


II. Solutions - 2° partie▲
II-A. Solution au problème n° 11 - premiers ▲
Il suffit de prendre le problème à l'envers et de récupérer facilement tous les nombres non premiers, c'est-à-dire ceux pour lesquels le reste de le division entière par au moins un des nombres qui lui est inférieur vaut 0 :
SELECT EN1.ENT_N
FROM T_ENTIER_ENT EN1
CROSS JOIN T_ENTIER_ENT EN2
WHERE MOD(EN1.ENT_N, EN2.ENT_N) = 0
AND EN2.ENT_N BETWEEN 2 AND EN1.ENT_N -1 ;Pour ce faire, on réalise le produit cartésien du nombre avec tous les nombres compris entre 2 et ce nombre moins un et l'on teste si le reste de la division entière vaut zéro. Si ce reste vaut zéro, alors preuve est faite que ce nombre n'est pas premier.
Dès que nous avons tous les nombres non premiers, il ne s'agit plus que de trouver le complément :
SELECT *
FROM T_ENTIER_ENT
WHERE ENT_N NOT IN (SELECT EN1.ENT_N
FROM T_ENTIER_ENT EN1
CROSS JOIN T_ENTIER_ENT EN2
WHERE MOD(EN1.ENT_N, EN2.ENT_N) = 0
AND EN2.ENT_N BETWEEN 2 AND EN1.ENT_N -1)
ORDER BY 1 ;Ceci peut aussi être fait à l'aide de l'opérateur ensembliste EXCEPT
SELECT *
FROM T_ENTIER_ENT
EXCEPT
SELECT EN1.ENT_N
FROM T_ENTIER_ENT EN1
CROSS JOIN T_ENTIER_ENT EN2
WHERE MOD(EN1.ENT_N, EN2.ENT_N) = 0
AND EN2.ENT_N BETWEEN 2 AND EN1.ENT_N -1
ORDER BY 1 ;La requête pour MS SQL Server :
SELECT *
FROM T_ENTIER_ENT
WHERE ENT_N NOT IN (SELECT EN1.ENT_N
FROM T_ENTIER_ENT EN1
CROSS JOIN T_ENTIER_ENT EN2
WHERE EN1.ENT_N % EN2.ENT_N = 0
AND EN2.ENT_N BETWEEN 2 AND EN1.ENT_N -1)
ORDER BY 1 ;II-B. Solution au problème n° 12 - traduction ▲
Facile avec la fonction COALESCE et des sous requêtes. Voici un premier exemple de solution.
Solution 1 :
SELECT TDR_LIBELLE, TDR_ID, TDR_LANGUE
FROM T_TRADUCTION_TDR TDR
WHERE TDR_LANGUE = COALESCE((SELECT DISTINCT TDR_LANGUE
FROM T_TRADUCTION_TDR
WHERE TDR_LANGUE = 'Français'
AND TDR_ID = TDR.TDR_ID), (SELECT DISTINCT TDR_LANGUE
FROM T_TRADUCTION_TDR
WHERE TDR_LANGUE = 'Anglais'
AND TDR_ID = TDR.TDR_ID)) ;Une solution élégante nous a été donnée par Sonia.
SELECT TDR_LIBELLE, TDR_ID, TDR_LANGUE
FROM T_TRADUCTION_TDR
WHERE TDR_LANGUE = 'Français'
UNION
SELECT TDR_LIBELLE, TDR_ID, TDR_LANGUE
FROM T_TRADUCTION_TDR
WHERE TDR_LANGUE='Anglais'
AND TDR_ID NOT IN (SELECT TDR_ID
FROM T_TRADUCTION_TDR
WHERE TDR_LANGUE='Français')
Cette solution n'utilise pas la fonction COALESCE.
Enfin, une solution sans utiliser de sous requêtes.
SELECT COALESCE(fr.TDR_LIBELLE, en.TDR_LIBELLE) AS TDR_LIBELLE,
COALESCE(fr.TDR_LANGUE, en.TDR_LANGUE) AS TDR_LANGUE,
COALESCE(fr.TDR_ID, en.TDR_ID) AS TDR_ID
FROM T_TRADUCTION_TDR t
LEFT OUTER JOIN T_TRADUCTION_TDR as en
ON en.TDR_ID = t.TDR_ID
AND en.TDR_LANGUE='Anglais'
LEFT OUTER JOIN T_TRADUCTION_TDR as fr
ON fr.TDR_ID = t.TDR_ID
AND fr.TDR_LANGUE='Français'
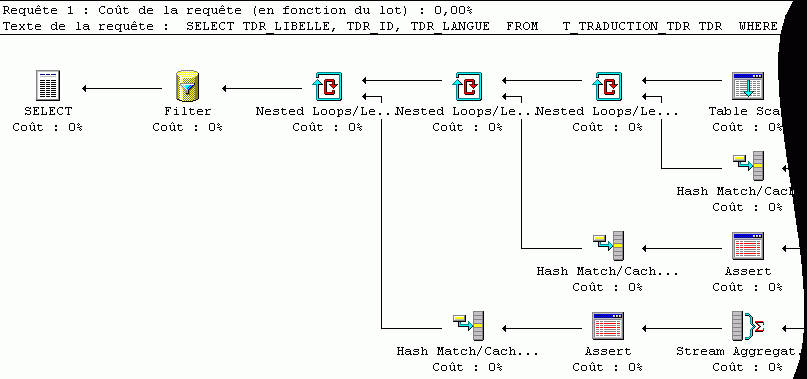
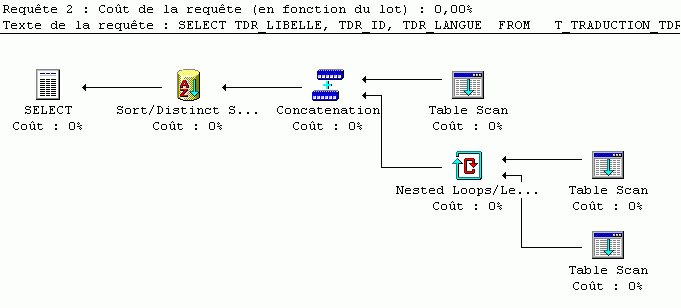
GROUP BY t.TDR_ID, fr.TDR_LIBELLE, en.TDR_LIBELLE, fr.TDR_LANGUE, en.TDR_LANGUE, fr.TDR_ID, en.TDR_IDSi l'on analyse les performances des trois requêtes à l'aide d'un outil qui visualise le plan d'exécution (MS SQL Server), on est frappé par la grande différence qui existe entre la première version et les deux suivantes...
Solution 1 (24 phases de traitement) :
Solution 2 (7 phases de traitement) :
Solution 3 (8 phases de traitement) :
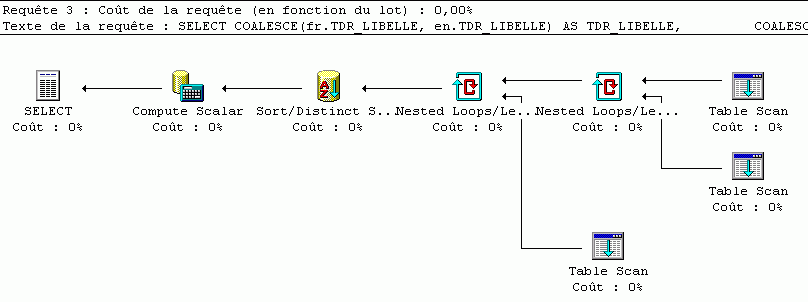
Mais la manière de faire n'indique pas toujours le coût exact. Mieux vaut s'interroger sur le nombre de lectures effectuées pour chacune des requêtes :
Table 'T_TRADUCTION_TDR'. Compte d'analyses 7, lectures logiques 7, lectures physiques 0, lectures anticipées 0.Table 'T_TRADUCTION_TDR'. Compte d'analyses 4, lectures logiques 4, lectures physiques 0, lectures anticipées 0.Table 'T_TRADUCTION_TDR'. Compte d'analyses 9, lectures logiques 9, lectures physiques 0, lectures anticipées 0.Autrement dit, la solution 3, pourtant assez économe en phases de traitement, est pire en terme de lecture que la première.
