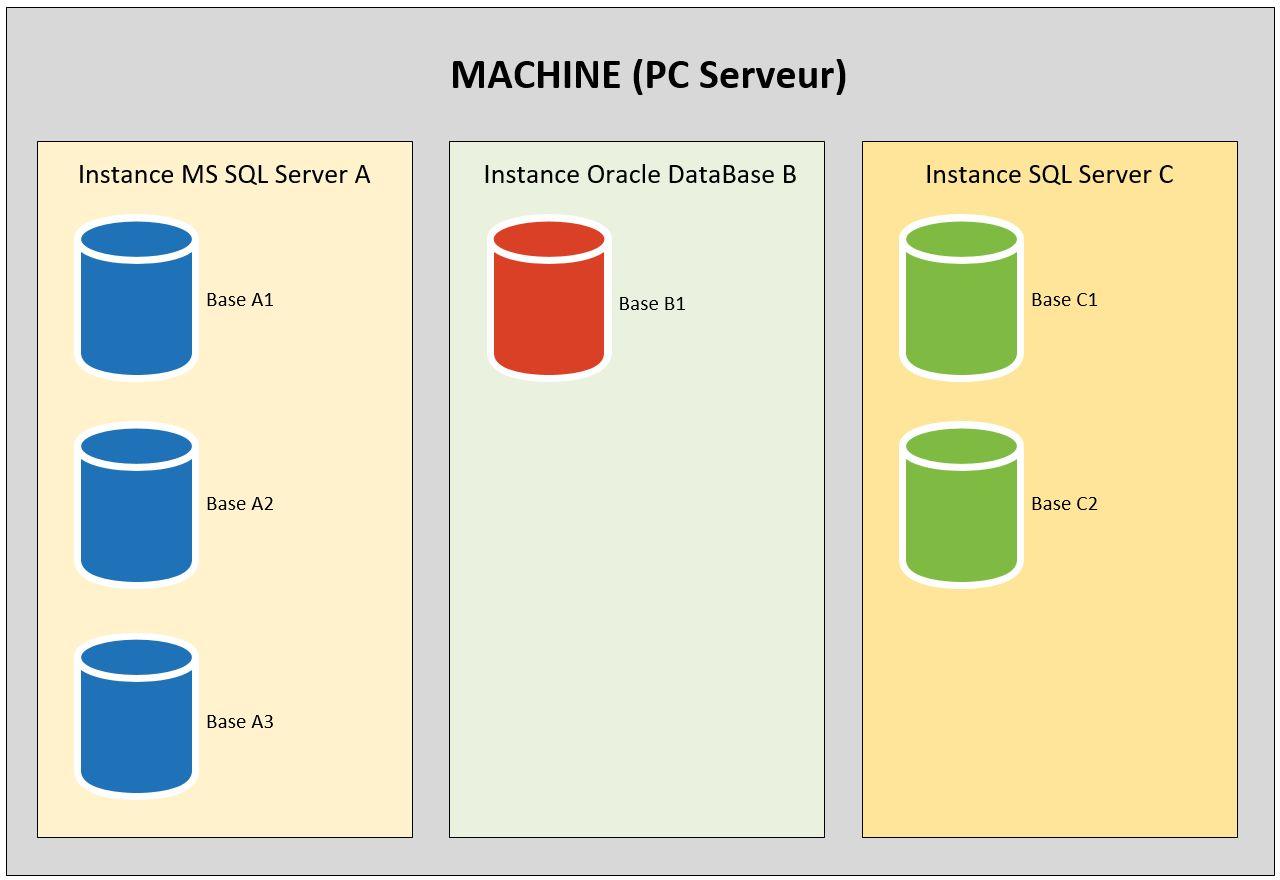
Pour rappel, une instance est un exécutable d’un SGBD Relationnel particulier et tourne en tant que service sur une machine qui peut être virtuelle ou physique. Plusieurs instances d’un même SGBDR ou de différents SGBDR peuvent être installées sur une même machine, bien que ceci ne soit pas conseillé en production. La figure 3.0a montre différentes instances installées sur une même machine, chaque instance ayant ses propres bases de données.
|
|
|
Figure 3.0a – Une machine avec différentes instances de SGBDR et leurs bases respectives |
III-2-1. La connexion▲
Avant de créer une base de données, il convient de se connecter au serveur. C'est la phase d'authentification. Mais cette connexion suppose au moins la création d'un utilisateur, qui est un objet de la base de données. SQL nous donne la clé en considérant qu'il doit toujours exister un utilisateur particulier de nom PUBLIC. Cet utilisateur est d'ailleurs plus proche de la notion de rôle que de celle d'un véritable utilisateur SQL.
Le choix de l'utilisateur « public » comme connexion par défaut à l'installation est très critiquable pour des raisons de sécurité car cet utilisateur ne peut en aucun cas être supprimé. C'est pourquoi les éditeurs de SGBDR professionnels ont opté pour d'autres comptes, comme c'est le cas avec les utilisateurs de noms « administrator » et « default » pour Oracle Database ou encore "sa" pour Microsoft SQL Server.
Pour SQL la connexion à un SGBDR prend la syntaxe suivante :
CONNECT TO {DEFAULT | nom_serveur [AS surnom_serveur ]
[USER nom_utilisateur] }Exemple 3.1 – Connexion au serveur par défaut
CONNECT TO DEFAULT;
L'ordre SQL de l’exemple 3.1 permet de se connecter au serveur de base de données défini par défaut. La plupart du temps un serveur de bases de données est installé sur une machine dédiée, ce qui fait qu'il n'y a pas d'ambiguïté. En revanche, si plusieurs serveurs sont installés sur la même machine, il faut nommer le serveur.
Exemple 3.2 – Connexion à un serveur par son nom
CONNECT TO S_MON_SERVEUR;
Dans l’exemple 3.2 on se connecte au serveur identifié « S_MON_SERVEUR ».
Il est même possible de renommer ce serveur, c'est à dire se servir d'un alias :
Exemple 3.3 – Connexion à un serveur par son nom, renommé par son alias
CONNECT TO S_MON_SERVEUR AS SRV1;
Qui se connecte à « S_MON_SERVEUR », mais le surnomme SRV1. Dès lors ce nouveau nom pourra être utilisé dans divers ordres SQL en lieu et place du nom authentique du serveur.
Enfin, il est possible de préciser le nom de l'utilisateur qui doit exister préalablement dans le SGBDR et qui sera associé à la connexion. Sans cette précision, le SGBDR emprunte le nom par défaut implanté par le constructeur ou encore l'utilisateur PUBLIC.
Exemple 3.4 – Connexion à un serveur par son nom, avec association d’un utilisateur SQL
CONNECT TO S_MON_SERVEUR USER U_MONA_LISA;
Se connecte au serveur « S_MON_SERVEUR » en empruntant l'identité U_MONA_LISA comme utilisateur.
Vous l'aurez compris, à une connexion est toujours associée un nom d'utilisateur. Un utilisateur SQL est un objet de la base de données et se définit aussi par un ordre SQL. Nous verrons cela au chapitre 8.
La norme SQL propose en outre la possibilité de basculer d'une connexion à l'autre (à condition que l'autre existe et soit dormante à l'aide de l'ordre :
SET CONNECTION { DEFAULT | nom_session }
Ou nom_session représente une connexion déjà établie et dormante (c'est à dire une connexion ouverte mais qui n'est pas activée par le passage d'ordre SQL..)
Bien entendu il est possible de fermer une connexion en utilisant l'ordre SQL DISCONNECT :
DISCONNECT { DEFAULT | CURRENT | ALL | nom_session }
|
|
NOTE |

Nous vous conseillons d'utiliser le site Web "The Connection Strings Reference" https://www.connectionstrings.com/ pour savoir comment paramétrer la chaîne de connexion propre à votre SGBDR, au middleware utilisé, et à la sécurité que vous voulez définir. Par exemple une chaîne de connexion pour Oracle Database via ODBC en sécurité SQL se définit de la manière suivante : Driver={Microsoft ODBC for Oracle};Server=myServerAddress;Uid=myUsername;Pwd=myPassword;
III-2-2. La session▲
Une session au sens de la norme SQL est une connexion activée et possède certains attributs particuliers. Les attributs d'une session sont :
- un identifiant d'autorisation (AUTHORIZATION) ;
- un nom de catalogue (CATALOG) ;
- un nom de schéma (SCHEMA) ;
- un fuseau horaire (TIME ZONE) ;
- un jeu de caractères (CHARACTER SET).
AUTHORIZATION : l'identifiant d'autorisation doit impérativement être choisi parmi les mots clés suivants USER, CURRENT_USER, SESSION_USER et SYSTEM_USER ou bien encore en donnant un nom d'utilisateur spécifique.
CATALOG : Un catalogue n’est ni plus ni moins qu’une base de données. Ce terme peut paraître curieux, mais souvenons-nous que le terme database n’était pas encore en vogue à l’époque de la naissance du langage SQL ou l’on parlait de databank…
SCHEMA : un schéma est un conteneur logique au sein d’une base de données, une base de données pouvant contenir de nombreux schémas destinés à isoler les différents pans logiques des objets de la base.
TIME ZONE : un fuseau horaire est l'indication du décalage de l'heure locale de la session par rapport au temps universel (UTC : Unified Time Coordination). Chaque session peut donc se connecter avec une synchronisation de fuseau horaire différente. C'est assez pratique lorsque l'on veut développer une application internationale, notamment pour les sites web et que les internautes viennent se connecter de toute la planète.
CHARACTER SET : le jeu de caractères permet de définir quel sous ensemble de symboles est utilisé pour codifier les littéraux.
|
|
NOTE |
III-2-3. Catalogues et schémas▲
Le terme SQL CATALOG désigne communément ce que nous appelons base de données. Le terme SCHEMA, désigne le seul type d'objet logique directement lié au CATALOG, c’est-à-dire un conteneur de tables, vues, procédures…
III-2-3-1. Le CATALOG, ou la base de données▲
Comme nous venons de le définir, le terme CATALOG permet de définir une base de données.
Il n'existe pas d'ordre SQL de création de CATALOG (base de données) dans la norme SQL. La raison en est simple : SQL laisse toute latitude aux éditeurs des SGBD relationnels d'inventer leur propre commande pour ce faire. En effet la définition d'une base de données pose le problème du stockage des données et nécessite donc des paramètres physiques particuliers comme la spécification des espaces de stockage et la manière dont sont journalisées les transactions. Or par principe le langage SQL ne concerne que des objets logiques.
Cependant, la plupart des éditeurs se sont accordés pour prévoir l'ordre CREATE DATABASE afin de générer dans le serveur une base de données.
À titre d'exemple, voici la syntaxe de création d'une base de données et de ses espaces de stockage pour SQL Server :
Exemple 3.5* – Création de bases de données avec définition du stockage pour Microsoft SQL Server
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
CREATE DATABASE B_FORUM
ON PRIMARY
( NAME = F_CATALOG,
FILENAME = 'D:\DATASQL\FORUM\F_CATALOG.D0',
SIZE = 10 GB,
FILEGROWTH = 100 MB ),
FILEGROUP FG_DATA1
( NAME = F_DATA1,
FILENAME = 'E:\DATASQL\FORUM\F_DATA1.D1',
SIZE = 80 GB,
MAXSIZE = 160 GB,
FILEGROWTH = 250 MB ),
( NAME = F_DATA2,
FILENAME = 'E:\DATASQL\FORUM\F_DATA1.D2',
SIZE = 80 GB,
MAXSIZE = 160 GB,
FILEGROWTH = 250 MB ),
FILEGROUP FG_INDEX1
( NAME = F_INDEX1,
FILENAME = 'F:\DATASQL\FORUM\F_INDEX1.I1',
SIZE = 80 GB,
MAXSIZE = 160 GB,
FILEGROWTH = 250 MB )
LOG ON
( NAME = 'F_LOG',
FILENAME = 'G:\LOGSQL\FORUM\F_LOG1.L1',
SIZE = 100 GB)
COLLATE French_CI_AI;
Ceci définit une base de données de nom B_FORUM dont les données sont réparties dans quatre fichiers distincts dont les noms logiques sont F_CATALOG, F_DATA1, F_DATA2, F_INDEX1, associés aux espaces de stockage (file group) PRIMARY, FG_DATA1, FG_INDEX1, dont les fichiers physiques sont situés sur quatre disques différents, le journal de transaction (fichier F_LOG) étant placé sur un cinquième disque. En outre la collation par défaut de cette base sera French_CI_AI.
Plus simplement, pour ce même SGBDR qu’est Microsoft SQL Server, on peut se contenter de la commande :
CREATE DATABASE nom_base ;
Dans ce cas, la base de données SQL Server sera créée avec les paramètres de stockage et de collation hérités de la base template "model". Pour Microsoft SQL Server ce stockage sera constitué de deux fichiers, l’un pour les données, l’autre pour la transaction.
|
|
NOTE |
III-2-3-2. Le SCHEMA, ou module d'une base de données▲
La notion de SCHEMA permet de modulariser une base de données. En fait une base de données (donc un CATALOG selon la norme) comporte au moins un schéma par défaut dans lequel on trouvera les objets de la base (tables, vues, routines...). Comprenez qu'il n'est pas possible de créer une table directement dans le CATALOG, mais qu'il faut passer par le schéma. Ainsi une base de données peut posséder autant de SCHEMA qu'on le désire, chaque schéma pouvant correspondre à un module dans le sens que l'on donne à ce mot pour désigner une bibliothèque de code ou un espace de nom dans un langage itératif. Seule différence avec ces derniers, SQL ne permet qu'un seul niveau de schéma.
Ainsi, dans l'exemple donné ci-avant, la base de données créée comporte automatiquement un schéma.
De fait, une base de données comporte toujours au moins un schéma par défaut. Nous verrons que de manière similaire, tout utilisateur SQL est associé à un schéma par défaut qui peut être différent du schéma par défaut de la base de données (voir chapitre 8).
|
|
ATTENTION |
Les avantages de la notion de SCHEMA sont considérables : outre la modularisation des objets de la base (permettant de la répartir dans différentes « unités » par exemple sur le plan fonctionnel ou encore sur le plan technique), le schéma permet de gérer des privilèges (autorisations) de manière souple et efficace, mais aussi de créer de toutes pièces tous les éléments d'une base de données sans que l'ordre ait une importance.
La figure 3.0b ci-après montre un exemple de base de données avec différents schémas dont certains sont administratifs (en jaune) :
|
|
|
Figure 3.0b – Une base de données et ses schémas |
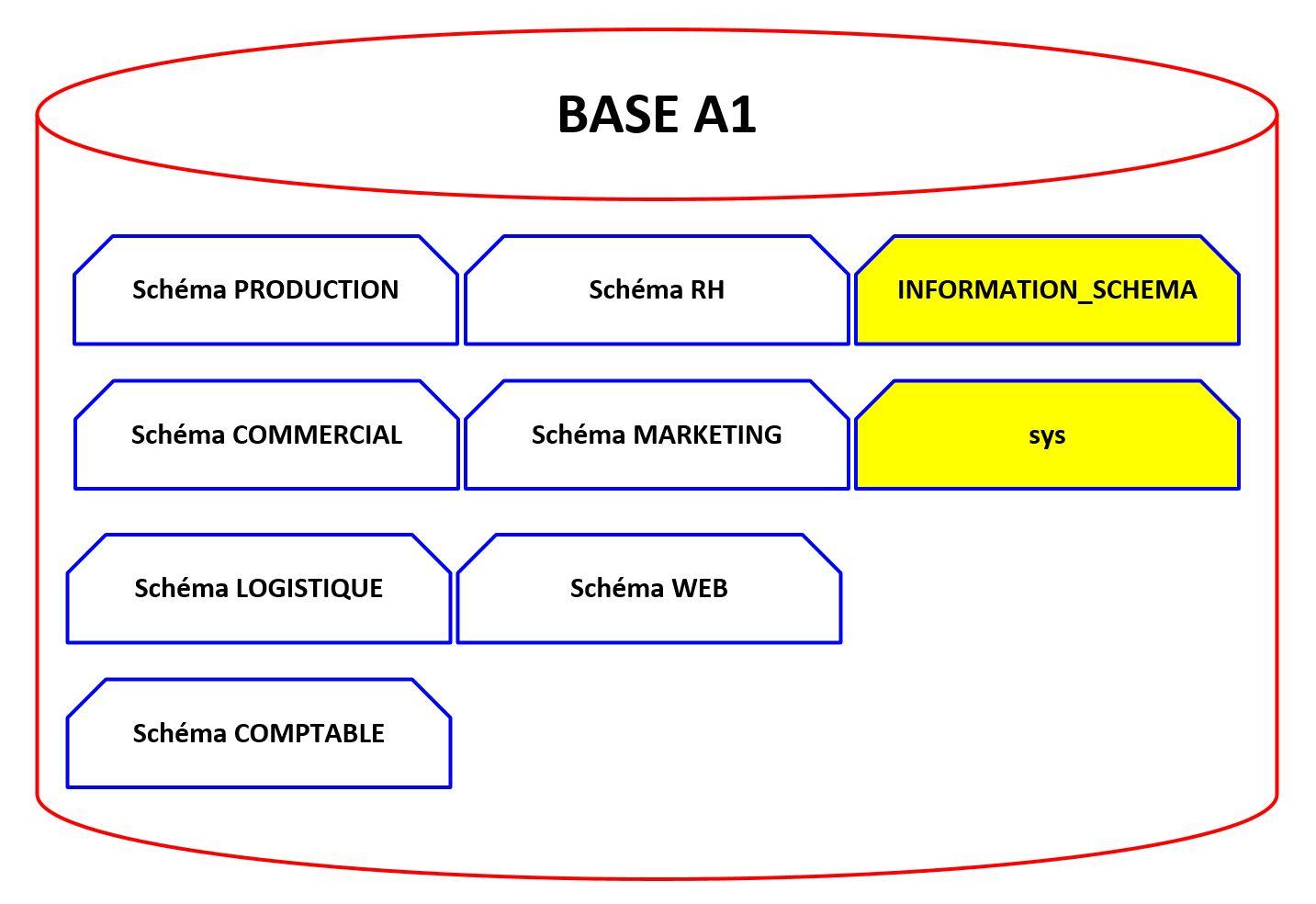
En fait un SCHEMA est un nom logique d'une subdivision d'une base de données (un conteneur) et tout objet d'une base devrait être systématiquement préfixé par le schéma dans lequel il repose.
Notons enfin qu'un schéma appartient toujours à un utilisateur, par défaut celui qui l'a créé.
|
|
ATTENTION |
La commande CREATE SCHEMA est une méta-commande dans le sens ou elle permet de créer de nombreux objets qui, à défaut de préciser le préfixe de schéma, seront créés dans le schéma indiqué par la commande. On peut ainsi commencer par créer un utilisateur et ses privilèges sur une vue qui sera créée après, vue qui elle-même peut précéder la création des tables sur laquelle elle repose. Cette particularité peut paraître surprenante, mais elle possède deux avantages :
- ne pas se soucier de l'ordre de dépendance des objets, et par ce fait permettre de créer des contraintes mutuellement dépendantes ;
- résoudre de fait un problème auquel se heurtent les développeurs débutants : celui de connaître l'ordre de création des tables liées par l'intégrité référentielle...
Notez que cette méta-commande ne peut incorporer que des ordres SQL du DDL (définition des données, tel que CREATE, ALTER ou DROP) mais en aucun cas des ordres du DML (Data Manipulation Language), ne serait-ce que pour ajouter des lignes aux tables (INSERT…).
L'ordre SQL de création d'un schéma revêt la syntaxe suivante :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
CREATE SCHEMA nom_schéma [ AUTHORIZATION propriétaire ]
[ DEFAULT CHARACTER SET jeu_de_caractères ]
[ PATH nom_schéma {, nom_schéma ... } ] ]
[ <objet> | <privilège> [, <objet> | <privilège> ...] ]
<objet> ::=
CREATE { DOMAIN | TABLE | VIEW | ASSERTION |
CHARACTER SET | COLLATION |
TRANSLATION | TRIGGER | TYPE |
PROCEDURE | FUNCTION | ROLE } définition_objet
<privilège> ::=
GRANT définition_privilège
Le propriétaire est en fait l'utilisateur qui créé les objets dans le schéma. Un schéma a toujours un propriétaire.
La clause PATH permet de définir les schémas dans lesquels il faudra rechercher, dans l'ordre de spécification, les différentes routines à utiliser (fonctions, procédures).
|
|
NOTE |
Exemple 3.6* – Création d’un schéma incorporant de nombreux objets
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
CREATE SCHEMA S_COMMERCIAL AUTHORIZATION U_MONA_LISA
DEFAULT CHARACTER SET LATIN1
CREATE VIEW V_CLIENT_CLI
AS
SELECT *
FROM T_CLIENT_CLI
FULL OUTER JOIN T_PROSPECT_PSP
ON T_CLIENT_CLI.PRS_ID = T_PROSPECT_PSP.PRS_ID
CREATE TABLE T_CLIENT_CLI
(PRS_ID INTEGER NOT NULL PRIMARY KEY REFERENCES T_PERSONNE_PRS (PRS_ID),
CLI_NOM VARCHAR(100),
CLI_SIRET CHAR(14) NOT NULL)
CREATE TABLE T_PROSPECT_PSP
(PRS_ID INTEGER NOT NULL PRIMARY KEY REFERENCES T_PERSONNE_PRS (PRS_ID),
PSP_NOM CHAR(16),
PSP_SIRET CHAR(14) NOT NULL)
CREATE TABLE T_PERSONNE_PRS
(PRS_ID INTEGER NOT NULL PRIMARY KEY)
CREATE ASSERTION AK_SIRET
CHECK NOT EXISTS
(SELECT *
FROM T_CLIENT_CLI
INNER JOIN T_PROSPECT_PSP
ON T_CLIENT_CLI.PRS_ID = T_PROSPECT_PSP.PRS_ID
AND T_CLIENT_CLI.CLI_SIRET_ID <> T_PROSPECT_PSP.PSP_SIRET);
Dans cet exemple nous commençons par créer l'objet V_CLIENT qui est une vue basée sur les tables T_CLIENT_CLI et T_PROSPECT_PSP qui n'ont pas encore été créées. Ensuite nous créons les objets table T_CLIENT_CLI et T_PROSPECT_PSP qui référencent la table T_PERSONE_PRS qui n’a pas encore été créée. Enfin nous créons une assertion (contraintes de niveau base) qui vérifie qu’une personne à la fois cliente et prospect dont les informations de numéro de SIRET (identification de l’entreprise) sont renseignées, correspondent bien.
