




Préambule▲
Parler du SQL de nos jours comme d'une nouveauté serait une gageure… cependant, ne faut-il pas voir en cet indestructible langage, une tentative un peu tardive, mais souhaitable, au travers des différents middleware disponibles, de standardisation d'un mode d'interrogation des données ?
Force est de constater que même les bases de données objet et le web se mettent au SQL. Le poids du passé sans doute…
Mais alors que faire ? Squeezer SQL ou s'en accommoder ?
Il y a plus d'une vingtaine d'années, le COBOL était, disait-on, assuré d'une mort certaine et à court terme. Aujourd'hui le défunt est encore haletant bien que défraîchi. En sera-t-il de même pour le SQL ? Tout le laisse supposer !
1. SQL un langage ?▲
Vous trouverez des compléments d'information sur le sujet aux pages 29 à 51 de l'ouvrage « SQL », collection « La Référence », Campus Press éditeur.
Et d'abord, SQL est-il un vrai langage ?(1)
Si l'on doit accepter ce mot au sens informatique du terme, il semble difficile de dire oui tant SQL est loin de la structure et des possibilités d'un langage de programmation courant. Point de variable, point de procédure ou de fonction… Pourtant il s'agit bien de former des phrases qui seront compilées afin d'exécuter des traitements.
Même si SQL s'est doté au fil du temps d'extensions, comme la possibilité de paramétrer les requêtes, il y a des lacunes importantes qui sont autant de freins à sa pénétration. Par exemple SQL ne sait être récursif alors que ce mode d'exécution est nécessaire pour résoudre une frange importante de problèmes, notamment ceux pour traiter les arbres ou les graphes.
En fait SQL est un langage de type « déclaratif ». On spécifie ce que l'on veut obtenir ou faire et c'est la machine qui décide comment elle doit l'exécuter. Pour certains, SQL est perçu comme un pis-aller tandis que d'autres préfèrent l'éviter ou retarder au plus l'inéluctable moment où son apparition sera incontournable.
La différence fondamentale entre les langages courants comme C ou Pascal, qui sont des langages procéduraux, réside dans le fait qu'avec ces derniers, vous indiquez l'ensemble des instructions nécessaires à traiter un problème. Vous gardez ainsi une certaine maîtrise sur le cycle d'exécution et l'enchaînement des différentes tâches d'un programme vous est parfaitement connu. En revanche, dans SQL vous n'avez, et d'ailleurs ne devez, pas avoir la moindre idée de comment la machine exécute votre demande, ni même dans quel ordre elle décompose le traitement de la requête en différentes tâches, ni d'ailleurs même comment elle les synchronise.
Lors d'une extraction concernant plusieurs tables, le moteur relationnel pourrait parfaitement lancer plusieurs traitements en parallèle pour extraire les données de chacune des tables, puis effectuer les jointures des différentes tables résultantes en fonction de l'ordre de terminaison des extractions…
C'est pourquoi les moteurs relationnels incluent des modules d'optimisation logique et parfois statistique.
Ainsi un optimiseur logique préférera traiter en premier les clauses excluant de la réponse un maximum de données, tandis qu'un optimiseur statistique commencera par traiter les tables de plus faible volume.
Exemple :
Soit une table contenant le personnel de la société " VIVE LE SQL " et une autre contenant
les salaires mensuels desdits employés.
" VIVE LE SQL " compte 1000 employés soit autant de lignes dans la table du personnel, et
la moyenne de durée d'emploi étant de 6 ans, la table des salaires compte donc environ
72 000 lignes.
Soit la requête suivante : rechercher les employés dont le nom commence par Z ou qui sont
domiciliés à Trifouilly et qui ont eu au moins un salaire supérieur à 50 000 francs.
* Un optimiseur logique commencera immanquablement par traiter la table des salaires
puis celle des employés.
* Un optimiseur statistique commencera par traiter les employés puis les salaires.
Nous pauvres humains, aurions immédiatement traité la table des salaires, car à ce niveau
d'émoluments il ne devrait pas y avoir grand monde dans la table des salariés…
Eh bien, croyez-moi ou pas… certains optimiseurs statistiques auraient eu la même appréciation !
En effet les plus performants ne se contentent pas seulement de conserver le nombre de lignes ou
le volume des données d'une table, mais aussi les moyennes, médianes, maximums et minimums de
certaines colonnes, voire le nombre de valeurs distinctes (indice de dispersion) ainsi que
le nombre d'occurrences des valeurs les plus fréquentes, notamment pour les colonnes pourvues
d'index... C'est le cas en particulier du SGBDR INGRES.Bref, pour conclure cette brève présentation de SQL, nous pouvons affirmer que, malgré ses défauts, et en attendant un futur langage objet pour l'interrogation des données, incluant tous les mécanismes dynamiques et bien entendu la récursivité , il nous faut continuer à utiliser sagement SQL, du mieux que nous pouvons, en rendant ainsi hommage a quelques-uns de ses créateurs…
2. SQL une histoire…▲
Nous sommes en 1970. Le docteur Codd, un chercheur d'IBM à San José, propose une nouvelle manière d'aborder le traitement automatique de l'information, se basant sur la théorie de l'algèbre relationnelle (théorie des ensembles et logique des prédicats). Cette proposition est faite afin de garantir une plus grande indépendance entre la théorie et l'implémentation physique des données au sein des machines. C'est ainsi que naîtront, vers la fin des années 70, les premières applications basées sur la proposition de Ted Codd, connues de nos jours sous l'acronyme SGBDR (signifiant Système de Gestion de Bases de Données Relationnelles).
Dans cette même période, Peter CHEN tente une approche pragmatique et conceptuelle du traitement automatique des données en proposant le modèle Entité-Association comme outil de modélisation. Nous sommes en 1976.
En parallèle, différents chercheurs travaillent à réaliser ce que seront les SGBDR d'aujourd'hui : citons entre autres l'équipe de Gene Wong à l'université de Berkeley qui entame le projet INGRES en 1972, et en 1975 propose le langage QUEL comme outil d'interrogation des données (aucun ordre de mise à jour des données n'y figure).
