




I. Positionnement du langage▲
Transact SQL est un langage procédural (par opposition à SQL qui est un langage déclaratif) qui permet de programmer des algorithmes de traitement des données au sein des SGBDR Sybase Adaptive Server et Microsoft SQL Server.
I-A. Historique▲
Il a été créé par Sybase INC. à la fin des années 80 pour répondre aux besoins d'extension de la programmation des bases de données pour son SGBDR.
Ce langage est donc commun aux deux produits (MS SQL Server et Sybase Adaptive) avec des différences mineures dans les implémentations.
Il sert à programmer des procédures stockées et des triggers (déclencheurs).
Transact SQL n'a aucun aspect normatif contrairement à SQL. C'est bien un « produit » au sens commercial du terme. En revanche depuis SQL 2 et plus fortement maintenant, avec SQL 3, la norme SQL a prévu les éléments de langage procédural normatif propres au langage SQL. Mais il y a une très grande différence entre la norme du SQL procédural et Transact SQL.
D'autres SGBDR utilisent d'autres langages procéduraux pour l'implémentation de procédures stockées et de triggers. C'est le cas par exemple du PL/SQL (Programming Langage) d'Oracle.
Il existe encore peu de SGBDR dont le langage procédural est calé sur la norme. Mais on peut citer OCELOT (SQL 3), PostGreSQL (SQL 2).
Par rapport à la concurrence, voici une notation approximative (sur 5) des différents langages procéduraux :
|
SGBDR |
Langage |
Respect norme |
Richesse |
|---|---|---|---|
|
Oracle 8 |
PL/SQL |
3/5 |
5/5 |
|
MS SQL Server v7 |
Transact SQL |
2/5 |
3/5 |
|
PostGreSQL |
SQL 2 |
4/5 |
4/5 |
|
OCELOT |
SQL3 |
5/5 |
4/5 |
|
InterBase |
ISQL |
3/5 |
3/5 |
Il s'agit bien entendu d'une notation toute personnelle parfaitement sujette à caution !
I-B. Utilisation▲
Transact SQL doit être utilisé :
- dans les procédures stockées, pour les calculs portant sur des données internes à la base, sans considération de gestion d'IHM. Exemple précalculs d'agrégats pour optimisation d'accès… ;
- dans les triggers, pour définir et étendre des règles portant sur le respect de l'intégrité des données. Exemple formatage de données, liens d'héritage exclusif entre tables filles…
En revanche il faut tenter de ne pas l'utiliser pour le calcul de règles métier, l'idéal étant de déporter cela dans des objets métier. Enfin l'usage de triggers pour de la réplication est à proscrire.
I-C. Conclusion▲
Nous retiendrons que ce qui compte dans l'étude de ce langage, c'est plus de comprendre ses grands concepts et son esprit afin de pouvoir le transposer sur d'autres SGBDR plutôt que d'apprendre par cœur telle ou telle instruction, d'autant que la documentation sur ce langage est assez fournie.
ATTENTION : nous étudierons ici la version Microsoft du langage Transact SQL
II. Syntaxe▲
II-A. Identifiant▲
Voici les règles de codage des identifiants (nom des objets)
Les identifiants SQL :
- ne peuvent dépasser 128 caractères ;
- ils doivent commencer par une lettre ou un « underscore » ;
- les caractères spéciaux et le blanc ne sont pas admis ;
- on se contentera d'utiliser les 37 caractères de base : ['A'..'Z', '0'..'9', '_'] ;
- la casse n'a pas d'importance.
Le symbole @ commence le nom de toute variable.
Le symbole dédoublé @@ commence le nom des variables globales du SGBDR.
Le symbole # commence le nom de toute table temporaire (utilisateur).
Exemple :
SELECT CURRENT_TIMESTAMP as DateTime
INTO #tempT
SELECT *
FROM #tempTLe symbole dédoublé ## commence le nom de toute table temporaire globale.
Conséquence : la libération des tables temporaires est consécutive à la libération des utilisateurs.
Nota : SQL Server utilise un base particulière « tempDB » pour stocker la définition des objets temporaires.
Attention : pour des raisons de performances, il est fortement déconseillé d'utiliser le SELECT … INTO … qui n'est d'ailleurs pas normalisé.
Un identifiant est dit « qualifié » s'il fait l'objet d'une notation pointée définissant le serveur, la base cible et l'utilisateur :
serveur.base_cible.utilisateur.objetExemple :
SELECT * FROM MonServeur.MaBase.MonUser.MaTableAttention : ceci suppose que les serveurs soient connus les uns des autres (procédure de « linkage »).
On peut ignorer le serveur, comme l'utilisateur, dans ce cas c'est l'utilisateur courant qui est pris en compte :
base_cible..objetet au sein de la base :
objetUn identifiant ne doit pas être un mot clef de SQL, ni un mot clef de SQL Server ni même un mot réservé. Dans le cas contraire, il faut utiliser les guillemets comme délimiteur.
La notion de constante n'existe pas dans Transact SQL.
II-B. Variables▲
Les types disponibles sont ceux de SQL :
bit, int, smallint, tinyint, decimal, numeric, money, smallmoney, float, real, datetime, smalldatetime, timestamp,
uniqueidentifier, char, varchar, text, nchar, nvarchar, ntext, binary, varbinary, image.Auxquels il faut ajouter le type :
cursorque nous verrons plus en détail.
Les valeurs de types chaînes doivent être délimitées par des apostrophes.
Une variable est déclarée à tout endroit du code par l'instruction DECLARE.
Exemple :
DECLARE @maChaine char(32)Une variable est assignée par l'instruction SET :
SET @maChaine = 'toto'Avant toute assignation, une variable déclarée est marquée à NULL.
Remarques :
- il n'existe pas de type « tableau » dans le langage Transact SQL. Cependant, une table temporaire suffit à un tel usage ;
- l'ordre SQL SELECT peut aussi servir à assigner une ou plusieurs variables, mais dans ce dernier cas il faut veiller à ce que la réponse à la requête ne produise qu'une seule ligne.
Exemple :
SELECT @NomTable = 'TABLES', @NombreLigne = count(*)
FROM INFORMATION_SCHEMA.TABLESAttention : dans le cas d'une requête renvoyant plusieurs lignes, seule la valeur de la dernière ligne sera récupérée dans la variable.
ASTUCE : si vous désirez concaténer toutes les valeurs d'une colonne dans une seule variable, vous pouvez utiliser la construction suivante :
DECLARE @Colonne varchar(8000)
SET @Colonne = ''
SELECT @Colonne = @Colonne +COALESCE(TABLE_NAME + ', ', '')
FROM INFORMATION_SCHEMA.TABLESNOTA : la notion de constante n'existe pas.
II-C. Structures basiques▲
La structure :
BEGIN
...
ENDpermet de définir des blocs d'instructions.
Les branchements possibles sont les suivants :
IF [NOT] condition instruction [ELSE instruction]
IF [NOT] EXISTS(requête select) instruction [ELSE instruction]
WHILE condition instruction
GOTO etiquette
WAITFOR [DELAY | TIME] tempsLes instructions :
BREAK
CONTINUEpermettent respectivement d'interrompre ou de continuer autoritairement une boucle.
Remarques :
- il n'y a pas de THEN dans le IF du Transact SQL, ni de DO dans le WHILE ;
- une seule instruction est permise pour les structures IF et WHILE, sauf à mettre en place un bloc d'instructions à l'aide d'une structure BEGIN / END ;
- un branchement sur étiquette se précise en suffixant l'identifiant de l'étiquette avec un caractère deux-points ':'
Exemple
Il s'agit de donner la liste de tous les nombres premiers entre 1 et 5000.
Première version en code procédural :
/* recherche de tous les nombres premiers de 1 à 5000 */
/* version procédurale (itérations) */
-- création d'une table provisoire pour stockage des données
create table #n (n int)
declare @n integer, @i integer, @premier bit
set @n = 1
set nocount on
-- un nombre premier n'est divisible que par 1 et lui-même
while @n < 5000
BEGIN
-- on présuppose qu'il est premier
set @premier = 1
set @i = 2
while @i < @n
BEGIN
-- autrement dit, tout diviseur situé entre 2 et lui-même moins un
-- fait que ce nombre n'est pas premier
if (@n / @i) * @i = @n
SET @premier = 0
SET @i = @i + 1
END
if @premier = 1
insert into #n VALUES (@n)
SET @n = @n + 1
END
SELECT * FROM #nPar ce code procédural, nous avons utilisé la formulation suivante : « n est premier si aucun nombre de 2 à n-1 ne le divise ».
Une autre façon de faire est de travailler en logique ensembliste. Si nous disposons d'une table des entiers, il est alors facile de comprendre que les nombres premiers sont tous les nombres, moins ceux qui ne sont pas premiers… Il s'agit ni plus ni moins que de réaliser une différence ensembliste.
/* recherche de tous les nombres premiers de 1 à 5000 */
/* version ensembliste (requêtes) */
DECLARE @max int
SET @max = 5000
-- cet exemple utilise la logique ensembliste pour calculer tous les nombres entiers
SET NOCOUNT ON
-- table temporaire de stockage des entiers de 1 à 5000
CREATE TABLE #n (n int)
-- boucle d'insertion de 0 à 5000
DECLARE @i int
SET @i = 0
WHILE @i < @max
BEGIN
INSERT INTO #n VALUES (@i)
SET @i = @i + 1
END
-- on prend tous les entiers de la table n moins les entiers de la table n pour
-- lesquels le reste de la division entière (modulo) par un entier moindre donne 0
-- NOTA l'opération MODULO se note % dans Transact SQL
SELECT distinct n
FROM #n
WHERE n not in (SELECT distinct n1.n
FROM #n n1
CROSS JOIN #n n2
WHERE n1.n % n2.n = 0
AND n2.n BETWEEN 2 AND n1.n - 1)
ORDER BY nNotez la différence de vitesse d'exécution entre les deux manières de faire…
Enfin, on peut encore optimiser l'une et l'autre des procédures en limitant le diviseur au maximum à CAST(SQRT(CAST(n2.n AS FLOAT)) AS INTEGER) + 1, car le plus grand des diviseurs d'un nombre ne peut dépasser sa racine carrée.
II-D. Variable de retour▲
Toute procédure stockée renvoie une variable de type entier pour signaler son état. Si cette variable vaut 0, la procédure s'est déroulée sans anomalie. Toute autre valeur indique un problème. Les valeurs de 0 à -99 sont réservées et celles de 0 à -14 sont prédéfinies. Par exemple la valeur -5 signifie erreur de syntaxe.
On peut assigner une valeur de retour de procédure à l'aide de l'instruction RETURN :
RETURN 1445II-E. Variables « système »▲
SQL Server définit un grand nombre de « variables système » c'est-à-dire des variables définies par le moteur.
En voici quelques-unes :
|
Variable |
Description |
|---|---|
|
@@connections |
nombre de connexions actives |
|
@@datefirts |
premier jour d'une semaine (1:lundi à 7:dimanche) |
|
@@error |
code de la dernière erreur rencontrée (0 si aucune) |
|
@@fetch_status |
état d'un curseur lors de la lecture (0 si lecture proprement exécutée) |
|
@@identity |
dernière valeur insérée dans une colonne auto-incrémentée pour l'utilisateur en cours |
|
@@max_connections |
nombre maximum d'utilisateurs concurrents |
|
@@procid |
identifiant de la procédure stockée en cours |
|
@@rowcount |
nombre de lignes concernées par le dernier ordre SQL |
|
@@servername |
nom du serveur SGBDR courant |
|
@@spid |
identifiant du processus en cours |
|
@@trancount |
nombre de transactions en cours |
II-F. Flags▲
Pour manipuler les effets de certaines variables, comme pour paramétrer la base de données, il est nécessaire de recourir à des « flags ».
