


III. Les nouveautés du langage Transact SQL▲
Voici une liste que j'espère suffisamment exhaustive des nouveautés de MS SQL Server 2005 en terme de langage Transact SQL...
III-A. Terminaison des lignes▲
Désormais il faut terminer toutes les lignes de code par le caractère point-virgule (;). Ceci est important car certaines syntaxes risquent de ne pas fonctionner correctement dans les procédures, les fonctions, les triggers ou tout simplement dans les différents ordres d'un fichier de "batch".
C'est encore une recommandation faible de MS, mais il y a des exemple déjà connus ou cette syntaxe est requise, notamment avant le lancement de l'ordre SEND (Service Broker)..
III-B. TABLE réparties▲
Sous SQL Server 2000 ont été introduites les vues partitionnées (indexables).
SQL Server 2005 propose dorénavant les tables réparties (partitionnées étant peu français...). La technique consiste à diviser la table en plusieurs partitions logiques (et si possible physique, par exemple sur des grappes RAID distinctes, c'est tout l'intérêt de cette affaire) à l'aide d'une règle de partitionnement introduite par la commande CREATE PARTITION...
Voici, par exemple comment procéder pour équi-répartir une table contenant des noms de personnes à l'aide d'une classification de type CUTTER-SANBORN :
CREATE PARTITION FUNCTION PF_CUTTER (CHAR(25))
AS RANGE LEFT FOR VALUE ('COSTAZ', 'HOENNER', 'PANIER')CREATE PARTITION SCHEMA PS_CUTTER
AS PARTITION PF_CUTTER
TO (FileGroup1, FileGroup2, FileGroup3, FileGroup4)
Notez que, comme la fonction de répartition compte trois valeurs pivot, il y aura quatre espace de stockage. C'est le vieux problème des intervalles...
Bien entendu, FileGroup1 ... FileGroup4 sont des groupes de fichiers préalablement créés sur des ressources de stockage distinctes.
CREATE TABLE T_EMPLOYEE_EMP
(EMP_ID INTEGER NOT NULL,
EMP_MATRICULE CHAR(8) NOT NULL,
EMP_NOM CHAR(25),
...
) ON PS_CUTTER (EMP_NOM)
C'est la colonne EMP_NOM qui est pris en compte par le schéma de répartition avec sa fonction associée.
Désormais les lignes contenant les noms des employés depuis A... jusqu'à COSTAZ inclus (ordre alphabétique, et seront stockées dans le groupe de fichier FileGroup1, celles contenant les noms de COSTAZ exclu à HOENNER inclus dans FileGroup2 et ainsi de suite...
Je n'ai pas encore fait de tests pour savoir si la fonction de partitionnement est sensible à la collation ou non, notamment pour les problématiques de casse ou d'accents et autres caractères diacritiques. Ce test est cepandant facile, car il est possible de savoir sur quelle partition se trouvent vos données...
La l'opérateur $PARTITION permet de récupérer le numéro de la partition pour une valeur spécifique. Cet opérateur doit être appliqué à la fonctrion de répartition. Il s'utilise comme ceci :
SELECT EMP_NOM, $PARTITION.PF_CUTTER(EMP_NOM)
FROM T_EMPLOYEE_EMP
Mieux, on peut compter le nombre de lignes de chacune des partitions pour voir si la répartition est équitable (c'est le but des tables de CUTTER-SANBORN !) :
SELECT $PARTITION.PF_CUTTER(EMP_NOM) AS PARTITION_NUM,
COUNT(*) AS NOMBRE_LIGNE
FROM T_EMPLOYEE_EMP
GROUP BY EMP_NOMIII-C. INDEX▲
On peut désomais contrôler le verrouillage des index avec les options ALLOW_ROW_LOCK et ALLOW_PAGE_LOCK disponibles dans les ordres CREATE et ALTER.
On peut contrôler aussi le parrallélisme d'accès sur un index avec l'option MAXDOP (n)
On peut aussi désactiver un index avec ALTER INDEX ... DISABLE.
Comme une table, un index peut aussi être partitionné lors de sa création. Cela permet notamment de synchronyser les partitions aux niveau des données et des index.