II-C. Solution au problème n° 13 - les bons joeurs ▲
En fait, la difficulté réside dans la jointure... Mais un simple CROSS JOIN suffit à résoudre le problème.
Pour compter les bonne réponses il suffit d'utiliser le CASE et d'attribuer la valeur 1 si la réponse est bonne et la valeur 0 si elle est fausse. La somme de ces valeurs donne le score.
Voici donc une solution :
SELECT PNL_NOM,
CASE WHEN J.PNL_REPONSE1 = R.RPS_REPONSE1 THEN 1 ELSE 0 END +
CASE WHEN J.PNL_REPONSE2 = R.RPS_REPONSE2 THEN 1 ELSE 0 END +
CASE WHEN J.PNL_REPONSE3 = R.RPS_REPONSE3 THEN 1 ELSE 0 END +
CASE WHEN J.PNL_REPONSE4 = R.RPS_REPONSE4 THEN 1 ELSE 0 END +
CASE WHEN J.PNL_REPONSE5 = R.RPS_REPONSE5 THEN 1 ELSE 0 END AS BONNE_REPONSE
FROM T_PANEL_PNL J
CROSS JOIN T_REPONSES_RPS R
ORDER BY BONNE_REPONSE DESC ;
Une solution dans le même genre nous a été donnée par Fabien C. :
SELECT PNL_NOM,
((SELECT COUNT(*) FROM T_REPONSES_RPS R WHERE R.RPS_REPONSE1 = J.PNL_REPONSE1) +
(SELECT COUNT(*) FROM T_REPONSES_RPS R WHERE R.RPS_REPONSE2 = J.PNL_REPONSE2) +
(SELECT COUNT(*) FROM T_REPONSES_RPS R WHERE R.RPS_REPONSE3 = J.PNL_REPONSE3) +
(SELECT COUNT(*) FROM T_REPONSES_RPS R WHERE R.RPS_REPONSE4 = J.PNL_REPONSE4) +
(SELECT COUNT(*) FROM T_REPONSES_RPS R WHERE R.RPS_REPONSE5 = J.PNL_REPONSE5)) AS T_REPONSES_RPS
FROM T_PANE id="XV"L_PNL J ;II-D. Solution au problème n° 14 - tranches d'âge ▲
Plusieurs petites difficultés :
- le calcul de l'âge ;
- la réalisation des tranches ;
- les effets de bords...
Pour le calcul de l'âge, je me sert de la formule suivante :
CAST(CURRENT_DATE - CLI_DATE_NAISSANCE AS INTERVAL DAY) / 365.2425
qui me donne un age décimal.
Pour la réalisation des tranches, il faut ajouter l'information puisqu'elle n'y est pas. Construisons donc une nouvelle table :
CREATE TABLE T_TRANCHE_AGE_TAG
(TAG_LIMITE INTEGER) ;INSERT INTO T_TRANCHE_AGE_TAG VALUES (18) ;
INSERT INTO T_TRANCHE_AGE_TAG VALUES (40) ;
Ces informations nous suffisent, mais il serait plus pratique d'avoir la représentation des tranches sous la forme :
TRANCHE_MIN TRANCHE_MAX
------------- -------------
0 18
18 40
40 NULLCar nous pourrons alors joindre la table des clients par une fourchette de valeur à cette représentation. Bien entendu nous ferrons en sorte de représenter le NULL comme étant une valeur loin dans le futur.
Cette requête nous donne presque la solution :
SELECT *
FROM T_TRANCHE_AGE_TAG TA1
LEFT OUTER JOIN T_TRANCHE_AGE_TAG TA2
ON TA1.TAG_LIMITE < TA2.TAG_LIMITE ;TAG_LIMITE TAG_LIMITE
----------- -----------
18 40
40 NULLIl faut juste rajouter la tranche commençant par zéro. Cela peut être fait à l'aide d'une opération d'UNION. Profitons-en pour mettre tout cela dans une vue :
CREATE VIEW V_TRANCHE_AGE_TAG
AS
SELECT TA1.TAG_LIMITE AS TRANCHE_MIN, TA2.TAG_LIMITE AS TRANCHE_MAX
FROM T_TRANCHE_AGE_TAG TA1
LEFT OUTER JOIN T_TRANCHE_AGE_TAG TA2
ON TA1.TAG_LIMITE < TA2.TAG_LIMITE
UNION
SELECT 0, MIN(TAG_LIMITE)
FROM T_TRANCHE_AGE_TAG ;Assemblons maintenant tout ceci dans la requête finale :
SELECT TRANCHE_MIN, COALESCE(TRANCHE_MAX, 9999) AS TRANCHE_MAX, COUNT(*) AS NOMBRE
FROM V_TRANCHE_AGE_TAG TAG
INNER JOIN T_CLIENT_CLI
ON CAST(CURRENT_DATE - CLI_DATE_NAISSANCE AS INTERVAL DAY) / 365.2425
BETWEEN TRANCHE_MIN AND COALESCE(TRANCHE_MAX, 9999)
GROUP BY TRANCHE_MIN, TRANCHE_MAX
ORDER BY TRANCHE_MIN ;TRANCHE_MIN TRANCHE_MAX NOMBRE
----------- ----------- -----------
0 18 6
18 40 4
40 9999 13Néanmoins cette solution n'est pas correcte. En effet ceux qui ont exactement 18 ans ou 40 ans sont comptabilisé 2 fois. Voici ce qui serait beaucoup plus correct :
SELECT TRANCHE_MIN, COALESCE(TRANCHE_MAX, 9999) AS TRANCHE_MAX, COUNT(*) AS NOMBRE
FROM V_TRANCHE_AGE_TAG TAG
INNER JOIN T_CLIENT_CLI
ON CAST(CURRENT_DATE - CLI_DATE_NAISSANCE AS INTERVAL DAY) / 365.2425 > TRANCHE_MIN AND
CAST(CURRENT_DATE - CLI_DATE_NAISSANCE AS INTERVAL DAY) / 365.2425 <= COALESCE(TRANCHE_MAX, 999)
GROUP BY TRANCHE_MIN, TRANCHE_MAX
ORDER BY 1 ;La requête pour MS SQL Server :
SELECT TRANCHE_MIN, COALESCE(TRANCHE_MAX, 9999) AS TRANCHE_MAX, COUNT(*) AS NOMBRE
FROM V_TRANCHE_AGE_TAG TAG
INNER JOIN T_CLIENT_CLI
ON DATEDIFF(DAY, CLI_DATE_NAISSANCE, CURRENT_TIMESTAMP) / 365.2425 > TRANCHE_MIN AND
DATEDIFF(DAY, CLI_DATE_NAISSANCE, CURRENT_TIMESTAMP) / 365.2425 <= COALESCE(TRANCHE_MAX, 999)
GROUP BY TRANCHE_MIN, TRANCHE_ id="XVI"MAX
ORDER BY 1 ;II-E. Solution au problème n° 15 - Les articles▲
La encore la technique consiste à rajouter de l'information à notre base de données. Notamment en créant une tables des articles parasites. Pour cela nous créons une table de nom T_ARTICLE_ATC avec l'article considéré et sa longueur incluant soit le blanc soit l'apostrophe avec le type SQL CHAR et non VARCHAR qui élimine les blancs finaux, et nous stockons la longueur considérée de cet article avec le blanc ou l'apostrophe, comme ceci :
