






I. L’auteur▲
|
|
Blog : |

II. Introduction▲
MySQL/MariaDB a été créé en mode « quick and dirty » par un développeur suédois de nom Michael Widenius. Ce qui en a fait son succès c’est que ce produit – considéré à l’époque comme l’un des plus mauvais de sa catégorie – a été donné gratuitement par son créateur. Brillante idée !
En l'intégrant dans toutes les distributions Linux (le fameux LAMP : Linux, Apache, MySQL, PHP), ce bon commercial réussit à l’imposer à tous ceux qui rêvaient de développer leur petit site web dynamique. La prolétarisation de l’univers informatique avançant à grands pas, les amateurs ont profité de l’occasion pour monter leurs petites solutions personnelles.
Le nom n’a d’ailleurs pas été choisi au hasard. MySQL ne signifie-t-il pas que c’est « mon petit business », loin des nécessités professionnelles d’une entreprise ?
Aussi surprenant que cela puisse paraître, l’un des principes fondamentaux de MySQL/MariaDB est d’essayer de ne jamais lever d’exception, même si les commandes lancées sont syntaxiquement incorrectes ou que les données renvoyées sont fausses.
Dans l’entreprise, du fait de MySQL, nombreuses sont les applications aux données fausses, mais rarement vérifiées.
Qui aujourd’hui effectue des POC (1) , des benchmarks (2) , des preuves de résultats, bref des tests sérieux pour vérifier la fiabilité de la solution, l’intégrité des données et la protection des informations ?
Cet article a donc pour but de vous démontrer que MySQL/MariaDB n’est pas compatible avec la sûreté, la qualité et les performances attendues par l’entreprise. Il en est même dangereux !
Une anecdote en passant…
Pour information, la collation(3) par défaut des serveurs et des bases de données dans MySQL est « latin1_swedish_ci » ! Beaucoup de développeurs n'ont pas remarqué cela et laissent en production cette collation qui peut s'avérer une bombe à retardement en matière de gestion des données accentuées, car le jeu de caractères accentués de la langue suédoise n'est pas compatible avec les principaux accents du français.
III. MySQL/MariaDB, un SGBD non relationnel▲
En 1985, compte tenu du succès naissant du modèle relationnel, Franck Edgar Codd, l’inventeur des SGBDR, excédé par l’appellation « relationnel » de tout un tas de produits qui ne le sont pas, édicte 12 règles pour confirmer si un SGBD est relationnel ou pas.
Un exemple tiré de la règle n°7(4) de Codd, indique que « toute mise à jour de données doit être faite de manière ensembliste ». Ce qui revient à dire que le traitement de modification des données doit être fait globalement : toutes les informations doivent être manipulées de manière simultanée et non de manière itérative (pas de ligne à ligne) contrairement à ce que ferait, hélas, un programme applicatif.
C'est le point clef des SGBD relationnels. Or MySQL/MariaDB fonctionne de manière itérative et non de manière ensembliste.
Démonstration
CREATE TABLE T (C INT UNIQUE);
INSERT INTO T VALUES (1), (2), (3);
UPDATE T SET C = C + 1;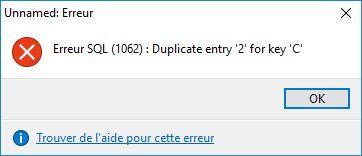
Bien évidemment cette dernière requête ne pose aucun problème sur des SGBD réellement relationnels comme IBM DB2, Oracle Database ou Microsoft SQL Server.
Imaginez le jour où vous aurez besoin de rectifier des numéros de facture, parce que le système informatique étant tombé en panne, on a édité des factures à la main.
IV. Les dangers de l’absence d’un catalogue « système »▲
À l’exception de MySQL/MariaDB, tous les SGBD relationnels, PostGreSQL compris, disposent d’un catalogue(5) tel que le prévoit la règle n°4 de Codd, c’est-à-dire des tables système contenant les métadonnées de la base, et transactionnées de la même manière que les tables « utilisateur ». La nécessité d’une telle organisation tient au respect de l’intégrité d’une base. Or MySQL/MariaDB est dans l’incapacité de garantir une telle intégrité. Les conséquences de cette absence sont extrêmement dangereuses ! Démonstrations…
IV-A. Disparition des objets de la base▲
Cette absence de catalogue système à de fâcheuses multiples conséquences dont l’une des pires est de permettre de perdre des objets de la base (des tables en particulier) sans que vous n’en soyez jamais informé !
La démonstration est d’une rare simplicité.
Créez une table et remplissez-la de quelques lignes. Par exemple :
CREATE TABLE ZZZ (C INT);
INSERT INTO ZZZ VALUES (1), (2), (3);Allez maintenant dans le répertoire de stockage de votre base, par exemple, par défaut, pour MariaDB sous Windows c’est : C:\Program Files\MariaDB 10.3\data.
Vous y trouverez les répertoires des bases, sachant que pour MariaDB/MySQL, une base c’est avant tout un répertoire.
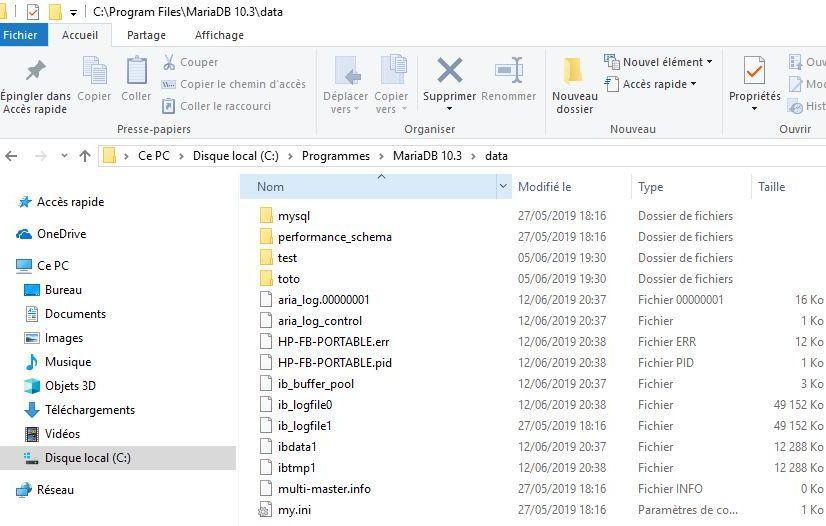
Allez dans le répertoire de la base considérée et supprimez tous les fichiers concernant la table ZZZ (il y en a au moins deux).
Vous avez maintenant flingué votre base.