ONLINE ON / OFF permet à un index d'être utilisé ou non pendant les opérations de construction ou de modification d'index.
Certaines opérations relativement pénible qui devaient être exécutées avec le DBCC sont désormais disponible via ALTER INDEX. Il s'agit de :
REBUILD, remplace le DBCC REINDEX
REORGANIZE remplace le DBCC INDEXDEFRAG
Mais la grande nouveauté consiste dans le fait que l'on puisse àjouter des colonnes d'information non indexées dans un index, afi d'assurer la couverture de certaines opérations de récupération de l'information dans les requêtes afin d'éviter de recourrir à des lectures multiples d'index. Cela se fait avec l'option INCLUDE.
Exemple :
CREATE TABLE T_EMPLOYEE_EMP
(EMP_ID INTEGER NOT NULL PRIMARY KEY,
EMP_MATRICULE CHAR(8) NOT NULL,
EMP_TITRE VARCHAR(12),
EMP_NOM CHAR(25),
EMP_PRENOM VARCHAR(16),
EMP_DATE_NAISSANCE DATETIME,
EMP_SALAIRE FLOAT
)
SQL Server à automatiquement créé un index CLUSTER du fait de la présence de la clef primaire. Cependant, la requête suivante :
SELECT EMP_ID, EMP_MATRICULE, EMP_NOM
FROM T_EMPLOYEE_EMP
WHERE EMP_MATRICULE = '12345678'
Fera un balayage de la table à la recherche pour rechercher la ligne.
Mieux, en ajoutant un index sur EMP_MATRICULE de la sorte :
CREATE INDEX IX_EMP_MATRICULE ON T_EMPLOYEE_EMP (EMP_MATRICULE)
Le plan de requête cherchera dans l'index IX_EMP_MATRICULE la valeur '12345678', puis ayant obtenu l'identifiant, le recherchera dans l'index CLUSTER afin de reprendre l'information concernant le nom.
Dans un tel cas, la construction d'un index comme :
CREATE INDEX IX_EMP_MATRICULE_IN_NOM_OUT
ON T_EMPLOYEE_EMP (EMP_MATRICULE)
INCLUDE (EMP_NOM)
Permet de s'éviter la double lecture de l'index puisque toutes les informations requise pour alimenter les données à renvoyées sont présente dans l'index IX_EMP_MATRICULE_IN_NOM_OUT. Dans un tel cas, le temps de traitement est divisé par deux. Le seul inconvénient est un temps d'insertion et de modification des lignes plus grand du fait de l'effort plu important à réliser afin d'alimenter le redondance.
III-D. Gestion des exceptions▲
S'il y avait bien un point à rectifier dans le Transact SQL, c'est bien celui là : la gestion des erreurs, et plus généralement des exceptions. L'écriture avant SQL Server 2005 était proche de celle du Cobol ! En effet, voici comment il fallait piloter une transaction composée de trois requêtes de mise à jour avec ma version 2000 :
BEGIN TRANSACTION
DELETE FROM ...
IF @@ERROR <> 0
GOTO LBL_ROLLBACK_ON_ERROR
INSERT INTO ...
IF @@ERROR <> 0
GOTO LBL_ROLLBACK_ON_ERROR
UPDATE ...
IF @@ERROR <> 0
GOTO LBL_ROLLBACK_ON_ERROR
COMMIT TRANSACTION
RETURN
LBL_ROLLBACK_ON_ERROR:
ROLLBACK
Il n'y avait d'ailleurs pas moyen d'obtenir grand chose sur le pourquoi du comment de l'erreur, tout étant dans une unique information : le numéro de l'erreur !
Désormais, comme dans tout langage moderne, Transact SQL dispose avec SQL Server 2005 d'une structure de bloc de capture d'erreur. Voici la même procédure que ci dessus, avec l'encapsulation de la gestion d'exception :
BEGIN TRY
BEGIN TRANSACTION
DELETE FROM ...
INSERT INTO ...
UPDATE ...