CREATE TABLE T_ARTICLE_ATC
(ATC_ARTICLE VARCHAR(8),
ATC_LONGUEUR INTEGER);On y insère les principaux articles de la langue française :
INSERT INTO T_ARTICLE_ATC VALUES ('L''', 2) ;
INSERT INTO T_ARTICLE_ATC VALUES ('LE', 3) ;
INSERT INTO T_ARTICLE_ATC VALUES ('LA', 3) ;
INSERT INTO T_ARTICLE_ATC VALUES ('LES', 4) ;
INSERT INTO T_ARTICLE_ATC VALUES ('UN', 3) ;
INSERT INTO T_ARTICLE_ATC VALUES ('UNE', 4) ;
INSERT INTO T_ARTICLE_ATC VALUES ('DE', 3) ;
INSERT INTO T_ARTICLE_ATC VALUES ('DES', 4) ;
INSERT INTO T_ARTICLE_ATC VALUES ('D''', 2) ;Ensuite, la requête consiste à lier les deux tables par jointure externe afin de conserver tous les titres en utilisant comme critère de jointure le début du titre par rapport au contenu de la table des articles. Si jointure il y a (donc colonne ATC_ARTICLE non vide), alors on transforme le titre en supprimant l'article en tête du titre et en le repoussant en fin entre parenthèses. La requête suivante répond exactement à la demande du sieur Bouchon :
SELECT CASE
WHEN ATC.ATC_ARTICLE IS NULL THEN OVG.OVG_TITRE
ELSE SUBSTRING(OVG.OVG_TITRE FROM ATC.ATC_LONGUEUR + 1 FOR 64 - ATC.ATC_LONGUEUR)
+ ' (' + TRIM(RIGHT, SUBSTRING(OVG.OVG_TITRE FROM 1 FOR ATC.ATC_LONGUEUR)) + ')'
END AS TITRE
FROM T_OUVRAGES_OVG OVG
LEFT OUTER JOIN T_ARTICLE_ATC ATC
ON UPPER(SUBSTRING(OVG.OVG_TITRE FROM 1 FOR ATC.ATC_LONGUEUR))
= SUBSTRING(ATC.ATC_ARTICLE FROM 1 FOR ATC.ATC_LONGUEUR) ;La requête pour MS SQL Server :
SELECT CASE
WHEN ATC.ATC_ARTICLE IS NULL THEN OVG.OVG_TITRE
ELSE SUBSTRING(OVG.OVG_TITRE, ATC.ATC_LONGUEUR + 1, 64 - ATC.ATC_LONGUEUR)
+ ' (' + RTRIM(SUBSTRING(OVG.OVG_TITRE, 1, ATC.ATC_LONGUEUR)) + ')'
END AS TITRE
FROM T_OUVRAGES_OVG OVG
LEFT OUTER JOIN T_ARTICLE_ATC ATC
ON UPPER(SUBSTRING(OVG.OVG_TITRE, 1, ATC.ATC_LONGUEUR))
= SUBSTRING(ATC.ATC_ARTIC id="XVII"LE, 1, ATC.ATC_LONGUEUR) ;II-F. Solution au problème n° 16 - tri alphabétique▲
La solution consiste, comme souvent, à rajouter des informations afin de piloter l'ordre...
Ajoutons une table avec les nombres et leur correspondance littérale :
CREATE TABLE T_NOMBRE_LETTRE_NBL
(NBL_NOMBRE CHAR(1),
NBL_LETTRES VARCHAR(16));Et insérons-y les valeurs suivantes :
INSERT INTO T_NOMBRE_LETTRE_NBL VALUES ('1', 'Un');
INSERT INTO T_NOMBRE_LETTRE_NBL VALUES ('2', 'Deux');
INSERT INTO T_NOMBRE_LETTRE_NBL VALUES ('3', 'Trois');
INSERT INTO T_NOMBRE_LETTRE_NBLVALUES ('4', 'Quatre');
INSERT INTO T_NOMBRE_LETTRE_NBL VALUES ('5', 'Cinq');
INSERT INTO T_NOMBRE_LETTRE_NBL VALUES ('6', 'Six');
INSERT INTO T_NOMBRE_LETTRE_NBLVALUES ('7', 'Sept');
INSERT INTO T_NOMBRE_LETTRE_NBLVALUES ('8', 'Huit');
INSERT INTO T_NOMBRE_LETTRE_NBLVALUES ('9', 'Neuf');
INSERT INTO T_NOMBRE_LETTRE_NBL VALUES ('0', 'Zéro');
Si votre SGBDR dispose des spécifications de collations conforme à la norme SQL, alors cette table suffit.
Dès lors, la requête s'exprime de la sorte :
SELECT LVR_TITRE,
CASE
WHEN NBL.NBL_NOMBRE IS NULL THEN LVR_TITRE
ELSE NBL_LETTRES || ' ' || SUBSTRING(LVR.LVR_TITRE FROM 2 FOR CHARACTER_LENGTH(LVR.LVR_TITRE)-1)
END COLLATE SQL_latin_DictionnaryUsage
FROM T_LIVRE_LVR LVR
LEFT OUTER JOIN T_NOMBRE_LETTRE_NBL NBL
ON SUBSTRING(LVR.LVR_TITRE FROM 1 FOR 1) = NBL.NBL_NOMBRE
ORDER BY 2 ;NOTA : Le nom de la collation est donné à titre indicatif, les éditeurs ayant toute latitude à ce sujet.
La requête pour MS SQL Server :
SELECT LVR_TITRE
FROM T_LIVRE_LVR LVR
LEFT OUTER JOIN T_NOMBRE_LETTRE_NBL NBL
ON SUBSTRING(LVR.LVR_TITRE, 1, 1) = NBL.NBL_NOMBRE
ORDER BY CASE
WHEN NBL.NBL_NOMBRE IS NULL THEN LVR_TITRE
ELSE NBL_LETTRES + ' ' + SUBSTRING(LVR.LVR_TITRE, 2, LEN(LVR.LVR_TITRE)-1)
END COLLATE French_CI_AI ;SQL Server possède l'avantage de pouvoir effectuer un tri externe, c'est à dire sans que la colonne ne figure dans la clause SELECT. Ici la collation choisie permet de faire confusion entre les caractères accentuées ou non (et plus généralement les caractères diacritiques ou non : cédille, tilde, ligature...) et de confondre aussi la casse (majuscule/minuscule).
Si telle n'était pas le cas; il faudrait alors allonger la table T_NOMBRE_LETTRE_NBL avec de nouvelles entrées telles que :
INSERT INTO T_NOMBRE_LETTRE_NBL VALUES ('À', 'a');
INSERT INTO T_NOMBRE_LETTRE_NBL VALUES ('Â', 'a');
INSERT INTO T_NOMBRE_LETTRE_NBL VALUES ('â', 'a');Etc.
Un seul problème subsisterait alors, celui de la gestion de l'espace pour le remplacement des nombres par les littéraux alors que cela n'est pas nécessaire pour id="XVIII" les caractères.
