


II. Améliorations apportées au langage SQL ▲
Voici une liste que j'espère suffisamment exhaustive des nouveautés de MS SQL Server 2005 et terme de "pur" langage SQL...
II-A. Jointure externes (norme SQL 1992) ▲
Excellente nouvelle : les jointures externes avec une syntaxe propre à SQL server et rendant des résultats souvent faux, ne sont désormais plus accéptées nativement. Cette nouvelle ne va pas réjouir un certains nombre de développeurs et de DBA qui se la sont "coulé douce" depuis une décennie... Les jointures externe normatives sont dans la norme depuis 1992 et ont commencées à être supportées par SQL Server version 6.5. MS a mis en garde ses utilisateurs depuis la version 2000 qu'il était nécessaire d'utiliser les jointures normatives à base de LEFT, RIGHT ou FULL OUTER JOIN parce qu'elles ne seraient plus supportées dans les version futures...
Le message d'erreur est alors le suivant :
Msg 4147, Level 15, State 1, Line ...
The query uses non-ANSI outer join operators ("*=" or "=*"). To run this query without modification, please set the compatibility level for current database to 80 or lower, using stored procedure sp_dbcmptlevel. It is strongly recommended to rewrite the query using ANSI outer join operators (LEFT OUTER JOIN, RIGHT OUTER JOIN). In the future versions of SQL Server, non-ANSI join operators will not be supported even in backward-compatibility modes.
II-B. Opérateur EXCEPT et INTERSECT (SQL:1992)▲
Dorénavant, SQL Server se conforme à la norme et propose les opérateurs ensemblistes EXCEPT (différence) et INTERSECT (intersection). Cepandant, et comme c'est le cas de l'actuel UNION, ces trois opérateurs n'implémente pas le prédicat USING.
Exemple pour la différence :
CREATE TABLE MACHINE
(MAC_NOM VARCHAR(12))
CREATE TABLE OBJET
(OBJ_NOM VARCHAR(12))INSERT INTO MACHINE VALUE('Moto')
INSERT INTO MACHINE VALUE('Perçeuse')
INSERT INTO MACHINE VALUE('Avion')
INSERT INTO MACHINE VALUE('Ventilateur')
INSERT INTO MACHINE VALUE('Réveil')
INSERT INTO OBJET VALUE('Moto')
INSERT INTO OBJET VALUE('Assiette')
INSERT INTO OBJET VALUE('Livre')
INSERT INTO OBJET VALUE('Table')
INSERT INTO OBJET VALUE('Perçeuse')SELECT OBJ_NOM
FROM T_OBJET
WHERE OBJ_NOM NOT IN (SELECT MAC_NOM
FROM T_MACHINE)SELECT O.OBJ_NOM
FROM T_OBJET O
LEFT OUTER JOIN T_MACHINE M
ON O.OBJ_NOM = M.MAC_NOM
GROUP BY O.OBJ_NOM
HAVING COUNT(M.MAC_NOM) = 0
OBJ_NOM
----------------
ASSIETTE
LIVRE
TABLESELECT OBJ_NOM
FROM T_OBJET
EXCEPT
SELECT MAC_NOM
FROM T_MACHINEII-C. Nouveau type XML (norme SQL:2003)▲
SQL Server accepte dorénavant le type XML comme le prévoit la norme SQL:2003. Ce type SQL permet d'insérer une grappe XML valide ou un document XML validé par rapport à un schéma XSD. De plus des méthodes spécifiques ont été introduites et un document XML validé peut être indexé de manière interne (voir ci après).
Les types DATE et TIME étaient prévus mais n'ont finalement pas été intégrés à cette version. Des problèmes de performances dans l'implémentation de ces types seraient à l'origine de la décision de MS de ne pas les intégrer à la version primale de MS SQL Server 2005
II-D. Amélioration des types existants▲
Les types VARCHAR, NVARCHAR et VARBINARY ont été améliorés et peuvent franchir la barre des 8000 octets. Pour cela, il faut indiquer une taille indéfinie à l'aide du marqueur "max".
CREATE TABLE T_MAX
(MAX_VARCHAR VARCHAR(max),
MAX_NVARCHAR NVARCHAR(max),
MAX_VARBIN VARBINARY(max))
INSERT INTO T_MAX VALUES (REPLICATE('X', 10000), REPLICATE('Y', 100000),
CAST(REPLICATE('F', 1000000) AS VARBINARY(max))Ils restent néanmoins limités à 2 Go de données.