COMMIT TRANSACTION
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION
END CATCH
Mais pour être parfait le code doit être un peu amélioré. En effet, cette version capture toutes les erreurs y compris les plus insignifiantes. pour ne plus s'occuper que des erreurs sur les phases de manipulations de données, voici comment procéder :
BEGIN TRY
BEGIN TRANSACTION
...
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF XACT_STATE() = -1
ROLLBACK TRANSACTION
IF XACT_STATE() = 1
COMMIT TRANSACTION
END CATCH
MS SQL Server 2005 introduit la fonction XACT_STATE capable de déterminer si la transaction est active et validable (1), active et en erreur (-1) ou bien inactive (0, transaction terminée et déjà validée ou pas de transaction du tout).
En plus de cette fonction, certaines fonctions supplémentaires permettent d'obtenir des informations sur l'erreur génératrice de la levée d'exception :
| ERROR_NUMBER | le numéro de l'erreur (vue sys.messages dans master). |
| ERROR_SEVERITY | le niveau de sévérité |
| ERROR_STATE | le niveau d'état de l'erreur |
| ERROR_PROCEDURE | le nom de la procédure stockée ou du trigger dans laquelle l'exception s'est produite |
| ERROR_LINE | le numéo de la ligne ou s'est produite l'erreur |
| ERROR_MESSAGE | le message de l'erreur avec les emplacements de pramètres |
L'utilisation des blocs TRY/CATCH nécessite le positionnement du flag XACT_ABORT à ON
III-E. Trigger de DDL▲
Voici une idée quelque peu reprise d'Oracle : pourquoi ne pas mettre en oeuvre des triggers sur la création, la suppression ou la modification des objets d'une base, voir de lancer du code lors de la création ou la suppression d'une base de données ?
C'est ce que propose désormais MS SQL Server 2005 à travers les triggersd DDL (rapellons pour ceux qui ne sont pas familié avec le langeg SQL que DDL signifie Data Definition Language, et c'est la partie du SQL qui s'occupe de créer, modifier ou supprimer les objets à l'aide des ordres CREATE, ALTER et DROP).
CREATE TRIGGER nom
ON { DATABASE | ALL SERVER }
FOR <événement>
AS
...
Les événements capturables au niveau base de données sont les suivants :
| CREATE_, ALTER_, DROP_ | APPLICATION_ROLE, ASSEMBLY, CERTIFICATE, CONTRACT, FUNCTION, INDEX, MESSAGE_TYPE, PARTITION_FUNCTION, PARTITION_SCHEME, PROCEDURE, QUEUE, REMOTE_SERVICE_BINDING, ROLE, ROUTE, SCHEMA, SERVICE, TABLE, TRIGGER, USER, VIEW, XML_SCHEMA_COLLECTION |
| CREATE_,DROP_ | EVENT_NOTIFICATION, SYNONYM, TYPE, STATISTICS |
| (autres) | ALTER_AUTHORIZATION_DATABASE, GRANT_DATABASE, DENY_DATABASE, REVOKE_DATABASE, UPDATE_STATISTICS |
Les événements capturables au niveau serveur sont les suivants :
ALTER_AUTHORIZATION_SERVER
CREATE_ENDPOINT
DROP_ENDPOINT
CREATE_LOGIN
ALTER_LOGIN
DROP_LOGIN
GRANT_SERVER
DENY_SERVER
REVOKE_SERVER
En sus, SQL Server 2005 fournit un "paquet" informatif sur l'événement pisté par le trigger, et accessible via la fonction EVENTDATA qui retourne un document XML. Bien entendu les attributs disponibles dans ce document différent en fonction de la nature de l'événement suivi.
Voici un exemple d'utilisation d'un tel trigger qui alerte par mail l'administrateur de bases de données de la création d'une nouvelle table dans la base et lui envoie le texte de l'ordre SQL de création de cette table. Notez comment a été extrait du document XML l'information qui nous intéressait :
CREATE TRIGGER E_ALERTE_CREATION_TABLE
ON DATABASE
FOR CREATE_TABLE
AS
DECLARE @SQLORDER VARCHAR(max)
SELECT @SQLORDER = EVENTDATA().value('(/EVENT_INSTANCE/TSQLCommand/CommandText)[1]',
'nvarchar(max)')
EXEC xp_sendmail @recipients = 'dba@myOrganisation.com',
@subject = 'Table créée dans la base ' + DB_NAME(),
@message = @SQLORDER
EVENTDATA() retourne le flux XML dont on extrait la valeur de l'élément "/EVENT_INSTANCE/TSQLCommand/CommandText)[1]" à l'aide de la fonction XQuery value.