Redémarrez maintenant le service de votre serveur MySQL/MariaDB :
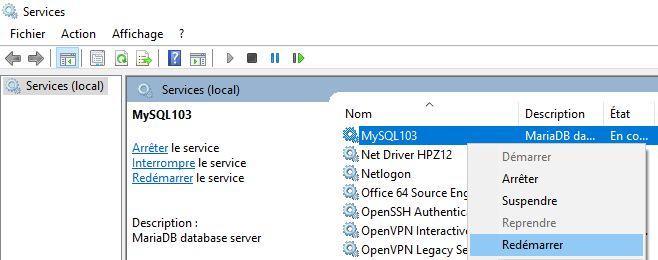
et tapez la requête suivante pour avoir la liste des tables de votre base : SHOW TABLES;
Vous constatez que vous avez perdu votre table et MySQL/MariaDB n’en sait rien !
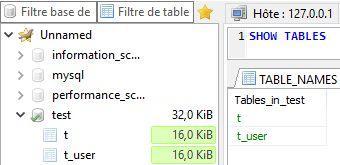
Bien évidemment aucun autre SGBDR à ma connaissance n’a un comportement aussi stupide. Tous, à l’exception de MariaDB/MySQL, ayant des tables système, la perte potentielle d’une table est immédiatement perçue du fait que la liste des tables (et de tous les autres objets de la base), contenue dans une table système, est en décalage avec le stockage.
Mais dans MySQL/MariaDB, le catalogue n’existant pas, MySQL/MariaDB, lit le répertoire susceptible de contenir les tables pour les lister ! Bref, vous n’avez aucun moyen de savoir quelles sont les tables perdues lors du crash d’un disque par exemple, ni, bien évidemment si l’on vous vole des fichiers de la base.
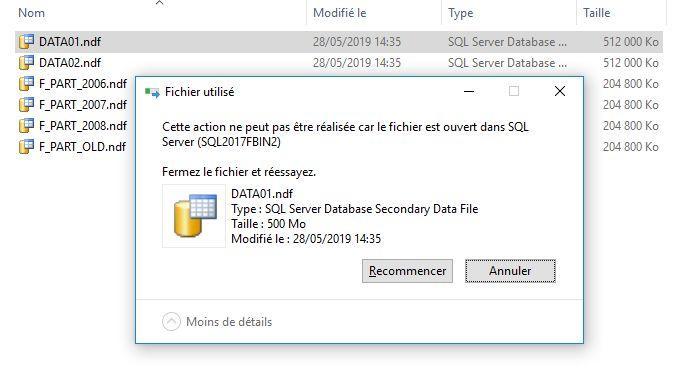
Dans certains SGBDR, les fichiers de la base sont tellement sécurisés, qu’il n’est même pas possible d’en déplacer le stockage, supprimer des tables ou copier les fichiers.
C’est le cas, en particulier, de Microsoft SQL Server où le système va interdire une telle manipulation.
Démonstration
IV-B. Validation automatique et involontaire des transactions▲
Cette absence de table système constituant le catalogue exigé par Codd, contraint MySQL/MariaDB à valider automatiquement toutes les transactions de tous les utilisateurs sans leur demander leur avis dans certaines circonstances. Imaginez un peu que vous soyez en train de simuler des positions bancaires et que, tout d’un coup, toutes les données que vous avez savamment modifiées, pour voir ce qui pouvait arriver dans votre simulation, se trouvent définitivement fixées sans aucun retour en arrière possible ! Incroyable non ?
C’est pourtant ce qui arrive si quelqu’un modifie la structure de la base de données pendant que vous avez démarré une transaction que vous n’avez pas encore terminée.
Démonstration
Ouvrez une fenêtre de requête et tapez les commandes suivantes :
START TRANSACTION;
INSERT INTO T VALUES (999);Ouvrez maintenant une seconde fenêtre et tapez la requête suivante :
CREATE TABLE TT (C DATE).
Revenez maintenant dans la première fenêtre et lancez la commande : ROLLBACK;.
Vous constaterez que malgré l’annulation de la transaction, la valeur 999 figure bien dans la table T !
Non seulement la transaction a été validée sans votre accord, mais la commande ROLLBACK n’a pas émis d’exception alors que la transaction n’existe plus.
En fait, dès la moindre commande du DDL (Data Définition Language – c’est-à-dire CREATE, ALTER, DROP.), MariaDB/MySQL valide toutes les transactions de tous les utilisateurs.
Aucun autre SGBD relationnel digne de ce nom (MySQL/MariaDB en étant indigne comme déjà indiqué) ne flinguerait à ce point l’intégrité de vos données.
Dans le même genre d’horreur, il est à noter que MySQL/MariaDB ne sait pas gérer les transactions imbriquées, mais les laisse exister et se lancer, produisant des résultats hasardeux. N’oubliez pas que l’un des principes de MySQL/MariaDB est de ne rien vérifier ni lever d’exception.
V. Schéma SQL – MySQL/MariaDB ment !▲
MySQL/MariaDB n'implémente pas la notion de schéma SQL propre à la norme du langage. Le discours est de faire croire que cela existe en répondant que c'est la même chose que de créer plusieurs bases de données, ce qui est absolument faux, car il est impossible d'utiliser une sécurité transversale entre deux bases, comme il est impossible de mettre en œuvre une intégrité référentielle déclarative entre deux bases.
En sus, du fait que les bases sont logiquement et physiquement indépendantes, il n'est pas possible de garantir qu’à la restauration les différentes bases auront un point de cohérence.
Les avantages de travailler avec différents schémas SQL sont considérables. La présence de différents schémas dans une même base permet d’isoler les données par affinité fonctionnelle ou technique et de permettre de gérer différents filtres d’accès au niveau du schéma. Par exemple, dans les ERP, il est courant de créer un schéma par unité fonctionnelle (vente, production, comptabilité, ressources humaines, marketing) et des schémas transverses pour l’administration ou les référentiels (historisation des mises à jour, référentiel géographique).
Il devient alors extrêmement simple et particulièrement efficace de gérer la sécurité en autorisant tel ou tel utilisateur à ne pouvoir lire que tel ou tel schéma, et écrire dans tel ou tel autre, pilotant une fois pour toutes la sécurité, quelles que soient les évolutions de la base (ajout de nouvelles tables, procédures, vues). Sans l’atout que présente la gestion des schémas SQL dans une base, il faudra sans cesse se poser la question de sécuriser chaque nouvel objet pour chaque utilisateur à chaque évolution de la base. Une problématique fastidieuse, qui finira par briser la mise en place de la sécurité et qui se traduira vite comme une passoire dans MySQL/MariaDB.