II-G. Solution au problème n° 17 - appariement▲
En fait une double condition doit être simultanément vraie : que tous les PER_2 de la valeur PER_1 scrutée soit dans les valeur de PER_2 en regard ET que tous les PER_2 en regard soit dans les valeurs des PER_2 de la valeur PER_1 scrutée. En négativant cette double condition, on obtient :
On joint la table sur elle-même avec équivalence pour PER_1 et différence pour PER_2. Pour plus de clarté, appelons les deux occurrences de notre table ORIGINE pour la première et DESTINATION pour la seconde :
SELECT DISTINCT ORIGINE.PER_1, DESTINATION.PER_1
FROM T_PAIRE_PER ORIGINE
INNER JOIN T_PAIRE_PER DESTINATION
ON ORIGINE.PER_2 = DESTINATION.PER_2
AND ORIGINE.PER_1 <> DESTINATION.PER_1
-- Le premier filtre considère que toutes les valeurs PER_2 de ORIGINE doivent être présentent dans PER_2 de DESTINATION.
-- Avec cette clause A1 et A9 sont éliminées.
WHERE NOT EXISTS (SELECT *
FROM T_PAIRE_PER
WHERE PER_1 = ORIGINE.PER_1
AND PER_2 NOT IN (SELECT PER_2
FROM T_PAIRE_PER
WHERE PER_1 = DESTINATION.PER_1))
-- Le second filtre considère que toutes les valeurs PER_2 de DESTINATION doivent être présentent dans PER_2 de ORIGINE.
-- Avec cette clause A5 est éliminée.
AND NOT EXISTS (SELECT *
FROM T_PAIRE_PER
WHERE PER_1 = DESTINATION.PER_1
AND PER_2 NOT IN (SELECT PER_2
FROM T_PAIRE_PER
WHERE PER_1 = ORIGINE.PER_1))
ORDER BY 1, 2 ;|
Le premier filtre
conduit au jeu de résultat suivant : |
Le second filtre
conduit au jeu de résultat suivant : |
Solution |
|
Sélectionnez |
Sélectionnez |
Sélectionnez |
Les données communes ont été mise en évidence par une couleur blanche et en gras.
On peut lire ces filtres de la manière suivante : il ne faut pas qu'il existe une valeur de PER_2 de la table origine qui ne soit pas dans la table de destination. Et vice versa pour le second filtre.
En fait le problème s'apparente à la division relationnelle et plus particulièrement à la division de Todd que Joe Celko évoque dans son ouvrage SQL for smarties (SQ id="XIX"L Avancé, Vuibert éditeur).
II-H. Solution au problème n° 18 - meilleure correspondance partielle ▲
Pour trouver la réponse à ce problème, il faut décomposer la chaîne de caractère composant le code en autant de chaînes de caractères de longueur allant de 1 à la valeur maximum permet le format du type SQL, ici 16. Puis de comptabiliser pour chacune de ces combinaisons, celle qui sont communes à l'aide d'un GROUP BY. Enfin de retenir de ce calcul celles ayant le nombre le plus élevé d'occurrences avec la longueur la plus grande.
Pour décomposer la chaîne représentant le code, il faut une table des nombres allant de 1 à la longueur maximale de la colonnes RTE_CODE soit 16. Pour cela reprenons la table T_ENTIER_ENT de l'exercice 6 :
CREATE TABLE T_ENTIER_ENT
(ENT_N INTEGER);INSERT INTO T_ENTIER_ENT VALUES (0);
INSERT INTO T_ENTIER_ENT VALUES (1);
INSERT INTO T_ENTIER_ENT VALUES (2);
INSERT INTO T_ENTIER_ENT VALUES (3);
INSERT INTO T_ENTIER_ENT VALUES (4);
INSERT INTO T_ENTIER_ENT VALUES (5);
INSERT INTO T_ENTIER_ENT VALUES (6);
INSERT INTO T_ENTIER_ENT VALUES (7);
INSERT INTO T_ENTIER_ENT VALUES (8);
INSERT INTO T_ENTIER_ENT VALUES (9) ;INSERT INTO T_ENTIER_ENT
SELECT TEU.ENT_N -- les unités
+ 10 * TED.ENT_N -- les dizaines
+ 100 * TEC.ENT_N -- les centaines
+ 1000 * TEM.ENT_N -- les milliers
FROM T_ENTIER_ENT TEU -- table des entiers pour les unités
CROSS JOIN T_ENTIER_ENT TED -- table des entiers pour les dizaines
CROSS JOIN T_ENTIER_ENT TEC -- table des entiers pour les centaines
CROSS JOIN T_ENTIER_ENT TEM -- table des entiers pour les milliers
WHERE TEU.ENT_N
+ 10 * TED.ENT_N
+ 100 * TEC.ENT_N
+ 1000 * TEM.ENT_N > 9 -- empêche d'insérer les doublons des unitésVolontairement, je la peuple avec des valeurs nettement supérieures à la taille maximale de la colonne concernée...
La requête est alors la suivante :
SELECT DISTINCT R.RTE_DESTINATION, SUBSTRING(RTE_CODE FROM 1 FOR LNG) as RTE_CODE
FROM T_ROUTE_RTE R
INNER JOIN (SELECT RTE_DESTINATION, MAX(LNG) AS LNG
FROM (SELECT RTE_DESTINATION, RTE_CODE2, LNG, COUNT(*) AS NBR
FROM (SELECT RTE_DESTINATION,
SUBSTRING(RTE_CODE FROM 1 FOR ENT_N) as RTE_CODE2,
ENT_N AS LNG
FROM T_ROUTE_RTE
CROSS JOIN T_ENTIER_ENT
WHERE ENT_N BETWEEN 1 AND CHARACTER_LENGTH(RTE_CODE)) T
GROUP BY RTE_DESTINATION, RTE_CODE2, LNG
HAVING COUNT(*) = (SELECT COUNT(*)
FROM T_ROUTE_RTE
WHERE RTE_DESTINATION = T.RTE_DESTINATION
GROUP BY RTE_DESTINATION)) TT
GROUP BY RTE_DESTINATION) TTT
ON R.RTE_DESTINATION = TTT.RTE_DESTINATIONLa même requête pour MS SQL Server :
SELECT DISTINCT R.RTE_DESTINATION, SUBSTRING(RTE_CODE, 1, LNG) as RTE_CODE
FROM T_ROUTE_RTE R
INNER JOIN (SELECT RTE_DESTINATION, MAX(LNG) AS LNG
FROM (SELECT RTE_DESTINATION, RTE_CODE2, LNG, COUNT(*) AS NBR
FROM (SELECT RTE_DESTINATION,
SUBSTRING(RTE_CODE, 1, ENT_N) as RTE_CODE2,
ENT_N AS LNG
FROM T_ROUTE_RTE
CROSS JOIN T_ENTIER_ENT
WHERE ENT_N BETWEEN 1 AND LEN(RTE_CODE)) T
GROUP BY RTE_DESTINATION, RTE_CODE2, LNG
HAVING COUNT(*) = (SELECT COUNT(*)
FROM T_ROUTE_RTE
WHERE RTE_DESTINATION = T.RTE_DESTINATION
GROUP BY RTE_DESTINATION)) TT
GROUP BY RTE_DESTINATION) TTT
ON R.RTE_DESTINATION = TTT.RTE_DESTINATIONDécomposition :
Le calcul de toutes les sous chaines se fait à l'aide d'un produit cartésien avec la table des nombres.
Pour un maximum d'efficacité on ne découpe pas les sous chaînes dont la longueur est supérieur à la taille de la données.