De même à Noël 1974 démarre chez IBM le projet qui portera le nom de System R, et donnera comme langage d'interrogation SEQUEL (Structured English QUEry Langage) en 1976.
Lors d'une conférence internationale à Stockolm (IFIP Congres), Larry Ellison, dirigeant d'une petite entreprise appelée Software Development Laboratories entend parler du projet et du langage d'interrogation et de manipulation des données. Il rentre en contact avec les chercheurs d'IBM. Quelques années après, Larry Ellison sort le premier SGBDR commercialisé et change le nom de sa société. Elle s'appellera désormais Oracle…
IBM, pour sa part, sortira une version commerciale bien après celle d'Oracle, ce qui fera dire à l'un des responsables du projet que « cela vous montre combien de temps il faut à IBM pour faire n'importe quoi… ». Finalement la première installation de System R est réalisée en 1977 chez Pratt & Whitney, et déjà les commandes du langage d'interrogation se sont étoffées de quelques judicieuses techniques préconisées par Oracle, comme la gestion des curseurs.
Au même moment apparaissent d'autres langages d'interrogation comme QBE de Zloof (IBM 1977) repris pour Paradox par Ansa Software, ou REQUEST de Fred Damerau (basé sur le langage naturel) ou encore RENDEZ VOUS (1974) de l'équipe de Ted Codd ainsi que SQUARE (Boyce 1975).
Mais le point critique du langage SEQUEL porte sur l'implémentation du… rien ! Ou plutôt devrais-je dire du nul !!!
Finalement la première réalisation connue sous le nom de SQL (82) voit le jour après l'arrivée de DB2, une avancée significative du System R d'IBM datant de mars 1979.
On peut donc dire que le langage SQL est né en 1979, mais baptisé SQL en 1982. En définitive SQL a vingt ans, et, comme le dit la chanson… on n'a pas tous les jours 20 ans…
Et 20 ans pour les uns ça suffit !, pour les autres ça se fête…
2-1. SQL une norme▲
Notons que SQL sera normalisé à quatre reprises : 1986 (SQL 86 - ANSI), 1989 (ISO et ANSI) et 1992 (SQL 2 - ISO et ANSI) et enfin 1999 (SQL:1999 - ISO) souvent appelé à tort (y compris par moi-même !) SQL 3. À ce jour, aucun SGBDR n'a implémenté la totalité des spécifications de la norme actuellement en vigueur. Mais je dois dire que le simple (?) SELECT est argumenté de quelque 300 pages de spécifications syntaxiques dans le dernier document normatif…
Néanmoins, la version SQL 2 (1992) est la version vers laquelle toutes les implémentations tendent. C'est pourquoi nous nous baserons sur SQL 2.
À noter, la future norme SQL:2003, sortira en juillet 2003.
2-2. SQL un standard▲
Même si SQL est considéré comme le standard de toutes les bases de données relationnelles et commercialisées, il n'en reste pas moins vrai que chaque éditeur tend à développer son propre dialecte, c'est-à-dire à rajouter des éléments hors de la norme. Soit fonctionnellement identiques, mais de syntaxe différentes (le LIKE d'Access en est l'exemple le plus stupide !) soit fonctionnellement nouveau (le CONNECT BY d'Oracle pour la récursivité par exemple). Il est alors très difficile de porter une base de données SQL d'un serveur à l'autre. C'est un moindre mal si l'on a respecté au maximum la norme, mais il est de notoriété absolue que lorsque l'élément normatif est présent dans le SGBDR avec un élément spécifique ce sera toujours l'élément spécifique qui sera proposé et documenté au détriment de la norme !
Exemple, la fonction CURRENT_TIMESTAMP, bien présente dans MS SQL Server, n'est pas spécifié dans la liste des fonctions temporelles de l'aide en ligne !!!
|
|
|

De plus, le plus petit dénominateur commun entre les quatre poids lourds de l'édition que sont Oracle, Sybase (ASE), Microsoft (SQL Server) et IBM (DB2) est tel qu'il est franchement impossible de réaliser la moindre base de données compatible entre ces différentes implémentations, sauf à n'y stocker que des données numériques !!!
Pour chaque SGBDR, on parle alors de dialecte. Il y a donc le dialecte SQL d'Oracle, le dialecte SQL de Sybase, etc.
Dans un excellent article, Peter Gulutzan fait le point sur l'essentiel de ce qui est normatif chez les principaux éditeurs de SGBDR : http://www.dbazine.com/gulutzan3.html
Et fustige leur comportement, similaire à celui des constructeurs d'ordinateurs en matière d'OS UNIX incompatibles et qui maintenant pleurent à chaudes larmes devant le rouleau compresseur « Linux » !
Une autre étude, par Michael M. Gorman montre que la volonté de ces éditeurs de SGBDR et leurs intérêts mercantiles à courte vue sont incompatibles avec le respect des standards…
À lire donc : http://www.tdan.com/i016hy01.htm
Nous avons aussi démontré qu'une même table créée sur différents SGBDR avec les mêmes données n'avait pas forcément le même comportement au regard du simple SELECT du fait des jeux de caractères et collations par défaut. Or tous les SGBDR ne sont pas paramétrables à ce niveau et ceux qui le sont, ne présentent pas en général les mêmes offres en cette matière.
À lire : Une question de caractères…
Enfin, pour tous ceux qui veulent connaître la norme comparée au dialecte de leur SGBDR favori, il suffit de lire le tableau de comparaison des fonctions de SQL : Toutes les fonctions de SQL
3. Remarques préliminaires sur les SGBDR▲
Avant tout, nous supposerons connues les notions de « bases de données », « table », « colonne », « ligne », « clef », « index », « intégrité référentielle » et « transaction », même si ces termes, et les mécanismes qu'ils induisent seront plus amplement décrits au fur et à mesure de votre lecture.
Voici quelques points qu'il convient d'avoir à l'esprit lorsque l'on travaille sur des bases de données.