III-F. Niveau d'isolation SNAPSHOT▲
Un nouveau niveau d'isolation, hors norme, de type SNAPSHOT a été ajouté. Il permet de réaliser ses transactions sur un cliché (un instantané des objets scrutés). Il est basé sur une verouillage optimiste et évite donc un tout vérouillage en lecture. Voici un niveau d'isolation idéal pour assurer des lectures complexes de données avec de forts volumes (calculs statistiques massifs sur des données en production par exemple)
En complément, l'article de Ravindra Okade sur le sujet .
III-G. Base de données SNAPSHOT (cliché)▲
Il est désormais possible de créer une base de données de type SNAPSHOT et de travailler dessus. Une base de données SNAPSHOT n'est autre qu'un cliché à un instant T d'une quelqconque base de données de SQL Server 2005. Le mécanisme de SNAPSHOT est extrémement rapide puisqu'au départ, aucune pas n'est copiée. Seules les pages qui vont être modifiées dans le futur et dans la base source seront envoyée dans le fichier du cliché avant modification.
Cette technique, déjà employée par Oracle, permet de restreindre de manière drastique le verouillage pendant des opérations de lecture lourde. Si l'on imagine une base de données OLTP fortement sollicité en exploitation courante et utilisée de temps à autre pour des extractions massives d'information telles que de l'analyses statistiques de données (donc proche des techniques OLAP), alors, il y a tout intérêt à utiliser cette possibilité pour executer les requêtes d'analyses statistiques sur un cliché de la base plutôt qu'en direct sur la base elle même. Ceci minimisera les poses de verrous tout en permettant un plus grand parallélisant dans les traitements.
III-H. Base de données mirroir▲
Il est possible de paramétrer une base de données pour qu'elle s'exécute en mirroir, c'est à dire une copie absolue et synchrone des données sur un autre serveur. Dans ce cas un mécanisme de validation en deux phases fait que toute transaction opérer sur la base originale n'est assurément complète qu'après la validation sur la base mirroir. Cela peut se faire avec ou sans serveur d'observation. Avec serveur d'observation le basculement est automatique et transparent. Le serveur d'observation peut être une version légère de MS SQL Server 2005 comme SQL Server Express (le remplaçant de MSDE).
III-I. Nouveaux paramètres de base de données▲
A la création, par défaut le pas d'incrément du grossissement des fichiers n'est plus de 10% mais de 1 Mo.
En dehors de la possibilité de créer des bases de données snapshot (cliché) ou mirroir, on trouve les paramètres suivants dans les ordres CREATE et/ou ALTER DATABASE :
EMERGENCY : base en mode lecture seule accessible sans login aux rôles fixe de servgeur et aux membres du groupe sysadmin (maintenance en cas de base suspecte par exemple)
DB_CHAINING : permet le chaînage des privilèges entre différentes bases
TRUSTWORRTHY : permet l'accès de modules dépersonalisés (UDT par exemple) à des ressources externes à la base de données
AUTO_UPDATE_STATISTIC_ASYNC : permet qu'une requête n'attende pas la fin du calcul de mise à jour des statistiques pour s'exécuter.
PAGE_VERIFY ( CHECKSUM ) : mise en place d'une vérification de cohérence binaire des pages effectuée entre le disque et la mémoire par recalcul du code redondant (Attention : couteux en temps et performances).
SUPPLEMENTAL_LOGGING : ajoute au journal des informations propres aux éditeurs d'add-on SQL Server 2005 (Attention : couteux en temps et performances)
DATE_CORRELATION_OPTIMIZATION : dans le cas d'une intégrité référentielle entre deux tables, basées sur au moins une colonne de type DATETIME, SQL Server maintien une corrélation statistique des données, permettant une plus grande optimisation des requêtes.