Tous ces objets seront créés dans le schéma S_COMMERCIAL propriété de l’utilisateur U_MONA_LISA (utilisateur SQL supposé pré exister).
Le concept de création de schéma est double : pouvoir décrire toute une base de données sans jamais avoir à se préoccuper du sens dans lequel chaque objet doit être créé du fait des interdépendances, et pouvoir créer des objets mutuellement dépendants. C'est le cas dans notre exemple entre les tables T_CLIENT_CLI et T_PROSPECT_CLI qui se référencent l'une l'autre.
|
|
|
Figure 3.0c – Un schéma SQL et ses différents objets relationnels |
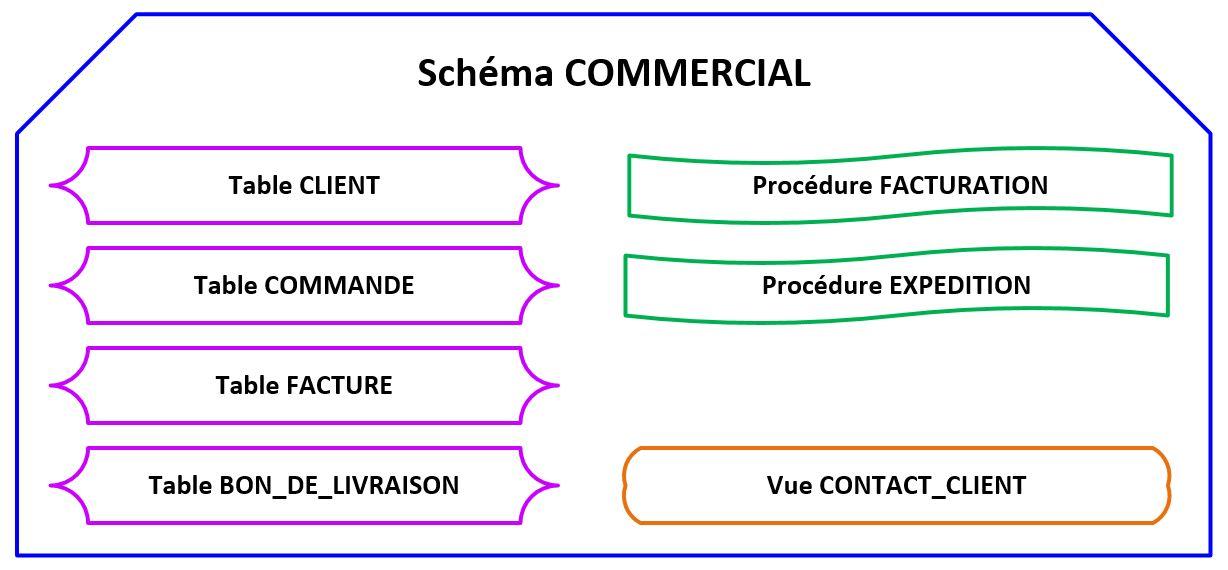
La figure 3.0c ci-avant présente un exemple de schéma SQL de nom « COMMERCIAL » contenant différents objets relationnels (tables, vues, procédures…
Bien entendu SQL propose un ordre de suppression de schéma :
DROP SCHEMA [ nom_schema ] { RESTRICT | CASCADE }
Qui permet de supprimer le schéma courant : s'il ne contient rien à l'aide de l'option RESTRICT, sinon, en détruisant en chaîne tous les objets créés ou référencés dans ce schéma à l'aide de l'option CASCADE. RESTRICT est par défaut.
La navigation à travers les objets dans les différents schémas de la base repose sur trois éléments :
- tout utilisateur est lié à un schéma par défaut ;
- toute base possède un schéma par défaut ;
- à défaut de préciser le schéma dans lequel l'objet repose, c'est le schéma par défaut de l'utilisateur qui est utilisé et si l’objet n’est pas trouvé dans le schéma utilisateur, alors il est cherché dans le schéma par défaut de la base.
Tant est si bien qu'une même table (même nom, voire mêmes colonnes), peut parfaitement être créée dans deux schémas différents.
|
|
NOTE |
|
|
ATTENTION |
III-2-4. La notion de propriétaire▲
Nous verrons au chapitre 8 consacré à la sécurité, ce qu’est la notion de propriétaire, mais disons rapidement que c’est un utilisateur SQL, propriétaire de certains objets, et par conséquent détenant tous les pouvoirs sur tous les objets qu’il créé afin de transmettre ses privilèges et finalement supprimer ces objets. Sans cette notion de propriétaire il serait bien difficile de donner à d’autres utilisateurs des privilèges (droits d’exécuter telle ou telle commande sur tel ou tel objet) et plus encore de prendre la responsabilité de la destruction des objets.
|
|
NOTE |
III-3. Créer des tables▲
Une table peut être créée de manière temporaire (locale ou globale) ou bien durable. Elle possède au moins une colonne, la plupart du temps plusieurs, et d'éventuelles contraintes de table. Les colonnes peuvent être éventuellement contraintes.
Une colonne permet de recevoir une donnée pour chaque ligne de la table. Une contrainte est une règle de vérification d'un prédicat dont le but est d'empêcher certaines actions ou d'obliger à respecter certains critères.
Voici une syntaxe simplifiée de la création de table :
2.
3.
4.
5.
6.
7.
8.
9.
10.
CREATE [ { GLOBAL | LOCAL } TEMPORARY ] TABLE [nom_schema.]nom_table
( <colonne> | <contrainte_de_table>
[ { , <colonne> | <contrainte_de_table> }... ] )
[ ON COMMIT { PRESERVE | DELETE } ROWS ]
<colonne> ::=
nom_colonne { <type> | <domaine> }
[ DEFAULT valeur_default ]
[ <contrainte_de_colonne>. ]
[ COLLATE collation ]
|
|
NOTE |
Cette syntaxe appelle plusieurs remarques :
- une table peut être créée de manière durable (par défaut) ou temporaire (TEMPORARY) et dans ce dernier cas uniquement pour l'utilisateur et la connexion qui l'a créé (LOCAL) ou bien pour l'ensemble des utilisateurs de la base (GLOBAL) ;
- lorsqu'une table est créée de manière temporaire et si elle n'est pas détruite explicitement, elle sera détruite lorsque la session dans laquelle elle a été créée prend fin ;
- une table comporte au moins une colonne et zéro ou plusieurs contraintes de table ;
- une colonne peut être spécifiée d'après un type SQL ou un domaine créé par l'utilisateur ;
- une colonne définie peut être dotée d'une valeur par défaut (DEFAULT) qui peut être une expression de valeur, une fonction SQL système, une fonction utilisateur ou encore le marqueur NULL ;
- une colonne peut être dotée de contraintes de colonnes telles que : obligatoire ou non ( NULL / NOT NULL), clé (PRIMARY KEY), unicité de valeur (UNIQUE), intégrité référentielle (FOREIGN KEY...) et validation (CHECK) ;
- sans spécification NOT NULL par défaut une colonne est « nullable » (NULL) ;
- indépendamment des contraintes de colonne, on peut ajouter des contraintes de table qui porte sur une ou plusieurs colonnes et permettent de définir la clé, l'unicité des valeurs, la validation des données et l'intégrité référentielle au niveau des lignes ;
- on peut spécifier une collation à une colonne de type littéral ;
- l'ensemble formé par les noms des contraintes et des colonnes (identifiant) doit être unique au sein de la table ;
- l'option ON COMMIT... n'est valable que pour les tables temporaires. Avec ...DELETE ROWS, les lignées insérées au cours d'une transaction sont supprimées en fin de transaction. Avec PRESERVE ROWS, les lignes sont conservées (voir au chapitre 7).
Exemple 3.7* – Création d’une table persistante et ses colonnes
2.
3.
4.
5.
6.
CREATE TABLE S_ADM.T_UTILISATEUR_USR
(USR_ID INTEGER,
USR_TITRE CHAR(6),
USR_NOM CHAR(32) COLLATE Latin1_General_CS_AS,
USR_PRENOM VARCHAR(32) COLLATE Latin1_General_CS_AS,
USR_ORGANISATION VARCHAR(128));
Cet exemple créé une table de nom T_UTILISATEUR_USR dans le schéma S_ADM dotée de colonnes dont certaines ont une spécification de collation, les autres colonnes littérales sont basées sur la collation paramétrée au niveau du schéma ou à défaut celle du serveur.
Exemple 3.8* – Création d’une table temporaire et ses colonnes
2.
3.
4.
CREATE LOCAL TEMPORARY TABLE T_BON_CLIENT_BCL
(BCL_NOM VARCHAR(32),
BCL_CREATION DATE,
BCL_REMISE FLOAT);
Cet exemple créé une table temporaire locale de nom T_BONT_CLIENT_BCL dans le schéma par défaut. Elle n'est visible que pour l'utilisateur courant. Elle peut être détruite avant la fin de la session par un ordre explicite de suppression de la table, sinon elle sera détruite en fin de session.
III-3-1. Contraintes de colonne▲
Il n’existe que deux types de contraintes propres aux colonnes :
- la contrainte d’obligation (NOT NULL) ;
- la contrainte de valeur par défaut (DEFAULT …).
Ces contraintes ne portent jamais que sur la définition de la colonne, mais nous devons les assimiler plus globalement aux contraintes de table…
III-3-2. Contraintes de table▲
Une contrainte de table permet de restreindre les conditions d'acceptation des données de la table. Rappelons que, comme pour les contraintes de domaines, dans le cas où une condition de contrainte n'est pas vérifiée, il y a violation de contrainte et le lot de lignes que l'on tentait de mettre à jour (insertion, modification ou suppression) est rejeté en bloc, même si la violation ne porte que sur une seule occurrence d'une seule colonne pour un seule ligne dans un lot comportant de nombreuses lignes.
Les contraintes permettent de rendre la base cohérente en respectant l'intégrité des données.
Outre les contraintes propres aux colonnes que nous avons vu au paragraphe précédent, SQL admet les contraintes suivantes :
- clé primaire (PRIMARY KEY) ;
- clé subrogée, unicité (UNIQUE) ;
- clé étrangère (FOREIGN KEY) ;
- validation de valeur (CHECK).
Nous les avons réparti en deux principales fonctionnalités : les contraintes validant les valeurs d'une colonne (NOT NULL, DEFAULT, CHECK) et les contraintes de clé (PRIMARY KEY, UNIQUE, FOREIGN KEY).
|
|
NOTE
|
|
|
ATTENTION |
Comme nous l'avons fait pour les objets de la base, une bonne habitude consiste à donner un nom pertinent aux contraintes. Vous trouverez en annexe 2 la convention de nommage utilisée pour les contraintes.
III-3-2-1. Contraintes validant les valeurs des colonnes▲
Une contrainte validant les valeurs d'une colonne permet de restreindre les conditions d'acceptation des données dans la ou les colonnes. Lors de la mise à jour des données, la contrainte est appliquée. On dit qu'il y a viol de contrainte lorsque la contrainte n'est pas respectée. Dans ce cas, l'action de mise à jour entreprise est empêchée.
Il y a trois contraintes de valeurs propres : NOT NULL (obligation de valeur), DEFAULT (valeur à défaut) et CHECK (contrôle des valeurs).
La syntaxe de création d'une contrainte validant la valeur propre d'une colonne est la suivante :
2.
3.
4.
5.
<contrainte_de_valeur> ::=
[ CONSTRAINT nom_contrainte]
{ [ NOT ] NULL |
DEFAULT <expression_défaut> |
CHECK ( <expression_validation> ) }
NULL / NOT NULL rend la spécification de valeur obligatoire. DEFAULT exprime qu'en cas d'absence de valeur, alors la valeur de la colonne est calculée par l'expression spécifiée. CHECK permet de valider les valeurs de différentes colonnes à l'aide d'une expression admettant diverses valeurs même calculées provenant d'autres colonnes. Dans ce cas, sa syntaxe revête la forme :
2.
CONSTRAINT nom_contrainte
CHECK ( <expression_validation> )
Nous allons maintenant détailler ces différentes contraintes.
III-3-2-1-1. Obligation de valeur ([NOT] NULL)▲
On peut rendre la saisie d'une colonne obligatoire en apposant le mot clé NOT NULL. Dans ce cas, il ne sera jamais possible de faire en sorte qu'il y ait absence de valeur dans la colonne Autrement dit, la colonne devra toujours être renseignée de manière explicite (expression de valeur) ou implicite (valeur par défaut) lors d'une insertion via l'ordre SQL INSERT. En outre l'application d'une modification de donnée d'une telle colonne, via l'ordre SQL de modification UPDATE, ne peut conduire à l'absence de valeur.
|
|
ATTENTION |
Syntaxe :
[ CONSTRAINT nom_contrainte ] [ NOT ] NULL
Si l'on désire que la colonne puisse ne pas être renseignée (donc accepter les marqueurs NULL), il n'est pas nécessaire de préciser le mot clé NULL, car c'est l'option par défaut, mais il est courant qu'on le fasse par facilité de lecture.
Exemple 3.9* – Création d’une table avec des colonnes ayant une obligation de valeur
2.
3.
4.
5.
6.
7.
CREATE TABLE S_ADM.T_UTILISATEUR_USR
(USR_ID INTEGER NOT NULL,
USR_LOGIN VARCHAR(256) CONSTRAINT NK_MAIL NOT NULL,
USR_TITRE CHAR(6) NULL,
USR_NOM CHAR(32) NULL,
USR_PRENOM VARCHAR(32) NULL,
USR_ORGANISATION VARCHAR(128));
L’exemple 3.9 montre la création d’une table dans le schéma S_ADM dont les colonnes USR_ID et USR_LOGIN doivent obligatoirement être renseignées.
|
|
NOTE |
Le mot clé DEFAULT permet de spécifier une valeur ou toute expression renvoyant une valeur qui sera affectée à une colonne dans le cas ou lors de l'insertion de données il n'est pas fait référence de manière explicite ou implicite à cette colonne. Notons qu’à défaut de contrainte par défaut, le marqueur NULL sera appliqué sauf si la colonne est NOT NULL.
Syntaxe :
[ CONSTRAINT nom_contrainte ] DEFAULT <expression_défaut>
La valeur par défaut d'une colonne peut être une expression de valeur, le marqueur NULL ou encore le résultat d’une fonction niladique (fonctions SQL « système ») comme les quelques-unes figurant dans le tableau 3.2 ci-dessous :
|
Nom fonction |
Description |
|---|---|
|
CURRENT_DATE |
date courante |
|
CURRENT_TIME(p) |
heure courante avec précision p de fractions de seconde |
|
CURRENT_TIMESTAMP(p) |
combiné date heure avec précision p de fractions de seconde |
|
LOCALTIME(p) |
heure locale (par rapport au décalage horaire paramétré dans la session) |
|
LOCALTIMESTAMP(p) |
combiné date & heure locales (par rapport au décalage horaire paramétré dans la session) |
|
USER, CURRENT_USER |
utilisateur courant |
|
SESSION_USER |
utilisateur qui s'est connecté et à initialisé la session (compte de connexion) |
|
Tableau 3.2 – quelques unes des fonctions utiles pour la contrainte de défaut |
|
Il existe de nombreuses autres fonctions qui sont normatives ou bien spécifiques à votre SGBDR.
|
|
NOTE |
De plus, la plupart des SGBDR acceptent des expressions plus complexes pour la spécification d’une valeur par défaut.
Exemple 3.10* – Création d’une table avec des colonnes ayant des valeurs par défaut
2.
3.
4.
CREATE TABLE S_COMMERCIAL.T_CLIENT_CLI
(CLI_NOM VARCHAR(32),
CLI_CREATION DATE DEFAULT CURRENT_DATE,
CLI_REMISE D_POURCENT CONSTRAINT DK_REMISE DEFAULT 10.0);
Cet exemple créé une table de nom T_CLIENT_CLI avec trois colonnes. La colonne CLI_CREATION prend par défaut la valeur de la date courante lors de l'insertion de la ligne.
La colonne CLI_REMISE est spécifiée par un domaine plutôt que par un type SQL et reçoit par défaut la valeur 10. La table créée est située dans le schéma S_COMMERCIAL.
Exemple 3.11* – Création d’une table avec des colonnes ayant des valeurs par défaut
2.
3.
4.
CREATE TABLE S_COMPTA.T_FACTURE_FCT
(FCT_NUMERO INTEGER,
FCT_DATE_EMISSION DATE CONSTRAINT DF_FCT_DTE DEFAULT CURRENT_DATE,
FCT_DATE_PAIEMENT DATE DEFAULT CURRENT_DATE + 30 DAY);
Cet exemple créé une table de nom T_FACTURE_FCT dans le schéma S_COMPTA. La colonne date d'émission est pourvue d'une contrainte nommée DF_FCT_DTE, spécifiant qu'à défaut de valeur, la date du jour est appliquée.
La colonne FCT_DATE_PAIEMENT est pourvue d'une contrainte de défaut anonyme spécifiant qu'à défaut de valeur la date de paiement est calculée sur la date actuelle à laquelle on rajoute 30 jours.
|
|
NOTE |
Ainsi dans notre exemple de définition du domaine D_POURCENT vu au chapitre précédent :
2.
3.
4.
5.
CREATE DOMAIN D_POURCENT
AS FLOAT
DEFAULT 0.0
CHECK (VALUE IS NOT NULL
AND VALUE BETWEEN 0 AND 100)
Malgré que la valeur par défaut du domaine soit de 0, c’est la valeur 10 qui sera insérée dans la colonne CLI_REMISE de la table S_COMMERCIAL.T_CLIENT_CLI, car au niveau de la table, la contrainte de défaut de la table supplante celle du domaine.
III-3-2-1-2. Contrainte de validation (CHECK)▲
Une contrainte de colonne de validation de données CHECK permet de restreindre les valeurs acceptables pour les colonnes visées en appliquant un prédicat. Lorsque le prédicat est évalué à Vrai, l'occurrence est acceptée et la ligne peut être validée. Dans le cas contraire il y a violation de contrainte et les lignes visées par l'ordre SQL sont rejetées.
Une contrainte de validation peut valider une seule colonne ou plusieurs simultanément. Dans le cas où elle vise une seule colonne alors elle peut faire partie intégrante de la définition de la colonne. Dans le cas contraire elle doit être exprimé à la suite de la définition des colonnes de la table.
Lorsque la contrainte ne vise qu'une seule ligne et que sa définition fait partie intégrante de la définition de la colonne, le prédicat peut contenir le mot clé VALUE en lieu et place de la colonne visée, dans une expression booléenne. La contrainte est respectée si le prédicat de validation vaut Vrai. Dans le cas contraire, une exception est levée et la commande de mise à jour est annulée.
Syntaxe de la contrainte de validation :
[ CONSTRAINT nom_contrainte ] CHECK ( <expression_validation> ) }
L'expression booléenne de validation peut contenir :
- des valeurs explicites ;
- le marqueur NULL ;
- des valeurs sous forme de fonctions SQL ou d'UDF (User Define Function) ;
- des opérateurs algébriques (+, -, *, /) ;
- l'opérateur de concaténation de chaîne ( || ) ;
- des opérateurs de comparaison (>, <, >=, <=, <>) ;
- des connecteurs logiques (AND, OR) ;
- l'opérateur de négation (NOT) ;
- la hiérarchisation des opérateurs à l'aide de parenthèses ;
- des expressions SQL spécifiques.
Ainsi que l’ensemble des opérateurs spécifique au SQL suivant :
|
Expression |
Description |
|---|---|
|
BETWEEN |
plage de valeurs |
|
LIKE |
comparaison partielle de chaîne de caractères à l’aide de motifs |
|
IN |
liste de valeur possible |
|
CASE |
branchement de différentes valeurs |
|
SIMILAR |
expression régulière (style SQL) |
|
Tableau 3.3 – Quelques opérateurs utilisables pour les contraintes de validation |
|
Exemple 3.12* – Création d’une table avec des contraintes de validation faisant partie de la définition de la colonne
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
CREATE TABLE S_ADM.T_UTILISATEUR_USR
(USR_NOM CHAR(32)
CONSTRAINT CK_USR_NOM
CHECK (TRANSLATE(VALUE COLLATE French_CI_AI,
'ABCDEFGHIJKLMNOPQRSTUVWXYZ –''',
' ') = ''
AND SUBSTRING(VALUE FROM 1 FOR 1)
NOT IN (' ', '-' , '''')
AND SUBSTRING(VALUE FROM CHARACTER_LENGTH(VALUE) -1 FOR 1)
NOT IN (' ', '-' , '''')
AND VALUE COLLATE French_CS_AI = UPPER(VALUE)),
USR_SEXE CHAR(1)
CHECK (VALUE IN ('H', 'F')),
USR_PASS NVARCHAR(32) NOT NULL
CHECK (CHARACTER_LENGTH(VALUE) >= 8
AND VALUE <> UPPER(VALUE) COLLATE French_CS_AS
AND VALUE <> TRANSLATE(VALUE, '0123456789',
' ')
AND VALUE <> TRANSLATE(VALUE COLLATE French_CI_AS,
'àâäéèêëîïôöùûüÿ',
' ')),
USR_ORGANISATION VARCHAR(128)
CHECK (VALUE COLLATE French_CS_AI = UPPER(VALUE)));
Dans cette table les validations suivantes sont effectuées :
- le nom de l'utilisateur ne doit comprendre que des lettres, ou encore les caractères « » (blanc),.« - » (trait d’union) ou « ‘ » (apostrophe) sauf aux extrémités ;
- le sexe de l'utilisateur peut être H (homme) ou F (femme) ou rester vide ;
- le mot de passe doit comporter au moins : 8 caractères, une majuscule et une minuscule, un chiffre et une lettre accentuée en majuscule ou minuscule ;
- l'organisation doit être spécifiée en majuscule (la fonction SQL UPPER remplace les lettres minuscules en majuscules.
Seule, la première contrainte CHECK a été nommée (CK_USR_NOM) les autres auront un nom décidé par le SGBDR.
Notez l’utilisation des fonctions normalisées suivantes :
- TRANSLATE : substitution de caractères ;
- SUBSTRING : extraction d’une sous-chaîne ;
- CHARACTER_LENGTH : longueur de la chaîne ;
- POSITION : position d’une sous chaîne ;
- UPPER : mise en majuscule.
Ainsi que des opérateurs :
- IN : vérifie qu’une valeur est dans une liste ;
- NOT IN : vérifie qu’une valeur n’est pas dans une liste ;
- COLLATE : impose une collation.