SET NOCOUNT ON / OFF
empêche/oblige l'envoi au client de messages pour chaque instruction d'une procédure stockée affichant la ligne « nn rows affected » à la fin d'une instruction (SELECT, INSERT, UPDATE, DELETE).
Remarque : il est recommandé de désactiver le comptage dans les procédures stockées afin d'éviter l'envoi intempestif de lignes non lues qui génère du trafic réseau et rallonge les temps d'exécution.
SET ANSI_DEFAULTS ON / OFF
Conformation d'une partie de SQL Server à la norme SQL 2.
SET DATEFORMAT {format de date}
Fixation du format de date par défaut.
SET IDENTITY_INSERT nomTable ON / OFF
Active, désactive l'insertion automatique de colonnes auto-incrémentées (identity) dans la table spécifiée.
Exemple : insertion de lignes dont la clef est spécifiée dans une table donnée pourvue d'un auto-incrément :
CREATE TABLE T_CLIENT
(CLI_ID INTEGER IDENTITY NOT NULL PRIMARY KEY,
CLI_NOM VARCHAR(32))
SET IDENTITY_INSERT T_CLIENT ON
INSERT INTO T_CLIENT (CLI_ID, CLI_NOM) VALUES (325, 'DUPONT')
INSERT INTO T_CLIENT (CLI_ID, CLI_NOM) VALUES (987, 'MARTIN')
SET IDENTITY_INSERT T_CLIENT OFF
INSERT INTO T_CLIENT (CLI_ID, CLI_NOM) VALUES (512, 'LEVY')
=> Serveur: Msg 544, Niveau 16, État 1, Ligne 1
Impossible d'insérer une valeur explicite dans la colonne identité de la table 'T_CLIENT' quand IDENTITY_INSERT
est défini à OFF.II-G. Batch et GO▲
Un batch est un ensemble d'ordres SQL ou Transact SQL passés en un lot. Il peut être exécuté en lançant un fichier vers le moteur SQL ou encore en l'exécutant dans l'analyseur de requêtes.
La plupart du temps un batch est utilisé pour créer les objets d'une base et lancer au coup par coup certaines procédures lourdes (administration notamment).
Le mot clef GO permet de forcer l'exécution de différents ordres SQL d'un traitement par lot. Hors d'un contexte de transaction, le serveur peut choisir dans les différents ordres qui lui sont proposés simultanément d'exécuter telle ou telle demande dans l'ordre que bon lui semble.
La présence du mot clef GO dans un fichier d'ordres SQL passé au serveur permet de lui demander l'exécution immédiate de cet ordre ou de l'ensemble d'ordres. Dans ce, cas l'instruction GO doit être spécifiée pour chaque ordre atomique ou bien pour chaque ensemble cohérents.
En fait le mot clef GO agit comme si chaque ordre était lancé à travers un fichier différent.
Enfin, un batch est exécuté en tout ou rien. Ainsi, en cas d'erreur de syntaxe par exemple, même sur le dernier ordre du lot, aucun des ordres n'est exécuté.
Attention
- Certains ordres ne peuvent être passés simultanément dans le même lot. Par exemple la suppression d'un objet (DROP) et sa recréation immédiatement après, (CREATE) est source de conflits.
- Le mot clef GO n'est valable que pour une exécution par lot (batch). Il n'est donc pas reconnu au sein d'une procédure stockée ni dans le code d'un trigger.
II-H. Quelques fonctions de base▲
USE est une instruction permettant de préciser le nom de la base de données cible. En effet il arrive que l'on soit obligé de travailler depuis une base pour en traiter une autre. C'est le cas notamment lorsque l'on veut créer une base de données et y travailler sur le champ.
La seule base en standard dans MS SQL Server est la base « master » qui sert de matrice à toutes les bases créées. Elle contient les procédures inhérentes au serveur, mais aussi celles inhérentes aux bases nouvellement créées, ainsi que les métadonnées spécifiques de la nouvelle base (tables dont le nom commence par « syS… »).
Exemple : création d'une base de données depuis la base MASTER et création d'une table dans cette nouvelle base :
CREATE DATABASE NEW_MABASE
ON
( NAME = 'NEW_MABASE_DB',
FILENAME = 'C:\MaBase.DATA',
SIZE = 100,
MAXSIZE = 500,
FILEGROWTH = 50 )
LOG ON
( NAME = 'NEW_MABASE_LOG',
FILENAME = 'C:\MaBase.LOG',
SIZE = 5,
MAXSIZE = 25,
FILEGROWTH = 5 )
GO
USE NEW_MABASE
GO
CREATE TABLE T_CLIENT
(CLI_ID INTEGER IDENTITY NOT NULL PRIMARY KEY,
CLI_NOM VARCHAR(32))
GOPRINT est une instruction permettant de générer une ligne en sortie de procédure. Elle doit être réservée plus à la mise au point des procédures stockées que pour une utilisation en exploitation.
EXEC est une instruction permettant de lancer une requête ou une procédure stockée au sein d'une procédure ou un trigger. La plupart du temps, il n'est pas nécessaire d'utiliser l'instruction EXEC, si l'intégralité de la commande SQL ou de la procédure à lancer est connue. Mais lorsqu'il s'agit par exemple d'un ordre SQL contenant de nombreux paramètres, alors il est nécessaire de le définir dynamiquement.
Exemple : voici une procédure cherchant dans toutes les colonnes d'une table l'occurrence d'un mot :
DECLARE
@TableName Varchar(128), -- nom de la table passé en argument
@SearchWord Varchar(32) -- mot recherché
Declare @ColumnList varchar(1000) -- liste des noms de colonnes dans
-- lesquelles la recherche va s'effectuer
Declare @SQL varchar(1200) -- requête de recherche
-- obtention de la liste des colonnes pour la requête de recherche
SELECT @ColumnList = COALESCE(@ColumnList + ' + COALESCE(', 'COALESCE(') + column_name +', '''')'
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = @TableName
AND DATA_TYPE LIKE '%char%'
PRINT 'INFO - @ColumnList value is : ' + @ColumnList -- juste pour voir !
-- assemblage du texte de la requête de recherche
Set @SQL = 'SELECT * FROM '+ @TableName
+ ' WHERE ' + @ColumnList
+ ' LIKE ''%' + @SearchWord +'%'''
PRINT 'INFO - @SQL value is : ' + @SQL -- juste pour voir !
-- exécution de la requête de recherche
Exec (@SQL)II-I. Commentaires▲
Comme dans le cadre du langage SQL de base, pour placer des commentaires, il suffit d'utiliser les marqueurs suivants :
|
Début |
Fin |
Commentaire |
|---|---|---|
|
-- |
pour une ligne de commentaire |
|
|
/* |
*/ |
pour un bloc de lignes ou de caractères |
III. UDF : fonction utilisateur▲
Une UDF, autrement dit User Define Function ou Function Définie par l'Utilisateur est une fonction que le concepteur de la base écrit pour des besoins de traitement au sein des requêtes et du code des procédures stockées ou des triggers. Elle fait donc partie intégrante de la base où elle est considérée comme un objet de la base au même titre qu'une table, une vue, un utilisateur ou une procédure stockée.
Il existe deux grands types de fonctions : celles renvoyant une valeur et celles renvoyant un jeu de données (table).
III-A. Fonction renvoyant une valeur▲
La syntaxe est assez simple :
CREATE FUNCTION [ utilisateur. ] nom_fonction
( [ { @parametre1[AS] type [ = valeur_défaut ] } [ , @parametre2 ... ] ] )
RETURNS type_résultant
[ AS ]
BEGIN
code
RETURN valeur_résultante
ENDExemple, calcul de la date de Pâques pour une année donnée :
CREATE FUNCTION FN_PAQUE (@AN INT)
RETURNS DATETIME
AS
BEGIN
-- Algorithme conçu par Claus Tøndering .
-- Copyright (C) 1998 by Claus Tondering.
-- E-mail: claus@tondering.dk.
IF @AN IS NULL
RETURN NULL
DECLARE @G INT
DECLARE @I INT
DECLARE @J INT
DECLARE @C INT
DECLARE @H INT
DECLARE @L INT
DECLARE @JourPaque INT
DECLARE @MoisPaque INT
DECLARE @DimPaque DATETIME
SET @G = @AN % 19
SET @C = @AN / 100
SET @H = (@C - @C / 4 - (8 * @C + 13) / 25 + 19 * @G + 15) % 30
SET @I = @H - (@H / 28) * (1 - (@H / 28) * (29 / (@H + 1)) * ((21 - @G) / 11))
SET @J = (@AN + @AN / 4 + @I + 2 - @C + @C / 4) % 7
SET @L = @I - @J
SET @MoisPaque = 3 + (@L + 40) / 44
SET @JourPaque = @L + 28 - 31 * (@MoisPaque / 4)
SET @DimPaque = CAST(CAST(@AN AS VARCHAR(4)) +
CASE
WHEN @MoisPaque < 10 THEN '0' + CAST(@MoisPaque AS CHAR(1))
ELSE CAST(@MoisPaque AS CHAR(2))
END +
CASE
WHEN @JourPaque < 10 THEN '0' + CAST(@JourPaque AS CHAR(1))
ELSE CAST(@JourPaque AS CHAR(2))
END
AS DATETIME)
RETURN @DimPaque
ENDOn utilise une telle fonction au sein d'une requête, comme une fonction SQL de base, à ceci près que, pour une raison obscure, il faut la faire précéder du nom du propriétaire.
Exemple :
|
Sélectionnez |
Sélectionnez |
III-B. Fonction renvoyant une table▲
Il existe deux manières de procéder : soit par requête directe (table en ligne), soit par construction et alimentation d'une table (table multi-instruction).
La première syntaxe (table et ligne) est très simple. Voici un exemple, qui construit et renvoie une table des jours de semaine :
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
La seconde syntaxe demande un peu plus de travail, car elle se base sur une variable « table ». En voici la syntaxe :
CREATE FUNCTION [ utilisateur. ] nom_fonction
( [ { @parametre1[AS] type [ = valeur_défaut ] } [ , @parametre2 ... ] ] )
RETURNS type_résultant TABLE < definition_de_table >
[ AS ]
BEGIN
code
RETURN
ENDVoici un exemple, qui construit une table d'entiers limités à MaxInt et comprenant ou non le zéro (entiers naturels) :
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
NOTA : SQL Server interdit l'utilisation de fonctions non déterministes au sein des fonctions utilisateur. Par exemple, la fonction CURRENT_TIMESTAMP qui renvoie la date/heure courante ne peut être utilisée dans le cadre de l'écriture d'une UDF. Il y a cependant moyen de contourner ce problème en utilisant par exemple une vue…
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
IV. Procédures stockées▲
Le but d'une procédure stockée est triple :
- étendre les possibilités des requêtes, par exemple lorsqu'un seul ordre INSERT ou SELECT ne suffit plus ;
- faciliter la gestion de transactions ;
- permettre une exécution plus rapide et plus optimisée de calculs complexes ne portant que sur des données de la base.
Dans ce dernier cas, la méthode traditionnelle nécessitait de nombreux allers et retours entre le client et le serveur et congestionnait le réseau.