- Il existe une grande indépendance entre la couche abstraite que constitue le SGBDR et la couche physique que sont le ou les fichiers constituant une base de données. En l'occurrence il est déraisonnable de croire que les fichiers sont arrangés dans l'ordre des colonnes lors de la création des tables et que les données sont rangées dans l'ordre de leur insertion ou de la valeur de la clef.
- Il n'existe pas d'ordre spécifique pour les tables dans une base ou pour les colonnes dans une table, même si le SGBDR en donne l'apparence en renvoyant assez généralement l'ordre établi lors de la création (notamment pour les colonnes). Par conséquent les tables, colonnes, index… doivent être repérés par leur nom et uniquement par cet identifiant.
- Les données sont systématiquement présentées sous forme de tables, et cela quel que soit le résultat attendu. Pour autant la table constituée par la réponse n'est pas forcément une table persistante, ce qui signifie que si vous voulez conserver les données d'une requête pour en faire usage ultérieurement, il faudra créer un objet dans la base (table ou vue) afin d'y placer les données extraites.
- La logique sous-jacente aux bases de données repose sur l'algèbre relationnelle elle-même basée sur la théorie des ensembles. Il convient donc de penser en termes d'ensemble et de logique et non en termes d'opération de nature atomique. À ce sujet, il est bon de se rappeler l'usage des patates (ou diagrammes de Wen) lorsque l'on « sèche » sur une requête.
- Du fait de l'existence d'optimiseurs, la manière d'écrire une requête à peu d'influence en général sur la qualité de son exécution. Dans un premier temps il vaut mieux se consacrer à la résolution du problème que d'essayer de savoir si la clause « bidule » est plus gourmande en ressources lors de son exécution que la clause « truc ». Néanmoins l'optimisation de l'écriture des requêtes sera abordée dans un article de la série.
4. Les subdivisions du SQL▲
Le SQL comporte cinq grandes parties, qui permettent : la définition des éléments d'une base de données (tables, colonnes, clefs, index, contraintes…), la manipulation des données (insertion, suppression, modification, extraction…), la gestion des droits d'accès aux données (acquisition et révocation des droits), la gestion des transactions et enfin le SQL intégré. La plupart du temps, dans les bases de données « fichier » (dBase, Paradox…) le SQL n'existe qu'au niveau de la manipulation des données, et ce sont d'autres ordres spécifiques qu'il faudra utiliser pour créer des bases, des tables, des index ou gérer des droits d'accès.
Certains auteurs ne considèrent que trois subdivisions incluant la gestion des transactions au sein de la manipulation des données… Cependant ce serait restreindre les fonctionnalités de certains SGBDR capables de gérer des transactions comprenant aussi des ordres SQL de type définition des données ou encore gestion des droits d'accès !
4-1. DDL : « Data Definition Language »▲
C'est la partie du SQL qui permet de créer des bases de données, des tables, des index, des contraintes…
Elle possède les commandes de base suivantes :
CREATE, ALTER, DROPQui permettent respectivement de créer, modifier, supprimer un élément de la base.
4-2. DML : « Data Manipulation Language »▲
C'est la partie du SQL qui s'occupe de traiter les données.
Elle comporte les commandes de base suivantes :
INSERT, UPDATE, DELETE, SELECTQui permettent respectivement d'insérer, de modifier de supprimer et d'extraire des données.
4-3. DCL : « Data Control Language »▲
C'est la partie du SQL qui s'occupe de gérer les droits d'accès aux tables.
Elle comporte les commandes de base suivantes :
GRANT, REVOKEQui permettent respectivement d'attribuer et de révoquer des droits.
4-4. TCL : « Transaction Control Language »▲
C'est la partie du SQL chargée de contrôler la bonne exécution des transactions.
Elle comporte les commandes de base suivantes :
SET TRANSACTION, COMMIT, ROLLBACKQui permettent de gérer les propriétés ACID des transactions.
4-5. SQL intégré : « Embedded SQL »▲
Il s'agit d'éléments procéduraux que l'on intègre à un langage hôte :
SET, DECLARE CURSOR, OPEN, FETCH...Le terme « ACID », ne fait pas référence, loin s'en faut au LSD, mais plus basiquement aux termes suivants :
A - Atomicité : une transaction s'effectue ou pas (tout ou rien), il n'y a pas de demi-mesure. Par exemple l'augmentation des prix de 10 % de tous les articles d'une table des produits ne saurait être effectuée partiellement, même si le système connaît une panne en cours d'exécution de la requête.
C - Cohérence : le résultat ou les changements induits par une transaction doivent impérativement préserver la cohérence de la base de données. Par exemple lors d'une fusion de sociétés, la concaténation des tables des clients des différentes entités ne peut entraîner la présence de plusieurs clients ayant le même identifiant. Il faudra résoudre les conflits portant sur le numéro de client avant d'opérer l'union des deux tables.
I - Isolation : les transactions sont isolées les unes des autres. Par exemple la mise à jour des prix des articles ne sera visible pour d'autres transactions que si ces dernières ont démarré après la validation de la transaction de mise à jour des données. Il n'y aura donc pas de vue partielle des données pendant toute la durée de la transaction de mise à jour.
D - Durabilité : une fois validée, une transaction doit perdurer, c'est-à-dire que les données sont persistantes même s'il s'ensuit une défaillance dans le système. Par exemple, dès lors qu'une transaction a été validée, comme la mise à jour des prix, les données modifiées doivent être physiquement stockées pour qu'en cas de panne, ces données soient conservées dans l'état où elles ont été spécifiées à la fin de la transaction.
Voici ce que disent, Sébastien BRAU, Christian CHANE-NAM, Louis-Laurent ANTIGNY, Gilberto DE VASCONCELOS sur les propriétés ACID d'un SGBDR :
Atomicité : si tout se passe correctement, les actions de la transaction sont toutes validées, sinon
on retourne à l'état initial.
L'unité de travail est indivisible. Une transaction ne peut être partiellement effectuée.
Cohérence : le passage de l'état initial à l'état final respecte la cohérence de la base.