PARAMETRIZATION : permet de piloter le comportement de l'optimiseur de plans de requête lorsqu'il se trouve face à des requêtes comportant des valeurs scalaires pouvant être paramétrées.
III-J. Plan de requête▲
De nombreuses améliorations ont été apportées au plan de requête.
Désormais, le plan de requête peut être externalisé et réinjecté sous la forme d'un document XML. Cela permet de charcuter un tel plan (hauts risques) afin d'obliger un comportement particulier du moteur SQL. La visualisation du plan de requête sous forme XML se produit lorsque le flag STATISTICS XML est positionné à on :
SET STATISTICS XML ON
D'autre part, le moteur est maintenant capable de reconnaître des requêtes similaires contenant des valeurs scalaires différentes (paramètres) comme étant une même requête paramétrable. Dès lors si un plan de calcul a déjà été établi pour une valeur particulière des paramètres, il sera repris pour les autres valeurs de cette même requête.
Dans le même esprit un ordre SQL au sein d'une procédure peut maintenant faire l'objet d'une compilation et donc du calcul d'un plan de requête indépendant de l'ensemble de la procédure. Autrement dit, il s'agit d'un genre particulier de recompilation partielle.
III-K. Journal▲
- d'éviter en cas de reprise après panne, de jouer les transactions finalement annulées (temps de reprise plus court);
- d'ajouter dans le journal même des informations en provenances d'add-on SQL server venant d'éditeurs tiers.
III-L. Envoi de mails▲
Ceux qui, comme moi, trouvait complétement hallucinant de devoir ajouter un serveur Exchange pour envoyer un simple mail par SQL Server, seront désormais content de savoir que l'on peut envoyer un mail via la procédure stockée sendimail_sp, dont la syntaxe est assez poussée :
sendimail_sp [ [ @profile_name = ] 'profile_name' ]
[ , [ @recipients = ] 'recipients [ ; ...n]' ]
[ , [ @copy_recipients = ] 'copy_recipient [ ; ...n]' ]
[ , [ @blind_copy_recipients = ] 'blind_copy_recipient [ ; ...n]' ]
[ , [ @subject = ] 'subject' ]
[ , [ @body = ] 'body' ]
[ , [ @body_format = ] 'body_format' ]
[ , [ @importance = ] 'importance' ]
[ , [ @sensitivity = ] 'sensitivity' ]
[ , [ @file_attachments = ] 'attachment [ ; ...n]' ]
[ , [ @query = ] 'query' ]
[ , [ @execute_query_database = ] 'execute_query_database' ]
[ , [ @attach_query_result_as_file = ] attach_query_result_as_file ]
[ , [ @query_attachment_filename = ] query_attachment_filename ]
[ , [ @query_result_header = ] query_result_header ]
[ , [ @query_result_width = ] query_result_width ]
[ , [ @query_result_separator = ] 'query_result_separator' ]
[ , [ @exclude_query_output = ] exclude_query_output ]sendimail_sp
@profile_name = 'AdminMabase',
@recipients = 'sqlpro@microsoft.com',
@query = 'SELECT COUNT(*) FROM T_CHAMBRE
WHERE CHB_COUCHAGE > 2 ,
@subject = 'Chambre de plus de 2 couchage',
@attach_query_result_as_file = 1 ;
Dans cet exemple, on envoie à sqlpro@microsoft.com avec le profil AdminMabase, le résultat de la requête dont la chaîne SQL est passée en paramètre. Certe il était possible de faire cela dans SQL Server 2000, à condition de savoir piloter des objets de type Ole à partir de commandes Transact SQL !
sendimail_sp n'est pris en charge qu'une fois que les objets de mailing aient été installés dans une base hôte de messagerie.