Une procédure stockée est accessible par l'interface de l'Entreprise Manager. Elle peut aussi être créée par l'analyseur de requête.
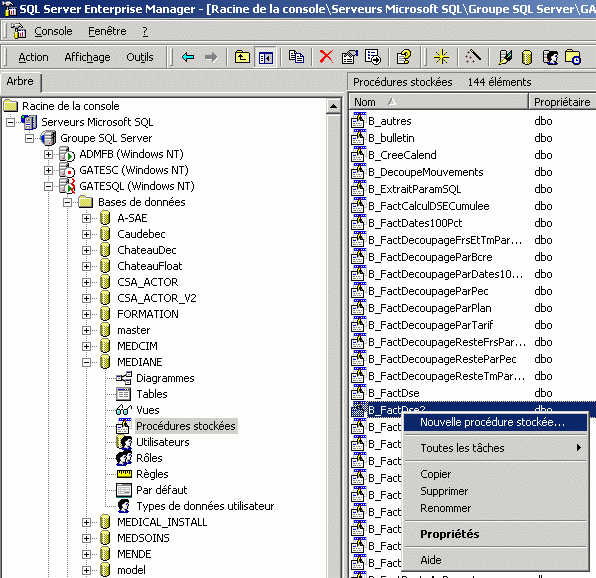
En créant une nouvelle procédure stockée, on se trouve devant une fenêtre de définition de code :
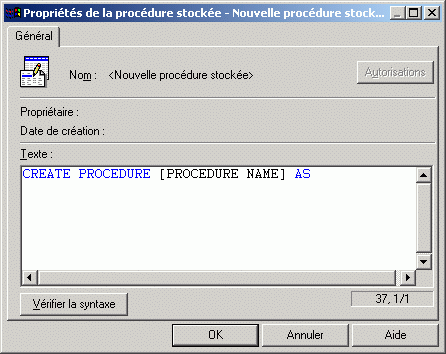
ATTENTION :
Les procédures stockées (v7) sont limitées à :
- 128 Mo de code ;
- 1024 paramètres en argument (y compris curseurs).
IV-A. Entête de procédure▲
Elle commence toujours par les mots clefs CREATE PROCEDURE suivis du nom que l'on veut donner à la procédure stockée.
Les paramètres et leur type – s'il y en a – suivent le nom.
L'entête se termine par le mot clef AS.
Exemple :
CREATE PROCEDURE SP_SEARCH_STRING_ANYFIELD
@TableName Varchar(128), -- nom de la table passé en argument
@SearchWord Varchar(32) -- mot recherché
AS
...IV-B. Paramètres, variables de retour et ensemble de données▲
Une procédure stockée peut accepter de 0 à 1024 paramètres (arguments). Elle a toujours une valeur de retour qui par défaut est le code d'exécution (entier valant 0 en cas de succès). Elle peut retourner des lignes de table comme une requête.
Pour déclarer les paramètres, il faut les lister avec un nom de variable et un type. Par défaut les paramètres sont des paramètres d'entrée.
Comme pour toutes les listes, le séparateur est la virgule.
On peut déclarer des valeurs par défaut et spécifier si le paramètre est en sortie avec le mot clef OUTPUT.
Exemple :
CREATE PROCEDURE SP_SYS_DB_TRANSACTION
@TRANS_NUM INTEGER, -- numéro de la transaction concernée
@OK BIT = 0 OUTPUT -- retour 0 OK, 1 problème
AS
...Pour récupérer la valeur d'un paramètre OUTPUT, il faut préciser une variable de récupération de nature OUTPUT dans le lacement de l'exécution.
Exemple :
DECLARE @RetourOK bit
EXEC(SP_SYS_DB_TRANSACTION 127, @RetourOK OUTPUT)
SELECT @RetourOKUn paramètre de type CURSOR (curseur) est un cas particulier et ne peut être utilisé qu'en sortie et conjointement au mot clef VARYING qui spécifie que sa définition précise n'est pas connue au moment de la compilation (le nombre et le type des colonnes ne sont pas définis à cet instant).
CREATE PROCEDURE SEARCH_TEXT @resultTable CURSOR VARYING OUTPUT
ASUn tel paramètre peut être réutilisé dans une autre procédure stockée ou dans un trigger.
Comme nous l'avons vu, toute procédure stockée renvoie une variable de type entier pour signaler son état. Si cette variable vaut 0, la procédure s'est déroulée sans anomalie. Toute autre valeur indique un problème. Les valeurs de 0 à -99 sont réservées et celles de 0 à -14 sont prédéfinies. Par exemple la valeur -5 signifie erreur de syntaxe. Bien entendu on peut assigner une valeur de retour de procédure à l'aide de l'instruction RETURN.
Une procédure stockée peut en outre renvoyer un jeu de résultats sous la forme d'un ensemble de données à la manière des résultats de requête.
Exemple :
CREATE PROCEDURE SP_LISTE_CLIENT
@CLI_ID_DEBUT INTEGER, @CLI_ID_FIN INTEGER
AS
SELECT '-- début de liste client --'
UNION ALL
SELECT CLI_NOM
FROM T_CLIENT
WHERE CLI_ID BETWEEN @CLI_ID_DEBUT AND @CLI_ID_FIN
UNION ALL
SELECT '-- fin de liste client --'IV-C. Gestion des erreurs▲
Il existe différents niveaux d'erreurs et différents moyens de les gérer.
Considérons une procédure stockée qui aurait pour effet de supprimer une ligne d'une table en s'assurant de supprimer préalablement toutes les lignes de tous les descendants concernés.
L'entête d'une telle procédure pourrait s'écrire :
CREATE PROCEDURE SP_DELETE_CLIENT_RECURSIVE
@CLI_ID INTEGERSi la ligne considérée n'est pas retrouvée dans la table des clients, comme si la valeur du paramètre est NULL, cette procédure échouera sans indiquer d'anomalie. Il faut donc procéder à des tests préalables (nullité, existence…). Sans cela, on dit que l'on a une « exception silencieuse ».
Pour les exceptions plus flagrantes, SQL Server fournit la variable globale @@error que l'on peut tester à tout instant. Cette variable est mise à jour à chaque instruction.
Le code continue de s'exécuter même après une erreur.
Pour gérer les erreurs, SQL Server dispose de la levée des erreurs à l'aide de l'instruction RAISERROR et l'utilisation du GOTO combiné à une étiquette de branchement pour la reprise sur erreur, permet de centraliser la gestion des erreurs à un seul et même endroit du programme.
Voici un exemple mettant en œuvre ces principes :
/*---------------------------------------------------\
| recherche d'une occurrence de mot dans n'importe |
| quelle colonne de type caractères d'une table donnée |
|----------------------------------------------------- |
| Frédéric BROUARD - COMMUNICATIC SA - 2001-12-17 |
\-------------------------------------------------- */
CREATE PROCEDURE SP_SEARCH_STRING_ANYFIELD
@TableName Varchar(128), -- nom de la table passé en argument
@SearchWord Varchar(32) -- mot recherché
AS
IF @TableName IS NULL OR @SearchWord IS NULL
RAISERROR ('Paramètres NULL impossible à traiter', 16, 1)
IF @@ERROR <> 0 GOTO LBL_ERROR
-- test d'existence de la table
IF NOT EXISTS(SELECT *
FROM INFORMATION_SCHEMA.tables
WHERE TABLE_NAME = @TableName)
RAISERROR ('Références de table inconnue %s', 16, 1, @TableName)
IF @@ERROR <> 0 GOTO LBL_ERROR
Declare @ColumnList varchar(1000) -- liste des noms de colonnes dans
-- lesquelles la recherche va s'effectuer
Declare @SQL varchar(1200) -- requête de recherche
-- obtention de la liste des colonnes pour la requête de recherche
SELECT @ColumnList = COALESCE(@ColumnList + ' + COALESCE(', 'COALESCE(') + column_name +', '''')'
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = @TableName
AND DATA_TYPE LIKE '%char%'
IF @ColumnList IS NULL
RAISERROR ('Aucune colonne de recherche trouvée dans la table %s',
16, 1, @TableName)
IF @@ERROR <> 0 GOTO LBL_ERROR
PRINT 'INFO - @ColumnList value is : ' + @ColumnList
-- assemblage du texte de la requête de recherche
Set @SQL =
'SELECT * FROM '+ @TableName
+ ' WHERE ' + @ColumnList
+ ' LIKE ''%' + @SearchWord +'%'''
PRINT 'INFO - @SQL value is : ' + @SQL
-- exécution de la requête de recherche
Exec (@SQL)
RETURN
LBL_ERROR:
PRINT 'ERREUR LORS DE L''EXÉCUTION DE LA PROCÉDURE STOCKÉE SP_SEARCH_STRING_ANYFIELD'IV-D. Procédures stockées prédéfinies▲
SQL Server possède des procédures stockées préétablies, un peu à la manière d'une bibliothèque d'utilisation. Elles servent essentiellement à l'administration (gestion des utilisateurs et des bases) et à l'information (dictionnaire des données). Elles se situent toutes dans la base « master ».
Ainsi, la procédure stockée « sp_help » fournit une description de n'importe quel objet de la base.
Pour appeler de telles procédures, il n'est pas nécessaire de préciser le nom de la base « master », ce nom est implicite.
Ces procédures stockées permettent :
- de piloter le paramétrage du serveur et de la base de données (respect des normes SQL 2, maximum d'utilisateurs…) - exemple : sp_configure ;
- de définir les objets de la base (table, index, contraintes, vues…) - exemple : sp_addtype ;
- d'administrer le serveur, les bases, les accès (rôles, utilisateurs, login…) - exemple : sp_droplogin ;
- d'obtenir de l'aide et de la documentation (aide en ligne, explications) - exemple : sp_helpsort ;
- de gérer les agents (alertes et batch) - exemple : sp_add_job ;
- d'assurer les réplications (entre bases et serveurs) - exemple : sp_deleteMergeConflictRows ;
- de monitorer le fonctionnement de SQL Server (tracer l'exécution) - exemple : xp_sqlTrace ;
- …
Nota : des procédures stockées dites étendues (dont le nom commence généralement par « xp_ ») font appel à du code C sous forme de DLL. Exemple : xp_cmdShell, permet de lancer un programme en ligne de commande depuis SQL Server (procédure dont l'utilisation est à déconseiller !).
Exemple - création d'un type utilisateur (DOMAINE SQL 2) pour spécification numérique de la valeur d'un mois avec contrôle de validité :
-- ajout du type TT_MONTH en entier obligatoire
SP_addType TT_MONTH, 'INTEGER', 'NOT NULL'
-- création de la règle R_CHECK_MONTH vérifiant
-- que la valeur est comprise entre 1 et 12
CREATE RULE R_CHECK_MONTH AS @value BETWEEN 1 AND 12
-- liaison de la règle au type
SP_bindRule R_CHECK_MONTH, TT_MONTHIV-E. Verrouillage▲
Le verrouillage est la technique de base pour assurer les concurrences d'accès aux ressources.
On peut observer les verrous posés lors des manipulations de données à l'aide de la procédure stockée sp_lock. De même on peut savoir qui utilise quoi à l'aide de la procédure stockée sp_who.
SQL Server pose en principe les bons verrous lors des requêtes. Mais il peut arriver que l'on souhaite :
- soit se débarrasser des contraintes de verrouillage, notamment pour faire du « dirty read » (lecture sale) ;
- soit poser des verrous plus contraignants pour s'assurer du traitement.
Dans les deux cas, il faut compléter les ordres SQL par une description des verrous attendus.