Isolation : les effets de la transaction ne sont pas perceptibles tant que celle-ci n'est pas terminée.
Une transaction n'est pas affectée par le traitement des autres transactions.
Durabilité : les effets de la transaction sont durables.
Rendre transparentes la complexité et la localisation des traitements et des données, tout en assurant
un bon niveau de performance, tels sont aujourd'hui les demandes des entreprises et les nouveaux
critères sur lesquels s'arrêtent leurs choix.Pour assurer l'ensemble de ces fonctions de base, les SGBDR utilisent le principe de la journalisation : un fichier dit « journal », historise toutes les transactions que les utilisateurs effectuent et surtout leur état : en cours, validées ou annulées. Une mise à jour n'est réellement effectuée que si la transaction aboutit. Ainsi en cas de panne du système, une relecture du journal permet de resynchroniser la base de données pour assurer sa cohérence. De même en cas de « RollBack », les instructions de la transaction sont lues « à l'envers » afin de rétablir les données telles qu'elles devaient être à l'origine de la transaction.
5. Implémentation physique des SGBDR▲
Il existe à ce jour, deux types courants d'implémentation physique des SGBD relationnels. Ceux qui utilisent un service de fichiers associés à un protocole de réseau afin d'accéder aux données et ceux qui utilisent une application centralisée dite serveur de données. Nous les appellerons SGBDR « fichier » et SGBDR client/serveur (ou C/S en abrégé).
5-1. SGBDR « fichier »▲
Le service est très simple à réaliser : il s'agit de placer dans une unité de stockage partagée (en général un disque d'un serveur de réseau) un ou plusieurs fichiers partageables. Un programme présent sur chaque poste de travail assure l'interface pour traiter les ordres SQL ainsi que le va-et-vient des fichiers de données sur le réseau.
Il convient de préférer des SGBDR à forte granularité au niveau des fichiers. En effet plus il y a de fichiers pour une même base de données et moins la requête encombrera le réseau, puisque seuls les fichiers nécessaires à la requête seront véhiculés sur le réseau.
Ces SGBDR « fichier » ne proposent en général pas le contrôle des transactions, et peu fréquemment le DDL et le DCL. Ils sont, par conséquent, généralement peu ACID !
Les plus connus sont ceux qui se reposent sur le modèle XBase. Citons parmi les principaux SGBDR « fichier » : dBase, Paradox, Foxpro, BTrieve, MySQL… Généralement basés sur le modèle ISAM de fichiers séquentiels indexés.
Avantage : simplicité du fonctionnement, coût peu élevé, voire gratuit, format des fichiers ouverts, administration quasi inexistante.
Inconvénient : faible capacité de stockage (quoique certains, comme Paradox, acceptent 2 Go de données par table !!!), encombrement du réseau, rarement de gestion des transactions, faible nombre d'utilisateurs, faible robustesse, cohérence des données moindre.
Access se distingue du lot en étant assez proche d'un serveur SQL : pour une base de données, un seul fichier et un TCL. Mais cela présente plus d'inconvénients que d'avantages : en effet pour interroger une petite table de quelques enregistrements au sein de base de données de 500 Mo, il faut rapporter sur le poste client, la totalité du fichier de la base de données… Un non-sens absolu, que Microsoft pallie en intimant à ses utilisateurs de passer à SQL Server dès que le nombre d'utilisateurs dépasse 10 !
5-2. SGBDR « Client/Serveur »▲
Le service consiste à faire tourner sur un serveur physique, un moteur qui assure une relative indépendance entre les données et les demandes de traitement de l'information venant des différentes applications : un poste client envoie à l'aide d'un protocole de réseau, un ordre SQL (une série de trames réseau), qui est exécuté, le moteur renvoie les données. De plus le SGBDR assure des fonctions de gestions d'utilisateurs de manière indépendante aux droits gérés par l'OS.
À ce niveau il convient de préférer des SGBDR C/S qui pratiquent : le verrouillage d'enregistrement plutôt que le verrouillage de page (évitez donc SQL Server…), et ceux qui tournent sur de nombreuses plateformes système (Oracle, Sybase…). Enfin certains SGBDR sont livrés avec des outils de sauvegarde et restauration.
Les SGBDR « C/S » proposent en général la totalité des services du SQL (contrôle des transactions, DDL et DCL). Ils sont, par conséquent, pratiquement tous ACID. Enfin de plus en plus de SGBD orientés objet voient le jour. Dans ce dernier cas, ils intègrent la plupart du temps le SQL en plus d'un langage spécifique d'interrogation basé sur le concept objet (O², ObjectStore, Objectivity, Ontos, Poet, Versant, ORION,GEMSTONE…)
Les serveurs SQL C/S les plus connus sont : Oracle, Sybase, Informix, DB2, SQL Server, Ingres, InterBase, SQL Base…
Avantage : grande capacité de stockage, gestion de la concurrence dans un SI à grand nombre d'utilisateurs, haut niveau de paramétrage, meilleure répartition de la charge du système, indépendance vis-à-vis de l'OS, gestion des transactions, robustesse, cohérence des données importante. Possibilité de montée en charge très importante en fonction des types de plateformes supportées.
Inconvénient : lourdeur dans le cas de solution « monoposte », complexité du fonctionnement, coût élevé des licences, administration importante, nécessité de machines puissantes.
NOTA : Pour en savoir plus sur le sujet, lire l'étude comparative sur les SGBDR à base de fichiers et ceux utilisant un moteur relationnel, intitulée Quand faut-il investir sur le client/serveur ? On y discute aussi des différents modes de verrouillage…
6. Type de données▲
Dernier point que nous allons aborder dans ce premier article, les différents types de données spécifiés par SQL et leur disponibilité sur les cinq systèmes que nous avons retenus pour notre étude.
Selon la norme ISO de SQL 92
6-1. Types alphanumériques▲
CHARACTER (ou CHAR) : valeurs alpha de longueur fixe
CHARACTER VARYING (ou VARCHAR ou CHAR VARYING) : valeur alpha de longueur maximale fixée
Ces types de données sont codés sur 2 octets (EBCDIC ou ASCII) et on doit spécifier la longueur de la chaine.
