


I. Chapitre 1 - Les bases de données et le langage SQL▲
Le langage SQL est le fruit d'années de réflexion sur la problématique de manipulation des données. Formalisé et normalisé, ce langage est né dans les années 80 et a vite été adopté par la majorité des éditeurs.
Grâce à un comité de normalisation dynamique, il s’est constamment adapté aux besoins des utilisateurs. Ainsi, après la norme SQL 2 de 1992 formant le cœur du langage, on trouve des versions majeures et mineures en 1999, 2003, 2006, 2008, 2011, 2016, 2019 et 2023 !
SQL repose sur deux principes fondamentaux : l'algèbre relationnelle (une branche des mathématiques conçue pour traiter des données de manière ensembliste) et la modélisation des données à base d'entités et de relations qui elle-même repose sur des concepts mathématiques (théorèmes de Heath et Fagin-Date, axiomes d’Armstrong…) traduits en un formalisme pratique (formes normales).
Ce sont les sujets que nous allons aborder dans ce chapitre et nous terminerons en présentant la base de données qui nous servira de fil rouge pour la majorité des exemples du livre et certains exercices.
I-1. Historique des systèmes de gestion de bases de données (SGBD)▲
Comme beaucoup de technologies de l’informatique aujourd'hui matures, les bases de données relationnelles sont nées des travaux d’IBM entre les années 1960 et 1970. De nombreux travaux de recherche ont été menés au cours de cette période avec les modèles de données hiérarchiques, réseaux et relationnels. Finalement le relationnel a été unanimement adopté par la suite et programmé à l’aide du langage SQL (Structured Query Language).
Le succès du langage SQL et sa longévité sont liés au fait qu’il repose sur une théorie mathématique et un langage complet au sens de Turing, à la différence de tous les autres systèmes de bases de données. Il est donc parfaitement adapté au traitement des données dans un contexte ou ces données sont fortement structurées, comme c’est le cas de l’informatique de gestion (ressources, humaines, comptabilité, relation client, ventes, gestion des stocks, etc.).
La théorie sur laquelle repose SQL a été énoncée par le professeur Edgar Frank Codd (1924-2003), un mathématicien d’Oxford, alors qu’il travaillait en tant que chercheur pour le compte d’IBM au laboratoire de San Jose. L’article « A relational model of data for large shared data banks », publié en juin 1970 dans la revue Association for Computing Machinery, fait toujours office de référence en la matière et a inspiré tous les travaux qui ont suivi et qui perdurent.
|
|
|
Figure 1.1 – Article original de 1970 de Codd sur le relationnel |

Codd voulait créer un système où l’interrogation des données devait utiliser le vocabulaire anglais. Après le voyage sur la lune, les travaux de la NASA sur la base de données modélisant les rochers rapportés ont aidé au développement de ce langage en lui donnant de la crédibilité.
Dès 1974, IBM entamait le prototype de bases de données relationnelles appelé System/R. Ce projet se terminait en 1979 prouvant ainsi la viabilité d’un tel système. Le langage de programmation utilisé par IBM pour System/R fut appelé SEQUEL (Structured English Query Language) rebaptisé par la suite SQL (Structured Query Language) car le nom SEQUEL était une marque de l’avionneur Hawkker-Siddeley, mais la prononciation de SQL est restée celle du SEQUEL (entendre en français si-cou-elle ). Comme tout langage, SQL a eu ses concurrents, le plus connu fut QUEL du SGBD Ingres du début des années 1980. Il y eut aussi SQUARE, ISBL, QBE, …
Bien qu’étant le précurseur de SQL, IBM ne fut pas le premier éditeur de SGBD. Ce privilège revint à Honeywell Information Systems, qui commercialisa un produit en juin 1976 tombé depuis en désuétude. À cette même période, un groupe d’ingénieurs attentifs aux résultats du projet System/R réalisèrent le premier produit commercial vraiment opérationnel au sein de la société Relational Software. En 1979, ils appelèrent leur système Oracle Version 2, premier d’une longue lignée, la version 1 n’ayant jamais existé (question de marketing…). Concurremment System R évolua vers le produit commercial SQL/DS qui devint DB2, nom toujours utilisé pour désigner le SGBDR d’IBM.
Microsoft n’est entrée qu’en 1994 dans ce marché, après un accord de partage du code du serveur de données de Sybase. Le contrat consistait pour Microsoft à porter ce SGBDR sous Windows et à en rétrocéder le code. À l’époque, ce SGBDR était le plus avancé : Sybase ayant inventé, avec SQL Server, le client/serveur, les déclencheurs, les procédures stockées, l’optimisation basée sur les coûts et le cache des plans d’exécution. … Rien que cela ! Mais Sybase ayant plus de confiance dans l’imposant IBM, entrepris une couteuse refonte de son produit pour le porter dans le système d’exploitation OS/2, en partenariat avec Ashton-Tate… En 1993, Sybase finit par vendre le code à Microsoft et les deux produits devinrent indépendants. Pour ne pas faire de confusion avec Microsoft SQL Server, Sybase rebaptisa son SGBDR ASE (Adaptive Server Enterprise).
Aujourd’hui IBM avec DB2, Oracle avec Oracle Database et Microsoft avec SQL-Server se partagent majoritairement le marché des SGBDR d’entreprise. Tandis que quelques outsiders du libre se sont implantés à partir de la fin des années 90.
I-2. Évolution des SGBD – années 80-90▲
Au cours des vingt années qui vont de 1980 à 2000, l'évolution des SGBD s'est effectuée en trois étapes :
- SGBD relationnels mettant en oeuvre les théories de Codd (INGRES par exemple) ;
- SGBD orientés objet afin de coller à la conception et la programmation objet (O² par exemple) ;
- SGBD relationnels objet (Oracle, IBM DB2, MS SQL Server par exemple).
Ces derniers sont aujourd'hui les plus répandus, car ils constituent une approche mixte – comme les langages C++ ou java – aujourd'hui reconnue et entérinée par la norme SQL, car proposant une évolution souple vers l'objet, en conservant les avantages et la simplicité de l'approche relationnelle.
I-2-1. SGBD relationnels▲
Le succès des SGBDR repose sur :
- le modèle de données relationnel qui s’appuie sur une théorie rigoureuse (théorie des bases de données et algèbre relationnelle) avec des principes simples ;
- l’indépendance entre données et traitements qui améliore la maintenance des programmes d’application (la modification d’une structure de données a peu de répercussions en théorie sur les programmes) ;
- l’indépendance vis-à-vis des systèmes d’exploitation et des couches basses réseaux (les données de la base sont indépendantes de ces derniers) ;
- la gestion des privilèges mixant éléments de la base de données et actions (ordre SQL) pour une sécurité maximale ;
- des systèmes bien adaptés aux grandes applications informatiques de gestion et qui ont acquis une maturité sur le plan de la fiabilité et des performances (évolution d’échelle – "scalabilité") ;
- Un langage SQL puissant et concis ; il peut souvent s’interfacer avec des langages de troisième génération (C, Ada, Cobol), mais aussi avec des langages plus récents (C++, Java, C#) ;
- des systèmes répondant parfaitement à des architectures de type client-serveur (passerelles ODBC et JDBC notamment) et Intranet ou Internet (configurations à plusieurs tiers).
Les limitations de la majorité des systèmes actuels sont les suivantes :
- la simplicité du modèle de données et le fait que le langage SQL soit natif et déclaratif nécessitent d’interfacer le SGBDR avec un langage de programmation évolué. De ce fait, le dialogue entre la base et le langage n’est plus direct et implique de maîtriser plusieurs technologies ;
- la normalisation conduit à l’accroissement du nombre de relations. Ainsi, si deux objets doivent être liés en mémoire, il faut simuler ce lien au niveau de la base par un mécanisme de clefs étrangères ou de tables de corrélation. Parcourir un lien implique souvent une jointure dans la base. Il en résulte un problème de performance dès que le style d’interrogation devient navigationnel : manipulation d’arbres, de graphes ou toute autre application mettant en relation un grand nombre d’objets ;
- la faible capacité de modélisation : seules les structures de données tabulaires sont permises. Il est ainsi difficile de représenter directement des objets complexes.
I-2-2. SGBD objet▲
Gemstone a été le premier SGBD objet, dérivé du langage Smalltalk. Des produits commerciaux existent, citons db4o, Objectivity, ObjectStore, Orient, Ozone, FastObjects, Versant (produit issu du système O2). Ces systèmes permettent de manipuler des objets persistants. Ils concernent toujours un segment très limité du marché des SGBD.
Parallèlement à ces initiatives individuelles, l’ODMG (Object Database Management Group) propose une API objet standard s’adaptant à tout SGBD par passerelles C++, Java et Smalltalk. En 1998, les compagnies qui soutenaient l’action de l’ODMG étaient Computer Associates, ObjectDesign, Versant, Poet, Objectivity, Ardent Software et Objectmatter. L’ODMG a soumis à la communauté Java la partie « Java Binding » pour définir la spécification JDO (Java Data Objects).
La technologie des bases de données objet n’a pas tenu ses promesses. En particulier il s’est avéré impossible d’indexer n’importe quel type d’objet, rendant les SGBD Orientés Objet, rapidement obsolètes tandis que les acteurs traditionnels comme Oracle, Microsoft ou IBM, rajoutaient une couche objet à leur SGBDR les rendant SGBDRO. Oracle avec java, SQL Server avec .net et IBM de façon purement normative.
I-2-3. SGBD objet-relationnel▲
La technologie objet-relationnelle est apparue en 1992 avec les SGBD UNISQL, Open ODB d’Hewlett-Packard (appelé par la suite Odapter). En 1993, la firme Montage Systems (devenue Illustra) achète la première version commerciale du système Postgres.
À la fin de l’année 1996, Informix adopte la technologie objet avec l’achat du SGBD d’Illustra. La stratégie d’Informix repose sur la spécialisation exclusive du SGBD. Il se différencie d’autres éditeurs comme Oracle qui propose, outre son serveur de données, une offre que certains jugent disparate (outils de messagerie, AGL, etc.). En juillet 1995, IBM inclut des aspects objets dans DB2 puis rachète en 2001 Informix. Oracle 8 propose en juin 1997 des aspects objet, mais les premières versions (avant la 8.1.7) étaient bien limitées en termes de fonctionnalités au niveau des méthodes et l’héritage n’était pas supporté.
Microsoft SQL-Server n’offre pas de fonctions objet au niveau du langage SQL qu’il propose. En revanche, il permet d'intégrer des objets et méthodes à SQL grâce au langage C#, par l'intermédiaire d'un "run time" (CLR). Computer Associates propose à son catalogue le produit Jasmine (fruit des travaux menés depuis 1996 avec Fujitsu). Le système PostgreSQL est un autre dérivé du SGBD objet Postgres développé en 1986 à l’université de Berkeley par Michael Stonebraker et Eugene Wong, les concepteurs d’Ingres. PostgreSQL est aujourd’hui un SGBD libre et open source, tandis que MySQL, autre SGBDR pseudo libre, est fourni avec la majorité des distributions Linux. Il est à noter que SAP DB (SGBD open source issu du logiciel Adabas) propose des extensions objet. D’autres produits commerciaux existent, citons UniSQL, Matisse, ObjectSpark.
Le succès de cette approche provient de :
- l’encapsulation des données des tables. Les méthodes définies sur les types composant les tables permettent de programmer explicitement l’encapsulation (il faudra en même temps que le programmeur interdise les accès directs aux objets par SQL) ;
- la préservation des acquis des systèmes relationnels (indépendance données/traitements), fiabilité et performances, compatibilité ascendante : l’utilisation de tables relationnelles est possible à travers des vues objet et leur mise à jour à travers des procédures stockées ;
- l’enrichissement du langage SQL par des extensions qui sont désormais normalisées (SQL:1999) ;
- la mise en œuvre des concepts objet (classes, héritage, méthodes) qui ont indéniablement démontré leurs apports dans la maintenance des applications (modularité extensibilité et réutilisabilité).
Les risques qu’encourent les programmeurs à miser tout sur cette façon de programmer les données, mais aussi les traitements sont les suivants :
- le modèle de données ne repose plus sur une théorie rigoureuse et sur des principes simples. Il s’affranchit de la première forme normale par exemple. De ce fait, la conception peut induire plus facilement des bases de données contenant des redondances, synonymes de problèmes potentiels d’intégrité des données, mais aussi de performances dégradées ;
- à l'exception de IBM DB2 qui est fortement calé sur la partie objet de la norme SQL:1999, les différents éditeurs n’ont pas adopté une syntaxe commune pour décrire les extensions proposées, d'autant que la norme autorise la coexistence de langages externes pour l'utilisation d'objets dans SQL. En conséquence, la migration d’une base objet-relationnelle d’un SGBD vers une base d’un autre SGBD est un travail très difficile ;
- le fait de migrer une base relationnelle vers l’objet pourra se faire en douceur en utilisant les vues objet. Par contre, le retour en arrière sera bien plus périlleux.
Notons enfin que la théorie de la normalisation n’a pas évolué pour intégrer les concepts objet. Aujourd’hui, la plupart des bases de données objet ont été rangées dans le placard des modes obsolètes de l’informatique, résultat de performances poussives et d’une forte complexité de développement. Cette voie de garage a néanmoins permis de dégager l’horizon pour des outils plus adaptés tels que les FrameWorks ou les ORMs(1), censés régler le pont entre le monde de la programmation orientée objet et l’univers des bases de données relationnelles.