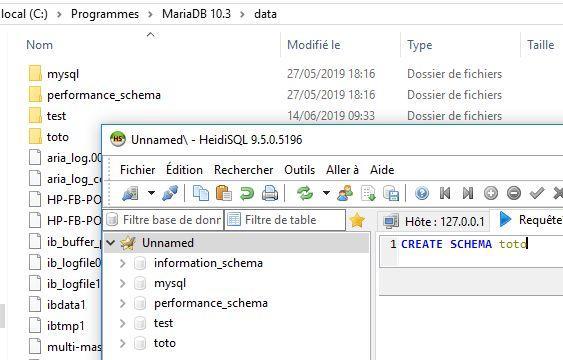
Mais le pire est que MySQL/MariaDB ment !
En effet, il vous est possible de lancer une telle commande : CREATE SCHEMA toto;
Comment cela est-il possible ? Tout simplement parce que MySQL ment ! En effet, il ne crée pas un schéma SQL, mais une nouvelle base de données et donc un nouvel espace de stockage indépendant.
Et maintenant, que le spectacle commence…
2.
3.
4.
5.
6.
CREATE TABLE test.T_CLI
(CLI_ID INT PRIMARY KEY);
CREATE TABLE toto.T_FAC
(FAC_ID INT PRIMARY KEY,
CLI_ID INT REFERENCES test.T_CLI (CLI_ID));
Voici deux tables l’une devant contenir des clients, créée dans la base (? le schéma ? test), l’autre devant contenir les factures dans la base (? le schéma ? toto) et liée par l’intégrité référentielle avec la précédente.
Insérons une ligne dans la table des factures : INSERT INTO toto.T_FAC VALUES (1, 1);
Pas de message d’erreur, alors que le client n°1 n’existe pas.
SELECT * FROM toto.T_FAC;
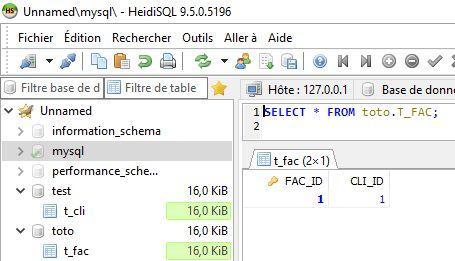
Oui l’intégrité d’une base est une notion inconnue de MySQL/MariaDB !
VI. Calculs faux▲
SQL est un langage normalisé et fortement typé. Les calculs doivent s’effectuer en fonction du type de données passées dans les opérandes des expressions de calcul. Si tous les types sont d’une même famille, alors, le type renvoyé doit l’être aussi. Par exemple, si vous effectuez des calculs avec des nombres entiers, alors le résultat doit être un nombre entier.
Mais pas pour MySQL/MariaDB !
Démonstration :
SELECT 3/2 doit donner 1. MySQL/MariaDB renvoie 1.5 !
Ceci serait anecdotique, si certains calculs issus d’expressions de comptages statistiques n’étaient pas, quelquefois, utilisés en tant que sous-requête d’une requête principale donnant ainsi des résultats faux.
Quant à certaines autres requêtes qui doivent effectivement renvoyer une erreur, comme nous l’avons dit, MySQL/MariaDB ignore certaines erreurs et renvoie des résultats alors que la requête devrait être immédiatement interrompue.
Voici un petit festival de démonstration :
2.
3.
4.
5.
6.
7.
SELECT 1/0;
SELECT LOG(0);
SELECT ACOS(2345678);
SELECT SQRT(-1)
Toutes ces requêtes renvoient NULL alors qu’elles devraient renvoyer une erreur.
Voici ce que fait SQL Server en comparaison :
Msg 8134, Niveau 16, État 1, Ligne 1
Division par zéro.
Pour la première et :
Msg 3623, Niveau 16, État 1, Ligne 7
Une opération en virgule flottante non valide s'est produite.
pour les autres.
Alors oui, les aficionados de MySQL/MariaDB vont me rétorquer qu’il existe un « strict mode » pour paramétrer l’exécution des requêtes afin qu’elles produisent enfin des résultats sensés. Mais les développeurs sont-ils au courant ? Appliquent-ils réellement ce mode dans les bases de données d’entreprises gérées par MySQL/MariaDB ?
Et une fois ce mode « lâche » mis en place dans une application qui est utilisée par de nombreux clients, l’éditeur aurait-il le courage de se tirer une balle dans le pied en activant un mode strict, capable de faire dérailler presque toutes ses requêtes ?
Et quelles sont les performances une fois ce mode activé ? Je vous laisse en juger par vous-même et peut-être serez stupéfait !
Malheureusement les réglages à ce niveau sont extrêmement confus, peu documentés et sujets à caution.