Exemple :
NOM_CLIENT CHAR(32)
OBSERVATIONS VARCHAR(32000)NATIONAL CHARACTER (ou NCHAR ou NATIONAL CHAR) : valeurs alpha de longueur fixe
NATIONAL CHARACTER VARYING (ou NCHAR VARYING ou NATIONAL CHAR VARYING) : valeur alpha de longueur maximale fixée sur le jeu de caractères du pays
Ces types de données sont codés sur 4 octets (UNICODE) et on doit spécifier la longueur de la chaine.
Exemple :
NOM_CLIENT NCHAR(32)
OBSERVATIONS NCHAR VARYING(32000)Nota : la valeur maximale de la longueur est fonction du SGBDR.
6-2. Types numériques▲
NUMERIC (ou DECIMAL ou DEC) : nombre décimal à représentation exacte à échelle et précision facultatives
INTEGER (ou INT): entier long
SMALLINT : entier court
FLOAT : réel à virgule flottante dont la représentation est binaire à échelle et précision obligatoire
REAL : réel à virgule flottante dont la représentation est binaire, de faible précision
DOUBLE PRÉCISION : réel à virgule flottante dont la représentation est binaire, de grande précision
BIT : chaine de bits de longueur fixe
BIT VARYING : chaine de bits de longueur maximale
Pour les types réels NUMERIC, DECIMAL, DEC et FLOAT, on doit spécifier le nombre de chiffres significatifs et la précision des décimales après la virgule.
Exemple :
NUMERIC (15,2)signifie que le nombre comportera au plus 15 chiffres significatifs dont deux décimales.
ATTENTION : le choix entre le type DECIMAL (représentation exacte) et le type FLOAT ou REAL (représentation binaire) doit être dicté par des considérations fonctionnelles. En effet, pour des calculs comptables il est indispensable d'utiliser le type DECIMAL exempt, dans les calculs de toute fraction parasite capable d'entraîner des erreurs d'arrondis. En fait le type DECIMAL se comporte comme un entier dans lequel la virgule n'est qu'une représentation positionnelle. En revanche pour du calcul scientifique, on préférera utiliser le type FLOAT, plus rapide dans les calculs.
Exemple :
SELECT CAST(3.14159 AS FLOAT (16,4)) AS PI_FLT, CAST(3.14159 AS DECIMAL (16,4)) AS PI_DECPI_FLT PI_DEC
----------------------------------------------------- ------------------
3.1415899999999999 3.1416NOTA : on peut utiliser une notation particulière pour forcer le typage implicite. Il s'agit d'une lettre précédant la chaine à transtyper. Les lettres autorisées, sont : N (pour Unicode), B pour binary (chaine de 0 et 1) et X pour binary (chaine hexadécimale constituée de caractères allant de 0 à F).
Exemple :
SELECT N'toto' AS MY_NCHAR, B'01010111' AS MY_BINARY_BIT, X'F0A1' AS MY_BINARY_HEX6-3. Types temporels▲
DATE : date du calendrier grégorien
TIME : temps sur 24 heures
TIMESTAMP : combiné date temps
INTERVAL : intervalle de date / temps
Rappelons que les valeurs stockées doivent avoir pour base le calendrier grégorien(2) qui est en usage depuis 1582, date à laquelle il a remplacé le calendrier julien. En matière de temps, la synchronisation s'effectue par rapport au TU ou temps universel (UTC : Universal Time Coodinated) anciennement GMT (Greenwich Mean Time) l'ensemble ayant été mis en place, lors la conférence de Washington DC en 1884, pour éviter que les chemins de chemins ne se télescopent.
ATTENTION : Le standard ISO adopté pour le SQL repose sur le format AAAA-MM-JJ. Il est ainsi valable jusqu'en l'an 9999… où AAAA est l'année sur quatre chiffres, MM le mois sur deux chiffres, et JJ le jour. Pour l'heure le format ISO est hh:mm:ss.nnn (n étant le nombre de millisecondes)
Exemple :
1999-03-26 22:54:28.123est le 26 mars 1999 à 22 h 54 m, 28 s et 123 millisecondes.
Mais peu de moteurs de requêtes l'implémentent de manière aussi formelle…
Le type INTERVAL est très particulier. Il est malheureusement rarement présent dans les SGBDR.
Sa définition se fait à l'aide de la syntaxe suivante :
INTERVAL précision_min TO [précision_max]où précision_min et précision_max peuvent prendre les valeurs :
{YEAR | MONTH | DAY | HOUR | MINUTE | SECOND}avec la condition supplémentaire suivante : précision_max ne peut être qu'une mesure temporelle plus fine que précision_min.
Exemple :
JOURS INTERVAL DAY
TRIMESTRE INTERVAL MONTH TO DAY
TACHE INTERVAL HOUR TO SECOND
DUREE_FILM INTERVAL MINUTEATTENTION
Veuillez noter que les réceptacles de valeurs temporelles ainsi créés par le type INTERVAL sont des entiers, et que leur valeur est contrainte lorsqu'ils sont définis avec une précision maximum sur tous les éléments les composant sauf le premier. Ainsi, dans une colonne définie par le type INTERVAL MONTH TO DAY, on pourra stocker une valeur de 48 mois et 31 jours, mais pas une valeur de 48 mois et 32 jours. De même dans un INTERVAL HOUR TO SECOND la valeur en heures est illimitée, mais celle en minutes et en secondes ne peut dépasser 59.
6-4. Types « BLOBS » (hors du standard SQL 2)▲
Longueur maximale prédéterminée, donnée de type binaire, texte long voire formaté, structure interprétable directement par le SGBDR ou indirectement par add-on externes (image, son, vidéo…). Attention : ne sont pas normalisés !