Exemple 3.13* – Création d’une table avec de nombreuses contraintes de validation
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
CREATE TABLE S_COM.T_FACTURE_FCT
(FCT_NUMERO INTEGER,
FCT_MONTANT_TOTAL DECIMAL(16,2),
FCT_DATE_EMISSION DATE,
FCT_DATE_LIMITE_PAIEMENT DATE,
CONSTRAINT CK_FCT_DLM
CHECK (FCT_DATE_LIMITE_PAIEMENT <= FCT_DATE_EMISSION + 30 DAY),
FCT_MODE_PAIEMENT VARCHAR(16)
CHECK(VALUE IN ('CHEQUE', 'ESPECE', 'CARTE BANCAIRE', 'VIREMENT')),
CONSTRAINT CK_FCT_MDP
CHECK ( ( FCT_MODE_PAIEMENT = 'ESPECE'
AND FCT_MONTANT_TOTAL <= 3000 )
OR ( FCT_MODE_PAIEMENT = 'CARTE BANCAIRE'
AND FCT_MONTANT_TOTAL > 15 )));
Cet exemple présente trois contraintes de validation : une est décrite dans la définition de colonne, les deux autres sont décrites spécifiquement en dehors des définitions de colonne.
- La contrainte anonyme CHECK(VALUE IN ('CHÈQUE', 'ESPÈCES', 'CARTE BANCAIRE', 'VIREMENT') oblige la valeur de la colonne FCT_MODE_PAIEMENT à correspondre exclusivement à l'une des quatre mentions CHÈQUE, ESPÈCES, CARTE BANCAIRE ou VIREMENT.
- La contrainte nommée CK_FCT_DLM oblige à ce que la date limite de paiement (colonne FCT_DATE_LIMITE_PAIEMENT) ne dépasse pas 30 jours après la date d'émission de la facture. Bien que portant sur une unique colonne, elle n'a pas été décrite dans la définition de la colonne et ne peut donc bénéficier du mot clé VALUE.
- Plus subtile, la contrainte CK_FCT_MDP oblige que le paiement par espèces soit limité à 3 000 € et celui par carte bancaire supérieur à 15 €. Elle combine les colonnes FCT_MODE_PAIEMENT et FCT_MONTANT_TOTAL.
Notez que cette dernière contrainte vise plusieurs colonnes simultanément. Il n'aurait pas été possible de la décrire dans la spécification d'une quelconque colonne de la table.
|
|
ATTENTION |
Exemple 3.14* – Création d’une table avec une contraintes de validation faisant appel à une table externe
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
CREATE TABLE S_COM.T_CLIENT_CLI
(CLI_NUMERO INTEGER,
CLI_NOM VARCHAR(32),
CLI_REMISE_MAXI_POURCENT FLOAT,
CLI_REMISE_MAXI_MONTANT DECIMAL(16,2));
CREATE TABLE S_COM.T_FACTURE_FCT
(FCT_NUMERO INTEGER,
CLI_NUMERO INTEGER,
FCT_DATE_EMISSION DATE,
FCT_MONTANT_TOTAL_AVANT_REMISE DECIMAL(16,2),
FCT_MONTANT_REMISE_TOTALE DECIMAL(16,2),
CONSTRAINT CK_FCT_REMISES
CHECK (FCT_MONTANT_REMISE_TOTALE
<= (SELECT CLI_REMISE_MAXI_MONTANT
FROM S_COM.T_CLIENT_CLI
WHERE S_COM.T_CLIENT_CLI.CLI_NUMERO
= S_COM.T_FACTURE_FCT.CLI_NUMERO)
AND FCT_MONTANT_REMISE_TOTALE
<= (SELECT CAST(CLI_REMISE_MAXI_POURCENT
* FCT_MONTANT_TOTAL_AVANT_REMISE
/ 100.0 AS DECIMAL(16,2))
FROM S_COM.T_CLIENT_CLI
WHERE S_COM.T_CLIENT_CLI.CLI_NUMERO
= S_COM.T_FACTURE_FCT.CLI_NUMERO)));
La contrainte CK_FCT_REMISES permet de vérifier pour toute commande que la remise ne dépasse ni le montant global de remise prévu pour le client (CLI_REMISE_MAXI_MONTANT) ni le pourcentage maximal de réduction admis pour ce même client CLI_REMISE_MAXI_POURCENT), informations toutes deux situées dans la table des clients.
|
|
NOTE |
Exemple 3.15* – Création d’une table avec des contraintes de validation faisant appel à des UDF
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
CREATE TABLE S_COM.T_PATIENT_PTN
(PTN_NUM_INSEE_SEXE CHAR(1),
PTN_NUM_INSEE_DATE_NAISSANCE CHAR(4),
PTN_NUM_INSEE_COMMUNE CHAR(5),
PTN_NUM_INSEE_RANG CHAR(3),
PTN_CLE_INSEE CHAR(2),
PTN_NOM CHAR(32),
PTN_PRENOM VARCHAR(25),
CONSTRAINT CK_PTN_NNI
CHECK (S_ROUTINES.F_VALIDE_NNI(PTN_NUMERO_INSEE_SEXE,
PTN_NUM_INSEE_DATE_NAISSANCE,
PTN_NUM_INSEE_COMMUNE,
PTN_NUM_INSEE_RANG,
PTN_CLE_INSEE)),
CONSTRAINT CK_PTN_NOM
CHECK (S_ROUTINES.F_VALIDE_NOM(PTN_NOM, 'MAJUSCULES')),
CONSTRAINT CK_PTN_PRENOM
CHECK (S_ROUTINES.F_VALIDE_NOM(PTN_NOM, 'INITMAJ')));
Cet exemple présente trois contraintes de validation faisant appel à des fonctions utilisateur (UDF), c'est à dire à des routines spécifiquement écrites pour un traitement particulier.
À la lecture de la définition de cette table on peut en déduire que :
- la cohérence du numéro national d'identité (vulgairement appelé numéro de sécurité sociale) est vérifié par la routine S_ROUTINES.F_VALIDE_NNI du schéma S_ROUTINES ;
- le nom du patient doit respecter certaines règles (par exemple commencer par une lettre et pour le reste, n'être composé que des caractères A à Z et leurs déclinaisons avec accents, ainsi que les caractères espace, tiret, apostrophe) et figurer en majuscule, ceci étant obtenu à l'aide de la routine S_ROUTINES.F_VALIDE_NOM du schéma S_ROUTINES ;
- le prénom du patient obéira aux mêmes règles que ci dessus mais en autorisant un mélange de majuscule et minuscule avec que, seules les premières lettres de chaque partie du prénom seront en majuscules et les autres en minuscules).
III-3-2-2. Contrainte de clé▲
Une contrainte de clé permet de restreindre les valeurs des données de différentes colonnes par rapport à un ensemble de données pris dans l'intégralité des lignes d'une table. De la même façon que pour les précédentes contraintes, lors de la mise à jour des données, la contrainte est appliquée. On dit qu'il y a viol de contrainte lorsque la contrainte n'est pas respectée. Dans ce cas, l'action de mise à jour entreprise est empêchée.
Il y a trois contraintes de clé : PRIMARY KEY (clé primaire), UNIQUE (clé subrogée ou candidate) et FOREIGN KEY (clé étrangère).
La syntaxe de création d'une contrainte de clé est la suivante :
Exprimée dans la définition de la colonne :
2.
3.
4.
5.
<contrainte_de_clé> ::=
[ CONSTRAINT nom_contrainte ]
{ PRIMARY KEY |
UNIQUE |
[FOREIGN KEY ] REFERENCES <table_mere> ( <colonne_de_référence> ) }
Exprimée en tant que contrainte libre :
2.
3.
4.
5.
6.
7.
8.
9.
<contrainte_de_clé> ::=
[ CONSTRAINT nom_contrainte ]
{ PRIMARY KEY ( <liste_colonne> ) |
UNIQUE ( <liste_colonne> ) |
FOREIGN KEY ( <liste_colonne> )
REFERENCES <table_mere> ( <liste_colonnes_de_référence> )
[ <clause_de_validation> ]
[ <clause_de_gestion_modification> ]
[ <clause_de_gestion_suppression> ] }
Nous allons maintenant détailler ces différentes contraintes.
III-3-2-2-1. Contrainte de clé primaire (PRIMARY KEY)▲
La contrainte de clé primaire PRIMARY KEY, aussi appelée plus simplement clé de la table, concerne, la, ou les colonnes, dont les valeurs serviront à identifier de manière unique une ligne de la table. Si la clé primaire est composée d’une unique colonne, alors les valeurs contenues dans cette colonne doivent être toutes différentes. Si la clé primaire est composée de plusieurs colonnes, alors la combinaison des valeurs de ces colonnes prise dans une même ligne doit être unique. Elles doivent toujours être renseignées (le marqueur NULL n'est pas accepté dans de telles colonnes).
Syntaxe exprimée dans la définition de la colonne :
[ CONSTRAINT nom_contrainte ] PRIMARY KEY
Syntaxe exprimée en tant que contrainte libre :
[ CONSTRAINT nom_contrainte ] PRIMARY KEY ( <liste_colonne> )
Exemple 3.16* – Création d’une table avec une contrainte de clé primaire
2.
3.
CREATE TABLE S_ADM.T_UTILISATEUR_USR
(USR_ID INTEGER NOT NULL CONSTRAINT PK_USR PRIMARY KEY,
USR_LOGIN VARCHAR(256) NOT NULL);
Créée une table dont la colonne USR_ID est la clé de la table. Cette contrainte de clé primaire est nommée PK_USR.
Notez que cet exemple est strictement similaire à l’exemple suivant :
2.
3.
CREATE TABLE S_ADM.T_UTILISATEUR_USR
(USR_ID INTEGER CONSTRAINT PK_USR PRIMARY KEY,
USR_LOGIN VARCHAR(256) NOT NULL);
En effet, de facto, la contrainte PRIMARY KEY appliquée à la colonne entraîne obligatoirement la contrainte d’obligation de valeur (NOT NULL). Il n’est donc pas obligatoire de la mentionner explicitement.
Exemple 3.17* – Création d’une table avec une contrainte de clé primaire multi-colonne
2.
3.
4.
5.
CREATE TABLE S_GEO.T_COMMUNE_CMN
(CMN_CODE_DEPARTEMENT VARCHAR(3) NOT NULL,
CMN_CODE_COMMUNE VARCHAR(3) NOT NULL,
CMN_NOM VARCHAR(64),
CONSTRAINT PK_CMN (CMN_CODE_DEPARTEMENT, CMN_CODE_COMMUNE));
Créé une table dont les colonnes CMN_CODE_DEPARTEMENT et CMN_CODE_COMMUNE constituent la clé de la table. Cette contrainte de clé primaire est nommée PK_CMN.
|
|
NOTE
|
III-3-2-2-2. Contrainte de clé subrogée (ou alternative – UNIQUE)▲
La contrainte de clé subrogée ou alternative (les deux termes étant similaires) impose que les occurrences de toutes les valeurs renseignées des colonnes définissant la contrainte UNIQUE soient différentes, autrement dit qu'il n'y ait pas de doublons. À l'exception du marqueur NULL, qui peut être présent plusieurs fois ou non, il ne doit jamais y avoir plus d'une fois la même valeur dans les colonnes de la table.
Syntaxe exprimée dans la définition de la colonne :
[ CONSTRAINT nom_contrainte ] UNIQUE [ NULLS [ NOT ] DISTINCT ]
Syntaxe exprimée en tant que contrainte libre :
2.
[ CONSTRAINT nom_contrainte ]
UNIQUE [ NULLS [ NOT ] DISTINCT ] ( <liste_colonne> )
L’option NULLS … DISTINCT est apparue avec la version 2023 de la norme SQL et se comporte comme suit :
- NULLS DISTINCT considère que toute valeur non exprimée est toujours différente de tout autre valeur. Pour l’exprimer différemment, tout marqueur NULL est toujours distinct de tout autre marqueur NULL.
- NULLS NOT DISTINCT considère que l’absence de valeur doit être considérée comme une valeur à distinguer des autres. Pour l’exprimer différemment, tout marqueur NULL est égal à tout autre marqueur NULL
À l’origine, certains SGBDR ont considéré que les NULLs devaient être distincts comme c’est le cas de MySQL/MariaDB et PostGreSQL tandis que d’autres comme d’Oracle Database et Microsoft SQL Server ont considéré que les NULLs étaient égaux.
Exemple 3.18* – Création d’une table avec contrainte de clé primaire et contrainte d’unicité :
2.
3.
4.
CREATE TABLE S_ADM.T_UTILISATEUR_USR
(USR_ID INTEGER NOT NULL PRIMARY KEY,
USR_NOM CHAR(32) NOT NULL,
USR_LOGIN VARCHAR(256) UNIQUE);
Créé une table dont la colonne USR_LOGIN peut être non renseignée, ou bien contenir une valeur distincte de toutes les autres valeurs déjà présentes. Notons en outre que la clé de cette table est implicitement dotée d'une contrainte d'unicité.
|
|
NOTE
|
Exemple 3.19* – Création d’une table avec une contrainte de clé primaire et une contrainte d’unicité multicolonne et deux contraintes d’unicité mono-colonne
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
CREATE TABLE S_RH.T_EMPLOYE_EMP
(EMP_ID INT NOT NULL PRIMARY KEY,
EMP_NUM_INSEE_SEXE CHAR(1),
EMP_NUM_INSEE_DATE_NAISSANCE CHAR(4),
EMP_NUM_INSEE_COMMUNE CHAR(5),
EMP_NUM_INSEE_RANG CHAR(3),
EMP_CLE_INSEE CHAR(2),
CONSTRAINT UK_EMP_NNI
UNIQUE(EMP_NUM_INSEE_SEXE,
EMP_NUM_INSEE_DATE_NAISSANCE,
EMP_NUM_INSEE_COMMUNE,
EMP_NUM_INSEE_RANG),
EMP_NOM CHAR(32),
EMP_PRENOM VARCHAR(25),
EMP_MATRICULE SMALLINT UNIQUE,
EMP_LOGIN VARCHAR(256) UNIQUE,
EMP_SOIGNANT BOOLEAN,
EMP_RPPS CHAR(12),
UNIQUE (EMP_SOIGNANT, EMP_RPPS);
Une table des employés avec trois clés subrogées : l'une concerne le numéro national d'identité (dit « numéro de sécurité sociale ») composé de quatre colonnes distinctes, l'autre le matricule et la troisième, un booléen indiquant s’il est soignant et le numéro RPPS du professionnel de santé (il s’agit d’employés d’un hôpital…).
|
|
ATTENTION |
III-3-2-2-3. Contrainte de clé étrangère (FOREIGN KEY)▲
La contrainte de clé étrangère est le moyen par lequel on référence les tables du modèle relationnel entres elles. Une telle contrainte permet, pour les valeurs de la table fille, de vérifier si elles sont référencées dans les colonnes d'une contrainte clé primaire ou subrogée/alternative fixée dans la table mère. Ce mécanisme s'appelle l'intégrité référentielle déclarative.
Il existe un autre moyen de garantir cette intégrité en passant par le biais de déclencheurs. C’est l’intégrité référentielle procédurale. Elle est plus complexe et moins performante, raison pour laquelle nous la déconseillons. Elle sera néanmoins abordée au chapitre 7 à titre d’exemple.
Une table mère, pour figurer dans une intégrité référentielle d'une la table fille, doit impérativement être pourvue d'une clé primaire ou d'une contrainte d'unicité.
Il faut comprendre en fait qu'une contrainte de clé étrangère se greffe sur une contrainte de clé primaire ou de clé subrogée par le biais de la liste de ses colonnes.
Syntaxe exprimée dans la définition de la colonne :
2.
3.
4.
5.
[ CONSTRAINT nom_contrainte ]
[FOREIGN KEY ] REFERENCES <table_mere> ( <colonne_de_référence> )
[ <clause_de _validation> ]
[ <clause_de _gestion_modification> ]
[ <clause_de _gestion_suppression> ]
Syntaxe exprimée en tant que contrainte libre :
2.
3.
4.
5.
6.
CONSTRAINT nom_contrainte
FOREIGN KEY ( <liste_colonne> )
REFERENCES <table_mere> ( <liste_colonnes_de_référence> )
[ <clause_de _validation> ]
[ <clause_de _gestion_modification> ]
[ <clause_de _gestion_suppression> ]
De manière générale, les contraintes d’intégrité référentielle déclarative (FOREIGN KEY … REFERENCES), c’est-à-dire les contraintes de clés étrangères obéissent aux règles suivantes :
- pour insérer ou modifier une valeur de colonne pourvue d'une clé étrangère, la valeur doit exister préalablement dans la table mère. Dans le cas contraire il y a violation de contrainte ;
- le type de données de la colonne cible (table fille) et de la colonne source (table mère) doit être le même ;
- les noms des colonnes cibles et sources de l'intégrité référentielle peuvent être différents, mais il est conseillé qu'elles portent le même nom car elles ont sémantiquement la même signification (cela résulte de la modélisation conceptuelle des données). Dans le cas contraire il ne sera pas possible d'utiliser la technique du NATURAL JOIN (voir chapitre 5) ;
- si la clé étrangère porte sur plusieurs colonnes, le rang de chacune des colonnes dans la liste doit être le même dans la définition de la contrainte d’unicité (PRIMARY KEY ou UNIQUE) dans la table mère comme dans la table fille (dans la liste des colonnes de la contrainte FOREIGN KEY) ;
- en cas de suppression ou de modification de la clé primaire de la ligne référencée dans la table mère, il se peut qu'une violation de contrainte se produise, cela dépend de la façon dont l'intégrité référentielle est gérée.
|
|
NOTE |
Exemple 3.20* – Création d’une table avec une contrainte de clé étrangère
2.
3.
4.
5.
6.
7.
8.
CREATE TABLE S_ADM.T_PRENOM_PRN
(PRN_ID INTEGER NOT NULL PRIMARY KEY,
PRN_PRENOM_USUEL VARCHAR(32) NOT NULL UNIQUE)
CREATE TABLE S_ADM.T_UTILISATEUR_USR
(USR_NOM CHAR(32) NOT NULL,
PRN_ID INTEGER
REFERENCES S_ADM.T_PRENOM_PRN (PRN_ID))
Dans la table des utilisateurs, nous faisons référence pour la colonne PRN_ID à une valeur clé de la table des prénoms. Cela permet d'aller chercher le prénom de l'utilisateur dans la table des prénoms si la colonne PRN_ID de la table des utilisateurs est renseignée.
Exemple 3.21* – Création de différentes tables avec de nombreuses contraintes
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
61.
62.
63.
64.
65.
66.
67.
68.
CREATE TABLE S_HOPITAL.T_PERSONNE_PHYSIQUE_PPS
(PPS_ID INT NOT NULL PRIMARY KEY,
PPS_NOM CHAR(32) NOT NULL,
PPS_PRENOM VARCHAR(25));
CREATE TABLE S_HOPITAL.T_PATIENT_PAT
(PRS_ID INT NOT NULL PRIMARY KEY
REFERENCES S_HOPITAL.T_PERSONNE_PHYSIQUE_PPS (PPS_ID),
PPS_NUM_INSEE_SEXE CHAR(1) NOT NULL,
PPS_NUM_INSEE_DATE_NAISSANCE CHAR(4) NOT NULL,
PPS_NUM_INSEE_COMMUNE CHAR(5) NOT NULL,
PPS_NUM_INSEE_RANG CHAR(3) NOT NULL,
CONSTRAINT UK_EMP_NNI
UNIQUE(PPS_NUM_INSEE_SEXE,
PPS_NUM_INSEE_DATE_NAISSANCE,
PPS_NUM_INSEE_COMMUNE,
PPS_NUM_INSEE_RANG),
PAT_DATE_NAISSANCE DATE NOT NULL);
CREATE TABLE S_HOPITAL.T_SOIGNANT_TYPE_SGT
(SGT_ID INT NOT NULL PRIMARY KEY,
SGT_LIBELLE VARCHAR(32) NOT NULL UNIQUE);
CREATE TABLE S_HOPITAL.T_SOIGNANT_SPECIALITE_SST
(SST_ID INT NOT NULL PRIMARY KEY,
SST_LIBELLE VARCHAR(32) NOT NULL UNIQUE);
CREATE TABLE S_HOPITAL.T_SOIGNANT_SGN
(PRS_ID INT NOT NULL PRIMARY KEY
REFERENCES S_HOPITAL.T_PERSONNE_PHYSIQUE_PPS (PPS_ID),
SGT_ID INT NOT NULL
REFERENCES S_HOPITAL.T_SOIGNANT_TYPE_SGT (SGT_ID),
SST_ID INT
REFERENCES S_HOPITAL.T_SOIGNANT_SPECIALITE_SST (SST_ID),
CONSTRAINTS CK_SGN_SI_MEDECIN
CHECK (SST_ID IS NULL
AND SGT_ID = (SELECT SGT_ID
FROM S_HOPITAL.T_SOIGNANT_TYPE_SGT
WHERE SGT_LIBELLE <> 'Médecin')
OR SST_ID IS NOT NULL
AND SGT_ID = (SELECT SGT_ID
FROM S_HOPITAL.T_SOIGNANT_TYPE_SGT
WHERE SGT_LIBELLE = 'Médecin')) ,
SGN_RPPS CHAR(12) UNIQUE);
CREATE TABLE S_HOPITAL.T_ORDONANCE_ODC
(ODC_ID INT NOT NULL PRIMARY KEY,
ODC_DATE DATE NOT NULL DEFAULT CURRENT_DATE,
PPS_NUM_INSEE_SEXE CHAR(1) NOT NULL,
PPS_NUM_INSEE_DATE_NAISSANCE CHAR(4) NOT NULL,
PPS_NUM_INSEE_COMMUNE CHAR(5) NOT NULL,
PPS_NUM_INSEE_RANG CHAR(3) NOT NULL,
SGN_RPPS CHAR(12) NOT NULL
REFERENCES S_HOPITAL.T_SOIGNANT_SGN (SGN_RPPS)
CHECK (VALUE IN (SELECT SGN_RPPS
FROM S_HOPITAL.T_SOIGNANT_SGN
WHERE SGT_ID = (SELECT SGT_ID
FROM S_HOPITAL.T_SOIGNANT_TYPE_SGT
WHERE SGT_LIBELLE = 'Médecin'))),
FOREIGN KEY (PPS_NUM_INSEE_SEXE,
PPS_NUM_INSEE_DATE_NAISSANCE,
PPS_NUM_INSEE_COMMUNE,
PPS_NUM_INSEE_RANG)
REFERENCES S_HOPITAL.T_PATIENT_PAT
(PPS_NUM_INSEE_SEXE,
PPS_NUM_INSEE_DATE_NAISSANCE,
PPS_NUM_INSEE_COMMUNE,
PPS_NUM_INSEE_RANG));
La table des personnes physiques sert de référence aux tables des patients et des soignants. Les soignants font référence à leur type (infirmier, kiné, médecin…) et la contrainte de validation CK_SGN_SI_MEDECIN qui impose que les médecins aient une spécialité ce qui est paradoxalement une contrainte d’intégrité référentielle partielle formée par une contrainte CHECK… Enfin dans la table des ordonnances figure deux contraintes de clé étrangères l’une portant sur le numéro INSEE de sécurité sociale du patient et l’autre sur le numéro RPPS du soignant.