Pour information, mes réglages au cours de l’exécution des requêtes étaient les suivants :
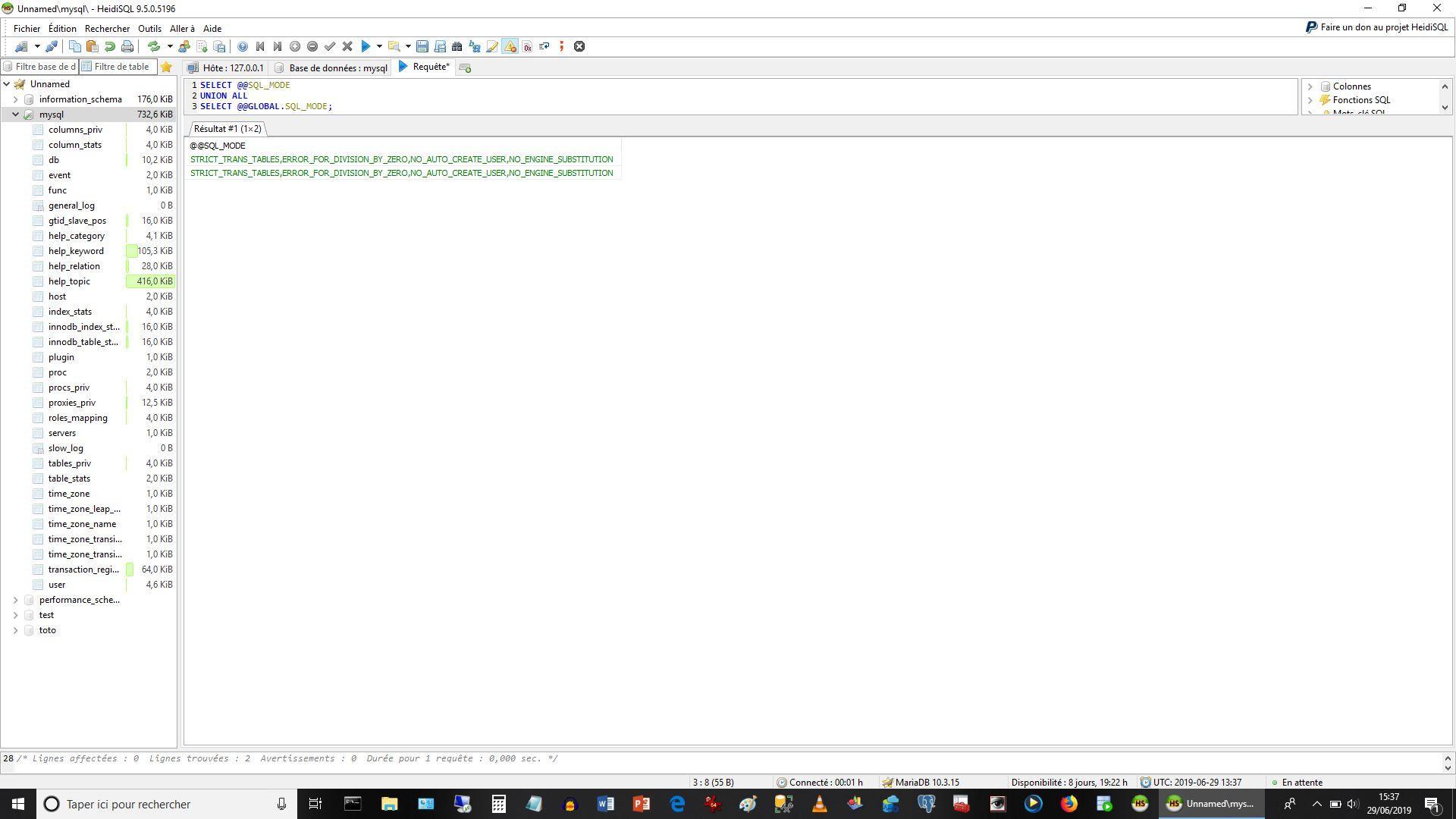
Me laissant entendre qu’il allait crier lors de la division par zéro, ce qui ne s’est pas passé.
MySQL/MariaDB mentirait-il encore ?
VII. Statistiques fausses▲
Dans le principe, la norme sur le langage SQL précise que, pour les opérations de regroupement inhérentes aux calculs d’agrégation (SUM, COUNT, MAX), la clause GROUP BY doit répondre aux spécifications suivantes :
- toute colonne présente dans la clause SELECT doit figurer dans la clause GROUP BY à l’exception des colonnes figurant dans les calculs d’agrégation ;
- le résultat de l’application de la clause GROUP BY combiné à des calculs d’agrégation doit produire une seule ligne avec une seule valeur par groupe.
MySQL/MariaDB a la fâcheuse tendance à renvoyer n’importe quoi sans jamais émettre d’erreur dans le cas où la clause GROUP BY est incomplète, donnant des résultats hasardeux presque toujours faux !
Démonstration.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
CREATE TABLE T_COURS
(COURS_NOM VARCHAR(16),
COURS_ELEVE VARCHAR(32),
COURS_TRIMESTRE INT,
COURS_NOTE INT);
INSERT INTO T_COURS VALUES
('math', 'Paul', 1, 10),
('math', 'Paul', 2, 11),
('math', 'Paul', 3, 12),
('math', 'Marc', 1, 8),
('math', 'Marc', 2, 10),
('math', 'Marc', 3, 15),
('français', 'Paul', 1, 10),
('français', 'Paul', 2, 12),
('français', 'Paul', 3, 14),
('français', 'Marc', 1, 12),
('français', 'Marc', 3, 18);
La requête suivante :
2.
3.
SELECT COURS_NOM, COURS_ELEVE, AVG(COURS_NOTE) AS MOYENNE
FROM T_COURS
GROUP BY COURS_ELEVE;
Est syntaxiquement fausse, car la clause GROUP BY ne contient pas toutes les colonnes exprimées dans le SELECT.
Tout SGBD Relationnel bien constitué, aurait renvoyé une erreur, comme celle générée par Microsoft SQL Server :
Msg 8120, Niveau 16, État 1, Ligne 20
La colonne 'T_COURS.COURS_NOM' n'est pas valide dans la liste de sélection parce qu'elle n'est pas contenue dans une fonction d'agrégation ou dans la clause GROUP BY.
MySQL/MariaDB exécute avec brio cette requête imbécile donnant un résultat inexploitable :
|
COURS_NOM |
COURS_ELEVE |
MOYENNE |
|---|---|---|
|
math |
Marc |
12,6000 |
|
math |
Paul |
11,5000 |
Passons sur le fait que MariaDB/MySQL ne respecte toujours pas les types de données (les résultats auraient dû être des entiers et non des réels donc, 12 et 11 et non 12,6 et 11,5), mais constatons que Marc est très content de voir que sa moyenne en math est passée à 12,5 alors qu’elle n’est que de 11 !
VIII. Limitations sur les collations (norme SQL)▲
La norme SQL a introduit la notion de collation afin de faciliter l’exploitation sémantique des données littérales. Cette exploitation doit pouvoir se faire, à tout moment (par exemple à la volée dans une requête SELECT) et dans toutes circonstances (dans le stockage des données, comme dans l’évaluation d’une contrainte) avec les paramètres suivants :
- CI (Case Insensitive) : insensible à la casse (confusion des majuscules et minuscules) ;
- CS (Case Sensitive) : sensible à la casse (distinction entre majuscules et minuscules) ;
- AI (Accent Insensitive) : insensible aux caractères diacritiques (confusion des lettres accentuées, cédilles, ligatures avec les lettres « nues ») ;
- WS (Wide Sensitive) : distinction de la « largeur » du pas du caractère (pour certains caractères disposant de différences scripturales comme les caractères 2 et ²) ;
- KS (Kanatype Sensitive) : distinction des deux formes d’écriture du japonais (katakana et hiragana) ;
- BINARY : sensible à tout.
Les collations devant être indépendantes de tout jeu de caractères.