III-M. Verrous mortels▲
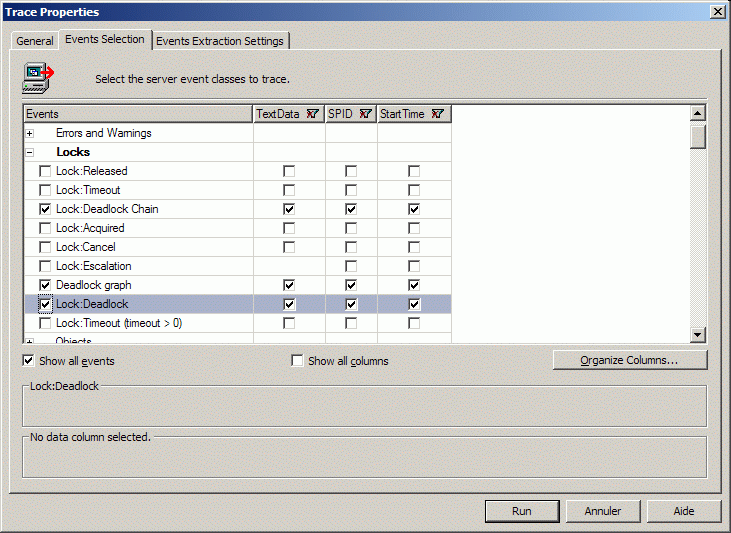
Un outil d'explication des verrous mortels (deadlocks, étreinte fatale, interblocage) a été mis en place. Il permet de visauliser le processus bloquant et les processus bloqués. Il est disposnible dans le profiler SQL (trace). En activant dans le menu des événement à tracer, sous l'entrée "Locks" l'item "Deadlock Graph", vous disposez d'un affichage graphique des processus en jeu.
Voici un exemple de ce que cet outil restitue visuellement :
1) Activation du profiler avec suivi des événements de verrouillage mortel (deadlock, verrou mortel, étreinte fatale et interblocage sont des synonymes) :
2) Après avoir obtenu un verrou mortel, visualisez la trace dans le profiler :
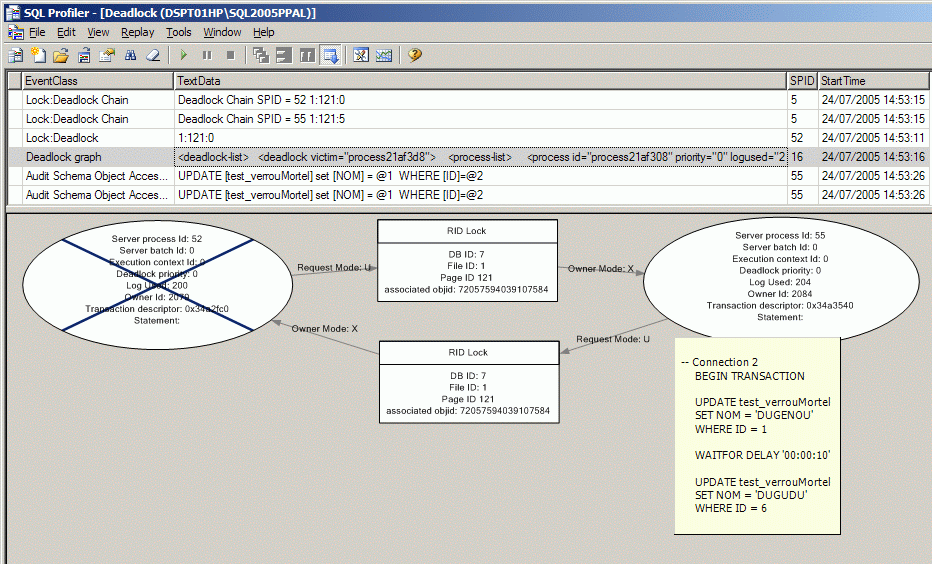
3) Vous pouvez sauvegarder ces informations sous la forme d'un fichier xdl qui contient le graphique ci dessus au format XML :
<deadlock-list>
<deadlock victim="process21af3d8">
<process-list>
<process id="process21af308" priority="0" logused="204"
waitresource="RID: 7:1:121:5" waittime="12998" ownerId="2084"
transactionname="user_transaction"
lasttranstarted="2005-07-24T14:53:03.003" XDES="0x34a3540" lockMode="U"
schedulerid="1" kpid="2924" status="suspended" spid="55" sbid="0"
ecid="0" transcount="2" lastbatchstarted="2005-07-24T14:47:08.407"
lastbatchcompleted="2005-07-24T14:46:36.270"
clientapp="SQL Server Management Studio - Query" hostname="DSPT01HP"
hostpid="3280" loginname="sa" isolationlevel="read committed (2)"
xactid="236223201281" currentdb="7" lockTimeout="4294967295"
clientoption1="671090784" clientoption2="390200">
<executionStack>
<frame procname="adhoc" line="4" stmtstart="54"
sqlhandle="0x020000008a29270045c3cde9ab6112567469ffe4a4a34104">
UPDATE [test_verrouMortel] set [NOM] = @1 WHERE [ID]=@2 </frame>
<frame procname="adhoc" line="4" stmtstart="92" stmtend="240"
sqlhandle="0x02000000b5084a220d1ee556e23143e29580c1f2c3f2ca47">
UPDATE test_verrouMortel
SET NOM = 'DUGENOU'
WHERE ID = 1 </frame>
</executionStack>
<inputbuf>
BEGIN TRANSACTION
UPDATE test_verrouMortel
SET NOM = 'DUGENOU'
WHERE ID = 1
WAITFOR DELAY '00:00:10'
UPDATE test_verrouMortel
SET NOM = 'DUGUDU'
WHERE ID = 6
</inputbuf>
</process>
<process id="process21af3d8" priority="0" logused="200"
waitresource="RID: 7:1:121:0" waittime="4967" ownerId="2079"
transactionname="user_transaction"
lasttranstarted="2005-07-24T14:53:01.070" XDES="0x34a2fc0" lockMode="U"
schedulerid="1" kpid="2852" status="suspended" spid="52" sbid="0"