Notez enfin que la contrainte de clé étrangère portant sur la colonne SGN_RPPS est redondante avec la contrainte CHECK afférente à cette même colonne, mais que l’inverse n’est pas vrai, étant entendu que la contrainte de validation vérifie l’existance de la valeur d’un RPPS dans la table des soignants, uniquement s’il est médecin…
Le fait que des tables se référencent entres elles posent le problème de la précédence de l’insertion des données. Ainsi avant d’insérer une nouvelle facture, donc une ligne dans la table des factures pour un nouveau client, il faudra préalablement créer le client en insérant une ligne dans la table des clients.
L’exemple 3.22 montre un scénario typique d’ordonnancement des insertions de lignes dans différentes tables liées par l’intégrité référentielle.
Exemple 3.22* – Insertion des lignes dans l’ordre logique pour les différentes tables ayant des contraintes d’intégrité référentielle
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
INSERT INTO S_HOPITAL.T_PERSONNE_PHYSIQUE_PPS VALUES
(1, 'PARÉ', 'Ambroise'), (2, 'CHARCOT', 'Jean-Martin'),
(3, 'SCHWEITZER', 'Albert'), (4, 'BARNARD', 'Christiaan'),
(5, 'ALZHEIMER', 'Aloïs'), (6, 'FLEMMING', 'Alexander'),
(7, 'FREUD', 'Sigmund'), (8, 'HIPPOCRATE', NULL),
(9, 'KOCH', 'Robert'), (10, 'PAVLOV', 'Ivan'),
(11, 'MORIN', 'Marie'), (12, 'LADOIX', 'Albert'),
(13, 'DUPONT', 'Patrick'), (14, 'DUPONT', 'Marc'),
(15, 'ROUX', 'Paul'), (16, 'GENTILUCI', 'Maurizio'),
(17, 'BEN BOUZA', 'Mounir'), (18, 'KLEIN', 'Maurice'),
(19, 'SANCHEZ', 'Manuel'), (20, 'MAC CULLOCH', 'Kenneth');
2.
3.
INSERT INTO S_HOPITAL.T_PATIENT_PAT VALUES
(17, '2', '8812', '43120', '007', '1988-12-20'),
(20, '1', '6001', '75112', '124', '1960-01-13');
2.
INSERT INTO S_HOPITAL.T_SOIGNANT_TYPE_SGT VALUES
(201, 'Médecin'), (202, 'Kiné'), (203, 'Infirmier');
2.
3.
4.
INSERT INTO S_HOPITAL.T_SOIGNANT_SPECIALITE_SST VALUES
(311, 'Urologue'), (312, 'Gastro-enterologue'),
(313, 'Gynécologue'), (314, 'Neurologue'),
(316, 'Orthopédiste'), (317, 'Pédiatre');
2.
3.
INSERT INTO S_HOPITAL.T_SOIGNANT_SGN VALUES
(1, 201, 316, '14578415'), (2, 201, 314, '12548785'),
(11, 203, NULL, '74519854'), (12, 202, NULL, '65875414');
2.
3.
4.
INSERT INTO S_HOPITAL.T_ORDONANCE_ODC VALUES
(1001, '2022-12-08', '2', '8812', '43120', '007', '14578415'),
(1002, '2021-09-16', '2', '8812', '43120', '007', '14578415'),
(1003, '2022-12-05', '1', '6001', '75112', '124', '12548785');
Les insertions doivent se faire dans cet ordre précis, sinon il y aurait viol de l’intégrité référentielle. Pour la suppression, l’ordre logique d’exécution des requête doit être inversé. Par exemple :
2.
3.
4.
5.
6.
DELETE FROM S_HOPITAL.T_ORDONANCE_ODC;
DELETE FROM S_HOPITAL.T_SOIGNANT_SGN;
DELETE FROM S_HOPITAL.T_SOIGNANT_SPECIALITE_SST;
DELETE FROM S_HOPITAL.T_SOIGNANT_TYPE_SGT;
DELETE FROM S_HOPITAL.T_PATIENT_PAT;
DELETE FROM S_HOPITAL.T_PERSONNE_PHYSIQUE_PPS;
III-4. Gestion de l'intégrité référentielle▲
La contrainte de type FOREIGN KEY permet de mettre en place une intégrité référentielle entre une (ou plusieurs) colonne(s) d'une table et la (ou les) colonne(s) en regard composant la clé d'une autre table (la table de référence) afin de garantir les dépendances existantes et permettant d’assurer la jointure « naturelle » entre les tables dans la requête selon le modèle relationnel que l'on a défini. On parle alors de relation maître/esclave, parent/enfant ou mère/fille.
|
|
|
Figure. 3.1 : Intégrité référentielle entre la table mère des clients et la table fille des factures. |
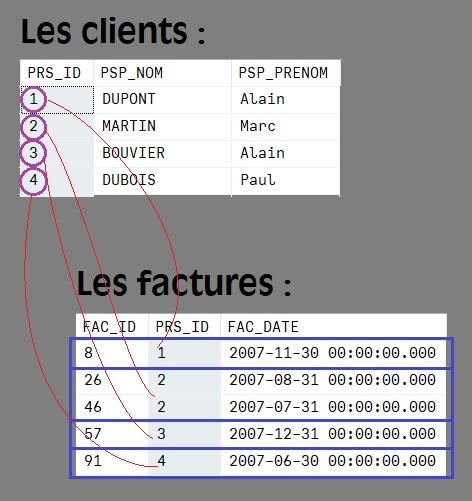
Le but de l'intégrité référentielle est de maintenir les « liens » d’intégrité entre les tables quelque soient les modifications engendrées sur les données dans l'une ou l'autre table.
Cette intégrité référentielle est validée lors de l'insertion grâce à la clause MATCH de la contrainte et maintenue au cours de la vie des données par les clauses ON DELETE et ON UPDATE lors des modifications de clés ou suppressions de lignes.
Voici une syntaxe plus complète de la contrainte de clé étrangère avec les clauses de validation et de gestion de l'intégrité référentielle :
2.
3.
4.
5.
6.
CONSTRAINT nom_contrainte
FOREIGN KEY ( <liste_colonne_table> )
REFERENCES table_référencée ( <liste_colonne_référencées> )
[ MATCH { FULL | PARTIAL | SIMPLE } ]
[ ON UPDATE { NO ACTION | RESTRICT | CASCADE | SET NULL | SET DEFAULT } ]
[ ON DELETE { NO ACTION | RESTRICT | CASCADE | SET NULL | SET DEFAULT } ]
Nous allons maintenant détailler les différentes clauses de cette contrainte, à savoir :
- la clause MATCH de validation de la référence ;
- la clause ON UPDATE de gestion de la mise à jour ;
- la clause ON DELETE de gestion de la suppression.
En fait il faut considérer que la clause MATCH précise comment se comporte l'insertion ou la mise à jour dans la table fille, tandis que les clauses ON DELETE / ON UPDATE concernent le comportement des données dans la table fille lorsque les références des valeurs de clés de la table mère changent ou sont supprimées.
Autrement dit la clause MATCH, de validation, se voit du point de vue de la table qui utilise la référence (table fille) tandis que les clauses ON DELETE / ON UPDATE, de gestion, se voient du point de vue de la table référencée (table mère).
III-4-1. Mode de validation de la référence, clause MATCH▲
La clause MATCH n’a d’intérêt que si la clé étrangère est composée de plusieurs colonnes. Elle précise la manière dont la contrainte valide ou refuse l'opération d'insertion ou de mise à jour en fonction des colonnes en jeu lorsque les valeurs de certaines colonnes sont manquantes (marqueurs NULL).
MATCH SIMPLE implique que :
- la contrainte s'applique si toutes les colonnes de la clé étrangère sont renseignées ;
- si une colonne au moins possède un marqueur NULL, la contrainte de clé étrangère ne s'applique pas.
Il y a donc violation de contrainte si les valeurs divergent et qu'elles sont toutes renseignées. Dans le cas ou une colonne n’est pas renseignée, la contrainte est ignorée.
MATCH PARTIAL implique que :
- La contrainte de clé étrangère s'applique pour toutes les colonnes renseignées, c’est-à-dire qu’il doit exister au moins une ligne dans la table de référence qui vérifie toutes les valeurs des colonnes renseignées.
Il y a donc violation de la contrainte si au moins une valeur renseignée diverge.
MATCH FULL implique que :
- Les colonnes composant la clé doivent être toutes vides (NULL) ou toutes renseignées, et dans ce dernier cas seulement, la référence est vérifiée.
Il y a donc violation de la contrainte si les valeurs divergent ou si une colonne est renseignée et l'autre pas.
A défaut de la spécifier c'est l'option MATCH SIMPLE qui s'impose par défaut.
|
|
NOTE |
Pour mieux comprendre le fonctionnement de cette clause, les exemples 3.23 à 3.25 montrent un modèle constitué d’une table mère (calendrier), d’une table fille (faits historiques) et une tentative d’insertion de lignes dans la table des événements de l’Histoire…
Exemple 3.23* – Une table de référence avec une contrainte UNIQUE multicolonne
2.
3.
4.
5.
6.
CREATE TABLE S_TALLY.T_CALENDRIER_CLD
(CLD_DATE DATE PRIMARY KEY,
CLD_AN SMALLINT NOT NULL CHECK(VALUE BETWEEN 1 AND 9999),
CLD_MOIS SMALLINT NOT NULL CHECK(VALUE BETWEEN 1 AND 12),
CLD_JOUR SMALLINT NOT NULL CHECK(VALUE BETWEEN 1 AND 31),
CONSTRAINT UK_CLD_AN_MOIS_JOUR UNIQUE (CLD_AN, CLD_MOIS, CLD_JOUR)) ;
Supposons que la table S_TALLY.T_CALENDRIER_CLD soit remplie avec toutes les données des dates des années de 1900 à l’an 2000, les colonnes CLD_AN, CLD_MOIS et CLD_JOUR étant respectivement, l’année, le mois et le jour du mois de chaque CLD_DATE… :
Et une table de faits historiques constituée comme montre l’exemple 3.24 :
Exemple 3.24* – Table de faits historiques faisant référence aux dates d’une table de calendrier
2.
3.
4.
5.
6.
7.
8.
9.
CREATE TABLE S_HISTORY.T_EVENEMENT_EVT
(EVT_ID INTEGER PRIMARY KEY,
CLD_AN SMALLINT,
CLD_MOIS SMALLINT,
CLD_JOUR SMALLINT,
EVT_DESCRIPTION VARCHAR(256) NOT NULL,
CONSTRAINT FK_EVT_AN_MOIS_JOUR
FOREIGN KEY (CLD_AN, CLD_MOIS, CLD_JOUR)
REFERENCES S_TALLY.T_CALENDRIER_CLD (CLD_AN, CLD_MOIS, CLD_JOUR));
Si la contrainte FK_EVT_AN_MOIS_JOUR est en MATCH SIMPLE, alors les insertions suivantes sont possibles :
Exemple 3.25* – Tentatives d’insertion dans la table des faits historiques liée par intégrité référentielle à la table de calendrier
2.
3.
4.
5.
6.
INSERT INTO S_HISTORY.T_EVENEMENT_EVT VALUES
(1, 1969, 7, 20, 'Premier pas de l''homme sur la lune'),
(2, 1945, 8, 6, 'Explosion de la bombe atomique à Hiroshima, Japon'),
(3, NULL, NULL, NULL, 'J.-M. Le Pen devient Président de la République'),
(4, NULL, 25, 212, 'Disparition d''Harry Potter dans la 4e dimension'),
(5, 1968, 5, NULL, 'Manifestations d''étudiants et grèves générales');
Si la contrainte FK_EVT_AN_MOIS_JOUR est en MATCH PARTIAL, alors la quatrième ligne (disparition d’Harry Potter) fait échouer le lot de requête car un mois 25 comme un jour de mois 212 n’existe pas.
Si la contrainte FK_EVT_AN_MOIS_JOUR est en MATCH FULL, alors la quatrième ligne (disparition d’Harry Potter) comme la cinquième ligne (Mai 68) font échouer le lot de requête car la clé étrangère est partiellement vide.
Rares sont les SGBDR qui en pratique mettent en œuvre toutes les options possibles de l’option MATCH pour la validation des références. En l’absence de cette clause, il est possible de programmer des déclencheurs car l’intégrité référentielle, comme nous l’avons déjà dit, peut être réalisée de manière procédurale… Nous verrons un tel cas au chapitre 7.
III-4-2. Mode de gestion de l'intégrité, clauses ON UPDATE / ON DELETE▲
Au cours de la vie de la base de données, il est possible que l'on soit amené à supprimer la ligne qui sert de référence (DELETE), comme à en modifier la valeur de la clé (UPDATE). Une telle manipulation des données de la table mère n'est pas sans conséquence dans le maintient de l'intégrité référentielle en regard des lignes des tables filles.
Le mode de gestion de l'intégrité consiste à se poser la question de la règle qui doit être mise en œuvre dans le cas ou l'on tente de modifier les données de référence qu’utilise différentes intégrités référentielles.
Les différents modes de gestion de l'intégrité référentielle que propose SQL sont les suivants :
NO ACTION, RESTRICT, CASCADE, SET DEFAULT, SET NULL et ne peuvent s'appliquer qu'aux ordres SQL UPDATE (modification de données) et DELETE (suppression de lignes).
ON DELETE NO ACTION / ON UPDATE NO ACTION :
Toute action de modification de clé ou de suppression de ligne dans la table mère échoue pour les lignes en relation d'intégrité référentielle entre table mère et fille.
Dans le cas du NO ACTION, il y a blocage de l'ordre SQL UPDATE ou DELETE dans le but de maintenir le lien d'intégrité tel quel. Ce blocage intervient en fin de transaction si la contrainte est déférée.
ON DELETE RESTRICT / ON UPDATE RESTRICT :
Similaire à NO ACTION, mais le blocage intervient immédiatement sur l'ordre SQL qui a engendré le viol de la contrainte.
ON DELETE CASCADE / ON UPDATE CASCADE :
Toute modification de clé ou suppression de ligne dans la table mère est répercutée dans la table fille : si l'on entreprend une suppression de lignes de référence les lignes de la table fille en regard sont elles aussi supprimées. Si l'on modifie des valeurs de clés qui servent de référence, alors ces valeurs modifiées sont répercutées dans la table fille.
Dans le cas du CASCADE, il y répercussion de l'ordre SQL avec modification de valeur ou suppression de lignes afin de maintenir ou d'évacuer le lien d'intégrité.
ON DELETE SET NULL / ON UPDATE SET NULL :
Toute action de modification ou de suppression dans la table mère est répercutée dans la table fille par la suppression des valeurs des clés étrangères, qui sont remplacées par des marqueurs NULL.
Dans le cas du SET NULL, il y suppression des valeurs des clés étrangères pour les lignes concernées, ce qui conduit à un déréférencement du lien d'intégrité.
En pratique, cela suppose que la clé étrangère est « NULLable » sinon cela n’a aucun intérêt.
ON DELETE SET DEFAULT / ON UPDATE SET DEFAULT :
Toute action de modification ou de suppression dans la table mère est répercutée dans la table fille par la mise en place des valeurs spécifiées par défaut pour les colonnes des clés étrangères.
Dans le cas du SET DEFAULT, il y mise en place des valeurs par défaut des clés étrangères pour les lignes concernées, ce qui conduit à un glissement des valeurs de références du lien d'intégrité.
En pratique, cela suppose que la clé étrangère est pourvue d’une contrainte de défaut et que cette valeur est renseignée dans la référence, sinon cela n’a aucun intérêt.
À ce stade il convient de préciser les éléments suivants concernant le fonctionnement du mode de gestion de la référence :
- Autant le mode NO ACTION / RESTRICT est toujours possible et s'avère être celui qui opère par défaut, autant les autres modes sont dépendants de facteurs complémentaires tel que d'autres contraintes de clé étrangères ou bien l'absence de spécification de valeurs par défaut ou encore l'obligation de spécification de valeur (NOT NULL).
- Le mode cascade est très tentant, mais son coût de traitement peut s'avérer élevé. Mal maîtrisé il peut se révéler bloquant et devenir totalement contre performant, notamment dans le cas de cascades multiples ou de combinaisons de cascades et NO ACTION / RESTRICT.
- L'intérêt du SET NULL est de permettre la suppression des lignes devenues orphelines de manière différée, par exemple dans un traitement par lot intervenant aux heures creuses.
- L'intérêt du SET DEFAULT réside dans la possibilité de définir une référence particulière qui concentre les efforts de gestion des références obsolètes dans un traitement spécifique, par exemple le client 0 ou moi-même et, bien entendu de différer la suppression physique des lignes…
- NO ACTION est le mode par défaut en l'absence de spécification.
Exemple 3.26* – Tables référencées par différentes intégrités référentielles de différents modes
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
CREATE TABLE S_COM.T_CLIENT_CLI
(CLI_ID INTEGER NOT NULL PRIMARY KEY,
CLI_NOM CHAR(32) NOT NULL);
CREATE TABLE S_COM.T_COMMANDE_CMD
(CMD_ID INTEGER NOT NULL PRIMARY KEY,
CMD_DATE DATE NOT NULL DEFAULT CURRENT_DATE,
CLI_ID INTEGER NOT NULL
REFERENCES S_COM.T_CLIENT_CLI (CLI_ID)
ON DELETE CASCADE);
CREATE TABLE S_COM.T_FACTURE_FCT
(FCT_ID INTEGER NOT NULL PRIMARY KEY,
FCT_DATE DATE NOT NULL DEFAULT CURRENT_DATE,
CLI_ID INTEGER NOT NULL
REFERENCES S_COM.T_CLIENT_CLI (CLI_ID)
ON DELETE NO ACTION
ON UPDATE NO ACTION,
FCT_TOTAL_TTC DECIMAL(16,2) NOT NULL,
FCT_ECHEANCE DATE NOT NULL DEFAULT CURRENT_DATE + 30 DAY);
L’exemple 3.26 montre les tables client, produit, commande, ligne de commande et facture dont l’intégrité référentielle entre les tables est gérée par différents modes (NO ACTION et CASCADE).
La représentation schématique de cette intrication est montrée par la figure 3.2 :
|
|
|
Figure 3.2 – Représentation graphique de la clause de gestion dans différentes intégrités référentielles |
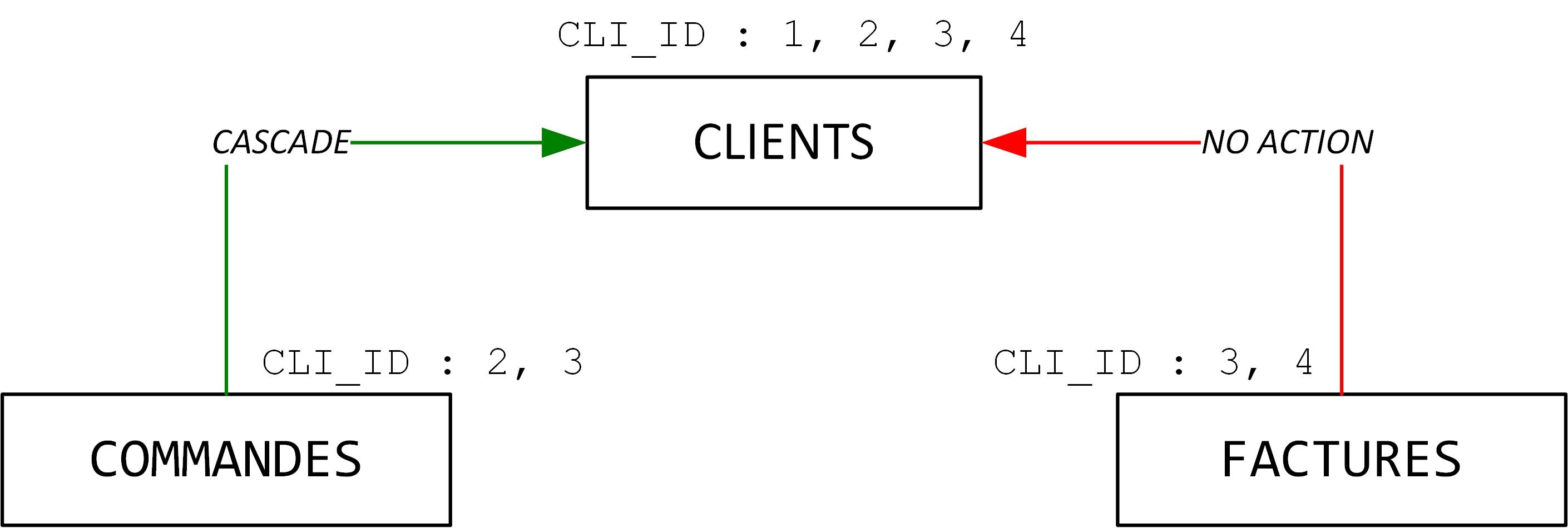
Avec une telle base la suppression d'un client entraîne la suppression de ses commandes. Mais d'un autre côté la suppression d'un client n'est pas possible si des factures portent la référence de ce client.
La figure 3.2 montre les identifiants des clients dans les différentes tables. La suppression des clients dont CLI_ID vaut 1 ou 2 réussie car l’intégrité en mode CASCADE est gérée entre la table des commandes et celle des clients.
Pour le client 3, rien n’est supprimé, ni le client, ni ses commandes ni les factures car la transaction échoue au niveau de la facture (NO ACTION).
Pour le client 4 là aussi la suppression est impossible car il a des factures…
Comme la suppression d'un client est un ordre atomique, si ce client a des factures il ne sera pas possible de le supprimer et la violation de la contrainte entraînant l'abandon de l'ordre, aucune commande ne sera supprimée.
En revanche la suppression en cascade se produira bien si ce client a des commandes mais n'a pas encore été facturé. Et c’est bien ce que nous voudrions dans la vraie vie, supprimer les commandes qui ne font l’objet d’aucun paiement !