Malheureusement MySQL/MariaDB ne supporte que très partiellement la notion de collation. On note :
- un faible nombre de collations, dépendant systématiquement du jeu de caractères (332, c’est peu comparé aux 3955 de Microsoft SQL Server) ;
- des collations avec très peu de paramétrage, presque uniquement basé sur la casse. Exemple : collation latine, uniquement en deux versions CS ou CI ;
- pas de possibilité de collation insensible aux accents (ni aux caractères diacritiques : cédille, ligature.) ;
- pas de collation sensible à la largeur de pas (WS) ;
- pas de distinction des kanatypes du japonais (KS) ;
- des collations strictement dépendantes des jeux de caractères et donc limitées à ce que les jeux de caractères sont susceptibles de proposer en la matière.
Ceci rend inexploitables ou très contre performantes certaines requêtes. Par exemple une recherche sans tenir compte des accents, nécessitera de désaccentuer un par un les caractères des données stockées dans les tables conduisant à des requêtes particulièrement inefficaces en dépit même de la pose d’index, qui seront ignorés dans un tel cas de figure.
On pourra obtenir des informations sur les collations utilisées et utilisables par le biais de ces trois requêtes :
2.
3.
SELECT @@collation_server AS SERVER_COLLATION;
SELECT @@collation_database AS DATABASE_COLATION;
SHOW COLLATION
Pour ce qui est des tables, il est possible de savoir les collations de chaque colonne
SELECT * FROM INFORMATION_SCHEMA.COLUMNS; .
Vous noterez au passage que les données retournées par MySQL/MariaDB sont fausses. En effet, la colonne TABLE_SCHEMA présente le nom de la base qui aurait dû figurer dans la colonne TABLE_CATALOG (la norme SQL considérant la notion de « CATALOG » comme étant une base de données).
Encore un vilain mensonge.
IX. UTF8 et problématiques d’indexation▲
Compte tenu de son utilisation (site web principalement) MySQL/MariaDB a délibérément choisi d’axer son encodage sur l’UTF8. Or cet encodage est la pire des plaies pour les sites web en dehors de ceux s'exprimant uniquement en langue anglaise (les Américains ayant tendance à tirer la couverture à eux afin de dominer le monde). En effet, cet encodage améliore les performances des langues ne disposant pas d’accents et autres caractères diacritiques (donc essentiellement l’anglais) au détriment des langues latines accentuées ou pire encore des langues non indo-européennes, c’est-à-dire celles qui ne sont pas basées sur le latin, le grec ou le cyrillique.
Cet encodage à « pas » variable est le suivant :
les lettres latines non accentuées sont codées sur 7 bits (il y en a donc 128), le 8e bit assurant la distinction entre ce premier groupe et les suivants comme suit :
- si le 8e bit est à zéro, nous sommes sur une lettre encodée sur 1 octet,
- si le 8e bit est à un, nous sommes sur une lettre encodée sur plus d’un octet ;
les lettres latines accentuées et les alphabets grec et cyrillique sont encodés sur 15 bits (il y en a donc 32 640 possibilités), le 16e bit assurant la distinction entre ce second groupe et les suivants comme suit :
- si le 8e bit est à un et le 16e bit est à zéro, nous sommes sur une lettre encodée sur deux octets,
- si le 8e bit est à un et le 16e bit est a un, nous sommes sur une lettre encodée sur plus de deux octets ;
les lettres des langues non indo-européennes (arabe, hébreu, chinois, japonais) sont encodées sur 23 bits (il y en a donc 8 355 968 caractères potentiels) ce qui est largement suffisant en l’état actuel des connaissances sur les langues vivantes.
Par rapport à l’ASCII, les langues européennes accentuées sont donc défavorisées parce qu’elles passent à plus d’un octet par caractère pour tous les caractères diacritiques.
Par rapport à l’UNICODE, les langues non indo-européennes sont aussi défavorisées parce qu’elles passent à trois octets par caractères au lieu de deux.
Mais le pire est dans la manipulation des données dans les bases MySQL. En effet, l’un des points clefs des opérations dans les SGBD relationnels est de pouvoir comparer, trier, regrouper les données de la manière la plus rapide qui soit. Or un encodage à pas variable (tantôt ma lettre est codée sur un octet, tantôt sur deux, voire sur trois) rend inopérants la plupart des algorithmes de tri, de comparaison et de classement.
Mais alors que fait MySQL/MariaDB ? Il encode tous les littéraux sur trois octets pour se simplifier la vie. Autrement dit, grâce à MySQL/MariaDB, vos bases sont trois fois plus grosses qu'elles ne devraient avec des conséquences catastrophiques :
- les performances sont trois fois plus lentes pour tous les accès par balayage des tables ou index (ce n’est pas grave, vous n’avez qu’à acheter des CPU plus rapides) ;
- la mémoire cache est trois fois plus encombrée par le fait de cet encodage (ce n’est pas grave, vous n’avez qu’à acheter trois fois plus de RAM) ;
- l’empreinte mémoire de certaines opérations (GROUP BY, DISTINCT, ORDER BY.) va pomper trois fois plus de RAM (ce n’est pas grave, vous n’avez qu’à acheter encore beaucoup plus de RAM).
Et certaines opérations vont devenir grotesques.
En effet, la limite de longueur d’une clef d’index est par défaut de 767 bytes soit moins de 256 caractères ! Ce n’est pas beaucoup quand on voit les tables obèses que les développeurs pondent. Mais heureusement il y a un contournement possible. Il suffit d’activer le paramètre innodb_large_prefix pour passer subitement à 3072 octets pour votre clef d’index, soit 1024 caractères possibles. Mais ce que l’on oublie de vous dire, c’est que dans ce cas il vous faut activer le mode « dynamic row format » qui déporte ces informations en dehors de la page (bonjour les accès) ou le mode « compressed row format » (bonjour l’allongement de durée des transactions).
Bref, si vous hésitez entre la peste, le choléra et la syphilis, choisissez les trois !
X. Sauvegarde non consistante▲
La façon dont MySQL/MariaDB réalise ses sauvegardes est triviale et possède plusieurs inconvénients. Pour effectuer une sauvegarde, MySQL réalise un rétro script de l’ensemble des commandes SQL du DDL (CREATE, ALTER) suivi de commandes INSERT pour alimenter les données des tables.
Ce genre de méthode appelée « dump » n’a pas grand-chose à voir avec une sauvegarde.
Dans les SGBD relationnels modernes, la sauvegarde consiste à copier les binaires des pages de données (les données des tables étant organisées par page(6) dans des fichiers), puis la portion du journal de transaction pendant laquelle la sauvegarde a été effectuée afin de capturer l’activité qui a eu lieu pendant la sauvegarde. Lors de la restauration, les fichiers de la base sont recréés en recopiant les pages de la sauvegarde vers le disque, puis, les transactions qui ont eu lieu au cours de la sauvegarde sont rejouées et la base ainsi restaurée contient toutes les données au moment de l’achèvement de la sauvegarde, et se trouve restaurée de manière parfaitement intègre.