Prenez simplement conscience qu'un LIKE sur une colonne de type VARCHAR(max) contenant en moyenne 60 000 caractères dans une table de plusieurs dizaines de milliers de lignes, risque de prendre... un certain temps !
II-E. Écriture des expressions de table (CTE : Common Table Expression, norme SQL:1999)▲
Les expressions de tables permettent des écritures très synthétiques de requêtes SQL. Elles ont été introduite avec la norme SQL:1999. Leur intérêt principal est de permettre des expression de requêtes récursives.
Extrait de mon livre "SQL" Pearson Education 2005, collection Synthex, co écrit avec Christian Soutou :
"Une expression de table consiste à exprimer une requête SELECT que l'on considérera comme une table dans la requête qui suivra cette expression. La création d'une vue répond à ce même principe tout en étant considéré comme un objet persistent de la base de données tandis que l'expression de table est créée dynamiquement et pour les besoins spécifique de la requête.
L'expression de table est utile pour simplifier certaines requêtes. Elle s'avère indispensable pour permettre un traitement récursif des données de la requête, parce qu'une corrélation est possible entre l'expression de table et la requête qui la construit."
Exemple : soit le réseau de transport suivant (théorie des graphes) ...
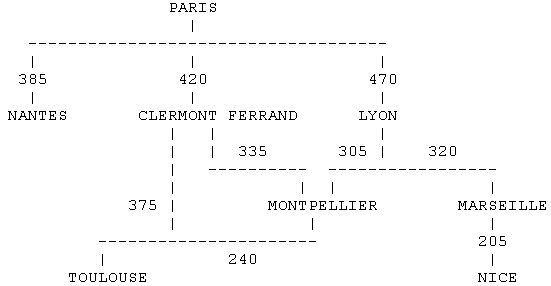
... composé de la table :
CREATE TABLE T_JOURNEY
(JNY_FROM_TOWN VARCHAR(32),
JNY_TO_TOWN VARCHAR(32),
JNY_MILES INTEGER)
... avec les données :
INSERT INTO T_JOURNEY VALUES ('PARIS', 'NANTES', 385)
INSERT INTO T_JOURNEY VALUES ('PARIS', 'CLERMONT-FERRAND', 420)
INSERT INTO T_JOURNEY VALUES ('PARIS', 'LYON', 470)
INSERT INTO T_JOURNEY VALUES ('CLERMONT-FERRAND', 'MONTPELLIER', 335)
INSERT INTO T_JOURNEY VALUES ('CLERMONT-FERRAND', 'TOULOUSE', 375)
INSERT INTO T_JOURNEY VALUES ('LYON', 'MONTPELLIER', 305)
INSERT INTO T_JOURNEY VALUES ('LYON', 'MARSEILLE', 320)
INSERT INTO T_JOURNEY VALUES ('MONTPELLIER', 'TOULOUSE', 240)
INSERT INTO T_JOURNEY VALUES ('MARSEILLE', 'NICE', 205)
Une question que l'on peut se poser est la suivante : quel est le plus court chemin pour aller de Paris à Toulouse ?
Avant l'introduction du CTE et des requêtes récursives, il n'existait pas de solution sous forme d'une requête SQL à cette simple question. Désormais, la requête suivante répond à la question :
WITH
journey (DESTINATION, ETAPES, DISTANCE, CHEMIN)
AS
(SELECT DISTINCT JNY_FROM_TOWN, 0, 0, CAST('PARIS' AS VARCHAR(MAX))
FROM T_JOURNEY
WHERE JNY_FROM_TOWN = 'PARIS'
UNION ALL
SELECT JNY_TO_TOWN, departure.ETAPES + 1,
departure.DISTANCE + arrival.JNY_MILES,
departure.CHEMIN + ', ' + arrival.JNY_TO_TOWN
FROM T_JOURNEY AS arrival
INNER JOIN journey AS departure
ON departure.DESTINATION = arrival.JNY_FROM_TOWN),
short (DISTANCE)
AS
(SELECT MIN(DISTANCE)
FROM journey
WHERE DESTINATION = 'TOULOUSE')
SELECT *
FROM journey j
INNER JOIN short s
ON j.DISTANCE = s.DISTANCE
WHERE DESTINATION = 'TOULOUSE'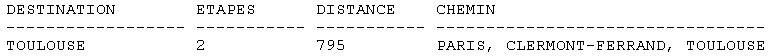
La clause WITH intoduisant le CTE est utilisable aussi dans les ordres DELETE, INSERT, UPDATE et dans la construction des vues. Par exemple on peut supprimer tout un sous arbre partant d'un noeud dans une table présentant une hiérarchie en auto référence.