III-5. Les assertions▲
Les assertions sont des contraintes dont l'étendue porte sur la base entière notamment pour permettre des règles de validation entre différentes colonnes de différentes tables ou vues à l'aide de prédicats. Les assertions au sens de la norme SQL sont donc des objets de la base de données.
Pour créer une assertion, il faut utiliser la commande CREATE ASSERTION et utiliser une contrainte de validation CHECK.
La syntaxe de création d'une assertion est la suivante :
2.
3.
4.
5.
6.
7.
CREATE ASSERTION [nom_schéma.]nom_assertion
CHECK ( predicat )
[ <attribut_assertion> ]
<attribut_assertion> ::
{INITIALLY DEFERRED | INITIALLY IMMEDIATE} [ [ NOT ] DEFERRABLE ]
| [NOT] DEFERRABLE [INITIALLY DEFERRED | INITIALLY IMMEDIATE]
Les règles de « differabilité », introduites par la clause <attribut_assertion> seront discutées au paragraphe suivant.
Nous prendrons comme exemple une unicité de clé devant porter sur deux tables distinctes, ce qui est le cas dans tous les héritages « exclusifs » :
Exemple 3.27* – Tables en héritage exclusif nécessitant une assertion d’exclusion
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
CREATE TABLE S_PRS.T_PERSONNE_GENERIQUE_PSG
(PSG_ID INTEGER PRIMARY KEY,
PSG_DATE_CREATION DATE NOT NULL);
CREATE TABLE S_PRS.T_PERSONNE_PHYSIQUE_PSP
(PSG_ID INTEGER PRIMARY KEY
REFERENCES S_PRS.T_PERSONNE_GENERIQUE_PSG(PSG_ID),
PSP_NOM VARCHAR(32) NOT NULL,
PSP_PRENOM VARCHAR(25),
PSP_DATE_NAISSANCE DATE);
CREATE TABLE S_PRS.T_PERSONNE_MORALE_PSM
(PSG_ID INTEGER PRIMARY KEY
REFERENCES S_PRS.T_PERSONNE_GENERIQUE_PSG(PSG_ID),
PSM_RAISON_SOCIALE VARCHAR(256) NOT NULL,
PSM_ENSEIGNE VARCHAR(64),
PSM_SIRET CHAR(14) NOT NULL UNIQUE);
Dans ce type de modélisation, les personnes morales et physiques héritent des caractéristiques d’une personne générique. Au niveau inférieur, il faut dissocier les PRS_ID en deux groupes, les valeurs affectées aux personnes physiques ne devant en aucun cas se retrouver dans la table des personnes morales et vice-versa.
Dans un tel cas on recoure à une assertion comme celle-ci :
Exemple 3.28* – Assertion d’exclusion pour le cas d’un héritage mutuellement exclusif
2.
3.
4.
5.
6.
7.
8.
CREATE ASSERTION A_UNIQUE_ID_PRS
CHECK
(NOT EXISTS
(SELECT PRS_ID
FROM S_PRS.T_PERSONNE_PHYSIQUE_PSP
INTERSECT
SELECT PRS_ID
FROM S_PRS.T_PERSONNE_MORALE_PSM);
La sous-requête SELECT de la clause CHECK qui forme le prédicat de l'assertion, met en correspondance les tables S_PRS.T_PERSONNE_PHYSIQUE_PSP et S_PRS.T_PERSONNE_MORALE_PSM en faisant l’intersection des ensembles formés de la clé de chacune des tables. Dans le cas présent, afin d'assurer l'unicité de la clé à travers les deux tables, il ne faut pas qu'une personne physique porte le même numéro de clé qu'une personne morale. En aucun cas, la requête ne doit retourner un résultat. Cela est assuré à l'aide de l'expression EXISTS qui renvoite vrai au cas où un résultat est retourné et faux dans le cas où la requête ne retourne aucune ligne.
L'assertion est vérifiée chaque fois que l’une des deux tables fait l’objet d’une mise à jour (INSERT, UPDATE, DELETE…) et la contrainte valide la commande si le prédicat CHECK vaut vrai, donc si la requête d'extraction ne produit aucun résultat. Dans le cas contraire le viol de la contrainte intervient et l'ordre SQL d'insertion ou de modification est empêché qu'il porte sur l'une ou l'autre table.
Dans le cas de l’exemple 3.29, toute suppression de ligne d’une des deux tables filles ne violera jamais cette contrainte, mais par sa nature, l’assertion impose que cette vérification soit faite même en cas de suppression, ce qui est un travail inutile…
Une contrainte de table ne suffit pas à exprimer une telle règle de validation. Seul l'usage de l'assertion (contrainte propre à la base) le permet.
|
|
NOTE |
III-6. La déférabilité des contraintes▲
Qu'il s'agisse de contraintes de domaine, de table ou encore d'assertions, toutes les contraintes peuvent inclure une clause de déferrabilité, c'est à dire que leur application peut être différée à un moment plus opportun.
Jusqu'ici, nous avons supposé implicitement que la contrainte opérait dès que le fait générateur la déclenchait (insertion, modification ou suppression dans une table par exemple). Or SQL admet une grande souplesse en ce sens qu'il propose différents outils pour différer la validation de la contrainte. Ces outils sont la clause de déferrabilité propre à chaque contrainte, et le paramétrage de la déferrabilité des contraintes au sein du schéma.
La déférabilité d'une contrainte est une opération nécessaire dès que différentes contraintes interagissent créant ainsi ce que l'on appelle une référence croisée ou circulaire...
Pour comprendre ce mécanisme et les modes d'utilisation qu'il offre, il est nécessaire de prendre en compte la notion de transaction, c'est à dire une combinaison de différents ordres SQL que l'on veut exécuter en séquence et d'un seul bloc, c'est à dire en tout ou rien.
Ainsi lorsqu'une table T1 fait référence à une table T2 par une intégrité référentielle, se pose le problème de la mise en place d'une intégrité référentielle inverse de T2 vers T1 (intégrité référentielle circulaire) ... Nous voici confrontés au problème de l'œuf et de la poule... C'est pour trancher ce dilemme que les outils de déferrabilité de contrainte ont été définis par SQL.
Par exemple, dans ce cas de figure, on ne peut insérer dans T1 que si l'on a inséré dans T2 et inversement. Les opérations doivent donc être successives et combinées et si l'une d'entre elle échoue, il faut les défaire toutes, ce qui se fait au travers d'une transaction SQL.
La syntaxe de la clause de déferrabilité de la contrainte est la suivante :
[ NOT ] DEFERRABLE | DEFERRABLE { INITIALLY DEFERRED | INITIALY IMMEDIATE }
NOT DEFERRABLE :
La contrainte opère dès que l'ordre SQL qui la met en cause est appliqué. Elle ne pourra jamais être différée. C'est l'option par défaut en l'absence de spécification.
DEFERRABLE :
La contrainte peut être différée. À défaut de spécification complémentaire, elle opère dès que l'ordre SQL qui la met en en cause est appliqué.
INITIALLY DEFERRED :
À défaut de spécification contraire au niveau de la session, la contrainte sera différée au début de chaque transaction. En d'autres termes elle est vérifiée en fin de transaction. Cette option n'est pas compatible avec NOT DEFERRABLE.
INITIALLY IMMEDIATE :
Une contrainte différable, INITIALLY IMMEDIATE sera appliquée immédiatement au début de la transaction. En d'autres termes elle est vérifiée au cours de la transaction pour chaque ordre SQL qui l'appelle, sauf si le paramétrage de session en a décidé autrement.
Le paramètre SET CONSTRAINTS permet de définir le fonctionnement global ou particulier des contraintes au sein de la session. Il se définit à l'aide de la syntaxe suivante :
SET CONSTRAINTS { <liste_de_contraintes> | [ ALL ] }
[ DEFERRED | IMMEDIATE ]Il n'opère que pour les contraintes qui n'ont pas été définies en tant que NOT DEFFERABLE.
Imaginons que nous voulons modéliser un client et ses commandes et placer dans la table du client la dernière commande servie, cela afin d'éviter de placer des clients sans commande dans la table des clients (les clients sans commandes étant placés naturellement dans la table des prospects...). Le problème se pose ainsi : comment insérer un nouveau client qui, par définition, n'a pas encore de commande, alors que l'on exige dans la table client de faire référence à la dernière commande ?
Nous pouvons concevoir cela à l'aide des descriptions de table suivante :
Exemple 3.29* – Tables avec contrainte d’intégrité en référence croisée
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
CREATE TABLE S_COM.T_CLIENT_CLI
(CLI_ID INTEGER NOT NULL PRIMARY KEY,
CLI_NOM CHAR(32),
CDE_ID INTEGER NOT NULL,
CONSTRAINT FK_CLI_CDE FOREIGN KEY (CDE_ID)
REFERENCES S_COM.T_COMMANDE (CDE_ID))
CREATE TABLE S_COM.T_COMMANDE_CDE
(CDE_ID INTEGER NOT NULL PRIMARY KEY,
CDE_DATE DATE,
CLI_ID INTEGER NOT NULL,
CONSTRAINT FK_CDE_CLI FOREIGN KEY (CLI_ID)
REFERENCES S_COM.T_CLIENT (CLIK_ID));
Or, si le lancement de ce script SQL de création des tables permettait d'instancier les objets, il serait en revanche impossible d'y rentrer la moindre donnée.
Dès lors, deux moyens sont possibles pour résoudre ce dilemme : modifier l'une des contraintes en la différant en fin de transaction, ou bien paramétrer le SGBDR pour qu'il valide une partie ou la totalité des contraintes à la fin de la transaction.
Deux solutions, toutes deux à base de contraintes différables sont possibles…
Exemple 3.30* – Résolution d’une référence d’intégrité croisée lors de la création des objets du schéma :
Les objets doivent avoir été créés comme suit :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
CREATE TABLE S_COM.T_CLIENT_CLI
(CLI_ID INTEGER NOT NULL PRIMARY KEY,
CLI_NOM CHAR(32),
CDE_ID INTEGER NOT NULL,
CONSTRAINT FK_CLI_CDE FOREIGN KEY (CDE_ID)
REFERENCES S_COM.T_COMMANDE (CDE_ID))
CREATE TABLE S_COM.T_COMMANDE_CDE
(CDE_ID INTEGER NOT NULL PRIMARY KEY,
CDE_DATE DATE,
CLI_ID INTEGER NOT NULL,
CONSTRAINT FK_CDE_CLI FOREIGN KEY (CLI_ID)
REFERENCES S_COM.T_CLIENT (CLIK_ID)
DEFERRABLE INITIALLY DEFFERED);
Dès lors, la transaction d’insertion combinée réussie :
2.
3.
4.
5.
6.
7.
8.
9.
BEGIN TRANSACTION;
INSERT INTO S_COM.T_CLIENT_CLI VALUES (101, 'DUPONT');
INSERT INTO T_COMMANDE_CDE VALUE (4589, '2005-09-01', 101);
UPDATE S_COM.T_CLIENT_CLI SET CDE_ID = 4589 WHERE CLI_ID = 101;
COMMIT;
Exemple 3.31* – Résolution d’une référence d’intégrité croisée par forçage de la session :
Les objets doivent avoir été créés comme suit :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
CREATE TABLE S_COM.T_CLIENT_CLI
(CLI_ID INTEGER NOT NULL PRIMARY KEY,
CLI_NOM CHAR(32),
CDE_ID INTEGER NOT NULL,
CONSTRAINT FK_CLI_CDE FOREIGN KEY (CDE_ID)
REFERENCES S_COM.T_COMMANDE (CDE_ID));
CREATE TABLE S_COM.T_COMMANDE_CDE
(CDE_ID INTEGER NOT NULL PRIMARY KEY,
CDE_DATE DATE,
CLI_ID INTEGER NOT NULL,
CONSTRAINT FK_CDE_CLI FOREIGN KEY (CLI_ID)
REFERENCES S_COM.T_CLIENT (CLIK_ID)
DEFERRABLE);
Là aussi, la transaction d’insertion combinée réussie avec le paramétrage de différabilité au niveau de la session :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
SET CONSTRAINTS FK_CDE_CLI DEFERRED;
BEGIN TRANSACTION;
INSERT INTO S_COM.T_CLIENT_CLI VALUES (101, 'DUPONT');
INSERT INTO S_COM.T_COMMANDE_CDE VALUE (4589, '2005-09-01', 101);
UPDATE S_COM.T_CLIENT_CLI SET CDE_ID = 4589 WHERE CLI_ID = 101;
COMMIT;
|
|
NOTE
|
III-7. En guise de conclusion sur les contraintes▲
Si les contraintes sont des mécanismes séduisants, notamment pour garantir l’intégrité et la qualité des données, il faut les utiliser à bon escient.
Précisons tout de suite, que la vérification des contraintes prend un temps généralement infime en regard à l’ensemble des opérations qu’une requête doit effectuer pour s’exécuter…
Dans les SGBDR évolués, l’optimiseur, qui décide du plan d’exécution de la requête, utilise les contraintes pour simplifier les commandes SQL et gagner du temps d’exécution…
III-7-1. Limites de la contrainte CHECK▲
En ce qui concerne les contraintes de validation, il est extrêmement dangereux et très contre-performant de faire référence à des données externes à la table. De plus, dans un tel cas, il serait possible d’utiliser la contrainte CHECK comme substitut à la contrainte FOREIGN KEY (ce que nous avons vu dans l’exemple 3.21 avec la contrainte CHECK de nom CK_SGN_SI_MEDECIN).
Dangereux, car pour des raisons de performance, certains SGBDR exécutent en parallèle les commandes SQL. Dès lors, des effets de bords pourraient se faire sentir sur les jointures résultant des opérations de vérification des contraintes de validation. À titre d’exemple, un calcul parallélisé comptant les occurrences de données externes à la table pourrait comptabiliser plusieurs fois les mêmes lignes de la table externe (recoupement de threads), pour différentes occurrences de la table interne. Cela entraînerait de facto l’interdiction du parallélisme et donc des problèmes de performance.
Pour ces mêmes raisons de performance, il faudrait poser de nombreux verrous afin d’interdire aux utilisateurs concurrents toute modification, le temps de vérifier la règle de validation de la contrainte CHECK, sur les lignes de la table externe, ce qui pose des problèmes de ressources et des blocages pour les autres utilisateurs.
Pire, il faudrait que les tables externes à la règle de validation soient dotées d’un mécanisme qui, lors de chaque mise à jour (INSERT, UPDATE, DELETE…) vérifient « à l’envers » que la contrainte dans la table distante est toujours validée…
Bien que la norme SQL n’interdise pas l’accès à des tables externes pour vérifier la validation de la règle d’une contrainte CHECK, rares sont les SGBDR professionnels qui le permettent.
Rares aussi sont les SGBDR qui permettent une contrainte CHECK portant sur plusieurs lignes de la table dans laquelle figure cette contrainte de validation, toujours pour des raisons de parallélisme, de concurrence et donc de performances.
Nous dirons donc que, même si votre SGBDR permet de créer des contraintes portant sur des tables externes ou vérifiant un lot de ligne de la table interne, il est plus que préférable de s’en abstenir.
III-7-2. Désintérêt de la notion d’ASSERTION▲
Les contraintes généralisées de type « assertions » sont des contraintes portant sur différentes tables de la base et doivent être vérifiées à chaque mise à jour des tables mentionnées dans la règle de validation.
Dans l’exemple 3.29 Ceci suppose de vérifier l’assertion pour :
- La table S_PRS.T_PERSONNE_PHYSIQUE_PSP lors des commandes INSERT, UPDATE et DELETE
- La table S_PRS.T_PERSONNE_MORALE_PMR lors des commandes INSERT, UPDATE et DELETE
Cela fait donc 6 événements à surveiller repartis en deux objets.
Or on s’aperçoit que dans le lot d’exemples 3.28 et 3.29 la vérification lors des suppressions est inutile.
De même, la vérification lors des modifications n’a aucun intérêt à s’exécuter si la valeur de la clé PRS_ID est inchangée.
Enfin, dans tous les cas, cette vérification devrait n’être entreprise que sur les valeurs modifiées :
- nouvelles lignes ;
- valeurs modifiées des colonnes ;
- lignes supprimées ;
…et non sur l’ensemble de toutes les lignes des tables invoquées.
De fait, les assertions posent donc des problèmes de performances en demandant un travail trop important, inutile, mobilisant trop de ressources et bloquant la concurrence. C’est pourquoi l'éditeur Sybase avec son SGBDR SQL Server (l'ancêtre de Microsoft SQL Server) a riposté en proposant la notion de déclencheur (trigger) rapidement adoptée par les autres SGBDR, dans laquelle on peut choisir les actions à circonscrire et limiter la règle de vérification aux lignes portant les valeurs nouvelles ou anciennes. Ce concept de déclencheur inventé par l’éditeur Sybase dans son SGBDR SQL Server en 1987 a finalement été accepté dans la norme SQL.
Heureusement, rares sont les SGBDR ayant mis en œuvre les assertions.
De manière systématique, abstenez vous de créer des contraintes portant sur des jeux de données, même à travers des fonctions « utilisateur » mais recourez aux déclencheurs pour ce faire. Ils ont performants, à condition de fonctionner en mode ensembliste (per statement). Voir le chapitre 7 à ce sujet.
III-7-3. La dangereuse Déferrabilité des contraintes▲
Là encore, si la chose semble séduisante, de nombreux auteurs, parmi lesquels Franck Edgar Codd lui-même et Chris Date, déconseillent la notion de déferrabilité des contraintes, car elle permet de violer à l’évidence quelques uns des principes mêmes du fondement des SGBD Relationnels comme la notion d’exécution atomique ou le fonctionnement ensembliste…
La solution de contournement passe par l’utilisation systématique des vues, associées à des contraintes simples, des procédures stockées et des déclencheurs. Nous étudierons ces deux derniers éléments au chapitre 7.
III-7-4. Optimisation par les contraintes▲
Nous avons vu au chapitre 1, § 1.3.1 que les contraintes pouvaient jouer un rôle important pour l’optimiseur, l’aidant à simplifier une requête. Cela porte sur tous les types de contrainte… PRIMARY KEY, UNIQUE, FOREIGN KEY, CHECK
Quelques exemples théoriques simples permettent de comprendre la chose…
Si une requête recherche un produit dont le prix est inférieur à une valeur négative, la présence d’une contrainte limitant les prix à des valeurs positive ou 0, entraînera un résultat immédiat et vide, car l’optimiseur constatant cette impossibilité n’ira même pas scruter les valeurs de la table.
Dans le cas d’une interrogation multi-tabulaire, les tables peuvent être référencées par des valeurs de clé à d’autres tables comme nous l’avons vu au § 3.3.2.2 consacré à la contrainte FOREIGN KEY entre autres. On parle alors de table mère possédant une clé primaire et d’une table fille possédant une clé étrangère référençant la clé primaire de la table mère. En l’absence de mécanisme garantissant l’intégrité d’une telle correspondance, les requêtes sont moins bien optimisées que si l’intégrité référentielle est activée.
Voici un exemple modélisant un club de sport dans lequel nous trouvons une table des adhérents (ils sont nombreux) une table des sports pratiqués (plus d’une centaine) et une table associant les adhérents aux sports qu’ils pratiquent. Pour connaître les sports réellement pratiqués, c’est-à-dire, ceux sur lesquels il y a encore des adhérents, la requête proposée est la suivante :
|
|
|
Figure 3.3 – Plan de requête en l’absence de contraintes d’intégrité référentielle (MS SQL Server) |
Le plan d’exécution montre que l’on accède aux trois tables et le coût de la requête (juste un indice de comparaison établi par l’optimiseur) est évalué à 0,264.
En ajoutant les contraintes d’intégrité référentielles et en rejouant la requête :
|
|
|
Figure 3.4 – Plan de requête avec présence de contraintes d’intégrité référentielle (MS SQL Server) |
Le coût de la requête est maintenant évalué à 0,0376… soit un gain de 7 fois !
La raison en est simple : la jointure entre la table des pratiques et la table des adhérents n’est plus nécessaire car l’intégrité référentielle garantit que toute clé d’adhérent (ADR_ID) dans la table des pratiques existe bien dans la table des adhérents. Bien qu’exprimée dans la requête, cette jointure est totalement éliminée pour des raisons de performance !
La volumétrie des données d’une base induit des temps de réponse qu’il est facile de combattre avec de bonne pratique comme la nécessité absolue de mettre en place le plus possible de contraintes simples. L’optimiseur en tiendra compte pour simplifier certains plans de requête.
III-7-5. Indexation des contraintes▲
Certaines contraintes sont créées avec un index qui permet d’en accélérer l’exécution.
À bien y regarder, aucun index n’est logiquement utile à une base de données (c’est pourquoi la norme SQL n’y fait aucune référence), mais physiquement nécessaire à l’obtention de bonnes performances.
Par exemple le fait de contrôler l’unicité d’une série de valeurs n’a pas besoin d’un index, censé accélérer la recherche de l’information. Pour garantir lors de l’insertion que l’on ajoute une valeur unique à la table, il suffit alors de verrouiller l’intégralité des lignes de la table de manière exclusive et les passer toutes en revue pour savoir si cette valeur existe déjà. Si oui, on rejette l’insertion, si non, on l’accepte. Mais il est évident que bloquer la totalité des accès concurrents à une table pour assurer une telle fonctionnalité n’est pas jouable, sauf si l’on est l’utilisateur unique de la base (dans ce cas, mieux vaut sans doute utiliser un tableur).
C’est pourquoi lorsque des contraintes FOREIGN KEY et UNIQUE sont posées, un index est créé de manière sous-jacente et cet index porte généralement le nom de la contrainte.
Certains SGBDR peu professionnels, en particulier MySQL et MariaDB ont décidé de créer des index sous les clés étrangères. Mais indexer systématiquement toutes les contraintes FOREIGN KEY est une absurdité que nous démonterons au chapitre 14.
III-8. Les vues▲
Dans le langage SQL les vues ne sont autres que des requêtes instanciées, c'est à dire un ordre d'extraction de données SELECT dont le résultat est vu comme une table, d'ou le nom de « vue ». L’ordre SQL CREATE VIEW permet de créer une vue.
On peut les considérer comme des tables virtuelles dans le sens ou l’on peut y extraire les données des tables sous-jacentes, comme effectuer des mises à jour qui seront répercutées dans les tables finales, directement sous certaines conditions, ou indirectement via des déclencheurs de type INSTEAD OF. D’ailleurs la norme SQL considère les vues comme des tables du type « VIEW » tandis que les tables qui stockent les données sont considérées comme des « BASE TABLE ».