Voici les paramètres de verrouillage que l'on peut spécifier :
|
Verrou |
SELECT |
UPDATE |
|---|---|---|
|
NOLOCK |
aucun verrou |
impossible |
|
HOLDLOCK |
maintien du verrou jusqu'à la fin de la transaction |
pas nécessaire |
|
UPDLOCK |
pose un verrou de mise à jour au lieu d'un verrou partagé |
redondant |
|
PAGLOCK |
force la pose d'un verrou de page |
force la pose d'un verrou de page |
|
TABLOCK |
force un verrou partagé sur la table |
force un verrou exclusif sur la table |
|
TABLOCKX |
force un verrou exclusif sur la table pendant toute la durée de la transaction |
force un verrou exclusif sur la table pendant toute la durée de la transaction |
Ces paramètres se précisent dans un ordre SQL après le nom de la table et le mot clef WITH en utilisant le parenthèsage.
Exemples :
Accélération d'une extraction de données en demandant la suppression du verrouillage :
SELECT *
FROM T_CLIENT C WITH (NOLOCK)
JOIN T_FACTURE F WITH (NOLOCK)
ON C.CLI_ID = F.CLI_IDVerrouillage exclusif de la table le temps de la mise à jour :
UPDATE T_CLIENT WITH (TABLOCK)
SET CLI_NOM = REPLACE(CLI_NOM, ' ', '-')On peut combiner certains paramètres de verrouillage.
Exemple :
... WITH (PAGLOCK HOLDLOCK) ...Attention : la manipulation des verrous est affaire de spécialistes. Une pose de verrous sans étude préalable de la concurrence d'exécution des différentes procédures stockées d'une base, peut conduire à des scénarios de blocage, comme « l'étreinte fatale ».
IV-F. Gestion de transactions▲
Tout ordre SQL du DML est une transaction (SELECT INSERT, UPDATE, DELETE).
Parce que SQL Server fonctionne en « AUTOCOMMIT », une combinaison de différents ordres nécessite la pose explicite d'une transaction.
Ceci se fait par l'instruction BEGIN TRANSACTION et doit être terminé soit par un ROLLBACK, soit par un COMMIT.
Une transaction peut être anonyme ou nommée. De toute façon SQL Server lui attribue un identifiant interne unique.
Exemple simple. Il s'agit de réserver trois places dans le vol AF714 pour le client 123, s'il y a bien de la place pour ce vol !
BEGIN TRANSACTION
-- reste-t-il de la place pour ce vol ?
IF NOT EXISTS(SELECT *
FROM T_VOL_AVION
WHERE VOL_REF = 'AF714'
AND VOL_PLACE_LIBRE > 3)
THEN
BEGIN
ROLLBACK TRANSACTION
RETURN
END
-- décompte des places vendues
UPDATE T_VOL_AVION
SET VOL_PLACE_LIBRE = VOL_PLACE_LIBRE - 3
WHERE VOL_REF = 'AF714'
IF (@@ERROR <> 0) OR (@@ROWCOUNT = 0)
GOTO ROLLBACK_ON_ERROR
-- génération d'une réservation
INSERT INTO T_RESERVATION (VOL_REF, CLI_ID, PLACES)
VALUES ('AF714', 123, 3)
IF (@@ERROR <> 0) OR (@@ROWCOUNT = 0)
GOTO ROLLBACK_ON_ERROR
-- validation de l'ensemble
COMMIT TRANSACTION
RETURN
-- si branchement à l'étiquette d'erreur alors ROLLBACK
ROLLBACK_ON_ERROR:
ROLLBACK TRANSACTIONSQL Server permet aussi de définir des points de sauvegarde, que l'on peut considérer comme une validation partielle d'une transaction. Pour définir un point de sauvegarde, il faut utiliser l'instruction SAVE TRANSACTION avec un nom de préférence (pas obligatoire).
Par conséquent pour faire un ROLLBACK partiel, il suffit de préciser le nom du point de sauvegarde dans l'ordre ROLLBACK.
L'utilisation de la variable @@TranCount permet de savoir le nombre de transactions ouvertes en cours.
Une bonne transaction ne saurait être bien gérée sans une appréciation claire du niveau d'isolation. SQL Server gère les quatre niveaux de la norme SQL 2. La commande SET TRANSACTION ISOLATION LEVEL dont les options sont READ COMMITTED, READ UNCOMMITTED, REPEATABLE READ et SERIALIZABLE permet de définir le niveau d'isolation d'une transaction.
|
Niveau |
Effets |
ID |
|---|---|---|
|
Sélectionnez |
Implémente la lecture incorrecte, ou le verrouillage de niveau 0, ce qui signifie qu'aucun verrou partagé n'est généré et qu'aucun verrou exclusif n'est respecté. Lorsque cette option est activée, il est possible de lire des données non validées, ou données incorrectes ; les valeurs des données peuvent être modifiées et des lignes peuvent apparaître ou disparaître dans le jeu de données avant la fin de la transaction. Cette option a le même effet que l'activation de l'option NOLOCK dans toutes les tables de toutes les instructions SELECT d'une transaction. Il s'agit du niveau d'isolation le moins restrictif parmi les quatre disponibles. |
0 |
|
Sélectionnez |
Spécifie que les verrous partagés sont maintenus durant la lecture des données pour éviter des lectures incorrectes. Les données peuvent néanmoins être modifiées avant la fin de la transaction, ce qui donne des lectures non renouvelées ou des données fantômes. Cette option est l'option SQL Server par défaut. |
1 |
|
Sélectionnez |
Des verrous sont placés dans toutes les données utilisées dans une requête, afin d'empêcher les autres utilisateurs de les mettre à jour. Toutefois, un autre utilisateur peut ajouter de nouvelles lignes fantômes dans un jeu de données par un utilisateur ; celles-ci seront incluses dans des lectures ultérieures dans la transaction courante. |
2 |
|
Sélectionnez |
Place un verrou sur une plage de données, empêchant les autres utilisateurs de les mettre à jour ou d'insérer des lignes dans le jeu de données, jusqu'à la fin de la transaction. Il s'agit du niveau d'isolation le plus restrictif parmi les quatre niveaux disponibles. Utilisez cette option uniquement lorsque cela s'avère nécessaire, car la concurrence d'accès est moindre. Cette option a le même effet que l'utilisation de l'option HOLDLOCK dans toutes les tables de toutes les instructions SELECT d'une transaction. |
3 |
Attention : par défaut SQL Server travaille au niveau READ COMMITTED. Ceci explique sa rapidité comparée a des serveurs qui fonctionnent par défaut au niveau d'isolation maximal, mais peut s'avérer catastrophique pour l'intégrité des données !!!
CONSEIL : il est toujours préférable d'utiliser la gestion des transactions que de manipuler les verrous, sauf en ce qui concerne la « lecture sale » notamment dans le cadre d'une utilisation client/serveur en mode déconnecté (par exemple dans le cadre de restitutions documentaires pour un site web).
NOTA : SQL Server permet de gérer des transactions distribuées et gère le « commit à deux phases », mais sans permettre l'utilisation de points de sauvegarde.
Exemple : gestion d'un arbre modélisé par intervalle
Pour une illustration plus complète des procédures stockées, nous allons montrer les différentes procédures nécessaires pour faire « fonctionner » un arbre modélisé sous forme intervallaire. Pour un développement plus complet de ce sujet, lire l'article sur la représentation intervallaire des arborescences.
Dans notre cas nous allons considérer une table permettant de gérer le développement des projets d'une entreprise. Voici la table du développement. Elle contient les informations de chaque nœud, y compris son identifiant, son libellé, ses bornes droite et gauche et son niveau :
CREATE TABLE T_DEVELOPPEMENT_DEV
(DEV_ID INTEGER IDENTITY (1, 1) NOT NULL , -- identifiant
DEV_NIVEAU SMALLINT NOT NULL , -- niveau du noeud
DEV_LIBELLE CHAR (32) NOT NULL , -- libellé
DEV_BORNE_GAUCHE INTEGER NOT NULL , -- borne gauche de l'arbre
DEV_BORNE_DROITE INTEGER NOT NULL) -- borne droite de l'arbreTout d'abord voici la procédure d'insertion d'un fils ainé, c'est-à-dire d'un fils qui sera le plus proche du sommet au moment de l'insertion. On passe à la procédure l'identifiant du nœud père et le libellé. Une variable de retour permet de connaître l'état de l'insertion.
CREATE PROCEDURE SP_DEV_INSERTION_ARBRE_FILS_AINE
@id_pere integer,
@libelle varchar(32),
@id_ins integer OUTPUT AS
-- Frédéric BROUARD 17/11/2001
-- insertion sous père dans l'arbre du développement
-- paramètres : id_pere, libelle
DECLARE @bg_pere integer
DECLARE @niveau integer
DECLARE @OK integer
SET NOCOUNT ON
-- démarrage transaction
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
BEGIN TRANSACTION INSERT_TREE_FILS_AINE
-- vérification de l'existence du père
SELECT @OK = count(*)
FROM T_DEVELOPPEMENT_DEV
WHERE DEV_ID = @id_pere
-- si élément supprimé, alors retour sans insertion avec valeur -1
IF @OK = 0
BEGIN
SELECT -1
ROLLBACK TRANSACTION INSERT_TREE_FILS_AINE
RETURN
END
-- recherche du bg_pere et calcul du niveau inférieur
SELECT @bg_pere = DEV_BORNE_GAUCHE, @niveau = DEV_NIVEAU + 1
FROM T_DEVELOPPEMENT_DEV
WHERE DEV_ID = @id_pere
-- décalage pour insertion borne droite
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_DROITE = DEV_BORNE_DROITE + 2
WHERE DEV_BORNE_DROITE > @bg_pere
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION INSERT_TREE_FILS_AINE
SELECT -1
RETURN
END
-- décalage pour insertion borne gauche
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_GAUCHE = DEV_BORNE_GAUCHE + 2
WHERE DEV_BORNE_GAUCHE > @bg_pere
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION INSERT_TREE_FILS_AINE
SELECT -1
RETURN
END
-- insertion
INSERT INTO T_DEVELOPPEMENT_DEV (DEV_NIVEAU, DEV_LIBELLE, DEV_BORNE_GAUCHE, DEV_BORNE_DROITE)
VALUES (@niveau, @libelle, @bg_pere + 1, @bg_pere + 2)
SELECT @id_ins = @@identity
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION INSERT_TREE_FILS_AINE
SELECT -1
RETURN
END
COMMIT TRANSACTION INSERT_TREE_FILS_IANE
SELECT @id_ins -- renvoie de l'identifiant de l'élément inséré.Pour le fils cadet, la procédure n'est pas plus compliquée :
CREATE PROCEDURE SP_DEV_INSERTION_ARBRE_FILS_CADET
@id_pere integer,
@libelle varchar(32),
@id_ins integer OUTPUT AS
-- Frédéric BROUARD 17/11/2001
-- insertion sous père dans l'arbre du développement
-- paramètres : id_pere, libelle
DECLARE @bd_pere integer
DECLARE @niveau integer
DECLARE @OK integer
SET NOCOUNT ON
-- on gère une transaction qui remanie les bornes de l'arbre.