I-2-4. SGBD NoSQL▲
De tout temps, compte tenu de leur hégémonie justifiée par leurs performances, la facilité d’exploitation et la qualité des produits, les SGBDR ont été attaqués. Dès leur naissance, les éditeurs d’anciens produits non relationnels tentent de s’immiscer dans le monde du relationnel à l’aide du marketing, mais sans les fonctionnalités. Telle sera par exemple la bataille au milieu des années 80 entre Franck Edgar Codd et ses compères – inventeurs du relationnel – d’un côté, et John Cullinam, sa firme « Cullinet » et son produit IDMS, lorsqu’il tente d’introduire la version « R » de son système de bases de données. Mais rien n’est relationnel là-dedans. Et ce n’est pas en collant un R sur l’étiquette qu’il le devient ! Notons qu’aujourd’hui, la bataille se situe plus sur l’acronyme SQL… Certaines bases de données « libres », mais surtout légères, comme PostGreSQL ou MySQL prétendre être relationnelles, mais ne le sont véritablement qu’à un degré bien moindre que leurs ainés (IBM DB2, Oracle Database ou Microsoft SQL Server).
Au cours de la vie des bases de données relationnelles dont la théorie remonte à 1970 et la pratique à 1979, beaucoup d’autres modèles ont vu le jour et se sont rapidement éclipsés. Tel est le cas des bases de données multivaluées comme Pick System, des bases XML comme Tamino d’AG Software ou encore des moteurs d’inférence des systèmes experts, premières tentatives de faire de l’IA (Intelligence Artificielle) avec des masses de données. L’un de ces modèles a quelque peu résisté, il s’agit des bases de données analytiques (OLAP : On Line Analytical Process) utilisées par la BI (Business Intelligence), mais dont la tendance, dans les années à venir, serait la disparition, au profit de l’analytique temps réel qui suppose d’attaquer directement les bases de données relationnelles du point de vue analytique en utilisant des techniques de stockage et d’indexation particulières dont on accède plutôt sur des réplicas que de manière directe, ceci afin de répartir la charge.
Un mouvement intéressant, mais non dénué de vénalité, nait avec les géants du Web. Voyant les coûts exorbitants des licences pour se fournir en systèmes de bases de données auprès des grands éditeurs, les FaceBook, Twitter, Google et autres mastodontes (Amazon, eBay, Instagram…) décidèrent au début des années 2000 d’investiguer le champ de bases plus légères, c’est-à-dire dénuées de certaines des fonctionnalités propres aux systèmes relationnels en se fondant sur un mensonge au sujet du théorème CAP de Brewer(2). Elles reprennent ainsi d’anciens principes en vigueur dans les bases de données d’antan et proposent notamment que le principe des transactions soit exclu de leur fonctionnement. C’est le mouvement NoSQL, un mouvement de contestation qui simplement veut la mort des bases de données relationnelles en scandant l’abandon du langage phare des SGBDR, le SQL !
Naissent alors des bases de données exploitant différents segments techniques (big table, document, graphe…). L’apogée du discours de bataille culmine en 2009 à San Francisco où, lors du premier sommet sur le sujet, les tenants du NoSQL racontent « comment ils ont renversé la tyrannie des coûteux et lents SGBD relationnels par des moyens plus simples et plus rapides de manipuler des données ». Jon Travis, l’un des présentateurs de la conférence, ira même jusqu’à dire « les SGBD relationnels en font trop, alors que les produits NoSQL font exactement ce dont vous avez besoin ».
Petit à petit, ces produits censés combattre et voulant tuer le relationnel, ont tous trouvé leurs limites et sont cantonnés dans des marchés de niche avec une intégration technique verticale. Le discours haineux envers les SGBDR s’amoindrit, et l’on ne parle plus d’affronter de face l’ancien ennemi, mais plutôt de le compléter. Le slogan NoSQL qui signifiait qu’on ne voulait plus du SQL est aboli et devient NotOnly SQL, abrégé en NOSQL !
Plus récemment, un grand nombre de ces systèmes de bases de données, cherchant un langage plus moderne, se confronte aux problématiques d’expression et retrouve une forme tellement semblable au SQL, qu’on en vient à réintégrer ce langage en le nommant New SQL !
Bref, le pétard NoSQL censé tuer les SGBD Relationnels a fait long feu… Un grand nombre de projets d’entreprise ont souffert de cette mode et l’on constate un retour vers un usage plus rationnel des différentes offres de SGBD. Du NoSQL, il ne reste que quelques acteurs, autrefois gratuits, mais maintenant de plus en plus chers, dans différentes niches dont les principales sont des bases dont les tables sont orientées :
|
paires clef/valeur en mémoire |
document |
|
graphe |
série chronologique (time series) |
|
larges colonnes (wide columns) |
verticales (columnar) |
Bien entendu le monde des grands éditeurs, constatant le succès modeste et relatif de ces petites niches, n’a pas attendu pour les intégrer au sein des SGBDR. On peut par exemple citer le SGBDR Microsoft SQL Server qui aujourd’hui intègre toutes ces technologies dans toutes ses éditions, y compris les versions gratuites !
|
|
|
Figure 1.2 – Distance de « popularité » entre les SGBDR et le NoSQL (source DB-Engines Ranking) |
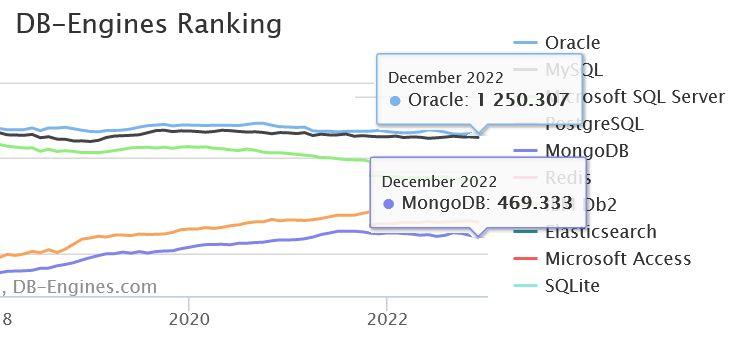
La figure 1.2 montre qu’en 2023, sur le plan de la popularité, les SGBD relationnels ont un écart d’un facteur 3 avec le plus populaire des SGBD NoSQL. Mais popularité ne veut pas dire utilisation, et les SGBD Relationnels restent très majoritaires en nombre d’installations et plus encore en volume de données traitées…
I-3. Le langage SQL▲
SQL signifie Langage de Requêtes Structurées. À priori, cet acronyme ne dit plus grand-chose. Mais le mot le plus important est « requête » dont le synonyme est « demande ». Du point de vue mathématique, le langage SQL est considéré comme complet au sens de Turing, puisqu’il offre la possibilité de requêtes récursives, introduites par la norme SQL:1999.
I-3-1. Un langage de requête▲
Contrairement aux langages de développement d’applications, SQL ne permet pas d’indiquer à la machine les différentes étapes à exécuter séquentiellement, mais plus simplement le résultat à obtenir. L’intelligence du SGBDR qui exécute la requête doit établir préalablement la décomposition et l’ordonnancement des différentes opérations nécessaires à l’obtention du résultat.
Le SGBDR a donc toute latitude pour choisir et composer son plan d’exécution de la requête, c’est-à-dire un arbre algébrique présentant toutes les étapes de réalisation du traitement (sous forme littérale ou graphique), que le moteur élabore en utilisant son « optimiseur », qui est un module d’analyse des différentes hypothèses de construction de la solution, en évaluant chaque variante pour finalement choisir celle qu’il estime être optimale.
|
|
|
Figure 1.3 – Plan d’exécution de requête choisi par l’optimiseur (Sentry SQL) |
Pour mettre en évidence ce phénomène, Christopher Date, compagnon de route de Franck Edgar Codd, mit au point le test suivant (dans un article intitulé « A Cure for Madness »)(3) :
Exemple 1.1 – test « d’intelligence » de l’optimiseur d’un SGBDR
Avec la table T_DATA et les données suivantes :
2.
3.
4.
5.
6.
CREATE TABLE T_DATA
(TYP CHAR(4),
VAL VARCHAR(16));
INSERT INTO T_DATA VALUES ('ALFA', 'abc'), ('ALFA', 'zzz'),
('ALFA', 'F. E. Codd'), ('ALFA', 'Chris Date'),('NUM', '123'), ('NUM', '999'),
('NUM', '1789'), ('NUM', '32765');
La requête :
SELECT *
FROM T_DATA
WHERE VAL = 1000;doit renvoyer une exception avec un message d’erreur indiquant que la conversion d’une valeur de type VARCHAR de la colonne VAL en type de données INT a échoué… Cette conversion implicite est normale. L’utilisateur exige une comparaison numérique (le nombre 1000) et non littérale (cela aurait été '1000').
En revanche, aucune des requêtes suivantes ne doit échouer :
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. |
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. |
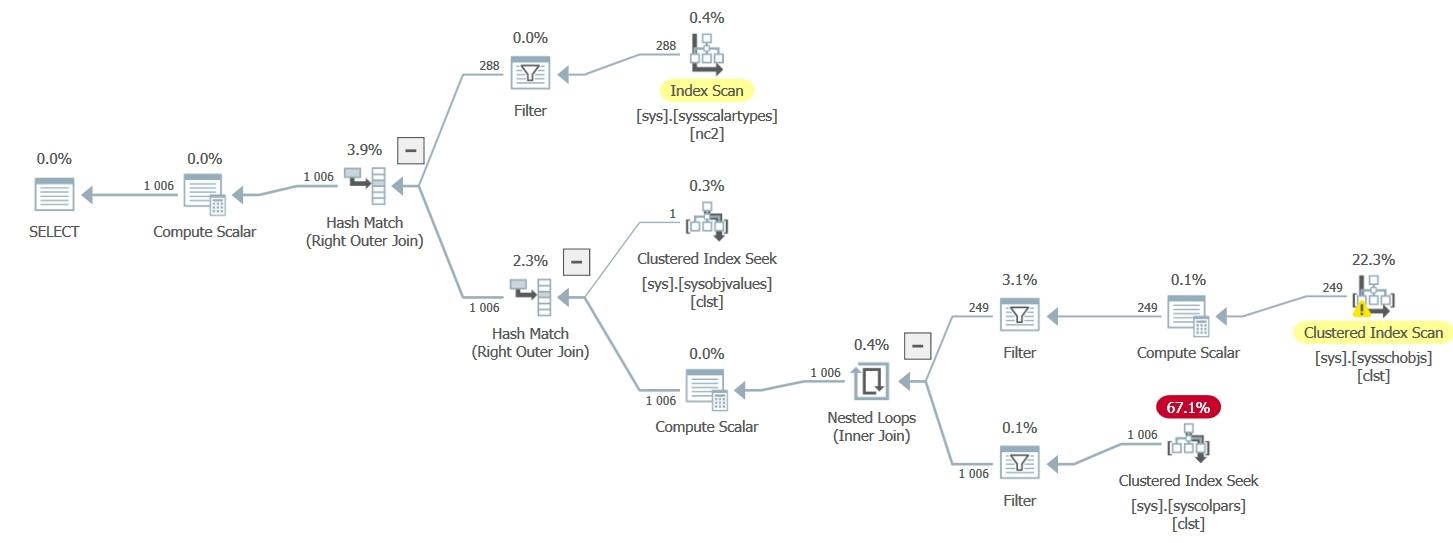
Alors qu’initialement, la requête interne de cette dernière sous requête (en bas à droite) est celle qui a causé notre erreur initiale, le SGBDR ne remonte plus d’erreur… Cela est dû au fait que toutes ces requêtes ne font qu’une ! En effet nous posons toujours la même question au système, et ce n’est pas parce que nous l’écrivons de plusieurs manières différentes que cela change quoi que ce soit au plan d’exécution d’une demande sémantiquement identique(4) :
|
|
|
Figure 1.4 – les 4 plans d’exécution identiques des 4 différentes requêtes (Microsoft SQL Server) |

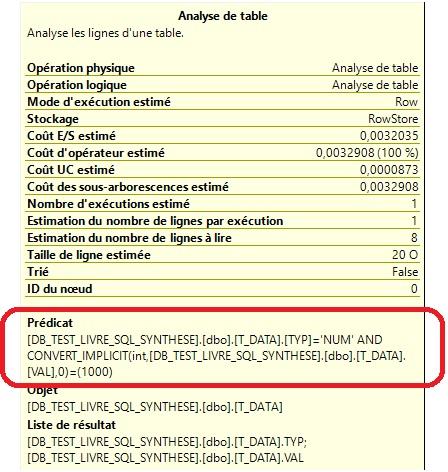
Comme le montre la figure 1.4, tous les plans d’exécution des 4 versions différentes de la requête sont identiques. Il est d’ailleurs à noter qu’a chaque fois, le filtrage des données s’effectue pour les deux valeurs simultanément, ce que l’on peut voir dans le détail de l’opération intitulée « Analyse de table » que montre la figure 1.5 :
|
|
|
Figure 1.5 – Détail de l’opération d’analyse de table (SQL Server) |
L’optimiseur, dans un SGBDR, possède le rôle crucial de déterminer, par des règles complexes, dont certaines sont tenues secrètes par les grands éditeurs (la R&D, coûte cher !), le plan d’exécution optimal de la requête, c’est-à-dire celui qui obtiendra probablement les meilleures performances. Ceci est obtenu par différents niveaux de règles :
- l’algébrisation : consiste à simplifier la requête par des règles mathématiques de type permutation, substitution… ;
- l’heuristique : élimination de certaines opérations inutiles en fonction de l’écriture de la requête ;
- sémantique : simplification de la requête en fonction de la structure des objets et notamment des contraintes ;
- statistiques : choix des algorithmes et séquencement des opérations en se fondant sur des statistiques de distribution des données, permettant de déterminer la cardinalité de chaque opération.