La vue normalisée de métadonnées « INFORMATION_SCHEMA » donnant la liste des tables, présente cette distinction, comme le montre la figure 3.5 :
|
|
|
Figure 3.5 – Liste des tables selon la norme SQL |
Elles sont nécessaires pour gérer finement les privilèges et elles sont utiles pour masquer la complexité de certains modèles relationnels afin de les rendre plus présentables, plus compréhensibles, ne serait-ce qu’aux développeurs. Elles sont indispensables au développement qui ne devrait jamais être bâti en accès direct aux tables, mais toujours par l’intermédiaire de vues.
Voici la syntaxe SQL pour définir une vue :
2.
3.
4.
CREATE VIEW nom_vue [ ( <liste_colonne> ) ]
AS
<requête_select>
[ WITH [ CASCADED | LOCAL ] CHECK OPTION ]]
Bien entendu, la liste des colonnes, si elle est spécifiée, doit comporter le même nombre d'items qu'il y a de colonnes dans la clause de sélection de la requête SELECT (les requêtes d'extraction de l'information SELECT sont vues aux chapitres 4 et 5).
Nous étudierons la clause CHECK OPTION au paragraphe 3.8.2.
|
|
ATTENTION |
En reprenant les tables de l’exemple 3.27, nous pouvons former les vues suivantes présentant les personnes morales, les personnes physiques et une concaténation des deux types de personnes :
Exemple 3.32* – Création de différentes vues basées sur les tables de l’exemple 3.28 :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
CREATE VIEW S_PRS.V_PERSONNE_PHYSIQUE
AS
SELECT PG.*, PSP_NOM , PSP_PRENOM, PSP_DATE_NAISSANCE
FROM S_PRS.T_PERSONNE_GENERIQUE_PSG AS PG
INNER JOIN S_PRS.T_PERSONNE_PHYSIQUE_PSP AS PP
ON PG.PSG_ID = PP.PSG_ID;
CREATE VIEW S_PRS.V_PERSONNE_MORALE
AS
SELECT PG.*,PSM_RAISON_SOCIALE, PSM_ENSEIGNE, PSM_SIRET
FROM S_PRS.T_PERSONNE_GENERIQUE_PSG AS PG
INNER JOIN S_PRS.T_PERSONNE_MORALE_PSM AS PM
ON PG.PSG_ID = PM.PSG_ID;
CREATE VIEW S_PRS.V_PERSONNE
AS
SELECT PG.*, CASE
WHEN PP.PSG_ID IS NULL
THEN 'Morale'
ELSE 'Physique'
END AS TYPE_PERSONNE,
COALESCE(PSP_NOM, PSM_RAISON_SOCIALE) AS NOM,
COALESCE(PSP_PRENOM, PSM_ENSEIGNE) AS PRENOM_OU_ENSEIGNE,
PSP_DATE_NAISSANCE AS DATE_NAISSANCE_PERSONNE_PHYSIQUE,
PSM_SIRET AS SNUMERO_SIRET_PERSONNE_MORALE
FROM S_PRS.T_PERSONNE_GENERIQUE_PSG AS PG
LEFT OUTER JOIN S_PRS.T_PERSONNE_PHYSIQUE_PSP AS PP
ON PG.PSG_ID = PP.PSG_ID
LEFT OUTER JOIN S_PRS.T_PERSONNE_MORALE_PSM AS PM
ON PG.PSG_ID = PM.PSG_ID;
Ces vues, présentent des données plus complètes concernant les personnes.
Les vues servent aussi à simplifier l'accès de certains utilisateurs aux informations communes situées dans une même table. Considérant par exemple la table des employés d'une entreprise comme définie à l’exemple 3.33 :
Exemple 3.33* – Création d’une table pour les employés :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
CREATE TABLE S_RH.T_EMPLOYE_EMP
(EMP_ID INT PRIMARY KEY,
EMP_NOM CHAR(32) NOT NULL,
EMP_PRENOM VARCHAR(25),
EMP_DATE_NAISSANCE DATE,
EMP_NNI_SEXE CHAR(1) NOT NULL,
EMP_NNI_DATE_NAISS CHAR(4) NOT NULL,
EMP_NNI_COMMUNE_NAISS CHAR(5) NOT NULL,
EMP_NNI_RANG_NAISS CHAR(3) NOT NULL,
EMP_DATE_ENTREE DATE NOT NULL,
EMP_SALAIRE DECIMAL(16, 2) NOT NULL,
EMP_FONCTION VARCHAR(16),
EMP_SERVICE VARCHAR(16),
EMP_MEDECIN_TRAITANT VARCHAR(32));
Différents acteurs vont devoir accéder aux informations des employés. En particulier :
- les comptables pour calculer la paye ;
- les délégués du personnel pour les revendications syndicales ;
- la médecine du travail pour les contrôles annuels.
Mais tous ces acteurs bénéficient-ils du même accès à toutes les informations de cette table d’employés ? Assurément non ! D’où l’intérêt des vues que présente l’exemple 3.34 :
Exemple 3.34* – Trois vues des employés pour trois catégories d’utilisateurs :
--> pour les ressources humaines, tout sauf le médecin traitant
2.
3.
4.
5.
6.
7.
CREATE VIEW S_RH.V_EMP_RH
AS
SELECT EMP_ID, EMP_NOM, EMP_PRENOM, EMP_DATE_NAISSANCE,
EMP_NNI_SEXE, EMP_NNI_DATE_NAISS,
EMP_NNI_COMMUNE_NAISS, EMP_NNI_RANG_NAISS,
EMP_DATE_ENTREE, EMP_SALAIRE, EMP_FONCTION, EMP_SERVICE
FROM S_RH.T_EMPLOYE_EMP;
--> pour les syndicats, pas de NNI ni salaire, ni médecin traitant
2.
3.
4.
5.
6.
CREATE VIEW S_RH.V_EMP_SYNDICAT
AS
SELECT EMP_ID, EMP_NOM, EMP_PRENOM, EMP_DATE_NAISSANCE,
EMP_DATE_ENTREE, EMP_FONCTION, EMP_SERVICE
FROM S_RH.T_EMPLOYE_EMP
WHERE EMP_FONCTION <> 'PDG';
--> pour la médecine du travail, tout sauf le salaire
2.
3.
4.
5.
6.
7.
CREATE VIEW S_RH.V_EMP_MEDECIN
AS
SELECT EMP_ID, EMP_NOM, EMP_PRENOM, EMP_DATE_NAISSANCE,
EMP_NNI_SEXE, EMP_NNI_DATE_NAISS,
EMP_NNI_COMMUNE_NAISS, EMP_NNI_RANG_NAISS,
EMP_DATE_ENTREE, EMP_FONCTION, EMP_SERVICE, EMP_MEDECIN_TRAITANT
FROM S_RH.T_EMPLOYE_EMP;
Chacun des acteurs ayant droit aux informations de l’employé ne verra pas les mêmes rubriques dans son interface, d’où le recours aux vues :
- les ressources humaines ont besoin de toutes les informations sauf le médecin traitant ;
- les syndicats ne doivent pas accéder aux informations confidentielles (NNI, médecin traitant) ni aux salaires et bien entendu ignorent le PDG ! ;
- le médecin du travail ne doit pas connaître le salaire mais il lui est indispensable d’accéder au NNI (Numéro National d’Identité – càd. N° de sécu) et au nom du médecin traitant.
Un dernier exemple (3.35) nous montre les tables des taux de TVA avec l’historique de l’évolution des taux. Cette dernière n’est pas facile à exploiter car y figure la date de début d’application du taux de TVA, mais pas la date de fin, ceci pour éviter une redondance qui, en cas de modification, pourrait conduire à un problème d’anomalie de mise à jour :
Exemple 3.35* – Tables présentant l’historique de l’évolution du taux de TVA de 1968 à 2023 :
2.
3.
4.
5.
6.
7.
8.
9.
10.
CREATE TABLE S_TAXE.T_TVA_NATURE_TVN
(TVN_ID INT PRIMARY KEY,
TVN_CODE CHAR(16) NOT NULL UNIQUE,
TVN_DATE_SUPPRESSION DATE);
CREATE TABLE S_TAXE.T_TVA_HISTORIQUE_TVH
(TVH_ID INT PRIMARY KEY,
TVN_ID INT NOT NULL REFERENCES S_TAXE.T_TVA_NATURE_TVN (TVN_ID),
TVH_D_APPLICATION DATE NOT NULL,
TVH_TAUX FLOAT NOT NULL)
On ne saurait fournir directement un accès à ce jeu de tables tant elles sont difficiles d’exploitation. Le recours à une vue de synthèse apparaît nécessaire :
|
|
|
Figure 3.6 – Tables des natures et taux de TVA |
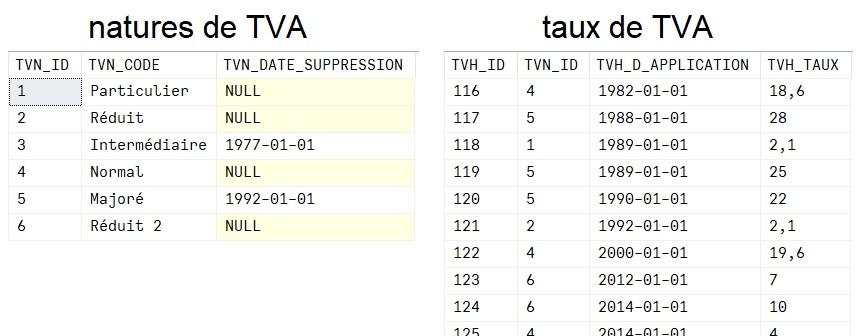
La vue suivante synthétise l’information de ces deux tables :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
CREATE VIEW S_TAXE.V_TVA
AS
SELECT N.TVN_ID, TVN_CODE, TVH_ID, TVH_D_APPLICATION AS DEBUT,
COALESCE(LEAD(TVH_D_APPLICATION)
OVER(PARTITION BY H.TVN_ID
ORDER BY TVH_D_APPLICATION),
TVN_DATE_SUPPRESSION, '9999-12-31') AS FIN,
H.TVH_TAUX
FROM S_TAXE.T_TVA_NATURE_TVN AS N
INNER JOIN S_TAXE.T_TVA_HISTORIQUE_TVH AS H
ON N.TVN_ID = H.TVN_ID;
La présentation du contenu de cette vue (extrait) est bien plus pratique :
|
|
|
Figure 3.7 – Vue de synthèse de l’historique des taux de TVA (extrait) |
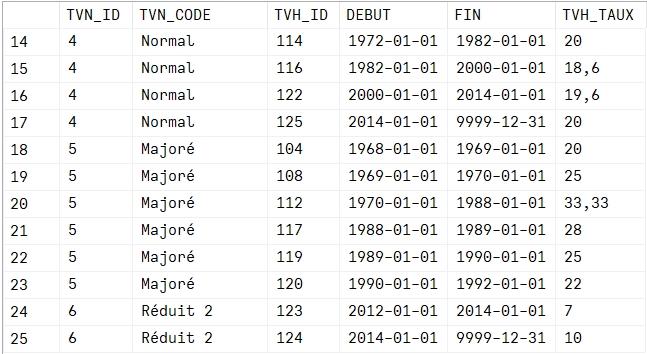
La présence des dates de début et fin d’application de chacun des types de taux avec leur nom facilite la lecture et l’exploitation.
Nous pouvons d’ailleurs faire une autre vue, à partir de cette vue, afin de filtrer sur les taux de TVA encore actuels, c’est-à-dire ceux dont la date de fin est au 31 décembre 9999 (date théorique de la fin des temps en SQL). L’exemple 3.36 nous montre la construction de cette vue :
Exemple 3.36* – Tables présentant l’historique de l’évolution du taux de TVA de 1968 à 2023 :
2.
3.
4.
5.
CREATE VIEW S_TAXE.V_TVA_ACTUELLE
AS
SELECT TVN_ID, TVN_CODE, TVH_ID, TVH_TAUX
FROM S_TAXE.V_TVA
WHERE FIN = '9999-12-31';
On peut difficilement faire plus simple !
|
|
|
Figure 3.8 – Vue des taux de TVA actuels |
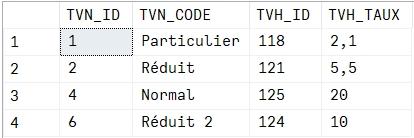
Au final, une vue s’exploite comme une table. On peut en extraire les informations par une commande SELECT comme on le fait sur une table. On peut mettre à jour les données par les commandes INSERT, UPDATE, DELETE comme une table, à condition de respecter certaines conditions… Voyons les quelles !
III-8-1. Mise à jour des données à travers les vues▲
Comme lorsqu'il s'agit d'une table, on peut mettre à jour directement les données des vues (insertion, suppression, modification), mais à condition que certaines règles soient respectées :
- ne porter que sur un ensemble de tables ou de vues modifiables : pas de sous requête sauf dans la clause WHERE, ni de requête ensembliste EXCEPT, UNION ou INTERSECT). Les vues contenant des tables jointes ou l'opérateur ensembliste UNION ALL peuvent être mises à jour dans certains cas, notamment si la vue publie la clé primaire ;
- ne pas contenir de données transformées (pas de concaténation, addition de colonne, fonction...) ni calcul d'agrégat (COUNT, SUM, AVG, MIN, MAX…) ;
- ne pas contenir l’opérateur DISTINCT ni de clause GROUP BY ou HAVING ;
- contenir toutes les colonnes obligatoires dans le cas de l’ajout de ligne (INSERT) ;
Cependant, et comme l'indique la première condition, une vue peut porter sur une autre vue et pour que la nouvelle vue construite à partir d'une autre vue puisse être modifiée, il faut qu'à chaque niveau d'imbrication des vues l'ensemble de ces règles soit respecté.
Les contraintes de la table étant respectées lors des mises à jour de vue, on ne peut insérer des données à travers une vue que si ces dernières respectent les contraintes. En particulier une vue qui ne contiendrait pas une colonne rendue obligatoire par une contrainte NOT NULL ne pourrait faire l'objet d'une insertion, alors qu'elle peut faire l'objet d'une modification ou d'une suppression de ligne.
En fait on peut dire que toute vues encapsulant un sous ensemble des lignes d'une unique table, dont aucune colonne n’est le résultat d’une transformation ou d’une d’un calcul, peuvent toujours être mises à jour.
Dans tous les cas il est possible de contourner ces limitations en ayant recours aux déclencheurs INSTEAD OF.
III-8-1-1. Mise à jour directe dans une vue mono-tabulaire▲
En repartant de la table des employés de l’exemple 3.34, formons la vue suivante :
Exemple 3.37* – Vue mono-tabulaire avec filtre WHERE :
2.
3.
4.
5.
6.
7.
8.
CREATE VIEW S_RH.V_EMP_SALARIE
AS
SELECT EMP_ID, EMP_NOM, EMP_PRENOM, EMP_DATE_NAISSANCE,
EMP_NNI_SEXE, EMP_NNI_DATE_NAISS, EMP_NNI_COMMUNE_NAISS,
EMP_NNI_RANG_NAISS, EMP_DATE_ENTREE, EMP_SALAIRE, EMP_FONCTION,
EMP_SERVICE, EMP_MEDECIN_TRAITANT
FROM S_RH.T_EMPLOYE_EMP
WHERE EMP_SERVICE <> 'Direction';
L’insertion d’un salarié est possible, même s’il est membre de la direction :
2.
3.
4.
5.
INSERT INTO S_RH.V_EMP_SALARIE VALUES
(1, 'DUPONT', 'Marc', '1987-12-21', '1', '8712', '54336', '028',
'2010-03-11', 1250, 'Découpeur', 'Production', NULL),
(2, 'LAMBERT', 'Luc', '1976-06-30', '1', '7606', '2A285', '001',
'2018-05-20', 18500, 'Président', 'Direction', NULL);
Alors que Luc Lambert, de par son statut de PDG sera invisible de la vue, mais aura bien été stocké dans la table… Nous verrons au § 3.8.2 comment dans un tel cas interdire les modifications des lignes non qualifiées avec la clause WITH CHECK OPTION.
En revanche, dès que notre vue ne montre pas les données brutes de la table :
-
les insertions ne sont plus possibles si :
- les colonnes originelles d’une transformation sont obligatoires ;
- l’insertion porte sur une colonne transformée lorsqu’elle n’est pas obligatoire ;
- les modifications ne sont pas possibles pour les colonnes transformées.
Ainsi dans la vue de l’exemple 3.38, toute insertion échoue, car le numéro de sécurité sociale a été présenté de manière concaténée :
Exemple 3.38*– Vue mono-tabulaire avec transformation des données :
2.
3.
4.
5.
6.
7.
CREATE VIEW S_RH.V_EMP_SALARIE_NNI
AS
SELECT EMP_ID, EMP_NOM, EMP_PRENOM, EMP_DATE_NAISSANCE,
CONCAT(EMP_NNI_SEXE, EMP_NNI_DATE_NAISS, EMP_NNI_COMMUNE_NAISS,
EMP_NNI_RANG_NAISS) AS NNI, EMP_DATE_ENTREE, EMP_SALAIRE,
EMP_FONCTION, EMP_SERVICE
FROM S_RH.T_EMPLOYE_EMP;
Les commandes SQL suivantes qui tentent d’ajouter des lignes partent en erreur :
2.
3.
4.
5.
INSERT INTO S_RH.V_EMP_SALARIE_NNI VALUES
(3, 'SCHMIDT', 'Albert', '1982-11-21', '1821154220030',
'2010-03-11', 1450, 'Manoeuvre', 'Logistique'),
(4, 'MOULIN', 'Marc', '1969-11-18', '1691125321007',
'2018-05-20', 3200, 'Vendeur', 'Commercial');
Néanmoins, il sera possible de contourner cette difficulté à l’aide d’un déclencheur INSTEAD OFF.
III-8-1-2. Mise à jour directe dans une vue multi-tabulaire▲
Reprenons les vues créées à l’exemple 3.32 où il est question de personnes génériques, personnes physiques et personnes morales. Pouvons nous faire des mises à jour ? Par exemple insérer ? La réponse est oui, à condition que ces insertions concernent toujours une seule table à la fois, sinon le moteur SQL ne peut pas savoir, par nature – une seule table doit être visée dans une mise à jour – et par logique : combien de lignes (cardinalité) devront être insérées dans chacune des tables ?
Exemple 3.39* – Insertion dans une table à travers la vue des personnes physiques
2.
3.
4.
5.
6.
7.
INSERT INTO S_PRS.V_PERSONNE_PHYSIQUE
(PSG_ID, PSG_DATE_CREATION)
VALUES (987, CURRENT_DATE);
INSERT INTO S_PRS.V_PERSONNE_PHYSIQUE
(PSP_NOM, PSP_PRENOM, PSP_DATE_NAISSANCE)
VALUES ('BONNARD', 'Frédéric', '1963-02-18');
La première insertion est réussie, mais la seconde échoue en indiquant qu’il est impossible d'insérer la « valeur » NULL dans la colonne PSG_ID, table S_PRS.T_PERSONNE_PHYSIQUE_PSP, et pour cause, cette colonne ne figure pas dans la liste d’insertion (PSP_NOM, PSP_PRENOM, PSP_DATE_NAISSANCE), car elle ne figure pas dans la définition de la vue. Si nous tentons de l’ajouter comme ceci :
2.
3.
INSERT INTO S_PRS.V_PERSONNE_PHYSIQUE
(PSG_ID, PSP_NOM, PSP_PRENOM, PSP_DATE_NAISSANCE)
VALUES (987, 'BONNARD', 'Frédéric', '1963-02-18');
Là encore impossible de d’insérer cette ligne car la colonne PSG_ID fait partie de la table des personnes génériques tandis que les colonnes PSP_NOM, PSP_PRENOM, PSP_DATE_NAISSANCE font partie de la table des personnes physiques. Le message d’erreur est généralement assez explicite, du genre : la vue ou la fonction S_PRS.V_PERSONNE_PHYSIQUE ne peut pas être mise à jour car la modification porte sur plusieurs tables de base. Dans ce cas, une solution serait de rajouter dans la vue la colonne PSG_ID de la table des personnes physiques en lui donnant un autre nom. Voici comment modifier la vue pour que l’insertion réussisse :
2.
3.
4.
5.
6.
ALTER VIEW S_PRS.V_PERSONNE_PHYSIQUE
AS
SELECT PG.*, PP.PSG_ID AS PSG_ID_PSP, PSP_NOM , PSP_PRENOM, PSP_DATE_NAISSANCE
FROM S_PRS.T_PERSONNE_GENERIQUE_PSG AS PG
INNER JOIN S_PRS.T_PERSONNE_PHYSIQUE_PSP AS PP
ON PG.PSG_ID = PP.PSG_ID;
Du coup, l’insertion ci-après, réussit :
2.
3.
INSERT INTO S_PRS.V_PERSONNE_PHYSIQUE
(PSG_ID_PSP, PSP_NOM, PSP_PRENOM, PSP_DATE_NAISSANCE)
VALUES (987, 'BONNARD', 'Frédéric', '1963-02-18');
III-8-1-3. Mise à jour d’une vue calculée▲
Qu’en est-il si les informations publiées par une vue ont été transformées ? La mise à jour directe est possible lorsque les informations sont extraites de manière brute des tables. Mais si une colonne fait l’objet de calculs ou de modifications, comment permettre quand même les INSERT, UPDATE et DELETE ?
C’est ce que nous allons voir avec un exemple simple, basé sur la vue de l’exemple 3.38 où toute insertion semblait impossible du fait de la concaténation des éléments du numéro national d’identité (n° de « sécu ») …
Dans un tel cas, if faut recourir à un déclencheur INSTEAD OF (nous verrons les déclencheurs plus en détail au chapitre 7). L’exemple 3.40 montre le code d’un tel déclencheur pour la commande INSERT :
Exemple 3.40* – Déclencheur INSTEAD OF pour permettre l’INSERT sur une vue calculée
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
CREATE TRIGGER E_I_EMP_SALAIRE_NNI
ON S_RH.V_EMP_SALARIE_NNI
INSTEAD OF INSERT
FOR EACH STATEMENT
BEGIN ATOMIC
INSERT INTO S_RH.T_EMPLOYE_EMP
SELECT EMP_ID, EMP_NOM, EMP_PRENOM, EMP_DATE_NAISSANCE,
SUBSTRING(NNI, 1, 1),
SUBSTRING(NNI, 2, 4),
SUBSTRING(NNI, 6, 5),
SUBSTRING(NNI, 10, 3),,
EMP_DATE_ENTREE, EMP_SALAIRE, EMP_FONCTION,
EMP_SERVICE, NULL
FROM new;
END;
Le code de ce trigger intercepte l’insertion de la ligne pour le rerouter sur la table en extrayant bribe par bribe les 4 éléments du numéro de sécurité sociale de la pseudo table « new ». Dès lors les insertions que nous avions tentées sont couronnées de succès :
2.