Ceci n’est pas le cas dans MySQL/MariaDB. En effet, une sauvegarde MySQL/MariaDB ne peut garantir l’intégrité de la base. Ceci est lié encore une fois au fait que MySQL/MariaDB ne possède pas de catalogue système listant les objets de la base.
Le processus utilisé consiste à scruter le répertoire où est stocké la base, et, fichier par fichier extraire les données. Entretemps, des utilisateurs peuvent alimenter les tables. Et c’est là que le bât blesse ! En effet, rien n’empêche une séquence de traitement comme la suivante :
- La sauvegarde copie les lignes de la table des clients ;
- Un utilisateur ajoute un nouveau client et une facture associée à ce nouveau client ;
- La sauvegarde copie les lignes de la table des factures.
À la restauration, on se retrouve avec une base contenant une facture sans client.
À priori donc, la sauvegarde MySQL/MariaDB ne permet pas de conserver l’intégrité des données de la base. Mais il y a cependant un moyen. Activer le mode « lock-tables », ce qui place la base de données en niveau d’isolation REPEATABLE READ et démarre une longue transaction.
Le problème est que ce mode verrouille petit à petit toutes les tables de la base au cours de la sauvegarde. Petit à petit plus aucun utilisateur ne pourra alimenter la base. De plus, nous avons vu que, lors du passage d’une commande de type DDL (CREATE, ALTER, DROP), toutes les transactions étaient immédiatement et sans préavis validées. Dans un tel cas, la transaction de la sauvegarde est finalisée, et vous vous retrouvez avec une base potentiellement inconsistante. Et cela peut-être par le simple fait de la création d’une table temporaire dans une procédure stockée !
En fait, MySQL/MariaDB ne sait pas garantir la consistance des sauvegardes à chaud. Le seul moyen pour ce faire est d’arrêter le service des données et effectuer la sauvegarde.
De plus, la génération d’un « dump » est un processus chronophage. Mieux vaut donc copier les fichiers du répertoire, cela va plus vite.
Il existe cependant des outils payants (la version Enterprise d’Oracle MySQL) capables de mieux gérer les sauvegardes. Il faudra donc migrer vos données et payer ! Parfois le gratuit coûte cher.
XI. Un chiffrement passoire▲
Tous les SGBD prétendent faire du chiffrement. Mais lorsque l’on examine à la loupe ce qui est fait et comment cela est fait, cela donne froid dans le dos pour certains SGBD du monde libre. Il en est ainsi de MySQL/MariaDB comme de PostGreSQL.
L’étude de la problématique de chiffrement et via les préconisations de la CNIL et les règlements du RGPD(7), montre sans équivoque que presque toutes les données d’une base contenant des personnes physiques devraient être chiffrées. Certes le nom, le prénom, mais aussi les emails, numéros de téléphone doivent l’être, mais aussi la combinaison d’une adresse ou d’une action unitaire et d’une date. De fil en aiguille c’est la base entière qu’il faut chiffrer. Pour cela les grands éditeurs (Oracle, Microsoft SQL Server) proposent une méthode globale appelée TDE (Transparent Data Encryption) pour chiffrer de manière élégante et sans impact sur les performances relationnelles, la totalité des données de la base. Cette technologie est hors de portée du monde libre.
Dans MySQL/MariaDB, le chiffrement impose la connaissance des clefs dans l’appel de fonction de déchiffrement ou bien le stockage de la clef à titre de fichier dans le système de fichiers à la portée du serveur. Un peu comme si vous laissiez votre voiture fermée à clef avec les clefs dessus. Lorsque l’on sait que la majorité des vols de données sont le fait d’attaques internes à l’entreprise, ce niveau de sécurité est plus qu’illusoire.
Un exemple de déchiffrement nous est donné par la commande suivante :
SELECT DECRYPT(MaColonne 'Mon mot de passe').
Bref, il suffit d’aller lire les sources sur les postes de développeurs pour connaître la clef, ou encore de parcourir les exécutables des applications des postes clients.
C’est en partie pour cette raison – une clef d’accès inscrite en clair dans un fichier de code source – que la CNIL a condamné la société UBER France à une amende de 400 000 €.
Dans les SGBD professionnels, comme SQL Server, la totalité du système de chiffrement repose sur une arborescence interne. Les clefs de chiffrement des données sont stockées dans la base de manière chiffrée, et ce chiffrement est généré par une clef « maître » de la base dont la génération a elle-même été entreprise par une clef maître de l’instance, générée lors de l’installation. Aucun fichier, aucun mot de passe. Les mécanismes sont automatiques et reposent généralement sur le fait que vous possédez un certificat adéquat. La plupart des clefs ne pouvant même pas être sauvegardées (sinon, c’est à nouveau un « trou » de sécurité).
Une autre possibilité offerte par les grands SGBDR, est de confier la gestion des clefs à un HSM (Hardware Security Module) c’est-à-dire un système électronique de génération et stockage des clefs, autodestructif en cas d’intrusion.
Mais le chiffrement dans MySQL est encore plus passoire qu’on ne le croit. En effet si vous désirez utiliser des outils de trace pour suivre les performances, alors ces derniers traceront les informations en clair et d’autres ne fonctionneront plus !
XII. stockage de documents électroniques▲
La norme du langage SQL a inventé de concept de « datalink » afin de résoudre avec élégance les problématiques de stockage des fichiers électroniques dans les bases de données (fonctionnalité M001 et suivantes de la norme ISO SQL:1999). Le datalink consiste à stocker tout type de fichiers (photo, son, vidéo, PDF) sous le contrôle du serveur SQL qui en assure la sécurité d’accès comme l’intégrité par le biais du transactionnement et de la sauvegarde(8).
MySQL n’incorpore pas ce genre de fonctionnalité réservé aux grands SGBDR comme SQL Server via le « FileStream » qui, en outre, assurent l’anonymisation automatique du nom du fichier et la possibilité d’indexer les documents électroniques de toutes natures en mode « fulltext(9) ».
Aujourd’hui ce genre de manque coûte très cher. La CNIL, responsable en France de l’application du RGPD a déjà épinglé plusieurs entreprises et sommé de payer des amendes compte tenu des accès plus qu’ouverts aux documents électroniques sur les serveurs Web de certains sites irresponsables.
C’est le cas de l’ADEF (Association pour le Développement des Foyers) qui a dû payer une amende de 75 000 € pour des documents confidentiels et nominatifs laissés en libre accès.