L’ensemble de ces règles est étudié plus ou moins profondément pour chaque requête, mais comme il se pourrait que l’établissement d’un plan optimal mette plus de temps à être élaboré que l’exécution d’un plan peu optimal (trivial), alors l’optimiseur dispose d’une limite en nombre d’actions à effectuer, ou bien d’un temps de calcul maximal, pour trouver le plan optimal.
I-3-2. Limites du langage SQL▲
SQL est le langage des bases de données relationnelles répondant à la fois à la problématique de création des objets de bases de données (modèle), de manipulation des données (algèbre relationnelle), de gestion de la sécurité (« droits d'accès »), de traitements locaux de données (procédures) et désormais doté d'extensions objet.
SQL n’est pas destiné à présenter les données au niveau cosmétique, ni pour interagir avec les utilisateurs. Il doit donc être encapsulé dans les applications qui utilisent des « middleware », c’est-à-dire des bibliothèques de code offrant un pont entre le SGBDR et le code applicatif pour la transmission des requêtes et la réception des données en résultant.
Pour les requêtes de lecture, le résultat est un jeu de données, c’est-à-dire un ensemble de lignes et de colonnes, à la manière d’un tableau(5), accompagné du descriptif technique des éléments (nom et type des colonnes, cardinalité…)(6). Pour les requêtes de mise à jour ou bien celles opérant sur la structure de la base (création, modification, suppression des objets), ou encore celles gérant la sécurité, le résultat est un code en retour, signalant la réussite ou l’échec, et dans ce dernier cas, avec un code d’erreur accompagné d’un message.
Mais avant tout, SQL est une norme.
I-3-3. Les normes SQL▲
Le langage SQL est normalisé depuis 1986(7). Cette norme s'est enrichie au fil du temps (publication X3.135-1986 de l’ANSI reprise par l’ISO peu de mois après : ISO 9075-1987). Cette première mouture, appelée SQL86 ou SQL1 (une centaine de pages), était le résultat de compromis entre constructeurs, mais fortement influencée par le dialecte d’IBM. En 1989, d’importantes mises à jour ont été faites en matière d’intégrité référentielle (ANSI X3.135-1989 et ISO/IEC 9075:1989).
La seconde norme (appelé SQL92 ou SQL2 d’un volume de 600 pages) a été finalisée en 1992. Elle définissait quatre niveaux de conformité : le niveau d’entrée (entry level), les niveaux intermédiaires (transitional et intermediate levels) et le niveau supérieur (full level). Les langages SQL des principaux éditeurs sont à peu près tous conformes au premier niveau et certains ont de nombreuses caractéristiques relevant des niveaux supérieurs.
Les groupes de travail X3H2 de l’ANSI et WG3 de l’ISO se sont penchés depuis 1993 sur les extensions qu’il fallait apporter à la précédente norme. Les optimistes prévoyaient SQL3 pour 1996… Rien ne s’est passé comme prévu. Il a fallu attendre 1999 pour voir établir le projet « SQL:1999 » appelé aussi SQL3 (volume de 1600 pages à l’époque). Ce retard était dû aux nombreux protagonistes (Oracle, IBM, Microsoft, Digital, Computer Associates, etc.) qui voulaient difficilement remettre en cause leur mode de pensée et risquaient de ne pouvoir assurer la compatibilité des bases de leurs clients.
Les évolutions de l’ancienne norme ne sont pas limitées qu’aux extensions objet. Bien d’autres mécanismes ont été introduits dans ce projet (géographie, temps, réel, séries temporelles, multimédia, OLAP, données et routines externes).
SQL:1999 (longtemps surnommée SQL3 avant sa formalisation) est désormais une norme (au sens International Standard de l’ISO). Cette norme apparaît dans le domaine Information technology -- Database languages –SQL. Elle porte principalement la référence ISO/IEC 9075. Les parties 1, 2 et 11 décrivent les bases du langage. Les autres parties constituent les extensions. Cet ouvrage ne traite pas des techniques OLAP, serveurs distants et fournisseurs de données, multimédia et langages objet, étant donné que ces éléments sont encore trop spécifiques à chaque éditeur. Les références aux spécifications (disponibles, mais payantes sur http://www.iso.org) sont, à ce jour, les suivantes :
SQL:1999 (ANSI / ISO / IEC)
9075-1:1999 Framework
9075-1:1999/Amd 1.2001 OLAP : On Line Analytical Process
9075-2:1999 Foundation
9075-2:1999/Amd 1.2001 OLAP : On Line Analytical Process
9075-3:1999 CLI : Call Level Interface
9075-4:1999 PSM : Persistent Stored Module
9075-5:1999 Host Language Bindings (SQL/Bindings)
9075-5:1999/Amd 1:2001 On-Line Analytical Processing (SQL/OLAP)
9075-9:2001 MED : Management of External Data
9075-10:2000 OLB : Object Langage Bindings
9075-13:2002 JRT : Java Routines and Types
9079:2000 Remote databases access for SQL with security enhancement
13249-1:2000 SQL Multimedia and application packages - Part 1 : Framework
13249-2:2000 SQL Multimedia and application packages - Part 2 : Full text
13249-3:1999 SQL Multimedia and application packages - Part 3 : Spatial
13249-5:2001 SQL Multimedia and application packages - Part 5 : Still image
13249-6:2002 SQL multimedia and application packages -- Part 6: Data mining
Peu après, une nouvelle version de SQL (SQL:2003) apportant des modifications mineures est apparue. Ses apports concernent l'auto incrément des clefs, de nouvelles fonctions d'agrégation, de rangement/ordonnancement et de calculs statistiques, les colonnes calculées, l'ordre MERGE combinant UPDATE et INSERT et surtout, un support complet de XML en particulier à l'aide de « wrapper ».
Les références de ces nouvelles normes sont les suivantes :
SQL:2003 (ANSI / ISO / IEC)
9075-1:2003 Framework (SQL/Framework)
9075-2:2003 Foundation (SQL/Foundation)
9075-3:2003 Call-Level Interface (SQL/CLI)
9075-4:2003 Persistent Stored Modules (SQL/PSM)
9075-9:2003 Management of External Data (SQL/MED)
9075-10:2003 Object Language Bindings (SQL/OLB)
9075-11:2003 Information and Definition Schemas (SQL/Schemata)
9075-13:2003 SQL Routines and Types Using the Java TM Programming Language (SQL/JRT)
9075-14:2003 XML-Related Specifications (SQL/XML)
19125-2:2004 Geographic information -- Simple feature access -- Part 2: SQL option
Les normes de 2006, 2008, 2011, 2016, 2019 et 2023 vont compléter ces éléments et en ajouter d’autres :
- amélioration de la prise en charge de XML avec SQL:2006 ;
- déclencheurs INSTEAD OF, pagination de résultat avec OFFSET FETCH dans la clause ORDER BY et commande TRUNCATE avec SQL:2008 ;
- tables temporelles et ajout de nouvelles fonctions fenêtrées avec SQL:2011 ;
- ROW PATTERN RECOGNITION, tables temporelles et le support de JSON avec SQL:2016 ;
- tableaux multidimensionnels avec SQL:2019 ;
- traitementg des NULLs dans l’unicité, fonctions GREATEST, LEAST, LPAD, RPAD, LTRIM, RTRIM, et BTRIM, fonction d’agrégation ANY_VALUE, tri externe dans un groupage avec SQL:2023 ;
Enfin, actuellement en cours d’évaluation, l’incorporation de certaines fonctionnalités du NoSQL…
Le succès que connaissent les grands éditeurs de SGBDR a plusieurs origines et repose notamment sur SQL :
- SQL peut s’interfacer avec des langages de troisième génération comme C, Ada ou Cobol, mais aussi avec des langages plus évolués comme C++, Java, C#.... Mais certains considèrent ainsi que le langage SQL n’est pas assez complet (le dialogue entre la base et l’interface n’est pas direct) et la littérature parle de « défaut d’impédance » (impedance mismatch) ;
- les SGBD rendent indépendants programmes et données (la modification d’une structure de données n’entraîne pas forcément une importante refonte des programmes d’application) ;
- ces systèmes sont bien adaptés aux grandes applications informatiques de gestion (architectures type client-serveur et Internet) et ont acquis une maturité sur le plan de la fiabilité et des performances, même avec de forts volumes (actuellement plus d’une centaine de Téra octets) ;
- ils intègrent des outils de développement comme les précompilateurs, les générateurs de code, d’états, de formulaires, de BI(8), et des outils d'administration, de réplication, de clusterisation, de sauvegarde, de surveillance ;
- ils offrent la possibilité de stocker des informations non structurées (comme du texte, du XML, du JSON… ou binaires comme du son, de l’image, de la vidéo...) et même du spatial (géométrie, géographie) dans des types de la famille des LOBs (Large OBject ).
I-3-4. Structure du langage▲
SQL est un langage composé de deux blocs bien distincts, ces deux blocs faisant l’objet de diverses subdivisions.
Le premier bloc SQL est constitué de la partie déclarative du langage, c'est-à-dire d'ordres SQL que le SGBDR doit exécuter. En d'autres termes, on spécifie ce que l'on veut obtenir ou faire et c'est la machine qui décide comment elle doit l'exécuter.
Le second bloc est constitué par un langage plus classique de type procédural dans lequel on retrouve les notions de fonctions, méthodes, procédures...
I-3-4-1. SQL déclaratif▲
Le bloc déclaratif de SQL est, lui-même, subdivisé en quatre parties :
- le DDL (Data Definition Language), c'est à dire les ordres SQL permettant de créer (CREATE) modifier (ALTER) ou supprimer (DROP) les objets de la base ;
- le DML (Data Manipulation Language), c'est-à-dire les ordres SQL permettant d'ajouter (INSERT) de modifier (UPDATE), de supprimer (DELETE) ou d'extraire des données ;
- le DCL (Data Control Language), c'est à dire les ordres SQL permettant de définir les privilèges afférents aux utilisateurs (GRANT, REVOKE) ;
- enfin, le TCL (Transaction Control Language) qui permet de gérer des transactions englobant des ordres des trois premières subdivisions (COMMIT, ROLLBACK…).
I-3-4-2. SQL procédural▲
Ce second bloc du SQL est lui-même subdivisé en différents modules parmi lesquels les plus importants sont :
- PSM (Persistent Stored Module) : concerne les fonctions, procédures et déclencheurs (triggers) en tant qu'objets de la base (donc stockés dans la base et par conséquent persistants) ;
- CLI (Call Level Interface) : en fait des « API » destinées à piloter des objets encapsulant des données dans des langages hôtes par l'intermédiaire, la plupart du temps, d'un middleware (BDE, dbExpress de Borland, OBDC, ADO, OleDB de Microsoft, JDBC...) ;
- Embedded SQL : le lancement d'ordres SQL depuis un langage hôte et la récupération des données dans un programme grâce à l'utilisation de CURSOR.
Voici un tableau de synthèse présentant les différentes subdivisions de SQL :
|
TCL (Transaction Control Language) |
||
|
DDL |
DML |
DCL |
|
SQL procedural : PSM, CLI, Embedded SQL... |
||
I-3-4-3. Notation des syntaxes du langage▲
Pour exprimer la syntaxe des commandes du langage SQL, nous avons adopté une notation basée sur la BNF (Backus Naur Form) bien connue des informaticiens. Les principes que nous avons appliqués sont les suivants :
|
symbole |
signification |
|
::= |
défini comme suit |
|
| |
ou logique |
|
< > |
concept (nom d'objet, valeur...) |
|
[ ] |
option possible |
|
{ } |
item à choisir |
Les noms des objets étant formulés en italique et les mots clefs en majuscule.
I-4. Du monde réel à SQL : la modélisation des données▲
La modélisation d’un problème, c'est-à-dire le passage du monde réel à sa représentation informatique, se définit en plusieurs étapes pour parvenir à son intégration dans un SGBD et permettre la manipulation des données par le langage SQL.