3.
4.
5.
INSERT INTO S_RH.V_EMP_SALARIE_NNI VALUES
(3, 'SCHMIDT', 'Albert', '1982-11-21', '1821154220030',
'2010-03-11', 1450, 'Manoeuvre', 'Logistique'),
(4, 'MOULIN', 'Marc', '1969-11-18', '1691125321007',
'2018-05-20', 3200, 'Vendeur', 'Commercial');
Enfin, par le même biais d’un déclencheur INSTEAD OF nous pouvons contourner le problème d’insertion multitable… Dans l’exemple 3.39 nous avions modifié la vue S_PRS.V_PERSONNE_PHYSIQUE pour qu’elle expose les colonnes des deux tables. Voici un déclencheur qui permet une insertion simultanée dans les deux tables :
Exemple 3.41* – Déclencheur INSTEAD OF pour insertion dans plusieurs tables à travers une vue
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
CREATE TRIGGER E_I_V_PERSONNE_PHYSIQUE
ON S_PRS.V_PERSONNE_PHYSIQUE
INSTEAD OF INSERT
FOR EACH STATEMENT
BEGIN ATOMIC
INSERT INTO S_PRS.T_PERSONNE_GENERIQUE_PSG
SELECT PSG_ID, COALESCE(PSG_DATE_CREATION, CURRENT_DATE)
FROM new;
INSERT INTO S_PRS.T_PERSONNE_PHYSIQUE_PSP
SELECT PSG_ID, PSP_NOM, PSP_PRENOM, PSP_DATE_NAISSANCE
FROM new;
END;
Dans l’exemple 3.41 nous alimentons les tables de la vue en deux temps, par rapport à la pseudo table « new ». La première insertion dirige les valeurs des colonnes PSG_ID et PSG_DATE_CREATION vers la table des personnes génériques et la seconde le reste des informations vers la table des personnes physiques.
Notez le recours à la fonction COALESCE que nous avons déjà évoquée au chapitre 2 § 2.6 et qui permet de remplacer un marqueur NULL par une valeur, ici la date système.
III-8-2. Restriction de mise à jour des vues modifiables▲
La clause WITH CHECK OPTION implique que, si la vue peut être mise à jour, alors les valeurs modifiées, insérées ou supprimées doivent répondre à la validation de la clause WHERE comme s'il s'agissait d'une contrainte.
Dans la vue de l’exemple 3.37, nous avions une clause WHERE indiquant que la vue était restreinte à tous les employés sauf ceux de la direction (en fait les PDG ne sont pas des salariés…) avec la clause WHERE suivante :
WHERE EMP_SERVICE <> 'Direction'
Lorsque nous avions tenté d’insérer Luc LAMBERT en tant que président à la direction, cette commande avait bien fonctionné mais cette personne n’était plus visible dans la vue… Dans un tel cas, il n’est alors plus possible de modifier (par un UPDATE) les informations de Luc LAMBERT, ni même de le supprimer (par un DELETE) à travers cette vue. Aucun message d’erreur, mais simplement le fait qu’aucune ligne n’est modifiée ou supprimée En revanche il est possible de promouvoir tout autre employé ne faisant pas partie de la direction en tant que membre de la direction.
C’est ce que montre l’exemple 3.42 :
Exemple 3.42* – Mise à jour d’une vue pour des données qualifiées ou non sans CHECK OPTION
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
UPDATE S_RH.V_EMP_SALARIE
SET EMP_DATE_NAISSANCE = '1978-06-30'
WHERE EMP_ID = 2; --> Luc Lambert;
DELETE FROM S_RH.V_EMP_SALARIE
WHERE EMP_ID = 2; --> Luc Lambert;
UPDATE S_RH.V_EMP_SALARIE
SET EMP_SERVICE = 'Direction',
EMP_FONCTION = 'Directeur'
WHERE EMP_ID = 1; --> Marc Dupont;
En modifiant la vue pour y ajouter la qualification des mises à jour qui doivent respecter le filtre WHERE, comme le montre l’exemple 3.42 :
Exemple 3.43* – Modification d’une vue pour y ajouter la clause CHECK OPTION
2.
3.
4.
5.
6.
7.
8.
CREATE VIEW S_RH.V_EMP_SALARIE
AS
SELECT EMP_ID, EMP_NOM, EMP_PRENOM, EMP_DATE_NAISSANCE,
EMP_NNI_SEXE, EMP_NNI_DATE_NAISS, EMP_NNI_COMMUNE_NAISS, EMP_NNI_RANG_NAISS,
EMP_DATE_ENTREE, EMP_SALAIRE, EMP_FONCTION, EMP_SERVICE
FROM S_RH.T_EMPLOYE_EMP
WHERE EMP_SERVICE <> 'Direction'
WITH CHECK OPTION;
Les mises à jour de l’exemple 3.42 vont toutes échouer avec l'apparition d'un message d'erreur comme celui-ci : « L'ordre UPDATE/DELETE a échoué parce qu'une ou plusieurs lignes résultant de l'opération n'étaient pas qualifiées sous la contrainte CHECK OPTION »
Les options CASCADED et LOCAL (CASCADE par défaut) font que la clause CHECK OPTION porte uniquement sur la vue (LOCAL) ou bien sur toutes les vues dérivées qui en dépendent (CASCADED), c’est-à-dire sur les vues construites sur d’autres vues. À défaut de le spécifier l'option CASCADED est prise en compte.
III-8-3. De l’intérêt des vues▲
Les vues SQL sont essentielles et on devrait toujours passer par ces objets qui constituent le modèle externe de Données (ou MED), grand oublié de la plupart des cours et tutoriels de la modélisation des bases de données. En voici les raisons…
III-8-3-1. Simplification de la présentation des données▲
Nous avons constaté avec les tables présentant l’historique de la TVA combien il était difficile de savoir la TVA applicable à telle date. La vue de l’exemple 3.35 présente des données faciles à comprendre par tout utilisateur et sans que les données de la base aient une forme quelconque de redondance… En effet, la tentative est grande de créer une table de l’historique de la TVA qui ait exactement les caractéristiques de la vue, mais ce serait au détriment des performances et de la facilité de mise à jour. En effet une telle table redonderait de manière directe le code de la TVA et de manière indirecte car calculée la date de fin qui n’est autre que la date suivante d’application du même code TVA ou si la TVA est actuelle la date de la fin des temps… Or toute redondance se traduit par des octets supplémentaires et tout octet supplémentaire par un allongement des temps de réponse, ainsi que qu’un allongement de la durée des différentes tâches de la maintenance d’une base de données (défragmentation, sauvegarde, vérification d’intégrité physique…).
III-8-3-2. Facilitation de la gestion de la sécurité▲
L’exemple 3.34 nous a montré que les données d’une table ne doivent pas toutes être présentées aux différentes catégories d’utilisateurs. Nous avons distingué le personnel des ressources humaines (RH), qui doit pouvoir accéder à tout sauf le médecin traitant, les délégués syndicaux ne devant voir aucune des données de numéro de sécurité sociale, ni de salaire, ni le médecin traitant et enfin les acteurs de la médecine du travail qui doivent pouvoir accéder à tout sauf le salaire. Donc trois vues pour trois catégories d’acteurs différents.
|
|
|
Figure 3.9 – Une même table trois vues différentes |
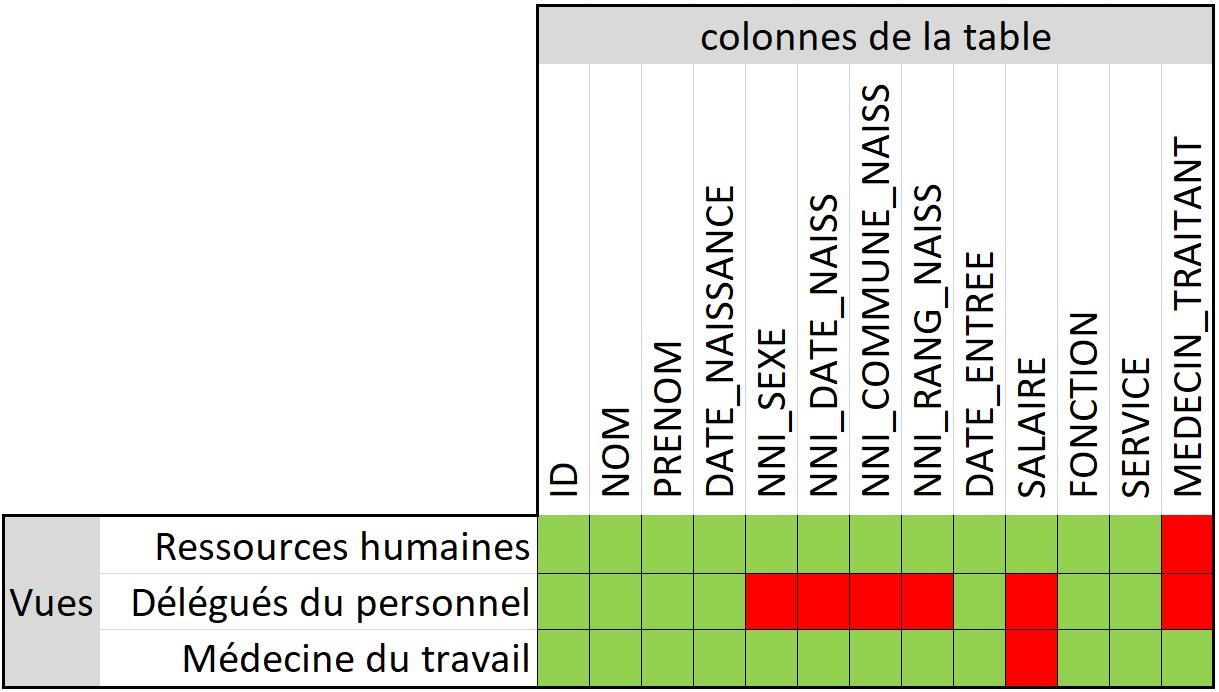
Il devient alors extrêmement facile de donner accès en lecture aux différents acteurs et pour les écritures en restreindre encore les possibilités :
|
|
|
Figure 3.10 – Une même table trois vues différentes et ses différents niveaux d’accès |
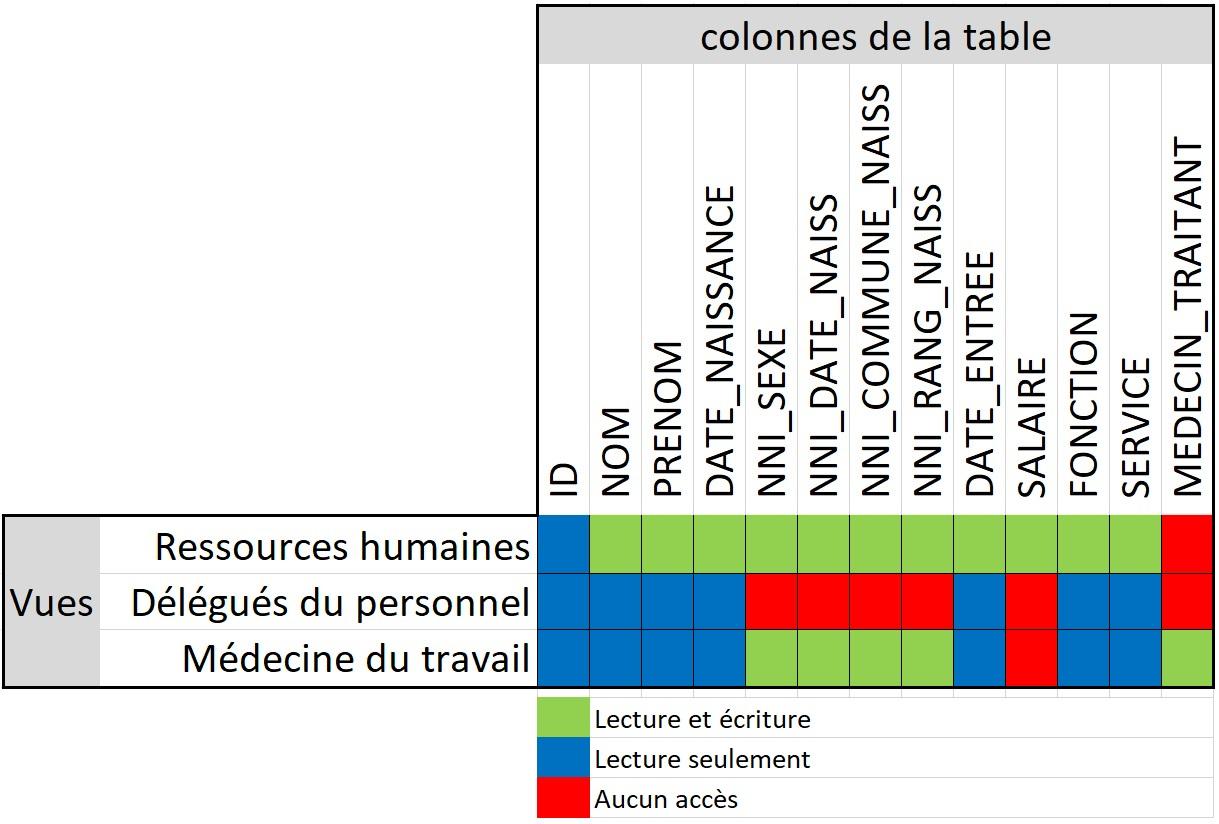
III-8-3-3. Abstraction des tables▲
Les vues constituent une abstraction des tables. C’est un concept similaire à la notion d’objet entre une instance de l’objet et son « moule » constitué par la classe. Mais nous ne sommes pas dans le même univers, car la persistance de l’information doit être prépondérante à toute considération de modification de la structure de l’objet. Dans le monde des objets, aucun objet n’est persistant. Dans le monde des bases de données, tout ce qui porte des données doit persister sous peine de perdre les informations.
Or il arrive que l’on soit dans l’obligation de restructurer la base par exemple en découpant une table devenue obèse (on parle de table obèse, lorsqu’il y figure trop de colonnes par rapport ce que devrait être une modélisation appliquant strictement les règles de l’art…). Une telle restructuration, par exemple couper une table horizontalement en deux parties impacterait la plupart des requêtes déjà écrites et le code de traitement… Mais en utilisant des vues qui assurent une interface entre les données des tables et la couche applicative, il n’y a plus rien à modifier dans le code applicatif, même si l’on découpe la table en plusieurs parties qui seront toutes rassemblées par une vue que l’on rendra modifiable directement ou par le biais de déclencheurs INSTEAD OF.
III-8-3-4. Simulation du comportement objet (CRUD)▲
Finalement, les tables pourvues d’une intégrité référentielle savamment pesée, de la technique des vues, combinées, si besoin est, à des déclencheurs INSTEAD OF et des procédures stockées, fournissent l’aspect CRUD (Create, Read, Update, Delete) dont le monde de la programmation objet revendique la paternité sans jamais avoir vu qu’il existait déjà au sein des SGBDR ! En effet, rappelons que l’acte de naissance les SGBD Relationnels date de 1970 sous la houlette de Franck Edgar Codd, alors que les premiers langages objet réellement opérationnels (smalltalk) datent de 1972…
Au début des années 2000, les connaissances du monde SQL et des SGBD Relationnels étaient assez bien maîtrisées par les développeurs, mais l’arrivée de nouveaux acteurs à la piètre qualité (PostGreSQL, MySQL…), mais aux coûts apparemment moindres, a fait pencher la balance de la connaissance vers le tout programmatique au détriment de l’intelligence des SGBD Relationnels. Et l’on a malheureusement vu l’arrivée d’ORM (Object Retational Mapping) et de « frameworks » censés combler le fossé séparant les deux mondes en offrant malheureusement des performances souvent lamentables, ce que Ted Neward qualifia à l’époque de Viêtnam de l’informatique…
En l’occurrence, CRUD est implémenté dans tous les SGBDR de bonne qualité (Oracle Database, IBM DB2, Microsoft SQL Server), même si l’objet représenté par la vue est composé d’accès à plusieurs tables, par le biais de :
- Create : INSERT INTO par le biais de déclencheurs ou de procédures stockées
- Read : SELECT par le biais de déclencheurs ou de procédures stockées
- Update : UPDATE par le biais de déclencheurs ou de procédures stockées
- Delete : DELETE impactant différentes tables en mode CASCADE par le biais de l’intégrité référentielle
III-9. Colonne calculées et auto incréments▲
Certaines colonnes de table peuvent contenir autre chose que des données brutes. SQL distingue les colonnes calculées et les auto-incréments.
III-9-1. Colonnes calculées▲
La norme SQL:2003 a formalisé un mécanisme déjà bien implanté dans certains SGBDR : les colonnes calculées, que SQL appelle GENERATED COLUMNS. Il s'agit tout simplement de définir dans la table une colonne dont le type sera remplacé par une expression scalaire pouvant être bâtie à partir d'autres colonnes de la table. Une colonne calculée doit être introduite par la clause :
GENERATED { ALWAYS | BY DEFAULT } AS ( <expression_de_calcul> )
Exemple 3.44 : tables avec des colonnes calculées
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
CREATE TABLE S_COM.T_FACTURE_ENTETE_FCE
(FCE_ID INTEGER PRIMARY KEY,
CLI_ID INTEGER NOT NULL
REFERENCES S_COM.T_CLIENT_CLI (CLI_ID),
FCE_DATE DATE NOT NULL DEFAULT CURRENT_DATE,
FCE_REMISE_POURCENT FLOAT NOT NULL DEFAULT 0
CHECK (VALUE BETWEEN 0 AND 100),
FCE_TOTAL_HT GENERATED ALWAYS AS
((SELECT SUM(FCD_PRIX_VENTE_HT)
FROM S_COM.T_FACTURE_ETAIL_FCD AS T
WHERE T.FCE_ID = FCE_ID) * (1 - FCE_REMISE_POURCENT / 100.0)),
FCE_TOTAL_TVA GENERATED ALWAYS AS
((SELECT SUM(FCD_TVA)
FROM S_COM.T_FACTURE_ETAIL_FCD AS T
WHERE T.FCE_ID = FCE_ID) * (1 - FCE_REMISE_POURCENT / 100.0)));
CREATE TABLE S_COM.T_FACTURE_ETAIL_FCD
(FCD_ID INTEGER PRIMARY KEY,
FCE_ID INTEGER NOT NULL
REFERENCES S_COM.T_FACTURE_ENTETE_FCE (FCE_ID) ON DELETE CASCADE,
PRD_ID INTEGER NOT NULL
REFERENCES S_COM.T_PRODUIT_PRD (PRS_ID),
FCD_PRIX_UNITAIRE_HT DECIMAL(16, 2) NOT NULL
CHECK (VALUE >= 0),
FCD_QUANTITE FLOAT NOT NULL DEFAULT 1
CHECK (VALUE > 0),
FCD_REMISE_POURCENT FLOAT NOT NULL DEFAULT 0
CHECK (VALUE BETWEEN 0 AND 100),
TVA_ID INTEGER
REFERENCES S_REF.T_TVA (TVA_ID),
FCD_PRIX_VENTE_HT GENERATED ALWAYS AS
(FCD_PRIX_UNITAIRE_HT * FCD_QUANTITE * (1 - FCD_REMISE_POURCENT / 100.0)),
FCD_TVA GENERATED ALWAYS AS
(FCD_PRIX_VENTE_HT
* (1 + COALESCE((SELECT TVA_TAUX
FROM S_REF.T_TVA AS T
WHERE T.TVA_ID = TVA_ID), 0))));
Cependant, et pour les mêmes raisons que cellesinvoquées concernant les contraintes de validation CHECK, la plupart des SGBDR refusent les expressions de calcul portant sur d’autres choses que la ligne courante de la table. Est donc généralement interdit dans l’expression d’une colonne calculée :
- un accès à plus d’une ligne de la table hôte ;
- un accès à une table externe à la table hôte.
Nous verrons au chapitre 7 que les vues matérialisées peuvent correspondre, sous certaines conditions à l’obtention d’un résultat similaire.
En l’occurrence, seule la colonne calculée FCD_PRIX_VENTE_HT est prise en compte dans la plupart des SGBDR.
III-9-2. Auto incréments▲
Il existe deux méthodes bien distinctes. L’usage de la propriété IDENTITY qui s’applique à une colonne d’une table, et l’objet SEQUENCE indépendant qui fournit des valeurs par le biais d’un appel intégré soit dans la définition de la colonne d’une table soit dans un déclencheur BEFORE.
|
|
ATTENTION |
III-9-2-1. Propriété IDENTITY▲
La propriété IDENTITY se définit dans la table comme colonne calculée à la place de la contrainte par défaut après la définition du type SQL de la colonne comme suit :
GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY
[ ( <option_autoincrément> ) ]Les arguments de cette propriété sont les suivants :
- START WITH <valeur> : initialisation de l'incrément
- INCREMENT BY <valeur> : initialisation du pas d'incrément
- MAXVALUE <valeur> | NO MAXVALUE : spécification ou suppression de la valeur maximale de l'auto incrément
- MINVALUE <valeur> | NO MINVALUE : spécification ou suppression de la valeur minimale de l'auto incrément
- CYCLE | NO CYCLE : spécification de cycle ou non.
- CACHE n | NO CACHE : indique si des valeurs précalculées doivent être mises en mémoire
Il ne peut y avoir qu’une seule colonne de la table pourvue de ce type d’auto-incrément.
Par défaut les options sont de démarrer à 1 par pas de 1 sans aucune autre option.
Il doit être utilisé sur une colonne de type entier.
Exemple 3.45* – Table pourvu de l’auto incrément IDENTITY
2.
3.
4.
5.
6.
7.
8.
9.
CREATE TABLE S_ADM.T_UTILISATEUR_USR
(USR_ID INTEGER
GENERATED ALWAYS AS IDENTITY
(START WITH -2147483648
INCREMENT BY 1
NO CYCLE
CACHE 100)
CONSTRAINT PK_USR PRIMARY KEY,
USR_LOGIN VARCHAR(256) NOT NULL);
|
|
ATTENTION |
III-9-2-2. Objet SEQUENCE▲
C’est un objet indépendant de toute table dont la syntaxe est :
2.
3.
4.
5.
6.
7.
8.