-- il ne faut pas être 'dérangé' par d'autres utilisateurs concurrents pendant cette manœuvre
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
BEGIN TRANSACTION INSERT_TREE_FILS_CADET
-- vérification de l'existence du père
SELECT @OK = count(*)
FROM T_DEVELOPPEMENT_DEV
WHERE DEV_ID = @id_pere
-- si élément supprimé, alors retour sans insertion avec valeur -1
IF @OK = 0
BEGIN
SELECT -1
ROLLBACK TRANSACTION INSERT_TREE_FILS_CADET
RETURN
END
-- recherche du bg_pere et calcul du niveau inférieur
SELECT @bd_pere = DEV_BORNE_DROITE, @niveau = DEV_NIVEAU + 1
FROM T_DEVELOPPEMENT_DEV
WHERE DEV_ID = @id_pere
-- décalage pour insertion borne droite
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_DROITE = DEV_BORNE_DROITE + 2
WHERE DEV_BORNE_DROITE >= @bd_pere
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION INSERT_TREE_FILS_CADET
SELECT -1
RETURN
END
-- décalage pour insertion borne gauche
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_GAUCHE = DEV_BORNE_GAUCHE + 2
WHERE DEV_BORNE_GAUCHE > @bd_pere
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION INSERT_TREE_FILS_CADET
SELECT -1
RETURN
END
-- insertion
INSERT INTO T_DEVELOPPEMENT_DEV (DEV_NIVEAU, DEV_LIBELLE, DEV_BORNE_GAUCHE, DEV_BORNE_DROITE)
VALUES (@niveau, @libelle, @bd_pere , @bd_pere + 1)
SELECT @id_ins = @@identity
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION INSERT_TREE_FILS_CADET
SELECT -1 as ID
RETURN
END
COMMIT TRANSACTION INSERT_TREE_SON
SELECT @id_insVoici maintenant comment on insère un frère à droite d'un autre :
CREATE PROCEDURE SP_DEV_INSERTION_ARBRE_FRERE_DROIT
@id_frere integer,
@libelle varchar(32),
@id_ins integer OUTPUT AS
-- Frédéric BROUARD 17/11/2001
-- insertion latérale à droite du frère
-- paramètres : id_frere, libelle
DECLARE @bd_frere integer
DECLARE @niveau integer
DECLARE @OK integer
SET NOCOUNT ON
-- démarrage transaction
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
BEGIN TRANSACTION INSERT_TREE_RIGHT
-- vérifie de l'existence du frère
SELECT @OK = count(*)
FROM T_DEVELOPPEMENT_DEV
WHERE DEV_ID = @id_frere
-- si élément supprimé, alors retour sans insertion avec valeur -1
IF @OK = 0
BEGIN
SELECT -1
ROLLBACK TRANSACTION INSERT_TREE_RIGHT
RETURN
END
-- recherche du bd_frere et du niveau
SELECT @bd_frere = DEV_BORNE_DROITE, @niveau = DEV_NIVEAU
FROM T_DEVELOPPEMENT_DEV
WHERE DEV_ID = @id_frere
-- décalage borne gauche pour insertion
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_GAUCHE = DEV_BORNE_GAUCHE + 2
WHERE DEV_BORNE_GAUCHE > @bd_frere
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION INSERT_TREE_RIGHT
SELECT -1
RETURN
END
-- décalage borne droite pour insertion
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_DROITE = DEV_BORNE_DROITE + 2
WHERE DEV_BORNE_DROITE > @bd_frere
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION INSERT_TREE_RIGHT
SELECT -1
RETURN
END
-- insertion
INSERT INTO T_DEVELOPPEMENT_DEV (DEV_NIVEAU, DEV_LIBELLE, DEV_BORNE_GAUCHE, DEV_BORNE_DROITE)
VALUES (@niveau, @libelle, @bd_frere + 1, @bd_frere+2)
SELECT @id_ins = @@identity
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION INSERT_TREE_RIGHT
SELECT -1
RETURN
END
COMMIT TRANSACTION INSERT_TREE_RIGHT
SELECT @id_insMême insertion en frère à gauche :
CREATE PROCEDURE SP_DEV_INSERTION_ARBRE_FRERE_GAUCHE
@id_frere integer,
@libelle varchar(32),
@id_ins integer OUTPUT AS
-- Frédéric BROUARD 17/11/2001
-- insertion latérale à gauche du frère
-- paramètres : id_frere, libelle
DECLARE @bg_frere integer
DECLARE @niveau integer
DECLARE @OK integer
SET NOCOUNT ON
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
BEGIN TRANSACTION INSERT_TREE_LEFT
-- vérification de l'existence du frère
SELECT @OK = count(*)
FROM T_DEVELOPPEMENT_DEV
WHERE DEV_ID = @id_frere
-- si élément supprimé, alors retour sans insertion avec valeur -1
IF @OK = 0
BEGIN
SELECT -1
ROLLBACK TRANSACTION INSERT_TREE_LEFT
RETURN
END
-- recherche du bg_frere
SELECT @bg_frere = DEV_BORNE_GAUCHE, @niveau = DEV_NIVEAU
FROM T_DEVELOPPEMENT_DEV
WHERE DEV_ID = @id_frere
-- décalage borne gauche pour insertion
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_GAUCHE = DEV_BORNE_GAUCHE + 2
WHERE DEV_BORNE_GAUCHE >= @bg_frere
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION INSERT_TREE_LEFT
SELECT -1
RETURN
END
-- décalage borne droite pour insertion
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_DROITE = DEV_BORNE_DROITE + 2
WHERE DEV_BORNE_DROITE > @bg_frere
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION INSERT_TREE_LEFT
SELECT -1
RETURN
END
-- insertion
INSERT INTO T_DEVELOPPEMENT_DEV (DEV_NIVEAU, DEV_LIBELLE, DEV_BORNE_GAUCHE, DEV_BORNE_DROITE)
VALUES (@niveau, @libelle, @bg_frere, @bg_frere+1)
SELECT @id_ins = @@identity
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION
SELECT -1
RETURN
END
COMMIT TRANSACTION INSERT_TREE_LEFT
SELECT @id_insEnfin, comment supprimer. Notez l'argument « récursif » passé en paramètre de procédure pour spécifier si l'on tue toute la lignée ou si on laisse survivre les descendants !
CREATE PROCEDURE SP_DEV_SUPPRESSION
@id_element integer,
@recursif bit
AS
-- Frédéric BROUARD 20/11/2001
-- suppression d'un élément (@recursif = 0) ou d'un sous-arbre (@recursif = 1)
-- paramètres : id_element, @recursif
DECLARE @OK integer
DECLARE @bg_element integer
DECLARE @bd_element integer
DECLARE @intervalle integer
SET NOCOUNT ON
-- démarrage transaction
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE
BEGIN TRANSACTION DELETE_TREE
-- vérifie de l'existence de l'élément
SELECT @OK = count(*)
FROM T_DEVELOPPEMENT_DEV
WHERE DEV_ID = @id_element
-- si élément supprimé, alors retour sans insertion avec valeur -1
IF @OK = 0
BEGIN
SELECT -1
ROLLBACK TRANSACTION DELETE_TREE
RETURN
END
-- recherche des bd_element et bd_element
SELECT @bd_element = DEV_BORNE_DROITE, @bg_element = DEV_BORNE_GAUCHE
FROM T_DEVELOPPEMENT_DEV
WHERE DEV_ID = @id_element
IF @recursif = 0
BEGIN
-- suppression de l'élément
DELETE FROM T_DEVELOPPEMENT_DEV
WHERE DEV_ID = @id_element
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION DELETE_TREE
SELECT -1
RETURN
END
-- décalage des bords droits et gauches des éléments du sous-arbre
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_DROITE = DEV_BORNE_DROITE - 1, DEV_BORNE_GAUCHE = DEV_BORNE_GAUCHE - 1
WHERE DEV_BORNE_GAUCHE > @bg_element AND DEV_BORNE_DROITE < @bd_element
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION DELETE_TREE
SELECT -1
RETURN
END
-- décalage des bords gauches des éléments externes au sous-arbre
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_GAUCHE = DEV_BORNE_GAUCHE - 2
WHERE DEV_BORNE_GAUCHE > @bg_element
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION DELETE_TREE
SELECT -1
RETURN
END
-- décalage des bords droits des éléments externes au sous-arbre
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_DROITE = DEV_BORNE_DROITE - 2
WHERE DEV_BORNE_DROITE < @bg_element
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION DELETE_TREE
SELECT -1
RETURN
END
END
IF @recursif = 1
BEGIN
-- suppression des éléments du sous-arbre
DELETE FROM T_DEVELOPPEMENT_DEV
WHERE DEV_BORNE_GAUCHE >= @bg_element AND DEV_BORNE_DROITE <= @bd_element
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION DELETE_TREE
SELECT -1
RETURN
END
-- calcul de l'intervalle de décalage
SET @intervalle = @bd_element - @bg_element + 1
-- décalage des bords gauches des éléments externes au sous-arbre
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_GAUCHE = DEV_BORNE_GAUCHE - @intervalle
WHERE DEV_BORNE_GAUCHE > @bg_element
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION DELETE_TREE
SELECT -1
RETURN
END
-- décalage des bords droits des éléments externes au sous-arbre
UPDATE T_DEVELOPPEMENT_DEV
SET DEV_BORNE_DROITE = DEV_BORNE_DROITE - @intervalle
WHERE DEV_BORNE_DROITE < @bg_element
IF @@ERROR <>0
BEGIN
ROLLBACK TRANSACTION DELETE_TREE
SELECT -1
RETURN
END
END
COMMIT TRANSACTION DELETE_TREEIV-G. Les curseurs▲
Les curseurs sont des mécanismes de mémoire tampon permettant d'accéder aux données renvoyées par une requête et donc de parcourir les lignes du résultat.
Un curseur se définit dans une instruction DECLARE possédant une requête de type SELECT. Il convient de définir pour chaque colonne renvoyée une variable de type approprié.
Pour lancer la requête associée (et donc placer les données dans les buffers appropriés) il faut utiliser l'instruction OPEN.
Un curseur doit être refermé avec l'instruction CLOSE.
Pour libérer la mémoire utilisée par un curseur, il faut utiliser l'instruction DEALLOCATE.
Pour lire les données de la ligne courante et les associées aux variables du curseur, il faut utiliser l'instruction FETCH.
Par défaut l'instruction FETCH navigue en avant d'une ligne à chaque lecture dans l'ensemble des données du résultat. Pour naviguer différemment, on peut qualifier le FETCH avec les mots clefs NEXT, PRIOR, FIRST, LAST, ABSOLUTE n et RELATIVE n, mais il faut avoir déclaré le curseur avec l'attribut SCROLL…
Enfin la variable @@fetch_Status permet de savoir si la dernière instruction FETCH passée s'est correctement déroulée (valeur 0), ce qui permet de tester si l'on est arrivé en fin de parcours de l'ensemble de données.
Une boucle traditionnelle de manipulation d'un curseur prend la forme suivante :
-- déclaration des variables de colonnes pour le curseur
DECLARE @Col1 Type1, @Col2 Type2, @Col3, Type3...
-- déclaration du curseur
DECLARE MyCursor CURSOR
FOR
SELECT COL1, COL2, COL3 …
FROM MyTable
-- ouverture du curseur
OPEN MyCursor
-- lecture du premier enregistrement
FETCH MyCursor INTO @Col1, @Col2, @Col3...
-- boucle de traitement
WHILE @@fetch_Status = 0
BEGIN
traitement
-- lecture de l'enregistrement suivant
FETCH MyCursor INTO @Col1, @Col2, @Col3...