Vous pouvez lire ici un article très complet sur le sujet. Il doit paraître en français dans SQL Server magazine d'octobre 2005.
II-F. Amélioration de l'intégrité référentielle (norme SQL:1992)▲
Deux nouvelles manière de gérer l'intégrité référentielle ont été implémentées. Bien que datant de la norme SQL2 (1992), MS SQL Server était en retard à ce sujet.
II-F-1. IR et SET NULL ▲
Désormais en cas de modification de la valeur de la clef, comme en cas de suppression de la référence, les lignes filles peuvent voir leur clefs étrangères valuées à NULL.
II-F-2. IR et SET DEFAULT ▲
Désormais en cas de modification de la valeur de la clef, comme en cas de suppression de la référence, les lignes filles peuvent voir leur clefs étrangères valuées à la valeur par défaut définie dans l'expression de construction de la table.
L'intérêt de ces deux nouvelles règles de gestion de l'intégrité référentielle réside dans l'obtention de performances par déport de l'effort de suppression comme par minimisation du verrouillage. En effet, avec un tel mécanisme, la suppression des lignes filles des tables référencées peut se faire dans un batch de nuit (ramasse miette), plutôt que par une cascade de "delete" à un moment de la journée ou la charge est maximale.
CREATE TABLE T_CLIENT_CLI
(CLI_ID INTEGER NOT NULL IDENTITY PRIMARY KEY,
CLI_NOM VARCHAR(32))
CREATE TABLE T_FACTURE_FAC
(FAC_ID INTEGER NOT NULL IDENTITY PRIMARY KEY,
FAC_DATE DATETIME NOT NULL CURRENT_TIMESTAMP,
FAC_MONTANT FLOAT NOT NULL,
CLI_ID INTEGER DEFAULT 0
FOREIGN KEY REFERENCES T_CLIENT_CLI (CLI_ID)
ON UPDATE SET DEFAULT
ON DELETE SET NULL)II-G. Fonctions de classement et d'énumération (norme SQL:2003)▲
Certaines fonctions de classement et d'énumération, dites de fenêtrage, prévues par la norme SQL:2003 ont été ajoutées à SQL Server 2005 : RANK, DENSE_RANK et ROW_NUMBER. Microsoft à rajouté NTILE qui permet des regroupements par tranches énumérées par des valeurs discrètes.
Extrait de mon livre "SQL" Pearson Education 2005, collection Synthex, co écrit avec Christian Soutou :
"
Fonctions de fenétrage et statistiques avancées (SQL:2003)
Les fonctions de "fenêtrage" s'appliquent au résultat de la requête et permettent par exemple la numérotation des lignes retournées ou l'établissement d'un rang. La syntaxe (simplifiée) est la suivante :
{ RANK()
| DENSE_RANK()
| PERCENT_RANK()
| CUME_DIST()
| ROW_NUMBER() } OVER <expression_specification>
RANK permet le classement absolu avec comptage des ex-aequo et DENSE_RANK sans le comptage des exaequo. PERCENT_RANK un classement en pourcentage. CUM_DIST la distribution cumulative et ROW_NUMBER numérote les lignes.
L'expression de spécification doit contenir l'ordre dans lequel les colonnes ou expressions doivent être triées pour que le classement ou la numérotation opère.