On trouve souvent les éléments suivants :
TEXT : suite longue de caractères de longueur indéterminée
IMAGE : stockage d'image dans un format déterminé
OLE : stockage d'objet OLE (Windows)
6-5. Autres types courants, hors norme SQL 92▲
BOOLEAN (ou LOGICAL) : curieusement le type logique (ou encore booléen) est absent de la norme. On peut en comprendre aisément les raisons… La pure logique booléenne ne saurait être respectée à cause de la possibilité offerte par SQL de gérer les valeurs nulles. On aurait donc affaire à une logique dite « 3 états » qui n'aurait plus rien de l'algèbre booléenne. La norme passe donc sous silence, et à bon escient ce problème et laisse à chaque éditeur de SGBDR le soin de concevoir ou non un booléen « à sa manière ».
On peut par exemple implémenter un tel type de données, en utilisant une colonne de type caractère longueur 1, non nul et restreint à deux valeurs (V / F ou encore T / F).
MONEY : est un sous-type du type NUMERIC avec une échelle maximale et une précision de deux chiffres après la virgule.
BYTES (ou BINARY) : Type binaire (octets) de longueur devant être précisée. Permet par exemple le stockage d'un code-barre.
AUTOINC : entier à incrément automatique par trigger.
6-6. Les domaines, ou la création de types spécifiques▲
Il est possible de créer de nouveaux types de données à partir de types préexistants en utilisant la notion de DOMAINE.
Dans ce cas, avant d'utiliser un domaine, il faut le recenser dans la base à l'aide d'un ordre CREATE :
CREATE DOMAIN nom_du_domaine AS type_de_donnéeExemple :
CREATE DOMAIN DOM_CODE_POSTAL AS CHAR(5)Dès lors il ne suffira plus que d'utiliser ce type à la place de CHAR(5).
L'utilisation des domaines possède de nombreux avantages :
- ils peuvent faire l'objet de contraintes globales ;
- ils peuvent être modifiés (ce qui modifie le type de toutes les colonnes de table utilisant ce domaine d'un seul coup !).
Exemple :
ALTER DOMAINE DOM_CODE_POSTAL
ADD CONSTRAINT MIN_CP CHECK (VALUE >= '01000')Dans ce cas le code postal saisi devra au minimum s'écrire 01000. On pourrait y ajouter une contrainte maximum de forme (VALUE <= '99999').
NOTA : certains SGBDR n'ont pas implémenté l'ordre CREATE DOMAIN. C'est le cas par exemple de SQL Server. Ainsi, il faut aller « trifouiller » les tables système pour insérer un nouveau type de donnée à l'aide de commandes « barbares » propres au SGBDR.
Exemple (SQL Server) :
sp_addtype DOM_CODE_POSTAL, 'CHAR(5)', 'null'Un des immenses avantages de passer par des définitions de domaines plutôt que d'utiliser directement des types de données est que les domaines induisent une bonne normalisation de la conception du schéma des données.
Pour ma part j'utilise souvent le jeu de domaines suivant :
D_KEY_INTEGER entier
D_TRIGRAMME char(3)
D_CODE char(8)
D_LIBELLE_COURT varchar(16)
D_LIBELLE varchar(32)
D_LIBELLE_LONG varchar(64)
D_TITRE varchar(128)
D_DATE date
D_TEMPS dateTime
D_TEXTE text
D_ADRESSE varchar(32) /* spécifique aux adresses */
D_BOOLEEN smallint(1) /* contraint à 0 ou 1, valeur par défaut 0 */
D_MONNAIE
D_ENTIER_COURT
D_ENTIER_LONG
D_REEL
...7. Contraintes de données▲
Dans la plupart des SGBDR, il est possible de contraindre le formatage des données à l'aide de différents mécanismes.
Parmi les contraintes les plus courantes au sein des données de la table on trouve :
- valeur minimum ;
- valeur maximum ;
- valeur par défaut ;
- valeur obligatoire ;
- valeur unique ;
- clef primaire ;
- index secondaire ;
- format ou modèle (par exemple trois caractères majuscules suivis de trois caractères numériques) ;
- table de référence (recopie d'une valeur d'une table dans un champ d'une autre table en sélectionnant par la clef) aussi appelé CHECK en SQL ;
- liste de choix.
Enfin entre deux tables liées, il est souvent nécessaire de définir une contrainte de référence qui oblige un enregistrement référencé par sa clef à être présent ou détruit en même temps que l'enregistrement visé est modifié, inséré ou supprimé. Ce mécanisme est appelé INTÉGRITÉ RÉFÉRENTIELLE.
Exemple : Soit une base de données contenant deux tables : CLIENT et COMMANDE dotées des structures suivantes…
CLIENT :
|
NO_CLIENT |
INTEGER |
|
NOM_CLIENT |
CHAR(32) |
COMMANDE :
|
REF_COMMANDE |
CHAR(16) |
|
DATE_COMMANDE |
DATE |
|
MONTANT_COMMANDE |
MONEY |
|
NO_CLIENT |
INTEGER |
Et dans lesquelles on trouve les valeurs suivantes :
CLIENT :
|
143 |
DUPONT |
|
212 |
MARTIN |
|
823 |
DUBOIS |
COMMANDE :
|
1999-11 |
11/7/1999 |
1235.52 |
212 |
|
1999-12 |
17/7/1999 |
45234.63 |
823 |
|
1999-13 |
18/7/1999 |
5485.23 |
142 |
|
1999-14 |
21/7/1999 |
11542.23 |
212 |
Si l'on détruit la ligne de la table CLIENT concernant le n° 212 (MARTIN) alors les factures 1999-11 et 1999-14 deviennent orphelines. Il faut donc interdire la suppression de ce client tant que des références de ce client persistent dans la table COMMANDE.
De même, le changement de la valeur de la clef NO_CLIENT ferait perdre la valeur de référence du lien entre les deux tables, à moins que la modification ne soit répercutée dans la table fille.
NOTA : on parle alors de tables en relation mère / fille ou encore maître / esclave.
8. Triggers et procédures stockées▲
En ce qui concerne les SGBDR en architecture client / serveur, il est courant de trouver des mécanismes de triggers (permettant d'exécuter du code en fonction d'un événement survenant dans une table) ainsi que des procédures stockées (du code pouvant être déclenché à tout moment). Dans les deux cas, c'est sur le serveur, et non dans le poste client que la procédure où le trigger s'effectue.