END
-- fermeture du curseur
CLOSE myCursor
-- libération de la mémoire
DEALLOCATE myCursorOn constate que l'instruction FETCH apparaît deux fois. Une première fois avant la boucle WHILE une seconde fois à l'intérieur et en dernière ligne de la boucle WHILE.
C'est la façon la plus classique et la plus portable d'utiliser des curseurs.
NOTA : les performances sont en baisse lorsque l'on utilise tout autre déplacement que le NEXT.
Remarque : il est possible d'effectuer des mises à jour de données via des curseurs, mais cela n'est pas conseillé. Dans ce cas il faut préciser en fin de déclaration du curseur : FOR UPDATE OF liste_colonne.
On peut aussi faire du « dirty read » avec les curseurs de SQL Server en précisant l'attribut INSENSITIVE juste après le nom du curseur.
La syntaxe complète SQL 2 de la déclaration d'un curseur dans MS SQL Server est :
DECLARE nom_curseur [INSENSITIVE] [SCROLL] CURSOR
FOR requête_select
FOR {READ ONLY | UPDATE [OF colonne1 [, colonne2...]]}]La syntaxe admise par le Transact SQL de MS SQL Server est plus complète, mais moins portable :
DECLARE nom_curseur CURSOR [LOCAL | GLOBAL] FORWARD_ONLY | SCROLL] [STATIC | KEYSET | DYNAMIC | FAST_FORWARD] READ_ONLY |
SCROLL_LOCKS | OPTIMISTIC] [TYPE_WARNING]
FOR requête_select
FOR UPDATE [OF colonne1 [, colonne2...]]]Exemple : voici un petit exercice consistant, pour chaque table de la base à en donner le nombre de lignes. Pour cela on utilise une vue d'information de schéma pour récupérer le nom de toutes les tables et les traiter.
/***************************************************/
-- Frédéric BROUARD - Communicatic SA - 2001-12-24 --
--=================================================--
-- Informe du nombre de lignes de chaque table de --
-- la base de données --
/***************************************************/
CREATE PROCEDURE SP_SYS_DB_DATA_ROWS
AS
-- variables locales de la procédure
DECLARE @NomTable VARCHAR(128), -- nom de la table
@SQL VARCHAR(1000) -- texte de la requête dynamique
-- pas de messages intempestifs
SET NOCOUNT ON
-- déclaration du curseur pour analyse des tables de la base
DECLARE CursBase CURSOR
FOR
SELECT TABLE_NAME
FROM INFORMATION_SCHEMA.tables
WHERE TABLE_TYPE = 'BASE TABLE'
-- gestion de la table des résultats : nom de la table temporaire
SET @NomTable = '#DATA_VOLUME'
-- vidage si existence de cette table, sinon création
IF EXISTS(SELECT * FROM INFORMATION_SCHEMA.tables WHERE TABLE_NAME = @NomTable)
DELETE FROM #DATA_VOLUME
ELSE
CREATE TABLE #DATA_VOLUME
(TABLE_NAME VARCHAR(128),
DATA_ROWS INTEGER)
-- ouverture du curseur
OPEN CursBase
-- lecture de la première ligne
FETCH CursBase INTO @NomTable
-- boucle ligne à ligne
WHILE @@FETCH_STATUS = 0
BEGIN
-- requête d'insertion avec recherche du nombre de lignes de la table analysée
SET @SQL = 'INSERT INTO #DATA_VOLUME SELECT '''
+ @NomTable + ''', COUNT(*) FROM ' + @NomTable
EXEC(@SQL)
FETCH CursBase INTO @NomTable
END
-- fermeture et désallocation d'espace mémoire du curseur
CLOSE CursBase
DEALLOCATE CursBase
-- envoi des données
SELECT * FROM #DATA_VOLUME
-- pas de messages intempestifs
SET NOCOUNT OFFExemple : un deuxième exemple plus complexe nous montre comment rechercher l'occurrence d'un mot dans toutes les colonnes de toutes les tables de la base. C'est une extension de l'exemple vu au paragraphe 4.3 :
/*---------------------------------------------------\
| recherche d'une occurrence de mot dans n'importe |
| quelle colonne de type caractères de n'importe |
| quelle table de la base de données |
|----------------------------------------------------- |
| Frédéric BROUARD - COMMUNICATIC SA - 2001-12-18 |
\-------------------------------------------------- */
CREATE PROCEDURE SP_SEARCH_STRING_ANYFIELD_ANYTABLE
@SearchWord Varchar(32) -- mot recherché
AS
DECLARE @ErrMsg VARCHAR(128)
-- effet de bord 1 : pas de mot passé
IF @SearchWord IS NULL
BEGIN
SET @ErrMsg = 'Impossible de traiter cette recherche avec un argument NULL'
GOTO LBL_ERROR
END
-- effet de bord 2 : mot vide passé
IF @SearchWord = ''
BEGIN
SET @ErrMsg = 'Impossible de traiter cette recherche avec un argument vide'
GOTO LBL_ERROR
END
-- effet de bord 3 : mot contenant un caractère joker % du LIKE
IF CHARINDEX('%', @SearchWord) > 0
BEGIN
SET @ErrMsg = 'Impossible de traiter cette recherche avec un argument contenant un caractère %'
GOTO LBL_ERROR
END
-- effet de bord 4 : mot contenant un caractère joker _ du LIKE
IF CHARINDEX('_', @SearchWord) > 0
BEGIN
SET @ErrMsg = 'Impossible de traiter cette recherche avec un argument contenant un caractère _'
GOTO LBL_ERROR
END
-- variables de travail
DECLARE @TableName VARCHAR(128), -- nom de la table passé en argument
@ColumnList1 VARCHAR(2000),-- liste des colonnes pour clause SELECT
@ColumnList2 VARCHAR(2000),-- liste des colonnes pour clause WHERE
@SQL VARCHAR(5000) -- requête dynamique
-- curseur parcourant toutes les tables
DECLARE CurTables CURSOR
FOR
SELECT DISTINCT TABLE_NAME
FROM INFORMATION_SCHEMA.tables
WHERE TABLE_TYPE = 'BASE TABLE'
AND TABLE_NAME IS NOT NULL
-- en cas d'erreur
IF @@Error <> 0
BEGIN
SET @ErrMsg = 'Erreur dans la recherche de la liste des tables concernées'
GOTO LBL_ERROR
END
-- ouverture du curseur
OPEN CurTables
-- lecture de la première ligne de l'ensemble de résultats
FETCH CurTables INTO @TableName
-- la lecture est-elle correcte ? Oui, on boucle !
WHILE @@Fetch_Status = 0
BEGIN
-- les variables contenant les listes des colonnes sont initialisées à vide
SET @ColumnList1 = ''
SET @ColumnList2 = ''
-- construction des listes
SELECT @ColumnList1 = @ColumnList1 + COLUMN_NAME+', ',
@ColumnList2 = @ColumnList2 + 'COALESCE('+COLUMN_NAME+', '''') + '
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = @tableName
AND DATA_TYPE LIKE '%char%'
-- pas de colonnes cibles pour la recherche, on lit l'enregistrement suivant et on boucle
IF @ColumnList1 = ''
BEGIN
FETCH CurTables INTO @TableName
CONTINUE
END
-- suppression du dernier caractère parasite des listes de colonne
SET @ColumnList1 = SUBSTRING(@ColumnList1, 1, LEN(@ColumnList1) - 1)
SET @ColumnList2 = SUBSTRING(@ColumnList2, 1, LEN(@ColumnList2) - 1)
-- création de la requête de recherche de l'ensemble des occurrences
SET @SQL = 'SELECT ' +@ColumnList1
+' FROM ' +@TableName
+' WHERE ' +@ColumnList2
+' LIKE ''%'+@SearchWord+'%'''
-- exécution de la requête de recherche des occurrences
EXEC(@SQL)
-- lecture de la ligne suivante
FETCH CurTables INTO @TableName
END
-- fermeture du curseur
CLOSE CurTables
-- libération de l'espace mémoire
DEALLOCATE CurTables
PRINT '*** RECHERCHE de l''occurrence '+@SearchWord+ ' dans toute la base terminée ***'
RETURN
-- gestion des erreurs
LBL_ERROR:
RAISERROR (@ErrMsg, 16, 1)Pour mettre à jour des données dans un curseur, il faut le déclarer avec la clause FOR UPDATE et utiliser un ordre UPDATE portant sur la table visée avec une clause WHERE dans laquelle on référence la ligne courante du curseur. Bien entendu la requête située dans le curseur ne peut porter que sur une seule table !
Exemple :
-- déclaration d'un curseur pour mise à jour
DECLARE NomCurseur CURSOR
FOR
SELECT ...
FROM LaTable
...
FOR UPDATE
...
-- exécution de la mise à jour sous curseur
UPDATE LaTable
SET Colonne1 = ..., Colonne2 = ...
WHERE CURRENT OF NomCurseurV. Les triggers▲
Les triggers ou déclencheurs servent à étendre les mécanismes de gestion de l'intégrité référentielle (liens d'héritage par exemple) et permettre le contrôle de saisie. Il s'agit de code déclenché lors de certains événements de la base de données. Un trigger est toujours rattaché à une table. Les événements qui déclenchent un trigger sont :
- l'insertion de données (INSERT) ;
- la suppression de données (DELETE) ;
- la mise à jour (UPDATE).
Ils sont donc déclenchés systématiquement par une requête SQL, après l'exécution de cette requête (AFTER), ou à la place de l'exécution de cette requête (INSTEAD). SQL Server n'implémente pas de trigger BEFORE (avant exécution), mais nous verrons comment le simuler…
En fait le trigger correspond à la programmation des événements des langages d'interfaces graphiques, comme Delphi ou Visual Basic.
V-A. Mise en place d'un trigger▲
On peut définir un trigger par l'interface de l'Entreprise Manager comme par un batch créé, par exemple dans l'analyseur de requêtes.
Et cliquer sur l'icône appropriée « Trigger »

V-B. Syntaxe d'un trigger MS SQL Server 2000▲
CREATE TRIGGER <nom_trigger>
ON <table_ou_vue>
FOR | AFTER | INSTEAD
OF [ INSERT ] [ , ] [ UPDATE ] [ , ] [DELETE]
AS
<code>Cette syntaxe ne tient pas compte de toutes les possibilités.
Emplois typiques :
- gestion d'héritage avec lien d'exclusion ;
- suppression, insertion et mise à jour en cascade ;
- contrôle de validité ;
- respect d'intégrité complexe ;
- formatage de données ;
- archivage automatique ;
- …
V-C. Éléments du langage spécifique aux triggers▲
V-C-1. Pseudotables INSERTED et DELETED▲
Les pseudotables INSERTED et DELETED contiennent les données respectives de l'insertion ou la mise à jour (INSERTED) ou bien de la suppression (DELETED). On peut les utiliser dans des requêtes comme des tables ordinaires. La structure de ces tables est calquée sur la structure de la table sur laquelle repose le trigger.
V-C-2. Fonctions UPDATE et COLUMNS_UPDATED▲
La fonction UPDATE permet de tester si une colonne est visée par un changement de valeur. Elle s'emploie de la manière suivante :
IF [NOT] UPDATE(<colonne>)
BEGIN
<traitement>
ENDElle ne peut être utilisée que dans les triggers de type INSERT et UPDATE.
La fonction COLUMNS_UPDATED() permet d'interroger les colonnes visées par un ordre INSERT ou UPDATE. Elle utilise un masque binaire constitué par le rang ordinal des colonnes de la table. Son emploi syntaxique est le suivant :
IF [NOT] (COLUMNS_UPDATED() & <masque ordinal>) <comparateur> <valeur masque attendue>
BEGIN
<traitement>
ENDUn exemple va nous permettre de préciser le fonctionnement de ce mécanisme.