ecid="0" transcount="2" lastbatchstarted="2005-07-24T14:47:07.267"
lastbatchcompleted="2005-07-24T14:46:50.290"
clientapp="SQL Server Management Studio - Query" hostname="DSPT01HP"
hostpid="3280" loginname="sa" isolationlevel="read committed (2)"
xactid="223338299400" currentdb="7" lockTimeout="4294967295"
clientoption1="671090784" clientoption2="390200">
<executionStack>
<frame procname="adhoc" line="13" stmtstart="54"
sqlhandle="0x020000008a29270045c3cde9ab6112567469ffe4a4a34104">
UPDATE [test_verrouMortel] set [NOM] = @1 WHERE [ID]=@2 </frame>
<frame procname="adhoc" line="13" stmtstart="330"
sqlhandle="0x020000001454d004cc5495b1dbeb741009ea2e13ef9460ce">
UPDATE test_verrouMortel
SET NOM = 'DUMONT'
WHERE ID = 1 </frame>
</executionStack>
<inputbuf>
BEGIN TRANSACTION
UPDATE test_verrouMortel
SET NOM = 'DUHAMEL'
WHERE ID = 6
WAITFOR DELAY '00:00:10'
UPDATE test_verrouMortel
SET NOM = 'DUMONT'
WHERE ID = 1
</inputbuf>
</process>
</process-list>
<resource-list>
<ridlock fileid="1" pageid="121" dbid="7"
objectname="TEST.dbo.test_verrouMortel" id="lock2fb4c80" mode="X"
associatedObjectId="72057594039107584">
<owner-list>
<owner id="process21af308" mode="X"/>
</owner-list>
<waiter-list>
<waiter id="process21af3d8" mode="U" requestType="wait"/>
</waiter-list>
</ridlock>
<ridlock fileid="1" pageid="121" dbid="7"
objectname="TEST.dbo.test_verrouMortel" id="lock2fb4e40" mode="X"
associatedObjectId="72057594039107584">
<owner-list>
<owner id="process21af3d8" mode="X"/>
</owner-list>
<waiter-list>
<waiter id="process21af308" mode="U" requestType="wait"/>
</waiter-list>
</ridlock>
</resource-list>
</deadlock>
</deadlock-list>III-N. Synonymes▲
Afin de singer les pauvres et irrespectueuses limites d'Oracle en matière de noms d'objet SQL, MS SQL Server à introduit la mauvaise idée du concept de synonyme. Vous pouvez donc, même si c'est une horreur, donner un nom simple à n'importe quel objet de la base, c'est à dire aux procédure stockées, fonctions, tables et vues, et ainsi cintroduire la plus grande confusion dans votre base de données. La syntaxe pour ce faire est la suivante :
CREATE SYNONYM <nom_synonyme> FOR <nom_objet>III-O. Cryptage▲
Le cryptage des données est désormais possible via l'utilisation de "certificats". Une clef maître de cryptage est créée lors de l'installation de MS SQL Server 2005. Elle a pour nom : "Service Master key". Chaque base de données doit avoir sa propre clef de chiffrement, que l'on obtient par la commande :
CREATE MASTER KEY ENCRYPTION BY PASWORD = '...'