L'avantage réside dans une plus grande intégrité du maniement des données et souvent d'un traitement plus rapide que si le même code tournait sur le poste client.
Ainsi le calcul d'un tarif dans une table de prestation peut dépendre de conditions parfois complexes ne pouvant être facilement exécutées à l'aide de requêtes SQL. Dans ce cas on aura recours au langage hôte du SGBDR, pour lequel on écrira une procédure permettant de calculer ce tarif à partir de différents paramètres.
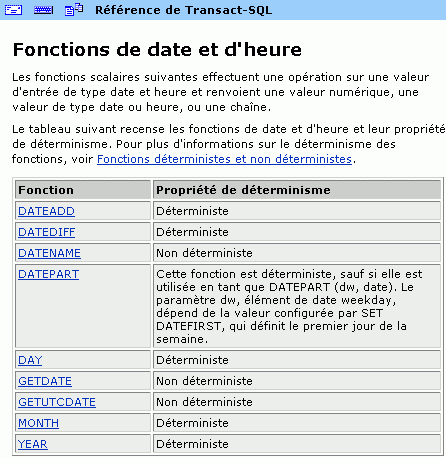
Mais la plupart du temps, triggers et procédures stockées s'écrivent dans un langage propre au SGBDR (Transact SQL pour SQL Server et Sybase, PL/SQL pour Oracle, etc.). Pour un aperçu du langage Transact SQL, veuillez lire l'article « Un aperçu du langage Transact SQL ».
Exemple : on désire calculer le tarif d'adhésion à une mutuelle santé pour une famille composée d'un homme né le 11/5/1950, d'une compagne née le 21/6/1965, d'un fils né le 16/3/1992, d'une fille née le 11/1/1981 et d'une grand-mère à charge (ascendant) née le 21/12/1922, le futur adhérent désirant payer sa cotisation au mois.
Les bases tarifaires établies sont les suivantes :
Table « TARIF_BASE » :
|
TYPE |
SEXE |
AGE_MIN |
TARIF |
|---|---|---|---|
|
ADHERENT |
HOMME |
16 |
1500 |
|
ADHERENT |
HOMME |
65 |
1800 |
|
ADHERENT |
FEMME |
16 |
1400 |
|
ADHERENT |
FEMME |
65 |
1700 |
|
CONJOINT |
HOMME |
16 |
1200 |
|
CONJOINT |
HOMME |
65 |
1500 |
|
CONJOINT |
FEMME |
16 |
1100 |
|
CONJOINT |
HOMME |
65 |
1300 |
|
ENFANT |
HOMME |
0 |
400 |
|
ENFANT |
HOMME |
8 |
600 |
|
ENFANT |
HOMME |
14 |
800 |
|
ENFANT |
HOMME |
18 |
1000 |
|
ENFANT |
FEMME |
0 |
300 |
|
ENFANT |
FEMME |
8 |
500 |
|
ENFANT |
FEMME |
14 |
700 |
|
ENFANT |
FEMME |
18 |
850 |
|
ASCENDANT |
HOMME |
35 |
1200 |
|
ASCENDANT |
HOMME |
65 |
1400 |
|
ASCENDANT |
FEMME |
35 |
1100 |
|
ASCENDANT |
HOMME |
65 |
1300 |
Table « TARIF_MAJO »
|
PAIEMENT |
MAJORATION |
|---|---|
|
MOIS |
12% |
|
TRIMESTRE |
8% |
|
SEMESTRE |
4% |
|
ANNEE |
0% |
Table « TARIF_MINO »
|
Nb_ENFANT_MAX |
MINORATION |
|---|---|
|
1 |
10% |
|
2 |
25% |
|
3 |
50% |
|
4 |
100% |
Il est très difficile d'établir une requête permettant de trouver le bon tarif dans un tel cas. En revanche, en passant la table de paramètres suivants à une procédure :
Table « PARAMS » :
|
TYPE |
SEXE |
DATE_NAISSANCE |
|---|---|---|
|
ADHERENT |
HOMME |
11/5/1950 |
|
CONJOINT |
FEMME |
21/6/1965 |
|
ENFANT |
HOMME |
16/3/1992 |
|
ENFANT |
FEMME |
11/1/1981 |
|
ASCENDANT |
FEMME |
21/12/1922 |
Il n'est pas très compliqué d'écrire dans un langage donné une procédure permettant de calculer ce tarif.
Une telle, procédure pourrait s'écrire dans un pseudo-code proche du Pascal :
Procedure CalcTarif(Params Array, modePaiement string) : money
var
unTarif : mney
leTarif : money
i,j : smallint ; indice de boucle
n : samllint ; nombre d'enfants
; tableau multicellulaire représentant les données des tables
BaseTarif : Array ; table TARIF_BASE
MajoTarif : Array ; table TARIF_MAJO
Minotarif : Array ; table TARIF_MINO
endVar
leTarif := 0
for i from 1 to Params.size()
; recherche du tarif pour les enfant avec comptage du nombre d'enfants
if Params.TYPE = "ENFANT"
then
for j from 1 to BaseTarif.size()
if (BaseTarif[j].TYPE = Params[i].TYPE) and (BaseTarif[j].SEXE = Params[i].SEXE)
then
if BaseTarif[j].AGE_MIN >= CalcAge(Params[i].DATE_NAISSANCE)
then
unTarif := BaseTarif[j].TARIF
break
endif
endif
endFor
; cumul des différents tarifs enfant trouvés
leTarif := leTarif + unTarif
; dénombrement des enfants
n = n+1
; recherche de la minoration pour le nombre d'enfants
for j from MinoTarif.size() downTo 1
if MinoTarif[j].NB_ENFANT_MAX <= n
then
; minoration du tarif cumulé des enfants
leTarif := leTarif * (1 - MinoTarif[j].MINORATION / 100)
break
endif
endFor
endif
endFor
for i from 1 to Params.size()
; recherche du tarif pour les autres types excepté les enfants
if Params.TYPE = "ENFANT"
then
continue
endif
for j from 1 to BaseTarif.size()
if (BaseTarif[j].TYPE = Params[i].TYPE) and (BaseTarif[j].SEXE = Params[i].SEXE)
then
if BaseTarif[j].AGE_MIN >= CalcAge(Params[i].DATE_NAISSANCE)
then
unTarif := BaseTarif[j].TARIF
break
endif
endif
endFor
; cumul des différents autres tarifs trouvés
leTarif := leTarif + unTarif
endFor
; calcul de la majoration pour le mode de paiement :
for i from 1 to MajoTarif.size()
if modePaiement = MajoTarif[i].PAIEMENT
then
leTarif := leTarif * (1 + MajoTarif[j].MAJORATION / 100)
break
endif
endFor
return leTarif
endProcedure9. Résumé▲
Voici les différentes implémentations du SQL sur quelques-uns des différents moteurs relationnels que nous avons choisi d'analyser.