On spécifie aussi la longueur dans la colonne LNG
SELECT RTE_DESTINATION,
SUBSTRING(RTE_CODE FROM 1 FOR ENT_N) as RTE_CODE2,
ENT_N AS LNG
FROM T_ROUTE_RTE
CROSS JOIN T_ENTIER_ENT
WHERE ENT_N BETWEEN 1 AND CHARACTER_LENGTH(RTE_CODE) ;La même requête pour MS SQL Server :
SELECT RTE_DESTINATION,
SUBSTRING(RTE_CODE, 1, ENT_N) as RTE_CODE2,
ENT_N AS LNG
FROM T_ROUTE_RTE
CROSS JOIN T_ENTIER_ENT
WHERE ENT_N BETWEEN 1 AND LEN(RTE_CODE) ;Ce qui donne :
RTE_DESTINATION RTE_CODE2 LNG
-------------------------------- ---------------- -----------
albania-Mobile 0 1
albania-Mobile 00 2
albania-Mobile 003 3
albania-Mobile 0035 4
albania-Mobile 00355 5
albania-Mobile 003553 6
albania-Mobile 0035538 7
albania-Mobile 0 1
albania-Mobile 00 2
albania-Mobile 003 3
albania-Mobile 0035 4
albania-Mobile 00355 5
albania-Mobile 003556 6
albania-Mobile 0035569 7
albania-Mobile 0 1
albania-Mobile 00 2
albania-Mobile 003 3
albania-Mobile 0035 4
albania-Mobile 00355 5
albania-Mobile 003556 6
albania-Mobile 0035560 7
SFR-Mobile 0 1
SFR-Mobile 00 2
SFR-Mobile 007 3
SFR-Mobile 0077 4
SFR-Mobile 00772 5
SFR-Mobile 007728 6
SFR-Mobile 0077280 7
SFR-Mobile 0 1
SFR-Mobile 00 2
SFR-Mobile 007 3
SFR-Mobile 0077 4
SFR-Mobile 00773 5
SFR-Mobile 007739 6
SFR-Mobile 0077390 7
BOUYGE_TEL 0 1
BOUYGE_TEL 00 2
BOUYGE_TEL 007 3
BOUYGE_TEL 0078 4
BOUYGE_TEL 00784 5
BOUYGE_TEL 007845 6
BOUYGE_TEL 0078452 7De ce résultat passé en sous requête, on compte le nombre de lignes identiques groupées par RTE_DESTINATION, RTE_CODE et longueur de la chaîne :
SELECT RTE_DESTINATION, RTE_CODE2, LNG, COUNT(*) AS NBR
FROM (SELECT RTE_DESTINATION,
SUBSTRING(RTE_CODE FROM 1 FOR ENT_N) as RTE_CODE2,
ENT_N AS LNG
FROM T_ROUTE_RTE
CROSS JOIN T_ENTIER_ENT
WHERE ENT_N BETWEEN 1 AND CHARACTER_LENGTH(RTE_CODE)) T
GROUP BY RTE_DESTINATION, RTE_CODE2, LNG ;La même requête pour MS SQL Server :
SELECT RTE_DESTINATION, RTE_CODE2, LNG, COUNT(*) AS NBR
FROM (SELECT RTE_DESTINATION,
SUBSTRING(RTE_CODE, 1, ENT_N) as RTE_CODE2,
ENT_N AS LNG
FROM T_ROUTE_RTE
CROSS JOIN T_ENTIER_ENT
WHERE ENT_N BETWEEN 1 AND LEN(RTE_CODE)) T
GROUP BY RTE_DESTINATION, RTE_CODE2, LNG ;RTE_DESTINATION RTE_CODE2 LNG NBR
-------------------------------- ---------------- ----------- -----------
BOUYGE_TEL 0 1 1
BOUYGE_TEL 00 2 1
BOUYGE_TEL 007 3 1
BOUYGE_TEL 0078 4 1
BOUYGE_TEL 00784 5 1
BOUYGE_TEL 007845 6 1
BOUYGE_TEL 0078452 7 1
SFR-Mobile 0 1 2
SFR-Mobile 00 2 2
SFR-Mobile 007 3 2
SFR-Mobile 0077 4 2
SFR-Mobile 00772 5 1
SFR-Mobile 007728 6 1
SFR-Mobile 0077280 7 1
SFR-Mobile 00773 5 1
SFR-Mobile 007739 6 1
SFR-Mobile 0077390 7 1
albania-Mobile 0 1 3
albania-Mobile 00 2 3
albania-Mobile 003 3 3
albania-Mobile 0035 4 3
albania-Mobile 00355 5 3
albania-Mobile 003553 6 1
albania-Mobile 0035538 7 1
albania-Mobile 003556 6 2
albania-Mobile 0035560 7 1
albania-Mobile 0035569 7 1Le résultat nous apparaît comme étant celui pour lequel pour chaque RTE_DESTINATION, NBR est maximum et en second LNG est maximum. C'est ce que les lignes mise en exergue en blanc gras indique.
Filtrons d'abord sur nombre au moyen d'une clause HAVING :
SELECT RTE_DESTINATION, RTE_CODE2, LNG, COUNT(*) AS NBR
FROM (SELECT RTE_DESTINATION,
SUBSTRING(RTE_CODE FROM 1 FOR ENT_N) as RTE_CODE2,
ENT_N AS LNG
FROM T_ROUTE_RTE
CROSS JOIN T_ENTIER_ENT
WHERE ENT_N BETWEEN 1 AND CHARACTER_LENGTH(RTE_CODE)) T
GROUP BY RTE_DESTINATION, RTE_CODE2, LNG
HAVING COUNT(*) = (SELECT COUNT(*)
FROM T_ROUTE_RTE
WHERE RTE_DESTINATION = T.RTE_DESTINATION
GROUP BY RTE_DESTINATION)La même requête pour MS SQL Server :
SELECT RTE_DESTINATION, RTE_CODE2, LNG, COUNT(*) AS NBR
FROM (SELECT RTE_DESTINATION,
SUBSTRING(RTE_CODE, 1, ENT_N) as RTE_CODE2,
ENT_N AS LNG
FROM T_ROUTE_RTE
CROSS JOIN T_ENTIER_ENT
WHERE ENT_N BETWEEN 1 AND LEN(RTE_CODE)) T
GROUP BY RTE_DESTINATION, RTE_CODE2, LNG
HAVING COUNT(*) = (SELECT COUNT(*)
FROM T_ROUTE_RTE
WHERE RTE_DESTINATION = T.RTE_DESTINATION
GROUP BY RTE_DESTINATION) ;
Qui donne :
RTE_DESTINATION RTE_CODE2 LNG NBR
-------------------------------- ---------------- ----------- -----------
BOUYGE_TEL 0 1 1
BOUYGE_TEL 00 2 1
BOUYGE_TEL 007 3 1
BOUYGE_TEL 0078 4 1
BOUYGE_TEL 00784 5 1
BOUYGE_TEL 007845 6 1
BOUYGE_TEL 0078452 7 1
SFR-Mobile 0 1 2
SFR-Mobile 00 2 2
SFR-Mobile 007 3 2
SFR-Mobile 0077 4 2
albania-Mobile 0 1 3
albania-Mobile 00 2 3
albania-Mobile 003 3 3
albania-Mobile 0035 4 3
albania-Mobile 00355 5 3Dans ce résultat passé en sous requête, on recherche ensuite la longueur la plus grande pour chaque RTE_DESTINATION :
SELECT RTE_DESTINATION, MAX(LNG) AS LNG
FROM (SELECT RTE_DESTINATION, RTE_CODE2, LNG, COUNT(*) AS NBR
FROM (SELECT RTE_DESTINATION,
SUBSTRING(RTE_CODE FROM 1 FOR ENT_N) as RTE_CODE2,
ENT_N AS LNG
FROM T_ROUTE_RTE
CROSS JOIN T_ENTIER_ENT
WHERE ENT_N BETWEEN 1 AND CHARACTER_LENGTH(RTE_CODE)) T
GROUP BY RTE_DESTINATION, RTE_CODE2, LNG
HAVING COUNT(*) = (SELECT COUNT(*)
FROM T_ROUTE_RTE
WHERE RTE_DESTINATION = T.RTE_DESTINATION
GROUP BY RTE_DESTINATION)) TT
GROUP BY RTE_DESTINATION ;La même requête pour MS SQL Server :
SELECT RTE_DESTINATION, MAX(LNG) AS LNG
FROM (SELECT RTE_DESTINATION, RTE_CODE2, LNG, COUNT(*) AS NBR
FROM (SELECT RTE_DESTINATION,
SUBSTRING(RTE_CODE, 1, ENT_N) as RTE_CODE2,
ENT_N AS LNG
FROM T_ROUTE_RTE
CROSS JOIN T_ENTIER_ENT
WHERE ENT_N BETWEEN 1 AND LEN(RTE_CODE)) T
GROUP BY RTE_DESTINATION, RTE_CODE2, LNG
HAVING COUNT(*) = (SELECT COUNT(*)
FROM T_ROUTE_RTE
WHERE RTE_DESTINATION = T.RTE_DESTINATION
GROUP BY RTE_DESTINATION)) TT
GROUP BY RTE_DESTINATION ;Qui donne :
RTE_DESTINATION LNG
-------------------------------- -----------
BOUYGE_TEL 7
albania-Mobile 5
SFR-Mobile 4Il ne suffit plus que de recoller les données avec la table d'origine et c'est ce qui donne la requête vue au début.