SELECT ROW_NUMBER() OVER(ORDER BY USR_ID) RNUM,
USR_ID, USR_NOM, USR_PRENOM,
RANK() OVER(ORDER BY USR_PRENOM) RANK,
DENSE_RANK() OVER(ORDER BY USR_PRENOM) DENSE_RNK
FROM T_UTILISATEUR_USR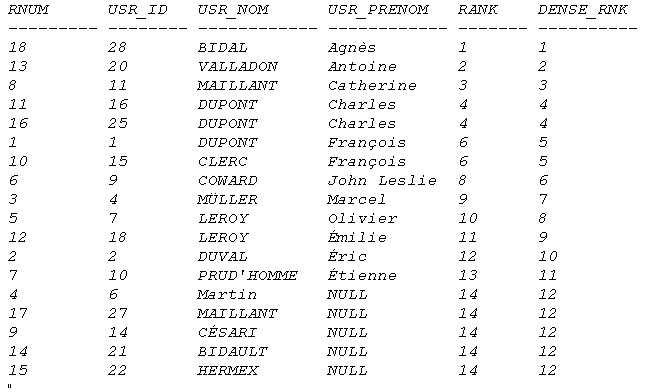
-
Microsoft SQL Server 2005 n'implémente pas les fonctions normatives PERCENT_RANK et CUM_DIST.
Quant à la fonction NTILE, spécifique à SQL Server 2005, elle permet de regrouper par tranches contenant un nombre en principes égaux de lignes les valeurs des colonnes visées. Cela peut être utilepour classer par sous groupe les éléments d'un ensemble. Par exemple, dans une classe de 16 élèves on peut créer trois groupes de travail pour les cours de gymnastique. Les forts, les moins forts et les faibles. Dans ce cas la fonction NTILE placera les six premiers des épreuves de sélection sportive dans le groupe 1, puis six en suivant dans le groupe 2 et enfin, 4 dans le groupe 3. L'expression d'une telle requête pourrait prendre la forme :
SELECT ELV_NOM,
NTILE(3) OVER(ORDER BY ELV_NOTE_GYM) AS ELV_GROUPE,
ELV_NOTE_GYM
FROM T_ELEVE_ELV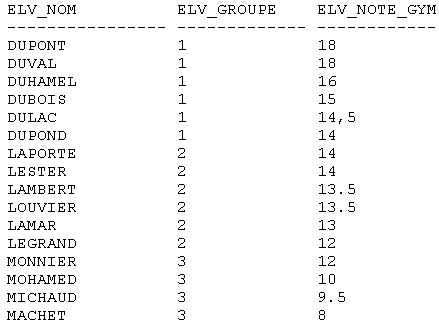
ces fonctions de classement sont des fonctions dîtes de "fenêtrage". Elle ne s'appliquent qu'aux lignes devant être affichées et ne peuvent ni figurer dans une sous requête classique, ni dans une clause WHERE, HAVING, etc... parce qu'elles s'appliquent après que les lignes du résultat aient été construite. Ainsi il n'est pas possible d'utiliser la fonction ROW_NUMBER ou NTILE pour faire directement de la pagination. En revanche, une telle requête peu être ancapsulée en tant que sous requête table dans la clause FROM et servir à différents usages.
Voici un exemple, de pagination dans un jeu de résultats avec deux méthodes différentes.
1) Pagination par bloc de ligne controlé (les lignes retournées sont controlées dans le filtre WHERE) :
SELECT *
FROM (SELECT ROW_NUMBER() OVER(ORDER BY USR_ID) RNUM,
USR_ID, USR_NOM, USR_PRENOM,
FROM T_UTILISATEUR_USR) T
WHERE RNUM BETWEEN 10 AND 19
Ici on retourne les lignes numérotées 10 à 19.
2) Pagination par nombre de page (le nombre de page est fixé, le nombre de ligne inconnu, la page retournée est contrôlée dans le filtre WHERE) :
SELECT *
FROM (SELECT NTILE(25) OVER(ORDER BY USR_ID) NTL,
USR_ID, USR_NOM, USR_PRENOM,
FROM T_UTILISATEUR_USR) T
WHERE NTL = 7
Ici on fixe le nombre de page à 25 et l'on retourne la page 7
Una autre construction plus élégante est possible via la CTE.
II-H. Opérateur PIVOT / UNPIVOT ▲
L'horrible, mais traditionnel opérateur PIVOT, bien qu'absent de la norme SQL fait son apparition dans SQL Server 2005 afin de permettre de réaliser des tableaux croisés. Il s'agit simplement d'une astuce cosmétique pour présenter des données avec de nouvelles colonnes dont les noms sont extraits d'une des colonnes de la requête.