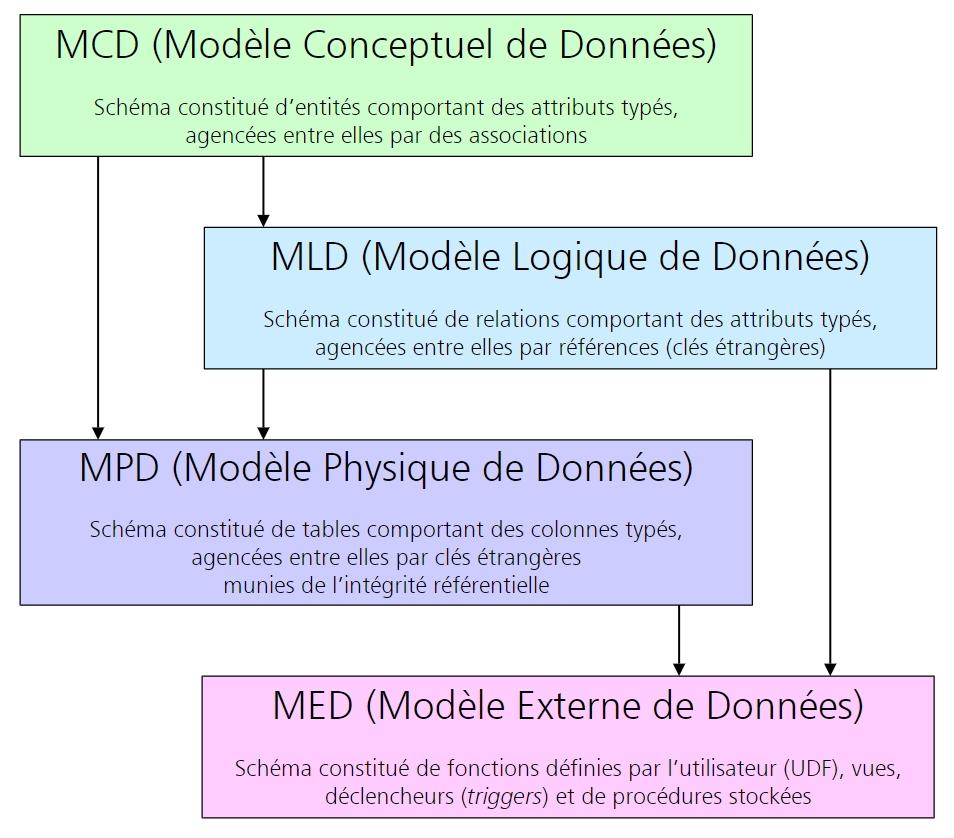
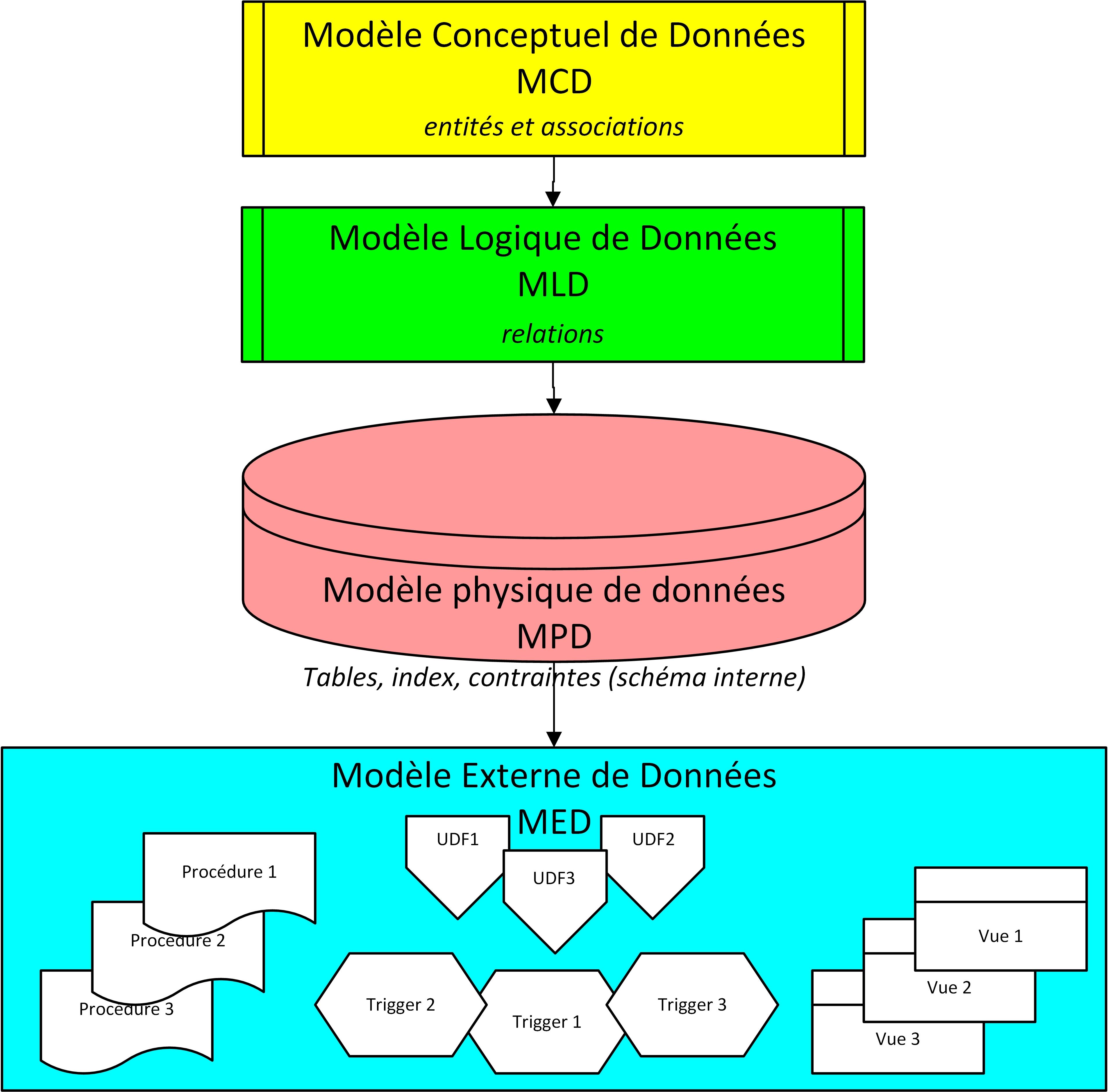
Classiquement, le processus de modélisation des données passe par deux phases : la réalisation d'un modèle conceptuel et sa traduction en un modèle relationnel.
Le premier niveau de modélisation, dit conceptuel (MCD : Modèle Conceptuel de Données), consiste en une phase d’analyse du problème réel. Cette phase d’analyse est assez délicate et permet de définir les données que l’on utilisera, leur mode d’évolution dans le temps (leur vie en somme) et les affinités qu’elles auront entre elles. C’est le moment où l’on se pose les questions essentielles comme celle de savoir à quel usage on destine le modèle informatique ainsi constitué.
C’est un labeur spécifique qui, par les compétences nécessaires, est plutôt réalisé par des spécialistes de l'analyse. Il s’exprime dans un formalisme de type entité-association (avec ou sans les extensions Merise/2) ou bien avec la notation UML (diagramme de classes). Notons qu'il existe une différence entre un modèle (par exemple le modèle conceptuel de données) et un formalisme (dans lequel est décrit un modèle) : ainsi, on peut parler de la modélisation conceptuelle des données suivant le formalisme entité-association ou le formalisme UML (la notation n’exprime que l’aspect représentation).
Le second niveau conduit à élaborer l’ensemble des objets manipulables par un SGBD. C’est un métier plus proche des bases de données et du SGBD employé. En pratique, cette opération est souvent réalisée par un architecte de données, un gestionnaire ou administrateur du SGBD.
Le modèle précédent (modèle conceptuel) est traduit, à l'aide de règles simples, en un modèle relationnel, c'est à dire dans un schéma de relations qui agence les différentes structures de données entre elles (relations...) , interprétable comme base de données pour tout SGBDR. Ce processus peut être facilement automatisé.
Cette seconde phase peut elle-même être découpée en deux : la conception d'un modèle de données logique (MLD : Modèle Logique de Données), c'est à dire une représentation sous forme de relations des données, indépendamment de tout SGBD spécifique, et la traduction en un modèle physique (MPD : Modèle Physique de Données), c'est à dire propre à un SGBD particulier, tous les SGBD n'ayant pas les mêmes caractéristiques et possibilités en matière de SQL.
Enfin, le dernier niveau de modélisation est constitué par les vues externes et les objets de code facilitant la manipulation des données (fonctions utilisateurs, déclencheurs, procédures…). C’est le modèle externe (MED : Modèle Externe de Données).
|
|
I-4-1. Le modèle conceptuel (ou MCD)▲
Un modèle conceptuel représente :
- les faits et les événements qui décrivent le monde à modéliser ;
- certaines contraintes (exemples : une compagnie aérienne n’affrète pas ses propres avions, un pilote ne doit voler que s’il détient une licence en cours de validité et une qualification valide pour le type d’avion en question, etc.) appelées règles de gestion ;
- l’héritage.
Il existe plusieurs techniques de modélisation conceptuelles : modèle entité-association (E-R pour Entity Relationship) à la notation américaine (qu’on doit à Peter Chen), modèle binaire NIAM (Natural Language Information Analysis Method), méthode Z...
Afin de préserver l’indépendance données/traitements, le modèle conceptuel ne doit pas comporter d’indications concernant la structure de mémorisation ou la technique d’accès. Pas question donc ici d’indiquer sur un diagramme, une quelconque information sur l’indexage, l’adressage, le partionnement ou tout autre détail concernant l’accès à la mémoire.
Le modèle conceptuel doit contenir plus d’informations qu’on pouvait trouver au début des sources COBOL lorsqu’il s’agissait de déclarer les structures de données manipulées par les programmes eux-mêmes. En effet, le concepteur devra ajouter sur les diagrammes conceptuels les règles de gestion (aussi appelées « règles de sécurité », « d’intégrité » ou « de fonctionnement »). Cela représente tout ce qu’il faudra assurer pour que la base de données reste cohérente durant toute la vie des applicatifs. L’objectif d’un modèle conceptuel ne peut pas être, comme certains l’affirment, de décrire complètement un système. Il modélise seulement l’aspect statique des données et il est souhaitable de composer des modules afin de réduire la taille des diagrammes.
Dans le monde professionnel, ces diagrammes ne sont plus manuscrits, mais saisis à l’aide d’outils graphiques informatiques. Ces mêmes outils génèrent le modèle logique de la base (le plus souvent le modèle relationnel) puis un script permettant de créer la base de données (le plus souvent un script SQL créant les différentes tables et contraintes). Dans cet ouvrage nous avons utilisé l'outil Power AMC de Sybase devenu Power Designer lors de son rachat par SAP.
La modélisation est un processus important et indispensable, car elle conditionne la structure de la base de données. Les structures de données permettant de stocker des objets complexes dans la base seront déduites des différents éléments issus du modèle conceptuel : entités (ou classes), associations et éventuellement contraintes. Le problème le plus courant que l'on rencontre au sein de bases de données mal conçues, est la redondance des données (répétition d’une information à plusieurs endroits). Cet avatar entraîne à terme des incohérences en modification, insertion et suppression.
Il n'entre pas dans le périmètre du présent ouvrage de décrire dans le détail les différentes techniques de modélisation et nous donnons dans la bibliographie les principaux ouvrages disponibles sur ce sujet. Notons néanmoins un abus de langage classique qui consiste à confondre la notion de lien avec le terme mathématique « relation », ce dernier portant sur l’objet contenant l’information, autrement dit une sorte de table, dotée de propriétés complémentaires.
I-4-2. Du modèle Entité-Association à UML▲
L’idée force du modèle entité association est de représenter par un modèle standardisé les différents éléments constitutifs du système d’information, appelés attributs (exemples : nom, date de naissance) que l’on regroupe en entités (exemple : les personnes), et les règles sémantiques qui les unissent, appelées associations.
Une manière simple de modéliser est de décrire la réalité par une phrase. Le sujet et le complément représentent des entités, et le verbe, l’association.
Exemple 1.2 : deux entités et une association entre elles
Un utilisateur (entité) publie (association) une information (entité).
Les cardinalités servent à mesurer le nombre de participation d'une entité à une association. Elles donnent des informations plus dynamiques sur la nature des associations :
- un-à-un : une personne ne pourrait publier qu’une et une seule information, et une information ne pourrait être publiée que par une seule personne ;
- un-à-plusieurs : une personne pourrait oybkuer un nombre indéfini d'informations (une ou plusieurs), mais une information ne pourrait être publiée que par une seule personne
- plusieurs-à-plusieurs : une personne pourrait publier un nombre indéfini d'informations (une ou plusieurs), et une information pourrait être publiée par plusieurs personnes.
Il y a de fortes similitudes entre le modèle de données Entité-Association (E-R pour Entity Relationship en anglais) et le diagramme de classes UML. Les concepts de base de ces modèles sont analogues :
- Attribut (attribute): donnée élémentaire, également appelée « propriété », qui sert à caractériser les entités et les associations ;
- Entité ou classe (entity, class) : concept concret ou abstrait (fait, moment etc.) du monde à modéliser. Elle se représente par un cadre contenant les attributs (et méthodes pour UML) ;
- Identifiant (identify) : attribut particulier permettant d’identifier chaque occurrence d’une entité (ou d’une classe) ;
- Association (relationship) : l’association permet de relier plusieurs entités ou classes entre elles. Une association se représente à l’aide d’un ovale (ou lien pour UML) ;
- Cardinalités ou multiplicités (cardinality-multiplicity) : couple de valeurs (minimum, maximum) indiqué à l’extrémité de chaque lien d’une association. Il caractérise la nature de l’association en fonction des occurrences des entités ou classes concernées.