Il est important que le type de la colonne RTE_CODE soit en fixe (CH id="XX"AR) et non en alfa variable (VARCHAR).
II-I. Solution au problème n° 19 - la médiane ▲
La définition stricte de la médiane est la suivante : une valeur pour laquelle, lorsque toutes les valeurs sont classées, il y a autant de valeurs ordonnées avant qu'après. Pour réaliser ce traitement, on peut considérer que la médiane consiste à classer un ensemble en deux sous ensembles :
- l'un contenant les valeurs en dessous de la valeur cherchée,
- l'autre contenant les valeurs au dessus des valeurs cherchées,
et à condition que ces deux ensembles comportent le même nombre de lignes.
II-I-1. Solution question 1 : les données à calculées sont toutes différentes (il n'y a pas de doublon) et en nombre impaires :▲
SSTT_ID STT_VALEUR
----------- -----------------------------------------------------
1 22.0
3 22.5
5 23.0 <-- la médiane est ici : 23
4 24.0
2 27.5Pour calculer le nombre de valeurs en dessous, on peut faire :
SELECT COUNT(*)
FROM T_STATISTIQUES_STT SOU
WHERE STT_VALEUR < [la valeur cherchée] ;Idem pour les valeurs au dessus :
SELECT COUNT(*)
FROM T_STATISTIQUES_STT SUR
WHERE STT_VALEUR > [la valeur cherchée] ;Lorsque les deux sous ensemble compte le même nombre de lignes à une ligne près, alors la valeur cherchée est la bonne. Une autre manière de formuler cela est de dire que le nombre de ligne de l'ensemble SUR moins le nombre de lignes de l'ensemble SOU doit être 0, 1 ou -1, suivant que le nombre de lignes total est pair ou impair. On peut exprime cela avec l'expression suivante :
ABS((SELECT COUNT(*)
FROM T_STATISTIQUES_STT SOU
WHERE STT_VALEUR < [la valeur cherchée]) -
(SELECT COUNT(*)
FROM T_STATISTIQUES_STT SUR
WHERE STT_VALEUR > [la valeur cherchée])) <= 1Pour obtenir la valeur cherchée, il suffit d'encapsuler cette expression en tant que sous requête corrélée :
SELECT *
FROM T_STATISTIQUES_STT STT
WHERE ABS((SELECT COUNT(*)
FROM T_STATISTIQUES_STT SOU
WHERE SOU.STT_VALEUR < STT.STT_VALEUR) -
(SELECT COUNT(*)
FROM T_STATISTIQUES_STT SUR
WHERE SUR.STT_VALEUR > STT.STT_VALEUR)) <= 1 ;II-I-2. Solution question 2 : les données à calculées sont toutes différentes (il n'y a pas de doublon) et en nombre paires : ▲
Seulement cette solution ne permet de trouver la bonne valeur que dans le cas ou les occurrences sont en nombre impaires. Dans le cas ou les lignes sont en nombre pair, par exemple en rajoutant la ligne (INSERT INTO T_STATISTIQUES1_ST1 VALUES (8, 23.5)), la médiane doit maintenant être calculée comme suit :
STT_ID STT_VALEUR
----------- -----------------------------------------------------
1 22.0
3 22.5
5 23.0
<-- la médiane est ici : moyenne de 23.0 et 23.5, soit 23.25
6 23.5
4 24.0
2 27.5la requête précédente fournit le résultat suivant :
STT_ID STT_VALEUR
----------- -----------------------------------------------------
5 23.0
6 23.5
Il convient donc de réaliser la moyenne de ce résultat pour exprimer la médiane. Cela s'effectue à l'aide de l'expression :
SELECT AVG(STT_VALEUR) AS MEDIANE
FROM (SELECT STT_VALEUR
FROM T_STATISTIQUES_STT STT
WHERE ABS((SELECT COUNT(*)
FROM T_STATISTIQUES_STT SOU
WHERE SOU.STT_VALEUR < STT.STT_VALEUR) -
(SELECT COUNT(*)
FROM T_STATISTIQUES_STT SUR
WHERE SUR.STT_VALEUR > STT.STT_VALEUR)) <= 1 ) TMEDIANE
--------------
23.75II-I-3. Solution question 3 : les données à calculer admettent des doublons et un nombre de lignes impairs▲
On a ajouté des lignes à notre jeu d'essai :
INSERT INTO T_STATISTIQUES_STT VALUES (7, 22.0);
INSERT INTO T_STATISTIQUES_STT VALUES (8, 22.0);
INSERT INTO T_STATISTIQUES_STT VALUES (9, 22.0);
INSERT INTO T_STATISTIQUES_STT VALUES (10, 22.0);
INSERT INTO T_STATISTIQUES_STT VALUES (11, 22.0);Dès lors, la médiane à calculer se trouve ici :
STT_ID STT_VALEUR
----------- -----------------------------------------------------
1 22.0
10 22.0
11 22.0
8 22.0
7 22.0
9 22.0 <-- la médiane est ici : 22.0
3 22.5
5 23.0
6 23.5
4 24.0
2 27.5
L'application de notre requête précédemment mise au point nous donne :
MEDIANE
--------------
NULLCe qui n'est pas tout à fait la bonne réponse.... ! Que s'est-il passé ?
Constatons tout d'abord que l'ensemble inférieur (SOU) est formé d'une seule valeur. Dès lors les opérations ensemblistes ne sont pas capable de faire la distinction entre les différentes valeurs. La limite entre les deux ensembles se positionne donc en dehors (ici dessous) de l'équilibre des lignes, et rien n'est retourné par la requête principale.