CREATE TABLE T_VENTE_VTE
(VTE_ID INT,
VTE_PERIODE VARCHAR(8),
VTE_ZONE VARCHAR(6),
VTE_CA FLOAT)
INSERT INTO T_VENTE_VTE VALUES (1, 'TR 1', 'Sud', 232534.34)
INSERT INTO T_VENTE_VTE VALUES (2, 'TR 2', 'Sud', 565537.65)
INSERT INTO T_VENTE_VTE VALUES (4, 'TR 3', 'Sud', 254537.89)
INSERT INTO T_VENTE_VTE VALUES (5, 'TR 4', 'Sud', 345564.98)
INSERT INTO T_VENTE_VTE VALUES (6, 'TR 1', 'Nord', 234507.67)
INSERT INTO T_VENTE_VTE VALUES (7, 'TR 3', 'Nord', 787537.88)
INSERT INTO T_VENTE_VTE VALUES (8, 'TR 4', 'Nord', 675455.62)
-- Avant SQL Server 2005 :
SELECT VTE_ZONE, SUM(VTE_CA) AS TRIMESTRE_1,
(SELECT SUM(VTE_CA)
FROM T_VENTE_VTE
WHERE VTE_PERIODE = 'TR 2'
AND VTE_ZONE = VTE.VTE_ZONE) AS TRIMESTRE_2,
(SELECT SUM(VTE_CA)
FROM T_VENTE_VTE
WHERE VTE_PERIODE = 'TR 3'
AND VTE_ZONE = VTE.VTE_ZONE) AS TRIMESTRE_3,
(SELECT SUM(VTE_CA)
FROM T_VENTE_VTE
WHERE VTE_PERIODE = 'TR 4'
AND VTE_ZONE = VTE.VTE_ZONE) AS TRIMESTRE_3
FROM T_VENTE_VTE VTE
WHERE VTE_PERIODE = 'TR 1'
GROUP BY VTE_ZONE
-- Avec SQL Server 2005 :
SELECT VTE_ZONE, SUM([TR 1]) AS TRIMESTRE_1, SUM([TR 2]) AS TRIMESTRE_2,
SUM([TR 3]) AS TRIMESTRE_3, SUM([TR 4]) AS TRIMESTRE_4
FROM T_VENTE_VTE
PIVOT (SUM(VTE_CA) FOR VTE_PERIODE IN ([TR 1], [TR 2], [TR 3], [TR 4]))
AS TRIMESTRE
GROUP BY VTE_ZONE
-- les mêmes résultats sans la cosmétique du tableau croisé :
SELECT VTE_ZONE, VTE_PERIODE, SUM(VTE_CA) AS CA
FROM T_VENTE_VTE VTE
GROUP BY VTE_ZONE, VTE_PERIODESi cette technique permet de réconcilier les afficionados d'Access et des tableaux croisés avec SQL Server, tant mieux. Mais ce "truc" possède de très nombreux inconvénients majeurs :
1) Aucune conformité aux normes SQL et franchement pas standard : la transformation de valeurs en nom de colonnes est une absurdité et le recours aux crochets pour nommer les colonnes provenant des valeurs n'obéit à aucune logique, ni aucun standard si ce n'est les spécificités de MS SQL Server.
2) Même si le plan de requête parait plus simple, il n'est pas certain que l'effort en terme d'E/S soit moindre. En effet l'utilisation d'un tel opérateur empêche en principe l'utilisation des index.
3) Toute opération cosmétique grève énormement les performances d'un serveur SQL parce qu'il n'a pas été prévu pour cela, alors qu'un outil de présentation spécialisement conçu à cet effet pourra donner le même rendu en minimisant les ressources.
4) La clause IN de l'opérateur PIVOT n'a pas été rendue générique. En l'occurrence l'écriture très tentant d'une requête du genre :
PIVOT (SUM(VTE_CA) FOR VTE_PERIODE IN (VTE_PERIODE) AS TRIMESTRE
ou encore :
PIVOT (SUM(VTE_CA) FOR VTE_PERIODE
IN (SELECT DISTINCT VTE_PERIODE FROM T_VENTE_VTE) AS TRIMESTRE
n'est pas possible. Il faut spécifier "en dur" et connaître d'avance les colonnes !
En conclusion : les opérateurs PIVOT / UNPIVOT revêtent peu d'intérêtn et sont à éviter systématiquement pour qui veut des performances.
UNPIVOT est l'opération inverse de PIVOT, mais ne peut reproduire exactement les données initiales du fait du traitement spécifiques des absences de valeurs (marqueurs NULL).