C’est aussi le cas de l’Alliance Française Paris Île de France, qui, pour les mêmes motifs a dû payer une amende de 30 000 €
C’est encore pour un motif similaire que l’entreprise Bouygues Telecom a été condamnée à verser une amende de 250 000 €.
XIII. Correction des bogues▲
Comme toutes les applications, MySQL n’est pas exempt de bogue. Mais compte tenu de son faible nombre de lignes de code (une installation de MySQL fait environ 210 Mo contre environ 7720 Mo pour SQL Server, soit 37 fois plus(10)), le nombre de bogues à ce jour (27/05/2019) 73 738, laisse à penser qu’un très grand nombre d’utilisateurs ont été victimes des malfaçons de ce logiciel. Combien cela coûte-t-il à l’entreprise ? Difficile de le chiffrer. C’est heureux, sinon plus aucune entreprise n'utiliserait un produit aussi calamiteux !
Combien de temps mettent les équipes de MySQL/MariaDB pour corriger un bogue ? Faites-vous, vous-même, votre propre opinion.
J’ai remarqué qu’un bogue critique, sur la gestion de l’auto-incrément (https://bugs.mysql.com/bug.php?id=199) a été ouvert en mars 2003 et corrigé en octobre 2017. Soit plus de 14 ans…
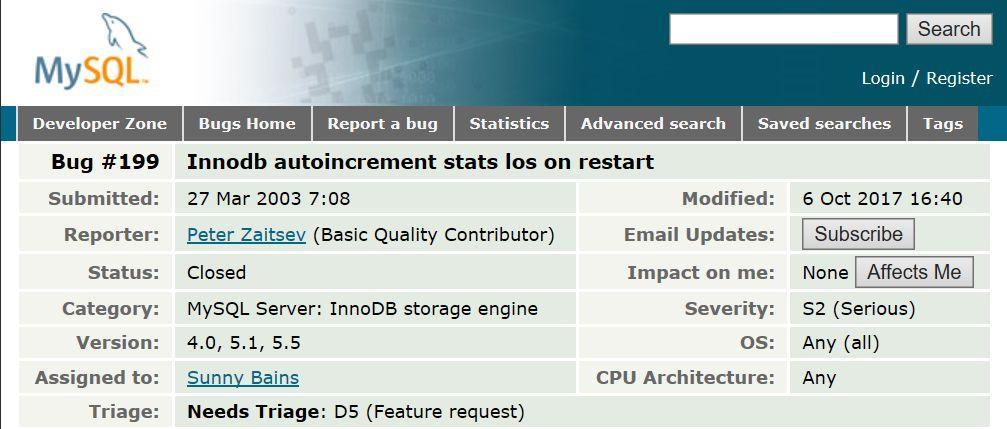
Au moins, 14 ans pour corriger un bogue aussi important, cela vous laisse le temps de réfléchir !
Ah oui, j’oubliais, comme c’est du soi-disant libre, certains aficionados vous répliqueront que vous n’aviez qu’à le corriger vous-même !
XIV. Vulnérabilités▲
Le NIST est l’organisme national américain, pour lequel il est obligatoire de déposer les vulnérabilités détectées dans les logiciels utilisés par l’administration des USA. Ce sont des failles de code relatives à la sécurité.
On trouvera tout ceci sur le site https://nvd.nist.gov/
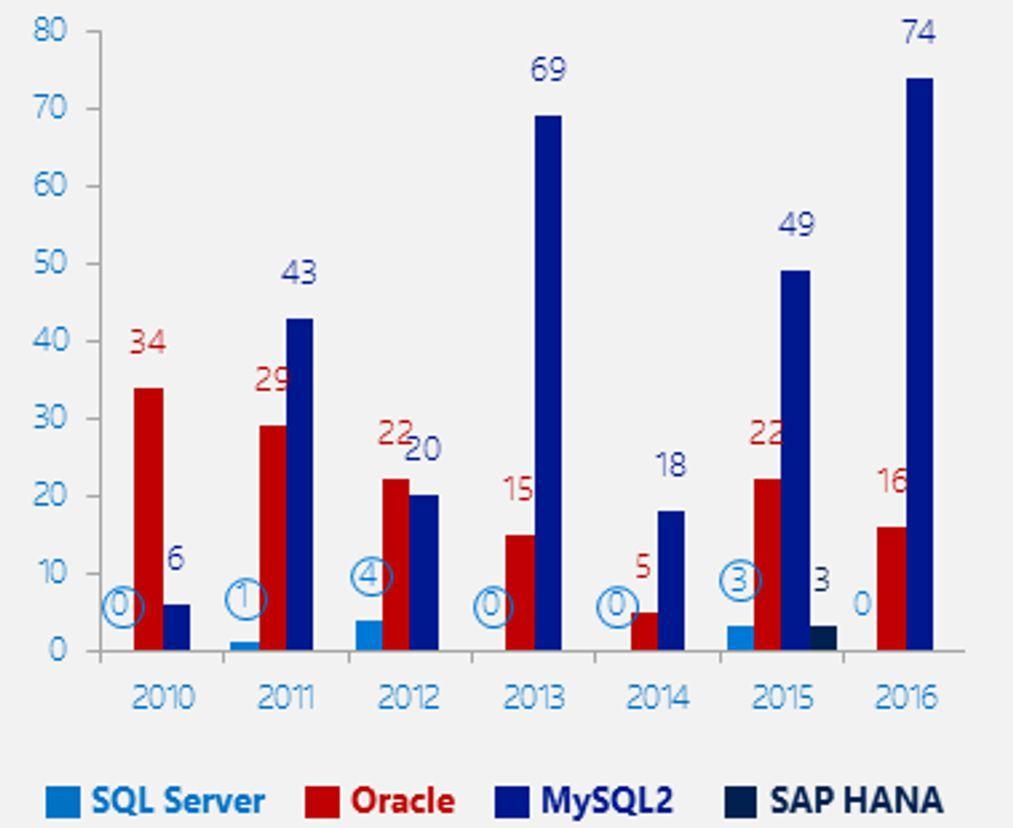
Le graphique ci-avant montre le nombre de CVE (Common Vulnerabilities and Exposures) pour la période allant de 2010 à 2016. MySQL/MariaDB gagne haut la main le podium du plus grand nombre de problèmes avec 279 CVE pour cette période, contre 143 pour Oracle, 8 pour SQL Server et 3 pour Hanna DB (base intégralement « in memory » récemment entrée dans le scope) .