Une solution pour contourner le problème des lignes paires et impaires est de dédoubler le nombre des lignes. Cela ne change rien à la médiane de multiplier par deux les occurrences si ces nouvelles occurrences sont des lignes dupliquées, mais cela permet d'avoir l'assurance que l'on travaille sur un nombre le lignes paires. Faisons cela à l'aide d'une vue :
CREATE VIEW V_STATISTIQUES_STT
AS
SELECT *
FROM T_STATISTIQUES_STT
UNION ALL
SELECT *
FROM T_STATISTIQUES_STTDès lors, on peut exprimer notre précédente requête par :
SELECT STT_VALEUR
FROM V_STATISTIQUES_STT STT
WHERE (SELECT COUNT(*)
FROM T_STATISTIQUES_STT) <= (SELECT COUNT(*)
FROM V_STATISTIQUES_STT AS SOU
WHERE SOU.STT_VALEUR >= STT.STT_VALEUR)
AND (SELECT COUNT(*)
FROM T_STATISTIQUES_STT) <= (SELECT COUNT(*)
FROM V_STATISTIQUES_STT AS SOU
WHERE SOU.STT_VALEUR <= STT.STT_VALEUR)
Remarquez comment nous avons changé notre requête pour nous adapté au nouveau cas en exigeant que le nombre de lignes de la vue en dessous (ou au dessus) de la valeur soit égal au nombre de ligne original de la table... Bien entendu cette requête renvoie systématiquement un multiple de deux lignes puisqu'elle opère sur un dédoublement des valeurs de la table. Il faut alors faire une moyenne des valeurs retournées :
SELECT AVG(STT_VALEUR) AS MEDIANE
FROM (SELECT STT_VALEUR
FROM V_STATISTIQUES_STT STT
WHERE (SELECT COUNT(*)
FROM T_STATISTIQUES_STT) <= (SELECT COUNT(*)
FROM V_STATISTIQUES_STT AS SOU
WHERE SOU.STT_VALEUR <= STT.STT_VALEUR)
AND (SELECT COUNT(*)
FROM T_STATISTIQUES_STT) <= (SELECT COUNT(*)
FROM V_STATISTIQUES_STT AS SUR
WHERE SUR.STT_VALEUR >= STT.STT_VALEUR) ) TMais cette requête n'est pas encore parfaite... En effet, si nous ajoutons la ligne suivante :
INSERT INTO T_STATISTIQUES_STT VALUES (12, 22.5)La médiane devrait être :
STT_ID STT_VALEUR
----------- -----------------------------------------------------
1 22.0
7 22.0
8 22.0
9 22.0
10 22.0
11 22.0
<-- la médiane est ici : moyenne de 22.0 et 22.5, soit 22.25
3 22.5
12 22.5
5 23.0
6 23.5
4 24.0
2 27.5Or la requête précédente nous donne pour valeur :
MEDIANE
-----------
22.125Simplement parce que le dédoublement des valeurs peut conduire à des occurrences quadruples ou plus encore des valeurs. Mais par définition la médiane dans ce cas étant la moyenne des deux valeurs, il suffit d'ajouter un DISTINCT dans le calcul de la fonction SQL AVG...
Finalement notre requête pour exprimer la médiane est en définitive :
SELECT AVG(DISTINCT STT_VALEUR) AS MEDIANE
FROM (SELECT STT_VALEUR
FROM V_STATISTIQUES_STT STT
WHERE (SELECT COUNT(*)
FROM T_STATISTIQUES_STT) <= (SELECT COUNT(*)
FROM V_STATISTIQUES_STT AS SOU
WHERE SOU.STT_VALEUR <= STT.STT_VALEUR)
AND (SELECT COUNT(*)
FROM T_STATISTIQUES_STT) <= (SELECT COUNT(*)
FROM V_STATISTIQUES_STT AS SUR
WHERE SUR.STT_VALEUR >= STT.STT_VALEUR) ) T ;Et si nous ne voulons pas de vue, cette requête peut finalement s'écrire :
SELECT AVG(DISTINCT STT_VALEUR) AS MEDIANE
FROM (SELECT STT_VALEUR
FROM (SELECT *
FROM T_STATISTIQUES_STT
UNION ALL
SELECT *
FROM T_STATISTIQUES_STT) STT
WHERE (SELECT COUNT(*)
FROM T_STATISTIQUES_STT) <= (SELECT COUNT(*)
FROM (SELECT *
FROM T_STATISTIQUES_STT
UNION ALL
SELECT *
FROM T_STATISTIQUES_STT) AS SOU
WHERE SOU.STT_VALEUR <= STT.STT_VALEUR)
AND (SELECT COUNT(*)
FROM T_STATISTIQUES_STT) <= (SELECT COUNT(*)
FROM (SELECT *
FROM T_STATISTIQUES_STT
UNION ALL
SELECT *
FROM T_STATISTIQUES_STT) AS SUR
WHERE SUR.STT_VALEUR >= STT.STT_VALEUR) ) T ;Chris Date et Joe Celko se sont bien battus par papiers interposés pour trouver les failles de ces différentes problématiques de l'expression de la médiane. Ils en ont tirés différentes expressions, dont celle que je viens de vous donner est la première version corrigés de la médiane de Date.
Joe Celko propose de calculer le nombre de lignes à retourner par les deux sous ensembles à l'aide de la demi valuation du nombre total des lignes. La, requête est intéressante à décomposer :
SELECT ST1.STT_ID, ST1.STT_VALEUR
FROM T_STATISTIQUES_STT AS ST1
INNER JOIN T_STATISTIQUES_STT AS ST2
ON ST1.STT_VALEUR <= ST2.STT_VALEUR
GROUP BY ST1.STT_ID, ST1.STT_VALEUR
HAVING COUNT(*) <= (SELECT COUNT(*) / 2 + 0.5
FROM T_STATISTIQUES_STT);STT_ID STT_VALEUR
----------- -----------------------------------------------------
3 22.5
12 22.5
5 23.0
6 23.5
4 24.0
2 27.5SELECT ST1.STT_ID, ST1.STT_VALEUR
FROM T_STATISTIQUES_STT AS ST1
INNER JOIN T_STATISTIQUES_STT AS ST2
ON ST1.STT_VALEUR >= ST2.STT_VALEUR
GROUP BY ST1.STT_ID, ST1.STT_VALEUR
HAVING COUNT(*) <= (SELECT COUNT(*) / 2 + 0.5
FROM T_STATISTIQUES_STT)STT_ID STT_VALEUR
----------- -----------------------------------------------------
1 22.0
7 22.0
8 22.0
9 22.0
10 22.0
11 22.0Il ne suffit plus que de prendre le minimum des valeurs au dessus et le maximum des valeurs en dessous pour obtenir notre solution en une ou deux lignes :
SELECT MIN(STT_VALEUR) AS STT_VALEUR
-- valeurs au dessus
FROM (SELECT ST1.STT_ID, ST1.STT_VALEUR
FROM T_STATISTIQUES_STT AS ST1