Soit une table de prospects comme suit :
CREATE TABLE T_PROSPECT
(PSP_ID INTEGER,
PSP_NOM CHAR(32),
PSP_PRENOM VARCHAR(25),
PSP_SAISIE DATETIME,
PSP_TEL VARCHAR(20))Les valeurs ordinales des colonnes de cette table (en fait la position des colonnes lors de la construction de la table) sont les suivantes :
PSP_ID PSP_NOM PSP_PRENOM PSP_SAISIE PSP_TEL
----------- --------------- ------------------ ---------------- --------------------
1 2 3 4 5Vous pouvez d'ailleurs retrouver la valeur de ces positions ordinales par une requête dans les vues de schéma normalisé, comme suit :
|
Sélectionnez |
Sélectionnez |
Dès lors, si vous voulez savoir si l'ajout ou la mise à jour concerne les colonnes PSP_NOM, PSP_PRENOM et PSP_TEL, il faut écrire :
|
Sélectionnez |
pour savoir si au moins l'une des colonnes est concernée. |
|
Sélectionnez |
pour savoir si toutes les colonnes sont concernées. |
Le chiffre 22 s'obtenant par l'addition des puissances de 2 de la position ordinale des colonnes visées, c'est-à-dire :
colonne : PSP_ID PSP_NOM PSP_PRENOM PSP_SAISIE PSP_TEL
---------- ---------- ---------- ---------- ----------
ordinal : 1 2 3 4 5
puissance 2 : 2^0 = 1 2^1 = 2 2^2 = 4 2^3 = 8 2^4 = 16
retenu : non oui oui non oui
valeur : 0 2 4 0 16 = 22 (SOMME de 16 + 4 + 2)V-C-3. Annulation des effets d'un trigger▲
Pour empêcher un trigger de produire son effet, on peut utiliser le ROLLBACK qui dans ce cas peut porter sur la transaction (ROLLBACK TRANSACTION celle qui a déclenché le trigger par exemple) ou uniquement le trigger (ROLLBACK TRIGGER) c'est-à-dire sur les seuls effets de ce dernier.
C'est par ce biais que l'on peut simuler un trigger BEFORE : utiliser un trigger AFTER et le « rollbacker » ou bien utiliser un trigger INSTEAD et insérer quand même dans la table de destination.
Attention : un trigger n'est déclenché qu'une seule fois, même si l'ordre SQL qui l'a déclenché concerne de nombreuses lignes.
V-D. Exemples de triggers▲
Premier exemple - contrôle de validité de format de données. On désire empêcher la saisie de tout numéro de téléphone dans la table client qui possède d'autres caractères que des chiffres (au maximum 20) et des points de séparation :
CREATE TRIGGER E_CLI_INS
ON T_CLIENT
FOR INSERT, UPDATE
AS
-- requête de contrôle avec table d'insertion
SELECT CAST(REPLACE(CLI_TEL, '.', '') as DECIMAL(20))
FROM INSERTED
-- rollback en cas d'erreur
IF @@Error <> 0
ROLLBACK TRANSACTIONLa première tentative de modification :
UPDATE T_CLIENT
SET CLI_TEL = '01 02 03 04 05'
WHERE CLI_ID = 1
Serveur : Msg 8114, Niveau 16, État 5, Procédure E_CLI_INS, Ligne 6
Erreur de conversion du type de données varchar en numeric.provoque une erreur et l'insertion n'a pas lieu.
Tandis que la seconde va bien produire ses effets :
UPDATE T_CLIENT
SET CLI_TEL = '91.92.93.94.95'
WHERE CLI_ID = 1Le seul inconvénient est que cette façon de procéder rejette toutes les lignes insérées ou mises à jour sans accepter celles qui peuvent être correctement formatées.
D'autre part on exécute cette procédure jusqu'au bout, même si la colonne CLI_TEL ne subit aucune modification. Néanmoins ce cas peut être résolu par un traitement spécifique utilisant la fonction UPDATE :
CREATE TRIGGER E_CLI_INS
ON CLIENT
FOR INSERT, UPDATE
AS
-- inutile si pas d'update de la colonne visée
IF NOT UPDATE(CLI_TEL)
RETURN
-- requête de contrôle avec table d'insertion
SELECT CAST(REPLACE(CLI_TEL, '.', '') as DECIMAL(20))
FROM INSERTED
-- rollback en cas d'erreur
IF @@Error <> 0
ROLLBACK TRANSACTIONSecond exemple - L'exercice consiste maintenant à corriger à la volée des saisies incorrectes. Tous les caractères de séparation tels que le tiret ou l'espace d'un numéro de téléphone devront être convertis en point.
CREATE TRIGGER E_CLI_INS
ON CLIENT
FOR UPDATE
AS
-- inutile si pas d'update de la colonne visée
IF NOT UPDATE(CLI_TEL)
RETURN
-- requête de correction avec table d'insertion
UPDATE client
SET cli_tel =
REPLACE(REPLACE(I.CLI_TEL, ' ', '.'), '-', '.')
FROM T_CLIENT C
INNER JOIN INSERTED I
ON C.CLI_ID = I.CLI_ID
-- rollback en cas d'erreur
IF @@Error <> 0
ROLLBACK TRANSACTIONAinsi l'ordre :
UPDATE T_CLIENT
SET CLI_TEL = '88 77-66 55.44'
WHERE CLI_ID = 1donne pour résultat :
cli_id cli_nom Cli_tel
----------- -------------------------------- --------------------
1 DUPONT 88.77.66.55.44et la saisie du numéro de téléphone a été corrigée à la volée et se trouve désormais au format voulu !
Attention : le danger réside dans l'exécution récursive de tels triggers. Comme l'on remet à jour la table à l'intérieur même du trigger, celui-ci est à nouveau déclenché. Le phénomène, s'il n'était pas limité, pourrait provoquer une famine du processus. Il faut donc veiller à le limiter. Dans ce sens SQL Server propose deux garde-fous : le premier, intrinsèque au serveur est de ne jamais dépasser 16 niveaux de récursion. Le second est de proposer une limite plus restrictive à l'aide de la procédure sp_configure, qui permet de modifier la variable nested triggers afin d'étendre les limites d'appel de triggers imbriqués.
De plus pour connaître le niveau d'imbrication du trigger à l'intérieur de ce dernier, il suffit de lancer la fonction TRIGGER_NESTLEVEL() qui renvoie une variable de niveau.
Conseil : il est préférable de ne pas utiliser de triggers imbriqués et donc de laisser le paramètre nested triggers de la configuration à 1.
Bien entendu ou pourrait être beaucoup plus fin dans ce genre de contrôle et analyser puis remplacer, caractère par caractère.
À titre de troisième exemple, nous allons réaliser un tel trigger :
CREATE TRIGGER E_CLI_INS
ON CLIENT
FOR UPDATE
AS
-- inutile si pas d'update de la colonne visée
IF NOT UPDATE(CLI_TEL)
RETURN
-- ouverture d'un curseur sur la table INSERTED
-- pour les téléphones renseignés
DECLARE CurIns CURSOR
FOR
SELECT CLI_ID, CLI_TEL
FROM INSERTED
WHERE CLI_TEL IS NOT NULL
IF @@error <> 0 GOTO LBL_ERROR
-- variable de travail
DECLARE @IdCli int, @TelAvant VARCHAR(20), @TelApres VARCHAR(20),
@car CHAR(1), @i int, @j int
-- ouverture du curseur
OPEN CurIns
IF @@error <> 0 GOTO LBL_ERROR
-- lecture première ligne
FETCH CurIns INTO @IdCli, @TelAvant
-- boucle de lecture
WHILE @@Fetch_Status = 0
BEGIN
-- si vide reboucle immédiatement
IF @TelAvant = ''
BEGIN
FETCH CurIns INTO @IdCli, @TelAvant
CONTINUE
END
-- scrutation de la valeur du téléphone
SET @i = 1
SET @j = 0
SET @TelApres = ''
-- boucle de nettoyage sur tous les caractères
WHILE @i <= LEN(@TelAvant)
BEGIN
-- reprise du caractère d'ordre i
SET @car = SUBSTRING(@TelAvant,@i,1)
-- on ne traite que les caractères de 0 à 9
IF @car = '0' or @car = '1' or @Car = '2' or @Car = '3'
or @car = '4' or @car = '5' or @Car = '6' or @Car = '7'
or @car = '8' or @car = '9'
BEGIN
SET @TelApres = @TelApres + @Car
SET @j = @j + 1
END
SET @i =@i + 1
END
-- si vide reboucle immédiatement
IF @TelApres = ''
BEGIN
FETCH CurIns INTO @IdCli, @TelAvant
CONTINUE
END
-- découpage par tranche de 2 nombres
SET @TelAvant = @TelApres
SET @i = 1
SET @TelApres = ''
-- boucle de découpage
WHILE @i <= LEN(@TelAvant)
BEGIN
SET @car = SUBSTRING(@TelAvant,@i,1)
SET @TelApres = @TelApres + @Car
IF @i % 2 = 0
SET @TelApres = @TelApres + '-'
SET @i =@i + 1
END
-- petit effet de bord si @TelApres se termine par un nombre pair,
-- alors tiret en trop !
IF @j % 2 = 0 -- au passage % est la fonction MODULO dans SQL Server
SET @TelApres = SUBSTRING(@TelApres, 1, LEN(@TelApres)-1)
-- mise à jour si différence
IF @TelAvant <> @TelApres
UPDATE CLIENT
SET CLI_TEL = @TelApres
WHERE CLI_ID = @IdCli
IF @@error <> 0 GOTO LBL_ERROR
FETCH CurIns INTO @IdCli, @TelAvant
END
-- fermeture du curseur et désallocation de l'espace mémoire
CLOSE CurIns
DEALLOCATE CurIns
RETURN
-- rollback en cas d'erreur
LBL_ERROR:
ROLLBACK TRANSACTIONQuatrième exemple - il s'agit maintenant de supprimer en cascade dans différentes tables. Si un client (table T_CLIENT) est supprimé, on doit lui retirer les factures (table T_FACTURE) qui le concernent :
CREATE TRIGGER E_DEL_CLI ON T_CLIENT
FOR DELETE
AS
DELETE FROM T_FACTURE
FROM T_FACTURE F
INNER JOIN DELETED D
ON F.CLI_ID = D.CLI_ID
IF @@ERROR <> 0
ROLLBACK TRANSACTIONBien entendu si vous avez placé de nouveau un trigger permettant de faire de la suppression dans les lignes de facture, alors il sera déclenché et supprimera les occurrences désirées. C'est ce que l'on appelle un déclenchement de triggers en cascade.
Cinquième exemple - la gestion d'un lien d'héritage suppose souvent une exclusion mutuelle entre les fils, nous allons voir comment gérer ce cas de figure. Partons d'une table T_VEHICULE dont la spécialisation provoque deux tables : T_AVION et T_BATEAU. Un véhicule peut être un avion ou bien un bateau, mais pas les deux. Une valeur de clef présente dans T_VEHICULE peut donc se retrouver soit dans T_BATEAU soit dans T_AVION, mais on doit éviter qu'elle se retrouve dans les deux tables.