En conclusion MySQL/MariaDB est juste deux fois pire qu’Oracle et 35 fois pire que SQL Server. Limitons-nous à comparer des produits comparables !
Voulez-vous la liste complète des CVE de MySQL ?
https://mariadb.com/kb/en/library/security/
Certaines vulnérabilités étant plus que critiques :
https://securitytracker.com/id/1041888
Parmi lesquelles une faille connue depuis fort longtemps perdure dans l’indifférence générale :
https://www.developpez.com/actu/242434/
XV. Performances▲
Il existe un organisme indépendant qui recense tous les tests de performance effectués sur les benchmarks officiels pour les bases de données relationnelles. C’est le TPC (Transaction Performance Council) dont les tests sont publiés et accessibles librement.
Pour les bases relationnelles, le TPC-C était le test phare jusqu’au début des années 2000. Il a failli être clôturé, mais Oracle a fait des pieds et des mains pour empêcher sa fermeture afin de continuer tout seul à publier des tests sur un jeu de requêtes aujourd’hui peu représentatif d’une base moderne (la pire des requêtes comportant trois tables).
Le TPC-E est beaucoup plus moderne. http://www.tpc.org/tpce/default.asp.
Il présente une base plus complexe avec quelques requêtes comportant jusqu’à huit tables en jointure. Il est donc relativement plus adapté aux bases actuelles.
Vous aurez beau scruter désespérément tous les résultats des benchmarks. Vous n’y trouverez ni MySQL ni MariaDB. Serait-ce à cause du monde libre ? Pourtant PostGreSQL y figure, via EnterpriseDB. Parfois à d’honorables places.
Voyez-vous, je crois que les performances de MariaDB sont tellement pathétiques qu’y figurer en toute dernière place, pour un SGBD pseudo relationnel qui clame haut et fort depuis deux décennies d’être le plus rapide, aurait de quoi refroidir les plus téméraires.
Un seul exemple. L’article intitulé « Count Distinct Compared on Top 4 SQL Databases » disponible à l’URL https://www.periscopedata.com/blog/count-distinct-in-mysql-postgres-sql-server-and-oracle et effectué sur des volumes relativement modestes, montre les chiffres suivants :
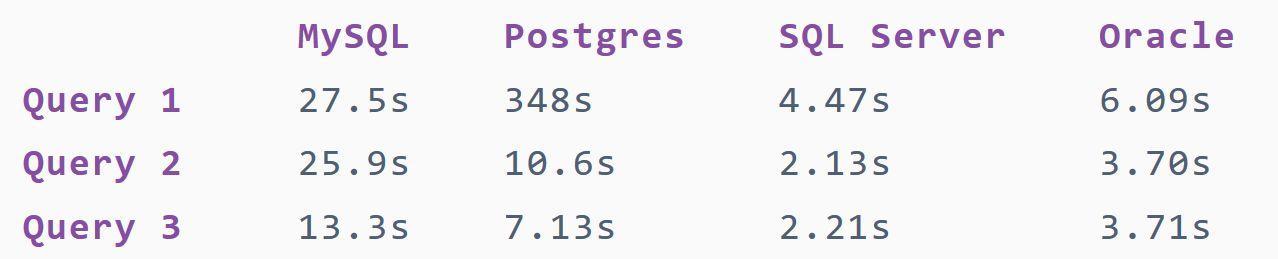
On y voit que pour un simple comptage MariaDB/MySQL est huit fois plus lent que SQL Server, et cinq fois plus lent qu’Oracle.
Et si ce n’était que cela !
XVI. Conclusion▲
Depuis longtemps, MySQL fait croire qu’il sait faire tout ce que font les grands SGBDR sans que les DSI n’aient réellement testé ses capacités opérationnelles, et le choisissent parfois pour des solutions critiques. Or la plupart des fonctions avancées de MySQL sont, soient farcies de nombreux bogues – certains monstrueux – soient dotées de performances totalement inacceptables lors de la montée en charge ou pire, de failles de sécurité incompatibles avec certaines réglementations, ou plus grave encore d’erreurs conduisant à détruire les données ou restituer des résultats faux.
Mais comme l’époque n’est plus à l’étude, mais à faire vite et merdique, on laisse passer dans l’entreprise des solutions qui sont de véritables bombes à retardement.
Récemment sollicité par l'éditeur du domaine de la santé, qui travaillait avec MySQL, je l’ai mis en garde sur le danger potentiel extrême de se voir asséner une amende colossale consécutive à un audit RGPD, du fait de l’incapacité de MySQL à pouvoir se conformer aux exigences de cette réglementation, notamment en matière de contrôle d’accès, chiffrement des données et de traçabilité des opérations.
Rappelons pour ce faire les affaires suivantes :
- Établissement hospitalier « Hospitalar Barreiro-Montijo » (Portugal) 400 000 €
- Gestion de cartes de crédit « Equifax Inc. » (USA - données britanniques) 500 000 £ ;
- Messagerie « Knuddels » (RFA) ;
- Vidéo en ligne « Daily motion » 50 000 €.
Dans le cas de l’hôpital portugais, ce dernier a eu le culot de rétorquer que « l’hôpital ne dispose pas d’outils informatiques suffisamment développés pour assurer la bonne gestion des données personnelles ». Était-ce du MySQL ?
Pointons les quelques préconisations simples que la non-application rend passibles d’amende au regard des auditeurs du RGPD :
- Le chiffrement doit être au meilleur état de l’art : ainsi des données confidentielles hachées en MD5 sans salage sont inacceptables ! Et d’ailleurs le MD5 n’est pas du chiffrement(11) ;
- Le salage du chiffrement, s’il est employé, doit être conservé dans un espace distinct de celui où sont stockés les mots de passe et ne pas être explosé en clair, ni côté serveur de bases de données, ni côté applicatif !
- Le gestionnaire doit informer dans les 72 heures son autorité de tutelle en cas de découverte d’une intrusion illicite dans les données personnelles, et pour cela doit mettre en œuvre toutes les techniques de détection et de traçabilité permettant de remonter au plus près de la source !
Et pour ce dernier point, il y a nécessité de conserver l’ensemble des versions de la structure de la base cible. En effet, que se passerait-il si on lit un objet (colonne, vue) qui est ensuite supprimé ou restructuré ? Pour cela, certains SGBDR disposent de déclencheurs de type DDL (Data Definition Language), capables de tracer toutes les modifications de structure d’une base ou de l’ensemble des bases de données.
XVII. Remerciements▲
Nous tenons à remercier Claude Leloup pour la relecture orthographique de cet article.