CREATE SEQUENCE [ nom_schema. ] nom_sequence
AS { <type_SQL_entier> | nom_domaine_entier }
[ START WITH <valeur> ]
[ INCREMENT BY <valeur> ]
[ { MINVALUE [ <valeur> ] } | { NO MINVALUE } ]
[ { MAXVALUE [ <valeur> ] } | { NO MAXVALUE } ]
[ CYCLE | { NO CYCLE } ]
[ { CACHE [ <valeur> ] } | { NO CACHE } ]
Observez qu’il possède les mêmes caractéristiques que la propriété IDENTITY.
Pour en obtenir une valeur il faut faire appel à la commande :
NEXT VALUE FOR [ nom_schema. ] nom_sequence
[ OVER ( <clause_orde_by_over> ) ]Pour opérer comme valeur d’une colonne de table, il doit être placé dans la contrainte par défaut de la colonne visée.
La clause OVER du séquenceur ne peut être invoquée que dans une commande de lecture SELECT ou un ordre UPDATE.
Exemple 3.46* – Définition d’une séquence et utilisation
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
CREATE SEQUENCE S_SYSTEM.SQC_TOUTES_TABLES
AS BIGINT
START WITH 1
INCREMENT BY 255
NO CYCLE
CACHE 10000;
-- utilisation dans la définition d'une table
CREATE TABLE S_ADM.T_UTILISATEUR_USR
(USR_ID INTEGER NOT NULL
DEFAULT NEXT VALUE FOR S_SYSTEM.SQC_TOUTES_TABLES
CONSTRAINT PK_USR PRIMARY KEY,
USR_LOGIN VARCHAR(256) NOT NULL);
-- utilisation dans une requêtes d'extraction SELECT
SELECT NEXT VALUE FOR S_SYSTEM.SQC_TOUTES_TABLES
OVER(ORDER BY EMP_DATE_NAISSANCE ),
*
FROM S_RH.T_EMPLOYE_EMP;
III-10. Modification et suppression des objets▲
SQL permet de modifier les objets créés à l'aide de l'ordre ALTER et de les supprimer à l'aide de la commande DROP.
Le principe général est le suivant : on peut modifier les caractéristiques d'un objet, à condition de ne pas entraîner de pertes de données. On peut supprimer un objet, mais si cet objet dépend d'autres objets (par exemple pour une table mère d'une intégrité référentielle ou une table d'une vue) il faut spécifier que l'on veut aussi entraîner la suppression en cascade des objets dépendants.
III-10-1. Suppression des objets▲
La syntaxe est simple :
DROP <type_objet> <nom_objet> [ { RESTRICT | CASCADE } ]
Avec :
<type_objet> ::=
{ DATABASE | SCHEMA | DOMAINE | SEQUENCE | TABLE | ASSERTION | VIEW }
<nom_objet> ::= [ nom_schema.]nom_objetRESTRICT est par défaut, sauf dans le cas de DATABASE (la base de données) dont la suppression entraîne la perte de tout le contenu de la base.
CASCADE n’est pas disponible pour le domaine mais la suppression est réussie dans tous les cas car le domaine se propage par copie de sa définition.
|
|
ATTENTION |
La suppression d’un schéma en mode CASCADE peut échouer s’il existe des intégrités référentielles entre tables de différents schémas.
La suppression d’une table en mode CASCADE supprimera toutes les tables filles liées par l’intégrité référentielle mais échouera si la table elle-même est une fille d’une intégrité référentielle à un niveau supérieur.
Exemple 3.47 – Suppression de divers objets
2.
3.
4.
DROP SCHEMA S_COM WITH CASCADE;
DROP TABLE S_ADM.T_UTILISATEUR_USR;
DROP SEQUENCE S_SYSTEM.SQC_TOUTES_TABLES;
DROP VIEW S_TAXE.V_TVA WITH CASCADE;
|
|
NOTE |
III-10-2. Modifier une base de données ou la supprimer▲
La norme SQL ne propose pas de commande pour modifier une base de données. Notons cependant que tous les éditeurs permettent de modifier des éléments d’une base de données, comme par exemple la collation par défaut, le stockage, différents paramétrages, etc.
La syntaxe générale pour ce faire est :
ALTER DATABASE nom_base <commande_modifiant_la_base>;
Pour supprimer une base de données, la commande est :
DROP DATABASE nom_base;
|
|
ATTENTION |
III-10-3. Modifier un schéma SQL▲
Bien que la norme SQL ne propose aucune manière de modifier un SCHEMA la plupart des éditeurs de SGBDR proposent une commande ALTER SCHEMA, par exemple pour en changer le propriétaire du schéma (nous verrons cette notion au chapitre 8 consacré à la sécurité), ou encore, renommer le schéma ou transférer des objets d’un schéma dans l’autre, etc.
La syntaxe générale pour ce faire est :
ALTER SCHEMA nom_schema <option_modification_schema>;
Pour supprimer un schéma SQL, la commande est :
DROP SCHEMA nom_schema [ { RESTRICT | CASCADE } ];
III-10-4. Modifier un DOMAIN▲
La syntaxe de l’ordre SQL ALTER DOMAIN est la suivante :
2.
3.
4.
5.
ALTER DOMAIN nom_domaine
{ SET DEFAULT <valeur_par_défaut> |
DROP DEFAULT |
ADD <contrainte_de_domaine> |
DROP CONSTRAINT <nom_contrainte> }
|
|
ATTENTION
|
Exemple 3.48 – Modification d’un domaine SQL
2.
3.
4.
5.
CREATE DOMAIN S_TYPE.D_JOUR_SEMAINE
AS CHAR(8)
DEFAULT 'Dimanche'
CONSTRAINT CK_D_JOUR CHECK (VALUE IN ('Lundi', 'Mardi', 'Mercredi',
'Jeudi', 'Vendredi', 'Samedi', 'Dimanche'));
On peut changer la contrainte listant les valeurs comme ceci :
2.
3.
4.
5.
6.
7.
8.
ALTER DOMAIN S_TYPE.D_JOUR_SEMAINE
DROP DEFAULT
DROP CONSTRAINT CK_D_JOUR;
ALTER DOMAIN S_TYPE.D_JOUR_SEMAINE
SET DEFAULT 'DIM';
ADD CONSTRAINT CK_D_JOUR CHECK (VALUE IN ('LUN', 'MAR', 'MER',
'JEU', 'VEN', 'SAM', 'DIM'));
S’il existe des informations conformes à l’ancienne définition du domaine, une violation de contrainte de domaine se produira.
III-10-5. Modifier une séquence ou un IDENTITY▲
On peut modifier les caractéristiques d’une séquence par le biais de la commande :
2.
3.
4.
5.
6.
7.
8.
ALTER SEQUENCE [ nom_schema.] nom_sequence
AS { <type_SQL_entier> | nom_domaine_entier }
[ START WITH <valeur> ]
[ INCREMENT BY <valeur> ]
[ { MINVALUE [ <valeur> ] } | { NO MINVALUE } ]
[ { MAXVALUE [ <valeur> ] } | { NO MAXVALUE } ]
[ CYCLE | { NO CYCLE } ]
[ { CACHE [ <valeur> ] } | { NO CACHE } ];
Pour un IDENTITY, les paramètres modifiables sont les mêmes, mais doivent être modifiés via la commande ALTER TABLE en précisant le nom de la colonne.
Syntaxe de l’ajout d’un IDENTITY à une colonne existante :
2.
3.
4.
ALTER TABLE [ nom_schéma.] nom_table
ALTER [ COLUMN ] nom_colonne
ADD GENERATED { ALWAYS | BY DEFAULT } AS IDENTITY
[ ( <options_identity> ) ];
Syntaxe de la modification des propriétés d’un IDENTITY lié à une colonne existante :
2.
3.
4.
5.
ALTER TABLE[ nom_schéma.] nom_table
ALTER [ COLUMN ] nom_colonne
{ SET GENERATED { ALWAYS| BY DEFAULT }
| SET <options_identity>
| RESTART [ [ WITH ] graine ] }
Les options identity sont les mêmes que celle de la séquence. Graine est la nouvelle valeur initiale de l’identity.
Syntaxe de la suppression d’un IDENTITY à une table :
ALTER TABLE[ nom_schéma.] nom_table DROP IDENTITY
Exemple 3.49 – Divers modification d’IDENTITY
2.
3.
4.
5.
6.
7.
8.
9.
ALTER TABLE S_ADM.T_UTILISATEUR_USR
ALTER COLUMN USR_ID
RESTART WITH 1;
ALTER TABLE S_ADM.T_UTILISATEUR_USR
ALTER COLUMN USR_ID
SET GENERATED BY DEFAULT;
ALTER TABLE S_ADM.T_UTILISATEUR_USR
ALTER COLUMN USR_ID
SET MAXVALUE 32765, CYCLE;
III-10-6. Supprimer une table ou en modifier la structure▲
La commande SQL DROP TABLE, permet de supprimer une table. Comme dans le cadre du DROP SCHEMA, elle prend elle aussi un éventuel paramètre RESTRICT ou CASCADE permettant de définir si une exception est levée et l'ordre annulé dans le cas ou la table est référencée par une vue, une assertion, un déclencheur ou une routine (RESTRICT), ou encore s'il faut aussi détruire en chaîne les objets ainsi référencés (CASCADE).
Plus intéressant est l'ordre SQL ALTER TABLE de modification d'une table, dont la syntaxe est la suivante :
2.
3.
4.
5.
6.
7.
8.
9.
ALTER TABLE nom_table
ADD [ COLUMN ] nom_colonne <type_ou_domaine> [ nom_collation ]
[ [ NOT ] NULL] [ <liste_constrainte>
| DROP [ COLUMN ] nom_colonne { RESTRICT | CASCADE }
| ALTER [ COLUMN ] nom_colonne SET DEFAULT <valeur_par_defaut>
| ALTER [ COLUMN ] nom_colonne DROP DEFAULT
| ALTER [ COLUMN ] nom_colonne <identity_option>
| ADD CONSTRAINT <contrainte_de_table>
| DROP CONSTRAINT nom_contrainte { RESTRICT | CASCADE }
On note donc qu'il est possible :
- d’jouter ou supprimer une colonne ou une contrainte de table ;
- d’ajouter ou supprimer une valeur par défaut à une colonne.
On en déduit qu'il n'est pas possible :
- de modifier le type de données ou le nom de la colonne;
- de supprimer ou ajouter une contrainte de colonne et en particulier jamais pour la contrainte de type NULL / NOT NULL;
- de modifier la collation d'une colonne existante.
Dans le cas de la suppression de la colonne avec l'option CASCADE, alors tous les objets (vues, assertions, déclencheurs, routines...), à commencer par les contraintes internes à la table et référençant cette colonne, sont supprimés.
Exemple 3.50 – Modification de la structure d’une table
En partant de la table ainsi définie :
2.
3.
4.
5.
6.
7.
8.
CREATE TABLE S_ADM.T_UTILISATEUR_USR
(USR_NOM CHAR(32) NOT NULL,
USR_PRENOM VARCHAR(16) NOT NULL,
USR_MAIL VARCHAR(256) NOT NULL,
USR_ORG VARCHAR(128),
CONSTRAINT PK_USR_NOMPRE PRIMARY KEY (USR_NOM, USR_PRENOM),
CONSTRAINT UK_USR_MAIL UNIQUE (USR_MAIL),
CONSTRAINT UK_USR_NOMORG UNIQUE (USR_NOM, USR_ORG));
La séquence des ordres suivants :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
ALTER TABLE S_ADM.T_UTILISATEUR_USR
DROP COLUMN USR_ORG
CASCADE;
ALTER TABLE S_ADM.T_UTILISATEUR_USR
ADD COLUMN USR_ID INTEGER NOT NULL;
ALTER TABLE S_ADM.T_UTILISATEUR_USR
DROP CONSTRAINT PK_USR_NOMPRE;
ALTER TABLE S_ADM.T_UTILISATEUR_USR
ADD CONSTRAINT PK_USR PRIMARY KEY (USR_ID);
…a pour effet d'obtenir la structure de table suivante :
2.
3.
4.
5.
6.
7.
CREATE TABLE S_ADM.T_UTILISATEUR_USR
(USR_NOM CHAR(32) NOT NULL,
USR_PRENOM VARCHAR(16) NOT NULL,
USR_MAIL VARCHAR(256) NOT NULL,
USR_ID INTEGER NOT NULL,
CONSTRAINT UK_USR_MAIL UNIQUE (USR_MAIL),
CONSTRAINT PK_USR PRIMARY KEY (USR_ID));
Bien que SQL n'ait pas prévu la possibilité de modifier directement le type ou le nom d'une colonne, on peut utiliser un script SQL transactionnel en plusieurs étapes pour y parvenir.
En partant de la structure de la table S_ADM.T_UTILISATEUR_USR obtenue dans l’exemple 3.49, voici un exemple de script SQL qui change le type et le nom de la colonne USR_MAIL en USR_USER_EMAIL NVARCHAR(128), ajoute une colonne référençant le DNS depuis la table S_ADM.T_DNS, coupe l’email en deux parties : la partie nom d’utilisateur allant dans la colonne USR_USER_EMAIL et le DNS faisant référence à la table des DNS dont la description est la suivante :
2.
3.
CREATE TABLE S_ADM.T_DNS
(DNS_ID INTEGER PRIMARY KEY,
DNS_NAME VARCHAR(128) NOT NULL UNIQUE);
Le tout en préservant les données…
Exemple 3.51 – Modification de table incluant un changement de nom de colonne
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
ALTER TABLE S_ADM.T_UTILISATEUR_USR
ADD USR_USER_EMAIL NVARCHAR(128) NOT NULL,
DNS_ID INTEGER NOT NULL REFERENCES S_ADM.T_DNS(DNS_ID);
UPDATE S_ADM.T_UTILISATEUR_USR
SET USR_USER_EMAIL =
SUBSTRING(USR_MAIL FROM 1
FOR CHARACTER_LENGTH(USR_MAIL)
-POSITION('@' IN USR_MAIL)-1),
DNS_ID = (SELECT DNS_ID
FROM S_ADM.T_DNS
WHERE DNS_NAME =
SUBSTRING(USR_MAIL FROM
POSITION('@' IN USR_MAIL) + 1 FOR
CHARACTER_LENGTH(USR_MAIL)
- POSITION('@' IN USR_MAIL)));
ALTER TABLE S_ADM.T_UTILISATEUR_USR
ADD CONSTRAINT UK_USR_MAIL UNIQUE (USR_USER_EMAIL, DNS_ID);
ALTER TABLE S_ADM.T_UTILISATEUR_USR
DROP COLUMN USR_MAIL CASCADE;
Qui donne au final la table suivante :
2.
3.
4.
5.
6.
7.
8.
CREATE TABLE S_ADM.T_UTILISATEUR_USR
(USR_NOM CHAR(32) NOT NULL,
USR_PRENOM VARCHAR(16) NOT NULL,
USR_ID INTEGER NOT NULL,
USR_USER_EMAIL NVARCHAR(128) NOT NULL,
DNS_ID INTEGER NOT NULL REFERENCES S_ADM.T_DNS(DNS_ID)
CONSTRAINT PK_USR PRIMARY KEY (USR_ID)
CONSTRAINT UK_USR_MAIL UNIQUE (USR_USER_EMAIL, DNS_ID));
On peut être surpris de voir que la première commande ALTER TABLE fonctionne alors que l’on a spécifié NOT NULL pour la colonne DNS_ID sans préciser de valeur par défaut. Mais lors d’une modification de table avec ajout de colonne, les lignes déjà présentes ne sont pas vérifiées pour les valeurs de la nouvelle colonne. On en conclut donc que l’obligation de valeurs ne porte que sur les opérations futures de mise à jour et non sur le passé. Mais le langage SQL a prévu que l’on puisse forcer les valeurs par défaut dans les lignes actuelles à condition que l’option WITH VALUES soit mentionnée juste après la valeur par défaut. À titre d’exemple on aurait pu lancer la commande suivante :
2.
3.
4.
ALTER TABLE S_ADM.T_UTILISATEUR_USR
ADD USR_USER_EMAIL NVARCHAR(128) NOT NULL,
DNS_ID INTEGER NOT NULL DEFAULT 1 WITH VALUES
REFERENCES S_ADM.T_DNS(DNS_ID);
On conçoit facilement qu'il est préférable d'utiliser un outil de modélisation de données capable d'automatiser de tels script SQL de modification de table.
III-10-7. modifier une ASSERTION▲
Il n'est pas possible de modifier une assertion, mais il est possible de la supprimer à l'aide de l'ordre SQL DROP ASSERTION puis de la recréer, le tout dans une transaction explicite.
III-10-8. Renommer un objet▲
La norme SQL n’a pas prévu la possibilité de changer le nom d’un objet et propose de le supprimer puis le recréer. Pour une table, il est plus facile de la recopier par création à la volée et détruire la table source (voire paragraphe suivant).
Certains SGBDR proposent une option de de changement de nom intégrée à la commande ALTER.
C’est le cas de PostGreSQL qui permet la commande :
ALTER <type_objet> [ nom_schema. ] nom_objet RENAME TO nouveau_nom;
…pour un objet de premier niveau (table, vue, …) et :
2.
3.
ALTER TABLE [ nom_schema. ] nom_table
{ RENAME [ COLUMN ] nom_colonne TO nouveau_nom_colonne
| RENAME CONSTRAINT nom_constrainte TO nouveau_nom_constrainte
…pour un objet de second niveau (colonnes, contraintes, …).
Ces commandes spécifiques à PostGreSQL ne permettent pas de changer le schéma de l’objet. Pour déplacer un objet d’un schéma à l’autre il faut utiliser la commande PostGreSQL :
ALTER <type_objet> [ nom_schema. ] nom_objet SET SCHEMA autre_nom_schéma;
Dans les deux syntaxes ci-avant :
<type_objet> ::= { SCHEMA | TABLE | VIEW | DOMAIN }
Exemple 3.52 – Renommage d’une table et déplacement dans un autre schéma (PostGreSQL).
2.
ALTER TABLE S_ADM.T_DNS RENAME TO T_NOM_SERVEUR_WEB_DNS;
ALTER TABLE S_ADM.T_NOM_SERVEUR_WEB_DNS SET SCHEMA S_INTERNET;
Dans Microsoft SQL Server ceci se fait, pour le changement de nom, à l’aide de la procédure stockée sp_rename et pour le changement de schéma avec ALTER SCHEMA :
EXEC sp_rename '[ nom_schema. ] nom_objet' , 'nouveau_nom_objet', '<type_classe>';
Dans lequel :
<type_classe ::= { COLUMN | DATABASE | <object_name> }
La sous-classe object_name devant être le nom d’une contrainte (CHECK, FOREIGN KEY, PRIMARY KEY, UNIQUE…) par exemple.
|
|
ATTENTION |
Enfin, la commande :
ALTER SCHEMA nom_schéma TRANSFERT [ nom_schéma. ] nom_objet;
…permet de transférer tout objet dans son nouveau schéma.
Exemple 3.53 – Renommage d’une table et déplacement dans un autre schéma (SQL Server).
2.
EXEC sp_rename 'S_ADM.T_DNS', 'T_NOM_SERVEUR_WEB_DNS', 'OBJECT';
ALTER SCHEMA S_INTERNET TRANSFER S_ADM.T_NOM_SERVEUR_WEB_DNS;
III-10-9. Création ou modification▲
Certains SGBDR permettent de modifier un objet, ou si l’objet n’existe pas de le créer. C’est la commande CREATE OR ALTER, disponible uniquement pour certains objets comme des domaines, des vues… mais pas des tables.
La syntaxe générale est :
CREATE OR ALTER [ nom_schéma.]nom_objet <definition_objet>
III-10-10. Suppression si présence▲
Certains SGBDR permettent de supprimer un objet uniquement au cas où ce dernier existe déjà.
La syntaxe générale est :
IF EXISTS DROP <classe_objet> [nom_schéma.]nom_objet [;]
Comme dans le cas de la création ou modification, cela évite une erreur si l'objet n'existe pas dans le cadre de l'ALTER ou du DROP.
III-11. Création d'une table à la volée▲
SQL permet de créer une table à la volée en partant, soit d'une expression de requête SELECT, soit d'une autre table.
III-11-1. Création d'une table basée sur une autre table▲
Pour créer une table en partant d'une autre table, il suffit de préciser, n'importe où à la place d'une définition de colonne, le mot clé LIKE et de l'accompagner du nom de la table. On peut ajouter des colonnes supplémentaires ou bien exclure certaines colonnes comme le montre la syntaxe suivante :
2.
3.
4.
5.
6.
7.
8.
CREATE TABLE [ nom_schéma.]nom_table
(LIKE [ nom_schéma.]nom_autre_table <options_like>
<options_like> ::= option1 [, option2 [, option3 ] ]
<optionN> ::= { INCLUDING | EXCLUDING } IDENTITY
| { INCLUDING | EXCLUDING } DEFAULTS
| { INCLUDING | EXCLUDING } GENERATED
Exemple 3.52 – Création d’une table vide empruntant la structure d’une table existante :
2.
CREATE TABLE S_ADM.T_LISTE_UTILISATEUR_LUT
(LIKE S_ADM.T_UTILISATEUR_USR);
III-11-2. Création d'une table basée sur une requête▲
Il est possible de créer une table à partir d'une expression de requête d'extraction de l'information (les requêtes SELECT d'extraction de l'information SELECT seront vues aux chapitres 4 et 5). Une syntaxe simplifiée est la suivante :
2.
3.
4.
5.
CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY } ]
TABLE [nom_schéma.]nom_table
[ ON COMMIT { PRESERVE ROWS | DELETE ROWS } ]
AS ( <requête_SELECT> )
[ WITH [ NO ] DATA ]
La clause ON COMMIT n’est valable que si la table est temporaire et permet de conserver ou supprimer les lignes ayant été mises à jour (INSERT, UPDATE, DELETE) pendant la transaction explicite. Nous expliquerons ce point plus en détail au chapitre 7.
DATA : signifie que les données émanent de la requête seront insérées à la suite de la création de la table. Dans le cas contraire (NO DATA) la table sera créée vide. Par défaut la table est copiée avec ses données
Exemple 3.53 – Création d’une table à partir d’une requête :
2.
3.
4.
5.
6.
CREATE TEMPORARY LOCAL TABLE T_USR
AS ( SELECT USR_PRENOM, USR_NOM,
USR_USER_EMAIL || '@' || DNS_NAME AS DEMAIL
FROM S_ADM.T_UTILISATEUR_USR AS U
JOIN S_ADM.T_DNS AS D ON U.DNS_ID = D.DNS_ID)
WITH DATA;
Créé une table temporaire locale avec les noms et prénoms des utilisateurs et leur email reconstitué.