I-4-2-1. E-R et UML▲
Les différents types d’associations (un-à-un, un-à-plusieurs, plusieurs-à-plusieurs, n-aires, héritage) sont modélisables. UML dispose du concept de classe-association pour les associations plusieurs-à-plusieurs et n-aires. Seule l’interprétation des cardinalités diffère entre le modèle de Merise, celui de Chen et UML. La majorité des outils ont pris en compte ces différences et génèrent automatiquement un modèle à partir d’un autre (round-trip engineering). Les traductions entre modèles ne sont pas encore parfaites mais s’améliorent au fil des versions des outils.
Les différentes contraintes qu’on peut définir dans un modèle conceptuel sont aussi supportées par les formalismes Entité-Association et UML. Il s’agit des contraintes de partition, d’exclusion, de totalité, d’inclusion et de simultanéité. Les trois premières contraintes sont appliquées aux entités (classes) ou aux associations. Les contraintes d’inclusion et de simultanéité sont dédiées aux associations. En général, les outils prennent en compte graphiquement certaines contraintes, mais ne génèrent aucune contrainte additionnelle au niveau de SQL.
L’agrégation d’UML (partagée ou composition) représente une association qui n’est pas symétrique et pour laquelle l’une des extrémités joue un rôle prédominant par rapport à l’autre. L’agrégation concerne un seul côté d’une association. Ainsi, elle devra se traduire au niveau du code SQL par des déclencheurs (triggers) ou des contraintes. Les outils la prennent en compte graphiquement mais ne génèrent aucun code additionnel au niveau de SQL.
Les règles de validation et de normalisation qui existaient avec Merise peuvent aisément être utilisables sous UML.
L’encapsulation et la visibilité devront être programmées manuellement et explicitement au niveau de la base. C’est là où se trouve le plus grand fossé entre classes d’objets et enregistrements de la base. Alors que l’encapsulation et la visibilité sont assurées intrinsèquement par les langages objets (C++ et Java par exemple), ces concepts ne sont pas natifs aux bases de données. Pour l’heure, les outils de conception ne répercutent pas automatiquement ces notions dans les scripts SQL. Et tant que les bases de données cibles seront relationnelles, il est probable que la situation restera en l’état.
La notation UML est relativement adaptée à la modélisation d’une base de données lorsqu’elle est utilisée à bon escient :
- la plupart des concepts fondamentaux de Merise peuvent être représentés dans le diagramme de classes d’UML qui offre en plus la possibilité de définir des stéréotypes personnalisés ;
- la représentation de certaines contraintes sur des associations n-aires est implicite avec les classes associations ;
- l’utilisation de la notation UML permet aux concepteurs de travailler dans un même environnement graphique, notamment avec la possibilité d’interfacer plus facilement les langages évolués C++ ou Java.
Mais UML pêche par un défaut majeur : son typage flou, ce qui pose généralement de gros problèmes de performance…
I-4-2-2. Formalismes graphiques▲
Nous présentons les deux formalismes graphiques les plus utilisés par les outils à savoir le MCD type Merise et le diagramme de classe UML. Il s’agit de modéliser la base de données des clients d’une banque. Un compte est rattaché à un client. Un compte épargne est rémunéré à un taux. Un compte courant est caractérisé par un nombre d’opérations de carte bleue. Un compte courant peut avoir plusieurs signataires. Pour un compte courant donné, un signataire peut avoir différents droits. On veut stocker les opérations faites par un client sur un compte courant.
Dans le MCD Merise suivant (figure 1.6), apparaîssent :
- six entités ;
- trois associations binaires (Possède et Propriétaire de type un-à-plusieurs et Signataire plusieurs-à-plusieurs) ;
- une association n-aire (Operations) ;
- un héritage simple ayant comme sur-entité Compte.
|
|
|
Figure.1.6 : modèle conceptuel MERISE |
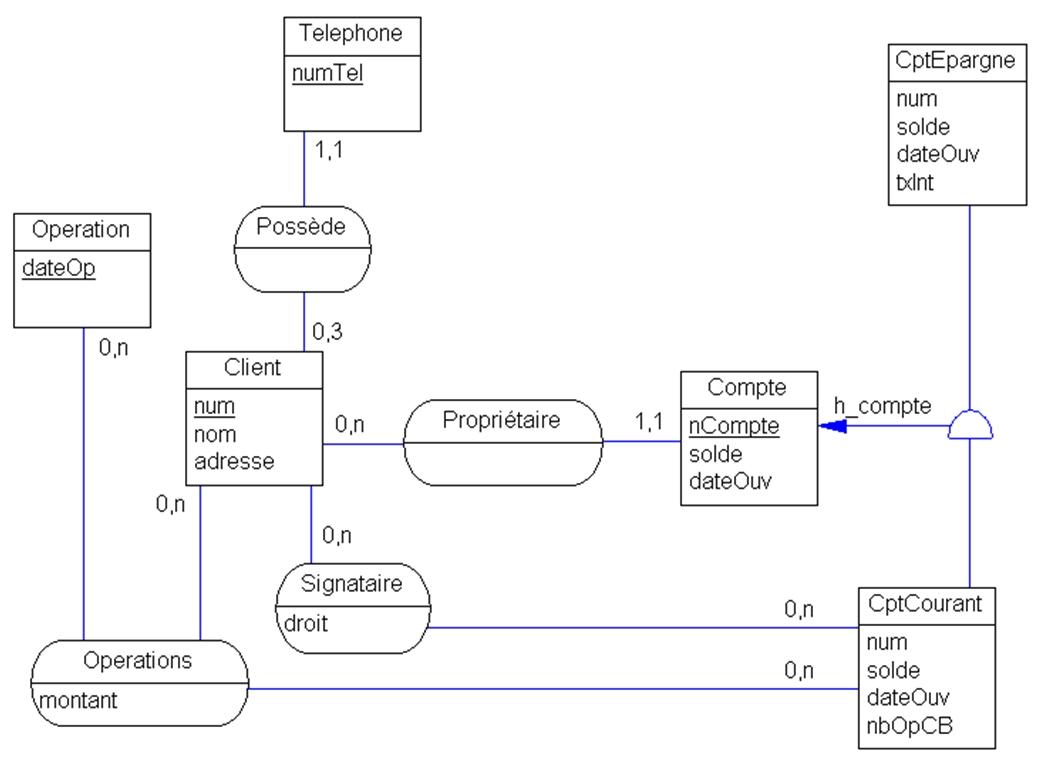
Un diagramme de classes UML équivalent au diagramme MERISE est présenté en figure 1.7. Il y apparaît :
- autant de classes que d’entités Merise ;
- des cardinalités inversées pour les associations binaires ;
- des classes-associations qui traduisent les associations plusieurs-à-plusieurs et n-aires.
|
|
|
Figure 1.7 : diagramme de classes UML |
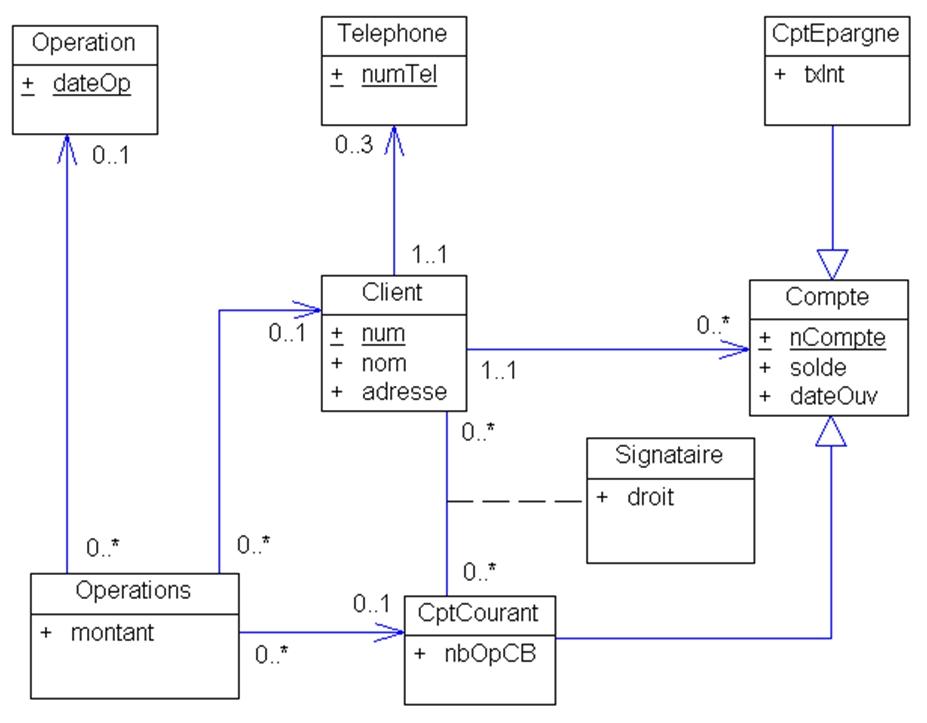
I-4-3. Du conceptuel aux relations : le modèle logique de données (ou MLD)▲
Une fois le modèle conceptuel validé, c’est-à-dire comprenant toutes les informations (exceptées les informations calculables), sans oubli et sans redondance et exprimé sous la forme d’entités (ou classe si UML) et associations, le modèle logique constitué des relations au sens mathématique peut être établi par des règles simples :
- toute entité est traduite en table ;
-
suivant les cardinalités des associations, des éléments sont ajoutés :
- un à un : l’identifiant de chacune des entités est glissé sous forme de clef étrangère dans l’autre entité et une assertion assure la correspondance des paires de clefs,
- un à plusieurs : l’identifiant de l’entité côté n est glissé sous forme de clef étrangère côté 1,
- plusieurs à plusieurs : une table associative est créée dont la clef est formée des identifiants des entités participant à l’association;
- les contraintes d’intégrité fonctionnelles sont traduites en clefs alternatives, déclencheurs ou vues.
Ce modèle est affiné notamment par l’adjonction de contraintes complémentaires répondant aux règles de gestion.
Cet ensemble de relations constitue le Modèle Logique de Données (MLD).
I-4-4. Du relationnel aux tables : le modèle physique de données (ou MPD)▲
La traduction du modèle logique de données en tables relationnelles dépend du SGBD Relationnel utilisé. Tous ne disposent pas des mêmes concepts, types et objets. Ce niveau de modélisation ajoute toute la partie physique invisible aux modèles précédents, notamment :
- la persistance ;
- le stockage ;
- l’indexation ;
- d’éventuels partitionnements.
De loin, le plus important est la partie persistance qui concerne la gestion des transactions. Un chapitre de cet ouvrage en parlera en détail.
Le modèle de données que SQL manipule est constitué de tables, correspondant aux relations décrites dans le modèle logique de Codd. La table relationnelle est la structure de données de base qui contient des entrées de données appelés lignes. Une table est composée de colonnes qui décrivent les lignes.
Considérons la figure suivante qui présente deux tables relationnelles permettant de stocker des compagnies, des pilotes et le fait qu’un pilote soit embauché par une compagnie :
|
|
|
Figure 1.8 : exemple de tables relationnelles |
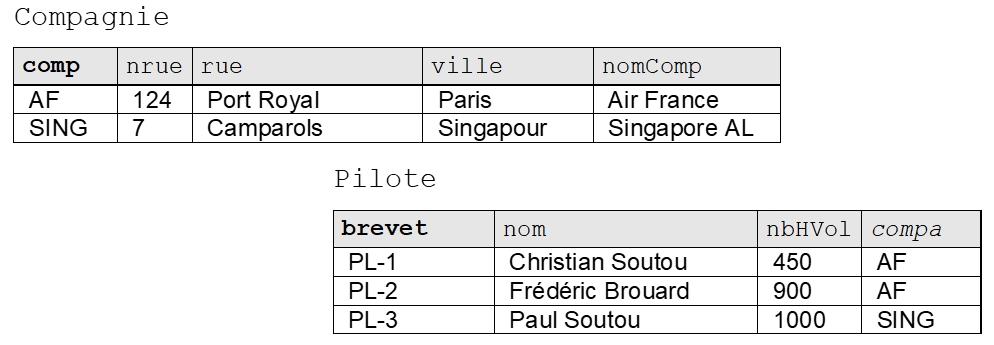
La clef primaire (primary key) d’une table est l’ensemble minimal de colonnes qui permet d’identifier de manière unique chaque ligne. Dans la figure précédente, les colonnes « clefs primaires » sont notées en gras. La colonne comp représente le code de la compagnie et la colonne brevet décrit le numéro du brevet.
Une clef est dite « candidate » (candidate key) si elle peut se substituer à la clef primaire à tout instant. Une table peut contenir plusieurs clefs candidates ou aucune. Dans notre exemple, les colonnes nomComp et nom peuvent être des clefs candidates si l’on suppose qu’aucun homonyme n’est permis.
Une clef étrangère (foreign key) référence dans la majorité des cas une clef primaire d’une autre table (sinon une clef candidate sur laquelle un index unique aura été défini). Une clef étrangère est composée d’une ou plusieurs colonnes. Une table peut contenir plusieurs clefs étrangères ou aucune. Dans notre exemple, la colonne compa (notée en italique dans la figure) est une clef étrangère, car elle permet de référencer une ligne unique de la table Compagnie grâce à sa clef primaire comp.
Le modèle relationnel est ainsi fondamentalement basé sur les valeurs. Les associations entre tables sont toujours binaires et assurées par les clefs étrangères. Les théoriciens considèrent celles-ci comme des pointeurs logiques. Les clefs primaires et étrangères seront définies dans les tables en SQL à l’aide de contraintes.