La vue système sys.symmetric_keys, contient les informations des clefs de chiffrement.
Une fois cette clef créée, vous pouvez obtenir un certificat (ou une clef asymetrique) qui vous permettra de crypter les données que vous avez à véhiculer. Le certificat s'obtient par la commande :
CREATE CERTIFICAT <nom_certif>
WITH SUBJECT = '<libelle>'
EXPIRY_DATE = '<date_expiration>'
Notez qu'un certificat n'est donc valable qu'un certain temps...
Pour crypter et décrypter des données, vous pouvez utiliser les fonctions suivantes :
| EncryptByCert() | DecryptByCert() |
| EncryptByAsymKey() | DecryptByAsymKey() |
| EncryptByKey() | DecryptByKey() |
| EncryptByPassphrase() | DecryptByPassphrase() |
En sus, la fonction Cert_id('<nom_certif>') renvoie l'identifiant du certificat en passant son nom comme paramètre.
CREATE CERTIFICAT SQLpro
WITH SUBJECT = 'Fred Brouard'
EXPIRY_DATE = '20050831'
EncryptByCert(Cert_id('SQLpro'), 'Ma phrase à crypter...' )
Le cryptage des données est nécessaire notamment pour l'utilisations des Web services via SQL Service Broker notamment dans les phases d'authentification et les processus de messagerie. En revanche le cryptage des données à l'intérieur d'une base ne relève que peu d'intérêt.
A lire l'excellent article de Marcin Policht sur le sujet.
III-P. Dépersonalisation (Execute AS)▲
SQL Server 2005 permet de définir implicitement le contexte d'exécution d'une procédure, une fonction (sauf table en ligne), un trigger (y compris DDL) ou une file d'attente (QUEUE dans Service Broker). Cette technique requiert l'utilisation du mot clef EXECUTE AS avec en paramètre le nom d'utilisateur (ou de connexion dans la cas d'un trigger DDL de serveur, ou bien à l'aide des paramètres objet CALLER, SELF ou OWNER. Dès lors la sécurité d'exécution et son contexte sont codé dans l'objet. Cela permet par exemple de donner des privilèges et donc de gérer une sécurité fine à des commande qui sont dépourvues de securité, comme la commande TRUNCATE.
CREATE PROCEDURE P_TRUNCATE (@A_TABLE NVARCHAR(128))
WITH EXECUTE AS 'SQL_troncator'
AS
DECLARE @QUERY NVARCHAR(150)
SET @QUERY = 'TRUNCATE TABLE ' + @A_TABLE
EXECUTE (@SQL)La fonction REVERT permet de revenir au contexte d'exécution de l'appelant.
III-Q. Conclusion▲
Les tables réparties comme les manipulations d'index en ligne et le snapshot, comme le mirroir de bases sont des nouveautés visant les VLDB (Very Large Data Bases), marché dans lequel SQL Server s'est finalement bien introduit comme en témoigne WinterCorp. La gestion des exceptions, autrefois point noir du codage Transact SQL hérite des techniques des langages modernes et c'est un plus indéniable. Les triggers de DLL apportent de bonnes solutions à des problématiques complexes, notamment à l'absence d'assertion (norme SQL), encore faudrat-il n'en point abuser. La procédure sendimail_sp est un bienfait à l'horrible verrue que constituait l'envoi de mail par les versions antérieures de SQL Server. Quant à plan de requête en XML, l'avenir dira comment il sera utilisé !
Bref, presque rien que du bon, à l'exception de la stupide introduction des synonymes pour singer Oracle.