Pour compléter votre information, l'article de Reanaud Harduin sur le sujet.
II-I. Opérateur APPLY ▲
L'opérateur APPLY à pour but d'appliquer une jointure à un ensemble de ligne extrait d'une colonne d'une table et sa table hôte. Mais, me direz-vous, est-il posible de metttre des lignes dans une colonne de table ? Oui, si l'on considère qu'une fonction table peut être appliquée pour une colonne, ou qu'une colonne peut contenir du xml dont l'extraction d'un noeud peut retourner un ensemble de lignes...
Voici un exemple, complet...
La fonction table suivante retourne une table constituée des 7 jours de la semaine contenant la valeur du paramètre DATETIME qu'on lui passe :
CREATE FUNCTION F_WEEKDAYTABLE (@A_DATE DATETIME)
RETURNS @WEEKDAYTABLE TABLE ("DATE" DATETIME primary key,
JOUR VARCHAR(8))
BEGIN
-- obtention de la date avec heure 0
SET @A_DATE = CAST(FLOOR(CAST(@A_DATE AS FLOAT)) AS DATETIME);
-- recherche du lundi
WHILE DATEPART(WEEKDAY, @A_DATE) <> 1
SET @A_DATE = @A_DATE -1
-- insertion des jours de la semaine dans la table
INSERT INTO @WEEKDAYTABLE VALUES (@A_DATE, 'Lundi')
INSERT INTO @WEEKDAYTABLE VALUES (@A_DATE + 1, 'Mardi')
INSERT INTO @WEEKDAYTABLE VALUES (@A_DATE + 2, 'Mercredi')
INSERT INTO @WEEKDAYTABLE VALUES (@A_DATE + 3, 'Jeudi')
INSERT INTO @WEEKDAYTABLE VALUES (@A_DATE + 4, 'Vendredi')
INSERT INTO @WEEKDAYTABLE VALUES (@A_DATE + 5, 'Samedi')
INSERT INTO @WEEKDAYTABLE VALUES (@A_DATE + 6, 'Dimanche')
-- retour
RETURN
END
-- la table suivante contient des factures :
CREATE TABLE T_FACTURE_FCT
(FCT_ID INTEGER NOT NULL PRIMARY KEY,
FCT_DATE DATETIME NOT NULL,
CLI_ID INTEGER NOT NULL)
INSERT INTO T_FACTURE_FCT VALUES (145, '20050718', 33)
INSERT INTO T_FACTURE_FCT VALUES (178, '20050720', 21)
INSERT INTO T_FACTURE_FCT VALUES (213, '20050722', 47)
Les factures doivent être envoyées le jeudi qui suit la date de la facture. Comment exprimer cela à l'aide des éléments ci dessous et obtenir :

SELECT *
FROM T_FACTURE_FCT F
CROSS JOIN dbo.F_WEEKDAYTABLE (F.FCT_DATE) W
WHERE W.JOUR = 'Jeudi'
Se solde par une erreur à la compilation :
Serveur : Msg 170, Niveau 15, État 1, Ligne 3
Ligne 3 : syntaxe incorrecte vers '.'.
En effet on ne peut pas exprimer une colonne d'une table de la clause FROM en paramètre dans une fonction contenue dans cette même clause FROM. Ce qui était impossible sous SQL Server 2000 devient possible en version 2005 : la solution passe par l'un des deux nouveaux opérateurs de jointure CROSS APPLY ou OUTER APPLY...
SELECT FCT_ID, FCT_DATE, CLI_ID,
CASE
WHEN FCT_DATE > W.DATE THEN WW.DATE
ELSE W.DATE
END AS DATE_ENVOI
FROM T_FACTURE_FCT F
CROSS APPLY dbo.F_WEEKDAYTABLE (F.FCT_DATE) W
CROSS APPLY dbo.F_WEEKDAYTABLE (F.FCT_DATE + 7) WW
WHERE W.JOUR = 'Jeudi'
AND WW.JOUR = 'Jeudi'
MS SQL Server dispose donc de deux opérateurs APPLY : CROSS APPLY pour un produit cartésien et OUTER APPLY pour une jointure externe.
II-J. Clause OUTPUT▲
Voici une clause intéressante pour les ordres SQL de mise à jour. Elle permet de tout connaître de ce qui s'est passé dans un tel ordre (INSERT, UPDATE, DELETE). Son principe consiste à répercuter les informations d'ajouts, modifications ou suppressions dans une table de votre choix. Voici un exemple d'utilisation d'une telle clause.