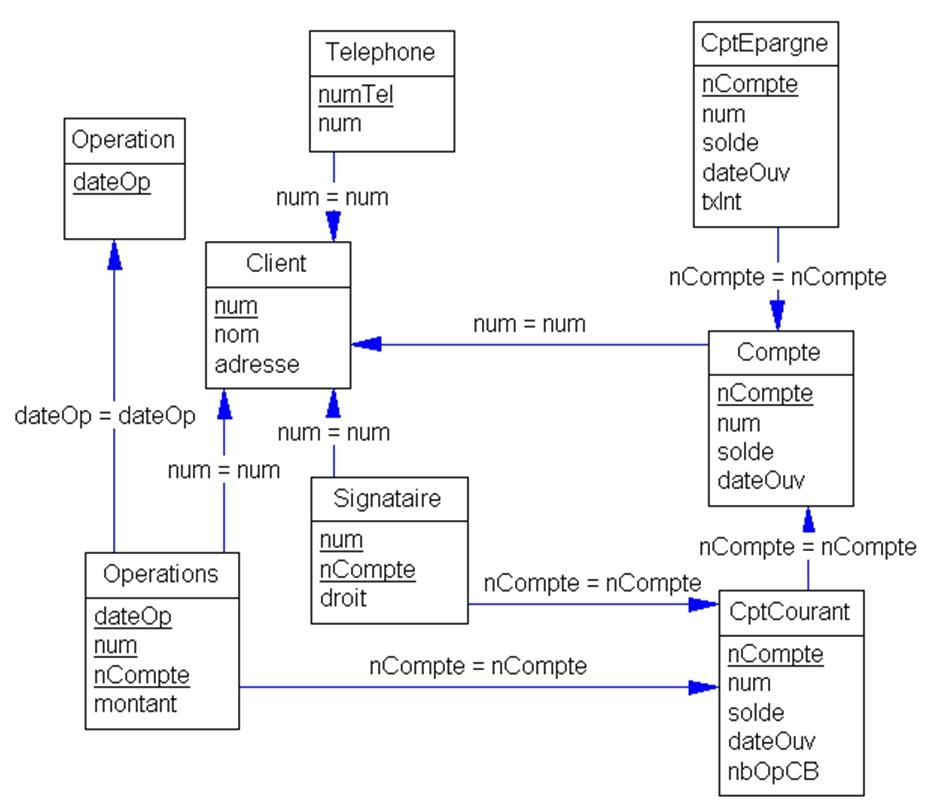
La figure 1.9 illustre le modèle relationnel de la gestion de la banque décrit au paragraphe précédent. Les clefs étrangères sont ici représentées sous la forme de flèches.
|
|
|
Figure 1.9 : modèle relationnel des données de l’exemple de la banque |
I-5. algèbre relationnelle▲
Étudions à présent brièvement les opérateurs qui constituent une partie de la base mathématique du modèle de donnée relationnel. L’algèbre relationnelle propose en tout et pour tout 8 opérateurs divisés en deux catégories :
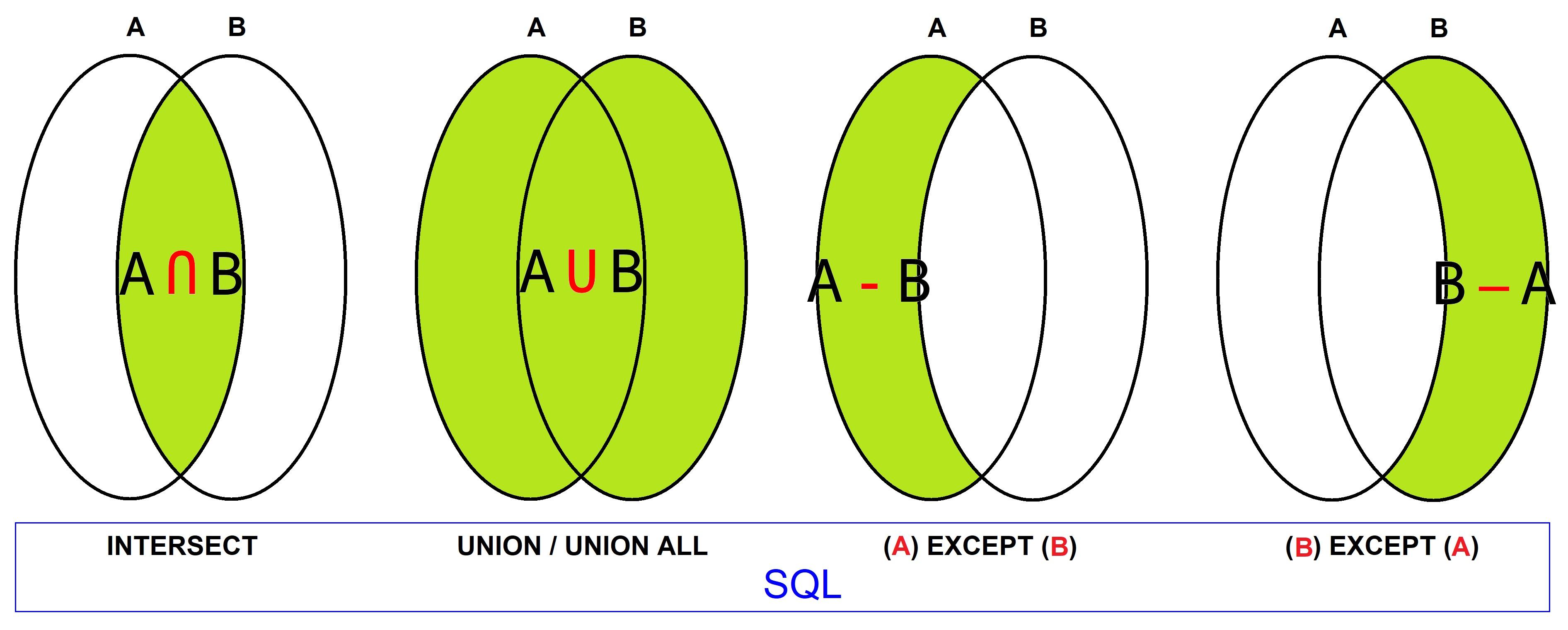
- Ensemblistes (UNION, INTERSECTION, DIFFERENCE)
- Relationnels (RESTRICTION, PROJECTION, JOINTURE, DIVISION, PRODUIT CARTÉSIEN)
On distingue les opérateurs unaires (ou monadiques) : projection et restriction qui opèrent sur une relation à la fois des opérateurs binaires (ou dyadiques) : union, différence, intersection, division, produit cartésien, jointure qui opèrent sur deux relations.
Le résultat d'une opération de l'algèbre relationnelle est une nouvelle relation ce qui permet de combiner les résultats entre eux afin de créer de nouvelles opérations bâties sur des expressions plus complexes. Il n’y a donc pas de limite à la « calculabilité » dans l’algèbre relationnelle.
NOTE
Dans le langage SQL, le résultat n'est pas une table – la différence est subtile – mais un jeu de donné constitué par un curseur, pouvant être considéré comme une table.
I-5-1. RESTRICTION (symbole σ )▲
La restriction de la relation R1[a1, ..., an], selon le prédicat p donne une relation R2[a1, ..., an] qui est notée σ(p)[R1]. R2 contient les tuples de R1 filtrés selon le prédicat p. La lettre grecque σ (sigma) est utilisée pour cette opération.
|
|
|
Figure 1.10 : effet d'une opération de restriction |
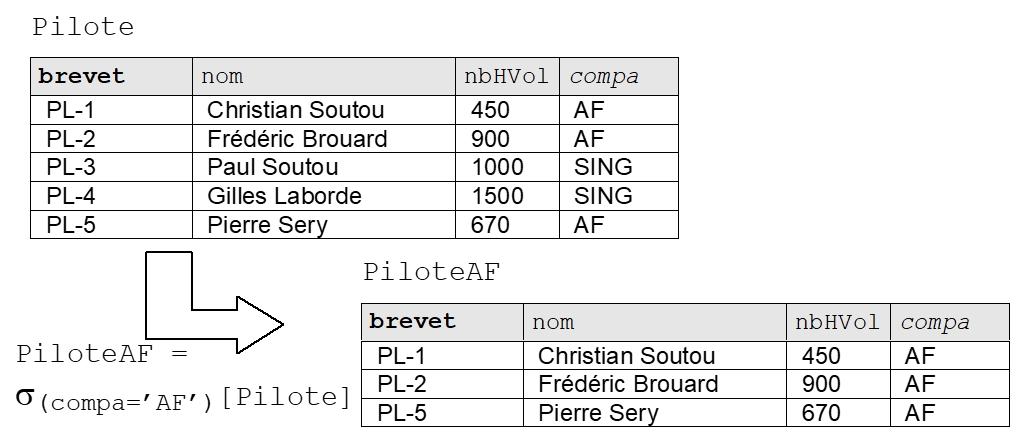
Dans le langage SQL, cette opération qui consiste à ne retenir que certaines lignes de la table, est réalisée par les clauses WHERE et HAVING, ainsi que dans la clause ORDER BY par l’intermédiaire des options OFFSET / FETCH(9).
I-5-2. PROJECTION (symbole Π)▲
La projection de la relation R1[a1, ..., an] sur les attributs ai, ..., am avec (ai, ..., am a1, ..., an) donne une relation R2[ai,...,am], qui est notée Π(ai,...,am)[R1]. . R2 contient seulement les données présentes dans les colonnes ai, ..., am issues de R1. La lettre grecque Π (pi) est utilisée pour cette opération.
|
|
|
Figure 1.11 : effet d'une opération de projection |

Dans le langage SQL, cette opération qui consiste à ne présenter qu’un sous ensemble des colonnes de la table est réalisée dans la clause SELECT.
I-5-3. UNION (symbole U)▲
L’union des relations R1[a1, ..., an] et R2[b1, ..., bn] donne la relation R3 qui contient les tuples de R1 et les tuples de R2 qui n’appartiennent pas à R1, elle est notée
U [R1, R2]. La lettre « U » en majuscule symbolise cette opération.
|
|
|
Figure 1.12 : effet d'une opération d'union |
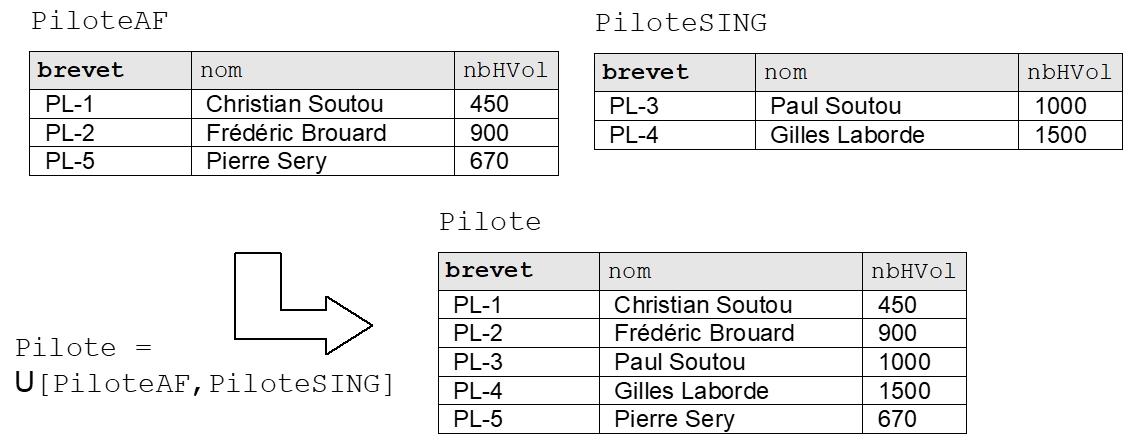
Dans le langage SQL, cette opération est réalisée par l’opérateur UNION.
I-5-4. DIFFERENCE (symbole –)▲
La différence des relations R1[a1, ..., an] et R2[b1, ..., bn] donne la relation R3 qui contient les tuples de R1 qui n’appartiennent pas à R2, elle est notée – [R1, R2] et symbolisée par le signe « moins » –.
|
|
|
Figure 1.13 : effet d'une opération de différence |
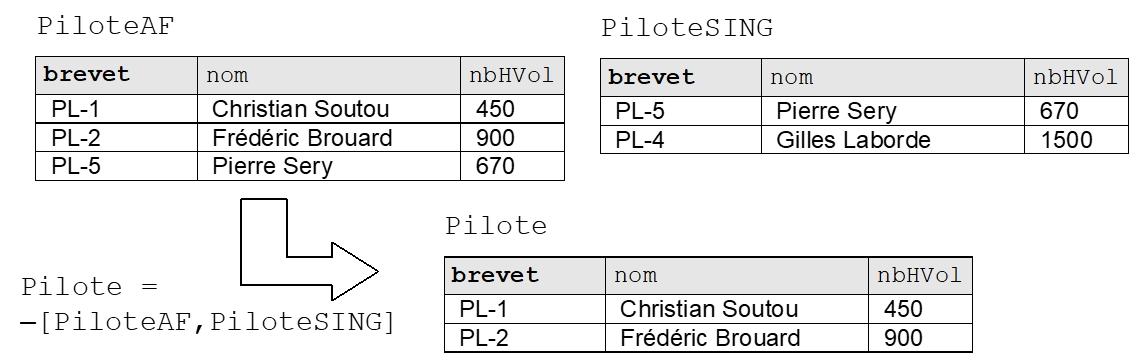
Dans le langage SQL, cette opération est réalisée par l’opérateur EXCEPT.