INNER JOIN T_STATISTIQUES_STT AS ST2
ON ST1.STT_VALEUR <= ST2.STT_VALEUR
GROUP BY ST1.STT_ID, ST1.STT_VALEUR
HAVING COUNT(*) <= (SELECT COUNT(*) / 2 + 0.5
FROM T_STATISTIQUES_STT) ) SUR
UNION ALL
SELECT MAX(STT_VALEUR) AS STT_VALEUR
-- valeurs en dessous
FROM (SELECT ST1.STT_ID, ST1.STT_VALEUR
FROM T_STATISTIQUES_STT AS ST1
INNER JOIN T_STATISTIQUES_STT AS ST2
ON ST1.STT_VALEUR >= ST2.STT_VALEUR
GROUP BY ST1.STT_ID, ST1.STT_VALEUR
HAVING COUNT(*) <= (SELECT COUNT(*) / 2 + 0.5
FROM T_STATISTIQUES_STT) ) SOU ;
Qui donne :
STT_VALEUR
-----------------------------------------------------
22.5
22.0Nous savons désormais quoi faire, et la requête globale s'exprime de la sorte :
SELECT AVG(STT_VALEUR) AS MEDIANE
FROM (SELECT MIN(STT_VALEUR) AS STT_VALEUR
-- valeurs au dessus
FROM (SELECT ST1.STT_ID, ST1.STT_VALEUR
FROM T_STATISTIQUES_STT AS ST1
INNER JOIN T_STATISTIQUES_STT AS ST2
ON ST1.STT_VALEUR <= ST2.STT_VALEUR
GROUP BY ST1.STT_ID, ST1.STT_VALEUR
HAVING COUNT(*) <= (SELECT COUNT(*) / 2 + 0.5
FROM T_STATISTIQUES_STT) ) SUR
UNION
SELECT MAX(STT_VALEUR) AS STT_VALEUR
-- valeurs en dessous
FROM (SELECT ST1.STT_ID, ST1.STT_VALEUR
FROM T_STATISTIQUES_STT AS ST1
INNER JOIN T_STATISTIQUES_STT AS ST2
ON ST1.STT_VALEUR >= ST2.STT_VALEUR
GROUP BY ST1.STT_ID, ST1.STT_VALEUR
HAVING COUNT(*) <= (SELECT COUNT(*) / 2 + 0.5
FROM T_STATISTIQUES_STT) ) SOU ) T ;Une façon plus concise d'exprimer la médiane est celle-ci :
SELECT AVG(STT_VALEUR)
FROM (SELECT E.STT_VALEUR
FROM T_STATISTIQUES_STT E
CROSS JOIN T_STATISTIQUES_STT D
GROUP BY E.STT_VALEUR
HAVING SUM(CASE
WHEN E.STT_VALEUR = D.STT_VALEUR THEN 1
ELSE 0
END) >= ABS(SUM(SIGN(E.STT_VALEUR - D.STT_VALEUR)))
) AS TD'autres formulations sont possibles, notamment en faisant usage d'une fonction de fenêtrage (norme SQL:2003) :
SELECT AVG(STT_VALEUR) AS MEDIANE
FROM (SELECT *
FROM (SELECT *, ROW_NUMBER() OVER(ORDER BY STT_VALEUR) AS RANG,
COUNT(*) OVER() AS NOMBRE
FROM T_STATISTIQUES_STT) AS T
WHERE ( NOMBRE % 2 = 0
AND RANG IN (NOMBRE / 2, (NOMBRE / 2) + 1 ))
OR ( NOMBRE % 2 = 1
AND RANG = NOMBRE / 2) ) AS T ;Enfin, si votre SGBDR supporte une fonction limitant le nombre de lignes retournées par une requête telle que TOP (MS SQL Server) ou LIMIT (MySQL), alors vous pouvez construire votre requête ainsi :
SELECT AVG(VAL)
FROM (SELECT MAX(STT_VALEUR) AS VAL
FROM (SELECT TOP(SELECT CASE
WHEN N % 1 = 0 THEN (N /2) + 1
ELSE N / 2
END AS TOPN
FROM (SELECT COUNT(*) AS N
FROM dbo.T_STATISTIQUES_STT) AS T)
STT_VALEUR
FROM dbo.T_STATISTIQUES_STT
ORDER BY STT_VALEUR) AS T1
UNION
SELECT MIN(STT_VALEUR) AS VAL
FROM (SELECT TOP(SELECT CASE
WHEN N % 1 = 0 THEN (N /2) + 1
ELSE N / 2
END AS TOPN
FROM (SELECT COUNT(*) AS N
FROM dbo.T_STATISTIQUES_STT) AS T)
STT_VALEUR
FROM dbo.T_STATISTIQUES_STT
ORDER BY STT_VALEUR DESC) AS T2
) AS T ;Un bon exercice complémentaire serait de voir quel est le coût de chacune de ces formulations et d'en déduire la meilleure. Cela risque de vous réserver que id=""lques surprises... !
II-J. Solution au problème n° 20 - insertion en bloc▲
Une première manière de faire est d'utiliser le produit cartésien des deux tables restreinte à l'univers visé :
INSERT INTO T_OBJET_COULEUR_OBC (OBJ_OBJET, CLR_COULEUR)
SELECT OBJ_OBJET, CLR_COULEUR
FROM T_OBJET_OBJ
CROSS JOIN T_COULEUR_CLR
WHERE OBJ_OBJET = 'feu tricolore' AND CLR_COULEUR IN ('rouge', 'vert', 'orange')
OR OBJ_OBJET = 'drapeau français' AND CLR_COULEUR IN ('bleu', 'blanc', 'rouge') ;Une façon plus basique est de réaliser une union des lignes à insérer :
INSERT INTO T_OBJET_COULEUR_OBC (OBJ_OBJET, CLR_COULEUR)
SELECT OBJ_OBJET, 'rouge' FROM T_OBJET_OBJ WHERE OBJ_OBJET = 'feu tricolore'
UNION
SELECT OBJ_OBJET, 'vert' FROM T_OBJET_OBJ WHERE OBJ_OBJET = 'feu tricolore'
UNION
SELECT OBJ_OBJET, 'orange' FROM T_OBJET_OBJ WHERE OBJ_OBJET = 'feu tricolore'
UNION
SELECT OBJ_OBJET, 'bleu' FROM T_OBJET_OBJ WHERE OBJ_OBJET = 'drapeau français'
UNION
SELECT OBJ_OBJET, 'blanc' FROM T_OBJET_OBJ WHERE OBJ_OBJET = 'drapeau français'
UNION
SELECT OBJ_OBJET, 'rouge' FROM T_OBJET_OBJ WHERE OBJ_OBJET = 'drapeau français' ;
C'est très verbeux, mais certains SGBDR acceptent de s'affranchir de la clause FROM. Dans ce cas c'est plus rapide.
Exemple pour MS SQL Server :
INSERT INTO T_OBJET_COULEUR_OBC (OBJ_OBJET, CLR_COULEUR)
SELECT 'feu tricolore', 'rouge'
UNION
SELECT 'feu tricolore', 'vert'
UNION
SELECT 'feu tricolore', 'orange'
UNION
SELECT 'drapeau français', 'bleu'
UNION
SELECT 'drapeau français', 'blanc'
UNION
SELECT 'drapeau français', 'rouge' ;Oracle, quant à lui, exige la clause FROM, mais autorise de préciser une table virtuelle de nom DUAL :
INSERT INTO T_OBJET_COULEUR_OBC (OBJ_OBJET, CLR_COULEUR)
SELECT 'feu tricolore', 'rouge' FROM DUAL
UNION
SELECT 'feu tricolore', 'vert' FROM DUAL
UNION
SELECT 'feu tricolore', 'orange' FROM DUAL
UNION
SELECT 'drapeau français', 'bleu' FROM DUAL
UNION
SELECT 'drapeau français', 'b id=""lanc' FROM DUAL
UNION
SELECT 'drapeau français', 'rouge' FROM DUAL ;