-- création d'une table de trace pour pister les modifications
CREATE TABLE T_TRACE_TRC
(TRC_ID INTEGER IDENTITY NOT NULL PRIMARY KEY,
TRC_DATEHEURE DATETIME DEFAULT CURRENT_TIMESTAMP,
TRC_TABLE NVARCHAR(128),
TRC_CLEF INTEGER,
TRC_DATA NVARCHAR(256),
TRC_HOST_NAME NVARCHAR(128),
TRC_PROGRAM_NAME NVARCHAR(128),
TRC_NT_USER_NAME NVARCHAR(128),
TRC_NET_ADDRESS NCHAR(12),
TRC_LOGIN_NAME NVARCHAR(128))
-- ordre DELETE avec clause OUTPUT :
DELETE FROM T_CHAMBRE_CHB
OUTPUT CURRENT_TIMESTAMP,
'T_CHAMBRE_CHB',
deleted.CHB_ID,
'CHB_NUM = ' + CAST(deleted.CHB_NUM AS VARCHAR(16)) +
', CHB_COUCHAGE = '+CAST(deleted.CHB_COUCHAGE AS VARCHAR(16)),
p.host_name,
p.program_name,
p.nt_user_name,
p.net_address,
p.login_name
INTO T_TRACE_TRC
FROM T_CHAMBRE_CHB CHB
CROSS JOIN master.dbo.sysprocesses p
WHERE CHB.CHB_COUCHAGE >= 5
AND p.spid = @@spid
Dans cet exemple nous faisons une jointure croisée avec la tables des processus pour le processus en cours afin de rapatrier les informations de l'utilisateur, du programme et du noeud réseau sur lequel il travaille afin d'alimenter la table de trace avec ces informations, comme avec les informations concernant les éléments supprimés. Notez la présence de la pseudo table deleted qui contient les lignes en cours de suppression, comme dans le cadre d'un trigger. De même la table inserted est disponible dans la clause OUTPUT.
Dans sa première version, la clause OUTPUT ne pouvait alimenter qu'une variable de type table devant être préalablement déclarée. Il a été annoncé que cette clause OUTPUT pourrait alimenter une table persistante quelconque. C'est ce que nous avons fait dans notre exemple. Néanmoins nous n'avons pas constaté dans le béta 3 cette évolution.
II-K. Amélioration et extension de la clause TOP ▲
Une des critiques souvent faite sur cette clause qui permet de limiter le nombre de lignes retournées est qu'elle n'était pas paramétrable. C'est désormais chose faite. On peut mettre dans TOP une variable comme une sous requête. Voici un exemple qui permet de retourner la moitié des lignes d'une table :
SELECT TOP(SELECT COUNT(*) / 2
FROM T_CHAMBRE)
*
FROM T_CHAMBRE
Il est maintenant possible d'utiliser la clause TOP dans les autres ordres SQL du DDL : INSERT, UPDATE, DELETE. Cela peut être très intéressant pour découper en plusieurs lots une requête qui écrit des données et donc minimiser le volume des transactions.
WHILE EXISTS (SELECT *
FROM T_CLIENT
WHERE CLI_NOM <> UPPER(CLI_NOM))
UPDATE T_CLIENT
TOP 400
SET CLI_NOM = UPPER(CLI_NOM)
Dans cette requête, on met en majuscules le nom des clients par paquet de 400 tant qu'il existe des noms de client qui ne l'ont pas encore été.
Autrefois, il fallait recourrir pour ce faire à l'indicateur ROWCOUNT. Microsoft annonce que celle-ci ne sera plus supportée dans les versions futures de SQL Server.
II-L. Échantillon de table (TABLE SAMPLE)▲
Cette nouvelle clause permet de retourner un échantillon de lignes de la table plutôt que de retourner toutes les lignes. Cette clause complète un peu la clause TOP, avec un avantage, les lignes sont retournées dans des pages de la table prises au hasard, alors que TOP implique un classement ce qui implique donc échantillon organisé donc peu représentatif.
Il est même prévu que la méthode d'échantillonnement puisse être choisie, voire d'implémenter sa propre méthode.