I-5-5. INTERSECTION (symbole ∩)▲
L’intersection des relations R1[a1, ..., an] et R2[b1, ..., bn] donne la relation R3 qui contient les tuples qui appartiennent à la fois à R1 et à R2, elle est notée ∩ [R1, R2] et symbolisée avec la lettre « U » inversée ∩.
|
|
|
Figure 1.14 : effet d'une opération d'intersection |

Dans le langage SQL, cette opération est réalisée par l’opérateur INTERSECT.
La figure 1.15 présente les trois opérateurs précédents, appelées opérateurs « ensemblistes ». Les attributs des relations doivent avoir des supports sémantiques similaires, autrement dit des « types » compatibles…
|
|
|
Figure 1.15 : opérateurs ensemblistes |
I-5-6. PRODUIT CARTÉSIEN (symbole x)▲
Le produit cartésien de R1[a1, ..., an] par R2[b1, ..., bn] donne la relation R3[a1, ..., an,, b1, ..., bn] qui contient les combinaisons des tuples de R1 et de R2, il est noté x[R1, R2]. Il est symbolisé par le signe x.
|
|
|
Figure 1.16 : effet d'une opération de produit cartésien |
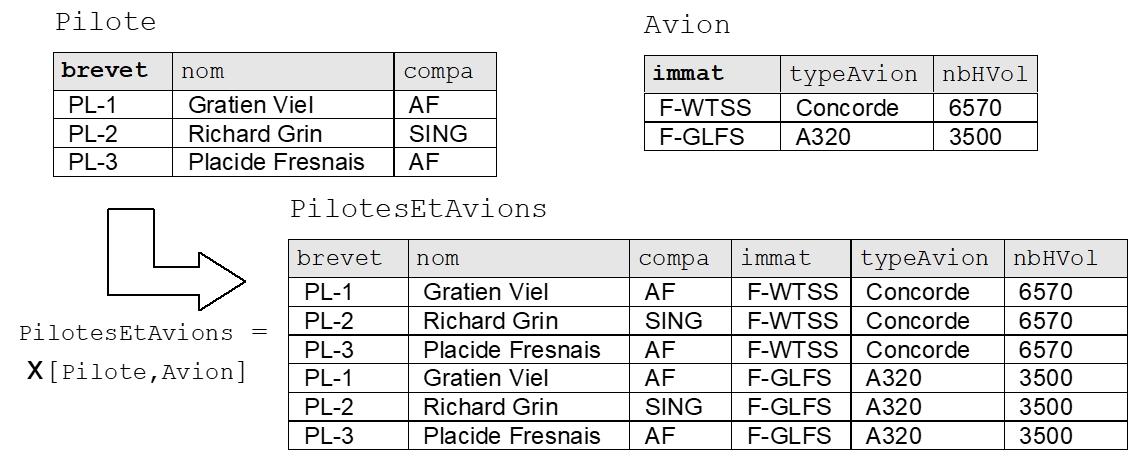
Le produit cartésien est le nom savant de la multiplication. C’est aussi l’inverse de la division. Dans le langage SQL, cette opération est réalisée par l’opérateur CROSS JOIN.
I-5-7. DIVISION (symbole ÷)▲
La division de R1[a1, ..., an,, b1, ..., bn] par R2[b1, ..., bn] donne la relation R3[a1, ..., an] qui contient les tuples ti vérifiant : ti ∈ ( R3 tels que tj ∈ R2 et ti, tj ∈ R1, elle est notée ÷ [R1, R2]. Elle symbolisée par le signe ÷.
|
|
|
Figure 1.17 : effet d'une opération de division |
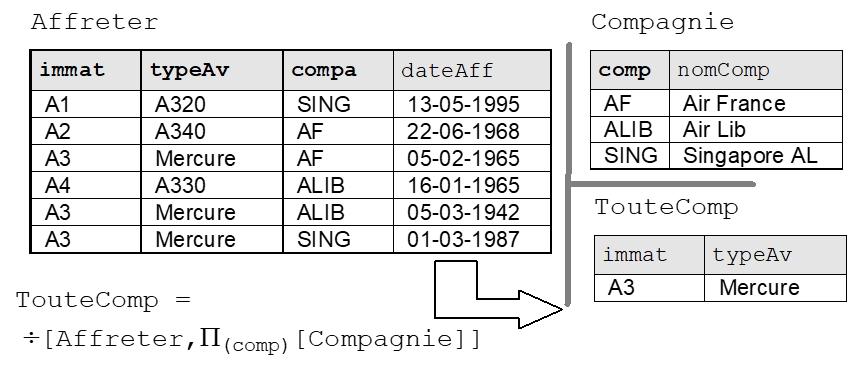
Le langage SQL ne dispose d’aucun opérateur particulier pour réaliser cette opération compte tenu des diverses formes qu’elle peut prendre (exacte ou approchée, c’est à dire avec ou sans reste, ou encore valuée). On la réalise alors à l’aide de sous-requêtes.
I-5-8. JOINTURE (symbole ⋈ )▲
La jointure de R1[a1, ..., an] avec R2[b1, ..., bn] suivant le prédicat p donne la relation R3[a1, ...,, an,, b1, ..., bn] qui contient les tuples de R1 et de R2 vérifiant le prédicat de jointure, elle est notée : ⋈(p)[R1,R2]. Symbolisée par un « diabolo » ⋈.
|
|
|
Figure 1.18 : effet d'une opération de jointure |

Dans le langage SQL, cette opération est réalisée par l’opération de jointure (JOIN) déclinée en différentes versions : INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN et FULL OUTER JOIN. Les jointures externes (OUTER) étant symbolisées par ⟕⟖⟗.
I-6. Le modèle externe de données (ou MED)▲
Le modèle externe de données ajoute les couches de présentation (vues) et l’intelligence au niveau de la gestion interne des données par le biais des fonctions définies par l’utilisateur (User Defined Function ou UDF), des déclencheurs et des procédures stockées et des fonctions utilisateurs. Nous découvrirons tous ces éléments dans un prochain chapitre.
En conclusion nous pouvons synthétiser la succession des modèles de données en 4 couches que résume la figure 1.20 :
|
|
|
Figure 1.19 – les différents niveaux de modélisation des données |
I-7. La syntaxe▲
La syntaxe, nous apprennent les dictionnaires, est la partie de la composition d’une langue qui décrit les règles de combinaison des différentes entités lexicales entres elles.
En informatique où le terme « langue » doit être remplacé par « langage », la syntaxe définit la grammaire formelle du langage. La syntaxe est donc peu permissive, et les outils qui traduisent ce langage en code exécutable, appelés « compilateurs », ne pardonnent pas la moindre erreur.
Par exemple, si en français, tout le monde comprendra une phrase comme : « Pierre est allé au coiffeur en moto », alors que la bonne syntaxe est « Pierre est allé chez le coiffeur à moto », il n’en va pas de même avec n’importe lequel des langages informatiques. La moindre divagation dans la précision des éléments d’une commande et donc plus généralement du code, provoquera immanquablement une erreur de syntaxe ou pire, un résultat faux…
Parmi les principales difficultés rencontrées par les débutants, notons :
- la précision du placement des virgules ;
- la gestion de l’imbrication des parenthèses ;
- la mauvaise orthographe des noms des objets ;
- l’oubli de fermeture des délimiteurs (apostrophe, guillemets…).
Ces difficultés sont normales et s’acquièrent avec le temps notamment par l’observation des syntaxes présentées, mais aussi, et surtout, avec la lecture et la reproduction des exemples… Bref, comme dans beaucoup de disciplines, la pratique entraîne l’habitude, et l’habitude une sûreté du codage.
Il n’en reste pas moins vrai que certains outils d’édition des requêtes SQL et certains SGBDR facilitent la vie. Nous prendrons deux exemples très contraires pour prouver notre propos… D’un côté le SGBDR Microsoft SQL Server et son outil d’édition SQL Server Management Studio (SSMS) qui pratique l’auto-complétion et de l’autre côté MySQL et son outil MySQL Workbench relativement frustre… En lançant simplement la requête de l’exemple 1.3, syntaxiquement erronée, voici le comportement de ces deux outils :
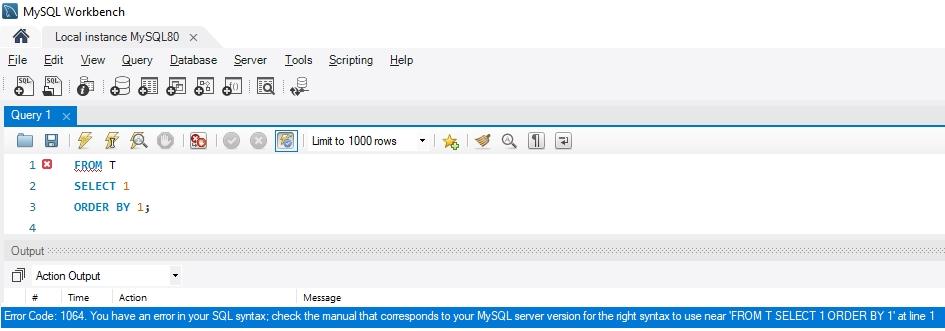
Exemple 1.3 – requête SQL dont la syntaxe est erronée :
FROM T
SELECT 1
ORDER BY 1;|
|
|
Figure 1.20 – Effet d’une erreur de syntaxe dans Microsoft SQL Server / SSMS |
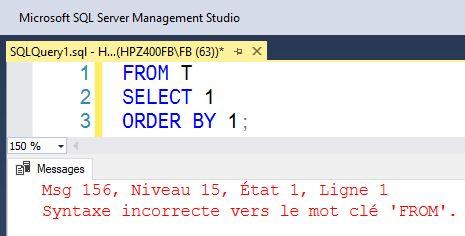
Tandis que le compilateur de Microsoft SQL Server (voir figure 1.20) indique clairement, non seulement la nature de l’erreur (syntaxe incorrecte) et l’élément en défaut (la clause FROM), mais en sus, l’outil SSMS positionne le curseur au début de la ligne où se situe l’erreur si l’on clique sur le message d’erreur.
En revanche, dans MySQL Workbench, le message est plus que sibyllin : rien n’indique la nature de l’erreur (reportez-vous au manuel…), pas plus qu’il n’aide l’utilisateur à positionner le curseur à l’endroit du code où son écriture est fautive (voir figure 1.21)…
|
|
|
Figure 1.21 – Effet d’une erreur de syntaxe dans MySQL / Workbench |
On aura compris que certains produits, venant en particulier du monde libre (MySQL / MariaDB, PostGreSQL…), offrent un niveau de service bien moindre que les SGBDR professionnels d’entreprise comme Microsoft SQL Server ou Oracle Database, où la productivité est la règle qui dicte la commercialisation.
On peut néanmoins opter pour un outil client d’édition des requêtes autre que celui fourni par le concepteur du SGBDR(10), mais aucun n’offre la richesse et la facilité de codage que l’on trouve dans Microsoft SQL Server Studio Management ou Oracle SQL Developper…
I-8. Organisation interne d’un SGBD Relationnel▲
Un SGBD Relationnel est en fait un programme informatique de type « service » et qui tourne en permanence. Il est à l’écoute des demandes des nombreux utilisateurs. Il reçoit des requêtes qu’il analyse et exécute suivant les permissions accordées aux utilisateurs sur les objets.
Il peut se faire que sur une même machine(11) physique ou virtuelle soit installées plusieurs instances(12) d’un même type de SGBDR. Ceci est fortement déconseillé en production, mais c’est courant pour l’analyse et les test dans les entreprises assurant le développement ou la maintenance d’applications.
Le terme de « base de données » (en anglais « database ») n’existait pas à l’époque de Ted Codd. On parlait alors de « databank » (banques de données) dans lesquelles on trouvait des « catalogues » de données. Le terme « catalogue » est cependant resté dans certaines vues de métadonnées et nous le rencontrerons au cours de cet ouvrage. Le terme « catalog » est un équivalent du terme database (bases de données) dans le langage SQL.
I-8-1. La notion de base de données ou CATALOG▲
Un SGBD Relationnel moderne peut comporter de nombreuses bases de données chacune devant être utilisée par une application précise. Par exemple, dans une entreprise, on pourra trouver une base de données pour les ressources humaines, une autre pour la comptabilité et une troisième pour la gestion des clients (actions commerciales, commandes, facturation, livraisons…). Le cloisonnement par base doit être relativement étanche, mais certaines données de chacune de ces bases peuvent alimenter d’autres bases. À titre d’exemple, les factures de la base client seront poussées vers la base comptable.
Une commande SQL spécifique, généralement CREATE DATABASE, permet de créer une nouvelle base de données dans le SGBDR.
Certains SGBD relationnels permettent de faire des jointures entre les tables des différentes bases de manière naturelle et optimisée. C’est le cas de Microsoft SQL Server. D’autres nécessitent l’établissement d’une liaison entre deux bases par un mécanisme à créer (DBLink), et la jointure s’effectue en migrant les données des tables distantes dans la base locale (remote join). Cette dernière technique adoptée par Oracle Database et PostGreSQL ne permet aucune optimisation de la jointure interbase.