CREATE TRIGGER E_AVI_INS ON T_AVION
FOR INSERT
AS
DECLARE @rowInUse int, @rows int
-- on regarde si les clefs existent bien dans la table T_VEHICULE
SELECT @RowInUse = COUNT(*)
FROM INSERTED
SELECT @Rows = COUNT(*)
FROM T_VEHICULE V
JOIN INSERTED I
ON V.VHC_ID = I.VHC_ID
IF @RowInUse <> @Rows
BEGIN
ROLLBACK
RAISERROR ('Identifiant de l''héritant inexistant',16,1)
RETURN
END
-- on regarde si les clefs n'existent pas dans la table T_BATEAU
SELECT @Rows = COUNT(*)
FROM T_BATEAU B
JOIN INSERTED I
ON B.VHC_ID = I.VHC_ID
IF @Rows <> 0
BEGIN
ROLLBACK
RAISERROR ('Fils préexistant dans l''entité sœur BATEAU',16,1)
ENDJeu de test :
CREATE TABLE T_VEHICULE
(VHC_ID INT)
CREATE TABLE T_AVION
(VHC_ID INT,
AVI_MARQUE VARCHAR(16),
AVI_MODELE VARCHAR(16))
CREATE TABLE T_BATEAU
(VHC_ID INT,
BTO_NOM VARCHAR(16),
BTO_PORT VARCHAR(16))
INSERT INTO T_VEHICULE VALUES (1)
INSERT INTO T_VEHICULE VALUES (2)
INSERT INTO T_VEHICULE VALUES (3)
INSERT INTO T_BATEAU VALUES (2, 'Penduick', 'Lorient')
INSERT INTO T_BATEAU VALUES (3, 'Titanic', 'Liverpool')
INSERT INTO T_AVION VALUES (1, 'Boeing', '747')
INSERT INTO T_AVION VALUES (3, 'Tupolev', '144')
INSERT INTO T_AVION VALUES (5, 'Airbus', 'A320')Les deux dernières insertions doivent être rejetées : l'id 3 existant dans l'entité frère T_BATEAU et l'id 5 n'existant pas dans l'entité mère.
Mais cet exemple est incomplet, car il faudrait créer ce même type de trigger dans la table T_BATEAU pour vérifier la présence de la clef dans la table père et vérifier son absence dans la table sœur. De même qu'il serait souhaitable de gérer une suppression en cascade pour le père et éventuellement une modification de la valeur de la clef en cascade ! Bref, à vous de jouer…
Sixième exemple - voici maintenant une association d'un genre particulier. L'association 0:0 ! Comment gérer une telle relation ? Comme à mon habitude un exemple concret est plus compréhensible : nous voici avec un texte à indexer mot pour mot, et pour cela nous devons classer chaque mot rencontré dans le texte dans une table T_MOT (MOT_MOT, MOT_REF, MOT_PAGE, MOT_LIGNE, MOT_OFFSET) avec la référence du texte, la page, la ligne et l'offset en nombre de caractères. Mais il serait absurde d'indexer tous les mots. C'est pourquoi une table T_MOT_NOIR(MNR_MOT) de mots indésirables (les mots « noirs ») est créée, et l'on souhaite qu'aucun des mots indexés pour le texte ne soit un mot noir ni qu'aucun mot noir ne se trouve dans les mots indexés. C'est donc bien une relation d'exclusion totale, telle que l'intersection des colonnes MOT_MOT de T_MOT et MNR_MOT de T_MOT_NOIR produise un ensemble vide, ou plus simplement que :
NOT EXISTS(SELECT *
FROM T_MOT MOT
JOIN T_MOT_NOIR MNR
ON MOT.MOT_MOT = MNR.MNR_MOT)Soit toujours évaluée à vrai !
Un tel trigger n'est pas difficile à écrire :
CREATE TRIGGER E_INS_MOT ON T_MOT
FOR INSERT
AS
IF EXISTS(SELECT *
FROM INSERTED I
JOIN T_MOT_NOIR M
ON I.MOT_MOT = M.MNR_MOT)
BEGIN
ROLLBACK
RAISERROR ('Insertion d''un mot noir impossible',16,1)
RETURN
ENDIl faudrait d'ailleurs penser à écrire sa réciproque dans la table T_MOT_NOIR empêchant ainsi l'insertion d'un mot noir préexistant dans la table T_MOT.
On peut bien entendu tester un tel trigger avec le jeu d'essai suivant :
CREATE TABLE T_MOT
(MOT_MOT CHAR(32),
MOT_REF CHAR(8),
MOT_PAGE INT,
MOT_LIGNE INT,
MOT_OFFSET INT)
CREATE TABLE T_MOT_NOIR
(MNR_MOT CHAR(32))
INSERT INTO T_MOT_NOIR VALUES ('LE')
INSERT INTO T_MOT_NOIR VALUES ('LA')
INSERT INTO T_MOT_NOIR VALUES ('LES')
INSERT INTO T_MOT_NOIR VALUES ('UN')
INSERT INTO T_MOT_NOIR VALUES ('UNE')
INSERT INTO T_MOT_NOIR VALUES ('DES')
INSERT INTO T_MOT_NOIR VALUES ('DE')
INSERT INTO T_MOT VALUES('LA', 'BIBLE', 147, 23, 14)
INSERT INTO T_MOT VALUES('VALLÉE', 'BIBLE', 147, 23, 14)
INSERT INTO T_MOT VALUES('DE', 'BIBLE', 147, 23, 14)
INSERT INTO T_MOT VALUES('LA', 'BIBLE', 147, 23, 14)
INSERT INTO T_MOT VALUES('MORT', 'BIBLE', 147, 23, 14)En conclusion nous pouvons dire que les triggers de la version 7 de SQL Server sont assez limités en ne permettant pas de gérer très finement les données. Ils ne fournissent pas un mécanisme pratique et simple lorsque l'on veut par exemple manipuler ligne à ligne et colonne par colonne la validité des données et les rectifier à la volée avant l'insertion définitive. Il semble que la version 2000 de SQL Server respecte plus la norme SQL 2 sur ce point.
Septième exemple - dans une relation d'héritage, comment insérer dans une table fille alors que l'insertion dans la table mère est un prérequis ?
Par exemple, nous avons une table des personnes, une table des clients et une table des employés. Ces tables sont construites de la sorte :
|
Sélectionnez |
|
Sélectionnez |
On ne peut donc pas insérer directement dans T_EMPLOYE_EMP, sauf à utiliser une vue et un trigger INSTEAD OF…
Création de la vue V_EMPLOYEE_EMP :
CREATE VIEW V_EMPLOYEE_EMP
AS
SELECT P.PRS_ID, P.PRS_NOM, P.PRS_PRENOM, E.EMP_MATRICULE
FROM T_PERSONNE_PRS P
INNER JOIN T_EMPLOYE_EMP E
ON P.PRS_ID = E.PRS_IDDès lors on peut créer un trigger d'insertion dans cette vue qui va décomposer les éléments à insérer et injecter les données dans les deux tables :
CREATE TRIGGER TRG_INS_EMPLOYE
ON V_EMPLOYEE_EMP
INSTEAD OF INSERT
AS
BEGIN
INSERT INTO T_PERSONNE_PRS (PRS_NOM, PRS_PRENOM)
SELECT PRS_NOM, PRS_PRENOM
FROM INSERTED
INSERT INTO T_EMPLOYE_EMP (PRS_ID, EMP_MATRICULE)
SELECT @@IDENTITY, EMP_MATRICULE
FROM INSERTED
ENDUtilisation :
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
NOTA : voici le trigger de contrôle d'intégrité des bornes des arborescences exprimées sous forme intervallaire (voir l'article sur ce sujet) :
CREATE TRIGGER E_DEV_UNIQUE_BORNE ON T_DEVELOPPEMENT_DEV
FOR INSERT, UPDATE, DELETE
AS
-- vérification de l'unicité de l'ensemble des bornes (bornes gauches et bornes droites)
IF EXISTS (SELECT COUNT(*), BORNE
FROM (SELECT DEV_BORNE_DROITE AS BORNE
FROM T_DEVELOPPEMENT_DEV
UNION ALL
SELECT DEV_BORNE_GAUCHE AS BORNE
FROM T_DEVELOPPEMENT_DEV) T
GROUP BY BORNE
HAVING COUNT(*) <> 1)
ROLLBACK
-- vérification de la borne maximale comme étant deux fois le nombre de lignes de la table
IF (SELECT MAX(BORNE)
FROM (SELECT DEV_BORNE_DROITE AS BORNE
FROM T_DEVELOPPEMENT_DEV
UNION ALL
SELECT DEV_BORNE_GAUCHE AS BORNE
FROM T_DEVELOPPEMENT_DEV) T) <> (SELECT COUNT(*) * 2
FROM T_DEVELOPPEMENT_DEV)
BEGIN
ROLLBACK
RAISERROR ('Une borne dépasse la valeur maximale attendue', 16, 1)
END
-- vérification de la borne minimale comme étant égale à un
IF (SELECT MIN(BORNE)
FROM (SELECT DEV_BORNE_DROITE AS BORNE
FROM T_DEVELOPPEMENT_DEV
UNION ALL
SELECT DEV_BORNE_GAUCHE AS BORNE
FROM T_DEVELOPPEMENT_DEV) T) <> 1
BEGIN
ROLLBACK
RAISERROR ('Une borne dépasse la valeur minimale attendue', 16, 1)
ENDVI. Cryptage du code, liaison au schéma et recompilation▲
ENCRYPTION indique que SQL Server crypte l'entrée de la table système contenant le texte de l'instruction (procédure, fonction, trigger ou vue). L'utilisation de cet argument permet la confidentialité du code et évite la publication de la procédure dans le cadre de la réplication.
C'est un moyen qui ne garantit pas qu'un utilisateur mal intentionné n'insère des données impropres. Mais cette technique permet de contraindre l'exécution de certains éléments aux seuls possesseurs d'un algorithme de vérification.
Pour comprendre comment mettre en œuvre un tel mécanisme, voici un exemple complet :
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
Voilà comment certains éditeurs de progiciels se protègent des petits malins qui tentent de « pourrir » leur base en y insérant des données sans passer par l'application !
RECOMPILE indique que SQL Server n'utilise pas le cache pour le plan de la procédure (ou de la vue). Elle sera donc recompilée à chaque l'exécution. Cela est conseillé lorsque vous utilisez des valeurs temporaires ou atypiques (aléatoires par exemple).
SCHEMABINDING indique qu'une fonction (vue ou index) est liée aux objets base de données auxquels elle fait référence. La fonction ainsi créée ne pourra être supprimée que si tous les objets base de données auxquels la fonction fait référence sont supprimés préalablement.
VII. ANNEXE BIBLIOGRAPHIQUE▲
Livres :
Transact SQL Programming - Kelvin Kline, Lee Gould & Andrew Zanevsky - O'Reilly
Professionnal SQL Server 7 Programming - Robert Vieira - Wrox
Inside Microsoft SQL Server 7.0 - Ron Soukup, Kalen Delaney, Microsoft Press
SQL Server 7 - Marc Israel - Eyrolles
SQL Server 7.0 - Stephen Wynkoop - Campus Press
SQL Server DBA - Mark Spenik, Orryn Sledge - Campus Press
SQL Server 2000 - Marc Israel - Eyrolles
SQL Server au quotidien Expert - M. F. Garcia, J Reding, E. Whalen, A. Deluca - Microsoft Press
Sites web :
http://www.microsoft.com
https://www.developpez.com/
http://www.multimania.com/lewisdj/sql.htm
http://www.sqlservercentral.com/
http://www.sqlteam.com/