TABLESAMPLE [SYSTEM] (nombre [ PERCENT | ROWS ] ) [ REPEATABLE (graine) ]
Exemple :
SELECT *
FROM T_FACTURE TABLESAMPLE (2 PERCENT)
Dans le cas ou l'on désire obtenir toujours le même jeu de lignes dans l'échantillon, on peut proposer une valeur numérique arbitraire pour la valeur graine. Dès lors, avec l'utilisation de cette même valeur, l'échantillon de pages retournées sera le même à chaque exécution, à condition que les pages n'aient pas été réorganisées (DBCC INDEXDEFRAG par exemple).
SELECT *
FROM T_FACTURE TABLESAMPLE (2 PERCENT) REPEATABLE 12345Comme TABLESAMPLE fonctionne sur des pages et non des lignes, le nombre de ligne est approximatif et dépend du nombre de ligne par page. Ceci peut être pénalisant dans de petite tables ou TABLESAMPLE peut ne rien renvoyer dans le cas d'un 40% par exemple si la totalité des lignes est contenue dans une page. Conséquence : TABLESAMPLE n'a d'intérêt que pour des tables volumineuses (plusieurs centaines de pages...).
II-M. Schéma SQL (norme SQL:1992)▲
La notion de schéma SQL a été améliorée (elle se trouve maintenant proche de la norme SQL2) et il est désormais possible de créer dans une même base différents schémas sans passer obligatoirement par un nouvel utilisateur. Cela revient à dire qu'un objet n'appartient plus directement à un utilisateur, mais à un schéma. En outre différents utilisateurs peuvent ajouter, modifier ou retirer des objets du schéma pourvu qu'ils en aient acquis les privilèges.
II-N. Sécurité▲
La sécurité à été grandement améliorée : des pseudo ordre SQL sont disponibles là ou des procédures complexes et absconces devaient être employées. Ainsi on trouve les ordres Transact SQL :
CREATE USER ... WITH DEFAULT_SCHEMA ...
CREATE LOGIN ...
GRANT ... ON SCHEMA ... TO ...
Comme nous l'avons déjà dit, la notion d'utilisateur SQL devient indépendante du schéma.
Un accès au serveur peut être formé avec un certificat (CERTIFICATE ou CREDENTIAL) ou une clef de chiffrement asymétrique. Cette technique est notamment requise pour authentifier certains processus notamment dans le cadre de l'utilisation des web services intégrés à MS SQL Server et par conséquent faire dialoguer des Serveurs SQL à travers le Web
Enfin, il est possible de caler la politique de gestion des mots de passe ("password policies") sur celle de Windows Server.,
Notons que la gestion des privilèges (GRANT, REVOKE) a été entièrement revue afin de gérer tous les nouveaux objets de SQL Server 2005. Ce qui existait sous SQL Server 2000 reste, bien entendu compatible. Les privilèges sont imbriqués de manière hiérarchique.
II-O. Vues systèmes▲
Microsoft utilise les nouvelles possibilités de schéma au sein des bases de données de SQL Server 2005 en ajoutant systématiquement à toute base de données créée un schéma de nom "sys" regroupant les vues systèmes interne à SQL Server.
Par exemple, la vue sys.database_files remplace avantageusement la table sysfiles :
- elle contient plus d'information que sysfiles
- les informations contenues sont plus claires
- les vues sont plus facile à sécuriser
Si vous devez recourrir aux informations systèmes, préférez dans l'ordre :
- les vues normatives (SQL2) d'information de schéma (INFORMATION_SCHEMA.TABLE par exemple)
- les vues systèmes (sys.objects par exemple)
- les procédures spécialisées (sp_help par exemple)et en dernier recours
- les tables systèmes (sysobjects par exemple)
En effet, seules les vues et les procédures sont compatibles d'une version à l'autre et les vues normatives sont à préférer pour des raisons de compatibilité.
II-P. Conclusion▲
Même s'il reste des efforts à faire du côté de SQL, tel que l'implémentation des types DATE et TIME (possible avec CLR), du type ROW ou ARRAY (ces derniers étant simulable par du xml) et qu'il manque encore certaines constructions SQL telle que le Row Value Constructor, le concept d'assertion ou encore les prédicats UNIQUE, DISTINCT ou MATCH, force est de constater que le SQL de MS SQL Server 2005 est d'un niveau élevé et largement suffisant pour la très grande majorité des développements.