I-8-2. La notion de schéma SQL▲
À l’intérieur d’une base de données relationnelle on trouve des schéma SQL qui sont en fait des conteneurs logiques. Tout objet relationnel doit figurer dans un schéma et le nom complet d’un objet doit être préfixé par le nom du schéma SQL. Toutefois, il existe systématiquement un schéma par défaut dans toutes les bases, voire un chemin de recherche dans différents schémas. De même, il existe un schéma par défaut attribué pour chacun des utilisateurs SQL qui sont les entités de sécurité sous lesquelles naviguent les applications accédant à la base.
Il n’est pas possible de créer un objet relationnel hors d’un schéma SQL. En revanche, certains objets non relationnels comme ceux permettant de gérer le stockage des données de la base ne peuvent pas être placés dans un schéma SQL.
Le concept de schéma est proche de celui de « bibliothèque » de code des langages procéduraux ou d’espace de noms des langages plus moderne comme C++, Java ou C#, à la différence près que l’on ne peut pas imbriquer les schémas SQL les uns dans les autres pour former une hiérarchie. En d’autres termes, il n’existe qu’un seul niveau de schéma SQL.
NOTE
Un même nom de table peut être présent dans différents schémas SQL. En effet, l’unicité des noms des objets se fait sur le nom complet de l’objet nom_schema.nom_objet. Pour les SGBDR multibase, cette unicité se fait aussi avec le nom de la base : nom_base.nom_schema.nom_objet.
L’idée sous-jacente aux schémas SQL est de modulariser la base de données. Par exemple un ERP, souvent doté de plusieurs milliers de tables et vues, gagnera à voir ces objets répartis en différents schémas comme RH, COMPTA, MARKETING, VENTE, PRODUCTION… qui permettent de présenter la base de données sous un aspect silo souvent utile à la mode actuelle des micro-services. Un autre découpage, souvent complémentaire, consiste à utiliser des schémas SQL transverses, notamment pour des données techniques ou référentielles. À titre d’exemple, on pourra créer les schémas suivants : SYSTEME, META, REFERENTIEL, IMPEX, EXT… Ceci pour, respectivement, des tables d’utilisateurs, des dictionnaires de données, un référentiel interne, des tables tampons, les données d’un référentiel externe.
Enfin, il faut savoir que l’on peut affecter des permissions spécifiques (appelés privilèges) aux schémas SQL, ce qui permet une grande souplesse en matière de sécurité préventive en plus de la modularité apportée naturellement par le découpage d’une base en de multiples schémas SQL.
Notez que certains schémas SQL sont fournis par les éditeurs. En principe, on trouve dans toutes les bases le schéma SQL normatif INFORMATION_SCHEMA(13) dans lequel sont implantées des vues présentant les métadonnées logiques de la base (tables, colonnes, contraintes…) et le schéma SQL « sys »(14) dans lequel on trouve tous les objets systèmes propres à chaque éditeur de SGBD Relationnels.
ATTENTION
MySQL / MariaDB font confusion entre les notions de schéma SQL et de base de données, mélangeant allègrement ces différents concepts sans les apports normatifs nécessaires à la sécurité ou la modularité (les sauvegardes pouvant s’avérer inconsistantes)…
NOTE
Oracle Database n’a jamais voulu intégrer le schéma normatif INFORMATION_SCHEMA présentant les vues logiques des métadonnées des objets relationnels.
I-9. Importance des bases de données▲
Jusqu’au début des années 90, les entreprises ont peu considéré les informations détenues dans leurs bases de données. Il en est résulté une faible appréciation de la valeur patrimoniale des stocks de données disponibles dans les bases. Il a fallu attendre une loi permettant de valoriser comptablement le capital représenté par le stockage de l’information et une prise de conscience avec l’arrivée des GAFA, pour que les entreprises commencent à se questionner dans le bon sens au sujet des informations qu’elles détiennent.
La valeur d’une base de données est dans la qualité de l’information qu’elle stocke. L’intelligence est dans la structuration de ces informations…
I-9-1. Valeur d’une base de données▲
Il est aujourd’hui comptablement et commercialement admis, que les informations d’une base de données constituent un capital. De nombreuses entreprises commercialisent les données qu’elles ont acquises, certaines ayant fait leur métier exclusivement sur ce concept en offrant des services apparemment gratuits (Google, FaceBook, Twitter, Tik Tok…).
Tout comme les brevets, les marques, les licences, les logiciels… les bases de données peuvent faire l’objet d’une appréciation financière au titre des actifs immatériels. En effet, il est tout à fait possible de revendre toute ou partie des informations contenues dans les bases de données de l’entreprise… ou encore de les exploiter d’une manière différente de celle prévue à l’origine.
I-9-2. Intelligence d’une base▲
La valeur d’un tel patrimoine, la base de données, est plus ou moins élevée pour les informations contenues dans celle-ci, en fonction de la facilité avec laquelle on peut exploiter ou non les données. C’est là qu’intervient la notion d’intelligence. En effet, selon que la structure de la base, c’est-à-dire l’organisation intime des informations dans les différentes tables, est plus ou moins efficiente, il en résultera une facilité ou une difficulté à accéder rapidement à l’information et une plus ou moins grande qualité des données stockées.
L’art de la modélisation d’une base de données repose sur des principes simples :
- des informations atomiques ;
- le stockage de l’information et seulement l’information (sans « bruit »)(15) ;
- la présence d’une clef pour chaque table ;
- aucune valeur inconnue (pas de « NULL ») ;
- la présence de contraintes de domaine ;
- la modification d’une information ne doit pas conduire à la mise à jour de plus d’une ligne d’une table.
L’ensemble de ces règles assure cette intelligence qui fournira à la fois des performances exceptionnelles et la garantie que les données soient saines et facilement exploitables.
Hélas, en pratique, on s’aperçoit que nombre de bases de données ne respectent pas ces principes et cela conduit à des bases fortement redondantes, des tables obèses (voir figure 1.22), des données fausses ou incomplètes et par conséquence des performances médiocres, voire difficilement acceptables. Il en résulte alors de nombreux coûts pour l’entreprise : surdimensionnement du matériel pour compenser les mauvaises performances (stockage exagéré), perte de temps et donc d’agent (développement complexe, maintenance lourde, administration exorbitante…), dévalorisation du capital des données…
|
|
|
Figure 1.22 – temps de réponse comparatif d’un SGBD Relationnel en présence de tables obèses |
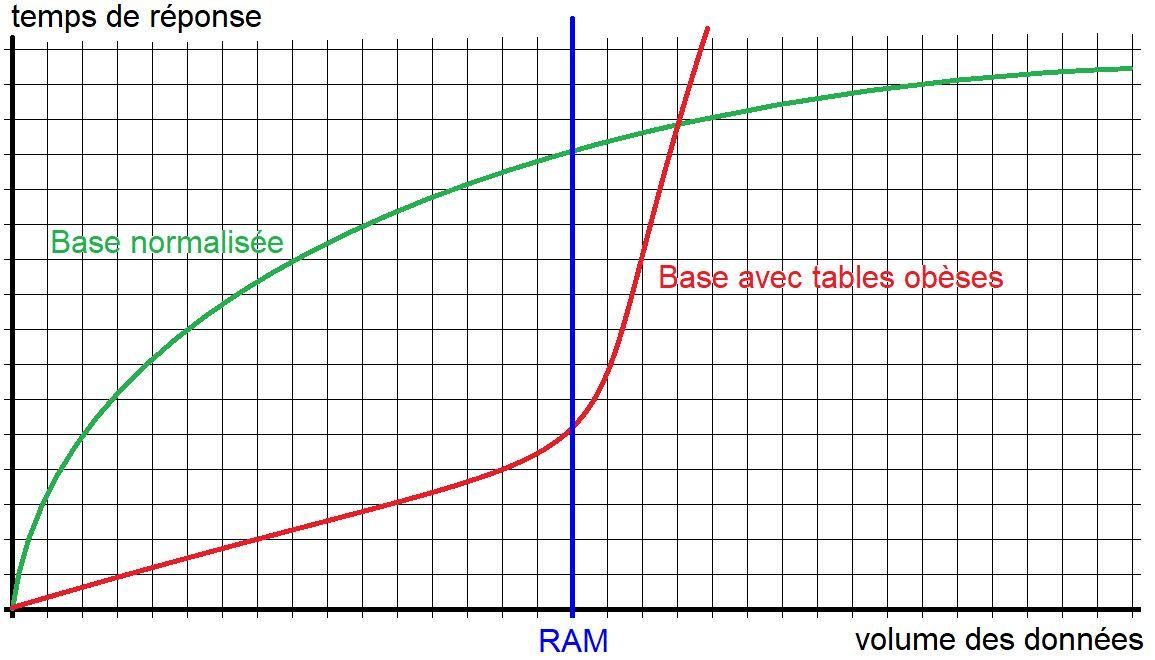
L’application stricte des règles de l’art de la modélisation des bases de données relationnelles donne généralement des tables de très faible degré, c’est-à-dire un nombre de colonnes en moyenne en dessous de 10. Il est alors facile d’indexer correctement ces tables afin d’obtenir de bonnes performances. Mais en présence de tables obèses, c’est-à-dire présentant un nombre de colonnes anormalement élevé, une indexation efficace devient impossible, tant le nombre d’index qu’il faudrait poser est démesuré (voir notre chapitre consacré à l’indexation). De plus, les SGBDR travaillant en mémoire, il est nécessaire que les données visées par une requête figurent en cache. Pour une recherche en index, cela ne représente que quelques pages. En l’absence d’index adéquat, il faut mettre en cache toute la table… C’est pourquoi la RAM est vite saturée en présence de tables obèses, et la majorité des accès se faisant par un balayage (lecture séquentielle de toutes les lignes de la table), les temps de réponse s’accroissent rapidement.
Le syndrome habituel, pour une base de données aux tables obèses, est un basculement relativement abrupt des performances vers le bas, signe que l’on a commencé à saturer le cache, et que désormais, une grande partie des requêtes nécessite des accès disques, épouvantablement plus lents que ceux effectués en mémoire…
I-10. Références pour ce chapitre▲
Toutes nos sources sont celles de publications scientifiques professionnelles (université, associations reconnues), instituts gouvernementaux ou plus rarement de publications personnelles vérifiées par croisement. Toutes sont librement accessibles.
Fondement des SGBDR :
Article 1970 de Franck Edgar Codd « A relational model of data for large shared data banks » :
https://dl.acm.org/doi/10.1145/362384.362685
« Relational Completness of Data Base Sublanguages » F. E. Codd - 1972
https://www.inf.unibz.it/~franconi/teaching/2006/kbdb/Codd72a.pdf
« The Relational Model for Database Management » Version 2 : F. E. Codd – Addison Wesley 1990.
https://dl.acm.org/doi/book/10.5555/77708
Sytem-R d’IBM :
« A History and Evaluation of System R »
https://dsf.berkeley.edu/cs262/SystemR-annotated.pdf
« System R: Relational Approach to Database Management »
https://dl.acm.org/doi/10.1145/320455.320457
Historique Sybase :
https://doc.ispirer.com/sqlways/Output/SQLWays-1-178.html
http://www.fundinguniverse.com/company-histories/sybase-inc-history/
https://seniordba.wordpress.com/2019/04/22/history-of-sql-server-2/
https://blogs.sap.com/2011/04/15/a-deeper-look-at-sybase-history-of-ase/
SGBD Objet :
« Object Database Management Systems - Concepts and Features »
https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication500-179.pdf
« An Introduction to Object-Oriented Databases and Database Systems »
http://reports-archive.adm.cs.cmu.edu/anon/itc/CMU-ITC-103.pdf
SGBD NoSQL :
« NOSQL Database and Its Comparison with RDBMS »
https://www.ripublication.com/ijcir17/ijcirv13n7_08.pdf
« Research on NoSQL Database Technology »
https://www.atlantis-press.com/article/25897262.pdf
Histoire du langage SQL :
« Early History of SQL » D. Chamberlin
https://ieeexplore.ieee.org/document/6359709
Modélisation :
« Modélisation des bases de données » C. Soutou…
https://www.eyrolles.com/Informatique/Livre/modelisation-des-bases-de-donnees-9782416007507/
« Bases de données relationnelles et normalisation : de la première à la sixième forme normale » François de Sainte Marie (alias fsmrel) :
https://fsmrel.developpez.com/basesrelationnelles/normalisation/normalisation.pdf
« Ingénierie des systèmes d’information : Merise Deuxième Génération » 4e édition : D. Nancy, B. Espinasse
https://pageperso.lis-lab.fr/bernard.espinasse/index.php/livre-merise/
Algèbre relationnelle :
« Relational Model and Relational Algebra » Todd J. Green University of California, Davis
https://www.cs.ucdavis.edu/~green/courses/ecs165a-w11/3-ra.pdf
« Conception de Bases de Données Relationnelles » Marc Plantevit
Faculté de Sciences et Technologie - Laboratoire LIRIS - Université Lyon 1
https://perso.liris.cnrs.fr/marc.plantevit/documents/LIF10_CM.pdf
Modèle Entité Association :
« The Entity-Relationship Model-Toward a Unified View of Data » Peter Chen
https://www.csc.lsu.edu/~chen/pdf/erd-5-pages.pdf
Théorie de l’information de Claude Shanon :
« A Mathematical Theory of Communication »
https://people.math.harvard.edu/~ctm/home/text/others/shannon/entropy/entropy.pdf