|
SGBDR |
Paradox 7 |
Access 97 |
Sybase adaptive 11 |
SQL Server 7 |
Oracle 8 |
|---|---|---|---|---|---|
|
Nature |
Service de fichier |
Service de fichier |
Serveur de données |
Serveur de données |
Serveur de données |
|
Nb utilisateur (max / en pratique) |
255 / 50 |
300 / 10 |
|||
|
Taille max de la base |
illimitée |
1 Go |
|||
|
Taille max d'une table |
2 Go (hors BLOBS) |
1 Go |
|||
|
Normalisation |
SQL 92 |
SQL 89 ? |
SQL 92 |
SQL 92 |
SQL 89 |
|
DDL |
Oui (a) |
Oui |
Oui |
Oui |
Oui |
|
DML |
Oui |
Oui |
Oui |
Oui |
Oui |
|
DCL |
Non |
Oui |
Oui |
Oui |
Oui |
|
TCL |
Oui (b,c) |
Non |
Oui |
Oui |
Oui |
|
DCL |
Non |
Oui |
Oui |
Oui |
Oui |
|
TCL |
Oui (b,c) |
Non |
Oui |
Oui |
Oui |
|
|
limité à 255 car. |
limité à 255 car. |
limité à 255 car. |
limité à 8000 car. |
limité à 2000 car. |
|
|
Non |
Non |
Oui |
Oui |
limité à 4000 car. |
|
|
Oui, avec 15 chiffres significatifs |
sous types comprenant des entiers et des réels |
Oui |
Oui |
Oui |
|
|
Oui |
Non |
Oui |
Oui |
Oui |
|
|
Oui |
Non |
Oui |
Oui |
Oui |
|
|
Oui, en fait NUMERIC |
Voir NUMERIC |
Oui |
Oui |
Oui |
|
|
Oui |
Non |
Non |
Non |
Oui |
|
|
Oui |
Non |
Non |
Non |
Non |
|
|
Oui |
Oui |
Oui |
Oui |
Non |
|
|
Non |
Non |
Non |
Non |
Non |
|
|
Non |
Oui |
Oui |
||
|
BOOLEAN |
Oui (LOGICAL) |
Oui |
Non |
Non |
Non |
|
MONEY |
Oui |
Oui |
Oui |
Oui |
Non |
|
BYTES |
Oui |
Non |
Non |
Non |
Oui (RAW) |
|
AUTOINC |
Oui |
Oui |
Non (d) |
Non (d) |
Non (d) |
|
BLOB |
Oui (4 types différents : MEMO, MEMO FORMATE en RTF, IMAGE et BINARY) limités à 2 Go |
Oui (2 types différents : MEMO, HYPERLIEN limité à 64 ko) |
Oui (2 types différents TEXT IMAGE) |
Oui (2 types différents IMAGE, TEXT) |
Oui (7 types différents : LONG, LONG RAW, LONG VARCHAR, BFILE, BLOB, CLOB, NCLOB) |
|
Autres types |
OCTET (1 à 255), OLE |
OLE, liste de choix |
BIT, BINARY |
BIT, BINARY, CURSOR, TINYINT, GUID |
ROWID (N° d'enregistrement) |
|
INTÉGRITÉ RÉFÉRENTIELLE |
Oui, stricte ou cascade (suppression et modif.) |
Oui, stricte ou cascade (suppression et modif.) |
Oui |
Oui, pas en cascade |
Oui |
|
TRIGGERS |
Non |
Non |
Oui |
Oui, limités |
BEFORE INSERT, BEFORE UPDATE, BEFORE DELETE, AFTER INSERT, AFTER UPDATE, AFTER DELETE |
|
PROCÉDURES STOCKÉES |
Non |
Non |
Oui, langage propriétaire Transact SQL |
Oui, langage propriétaire Transact SQL |
Oui, langage propriétaire PL/SQL |
(a) Avec quelques limitations (par exemple les contraintes d'intégrité référentielles ne peuvent être créées par le SQL)
(b) Limité en rollback à 255 enregistrements
(c) Pas dans le SQL, mais en code du langage hôte
(d), Mais possible à l'aide de triggers ou de commandes spécifiques
10. Conclusion▲
En matière de SGBDR « fichier », Paradox se révèle plus pauvre au niveau du DDL et du TCL, mais plus riche en matière de DML qu'Access. Quant aux types de données, Paradox se révèle bien plus complet qu'Access qui n'intègre même pas de champ de type « image »… Pensez que dans Access le type entier n'est même pas défini ! Enfin en matière de BLOB la plupart des SGBDR acceptent jusqu'à 2 Go de données, sauf Access qui est limité à 64 Ko…
En ce qui concerne la capacité de stockage, Access révèle très rapidement de nombreuses limites, comme en nombre d'utilisateurs en réseau.
En matière de contrôle des transactions, Paradox est limité à 255 enregistrements en RollBack. Mais la présence de tables auxiliaires permet de dépasser ces limites sans encombre, à condition de prévoir le code à mettre en œuvre.
Différence fondamentale pour Paradox, pas de DCL. Mais cela est largement compensé par un niveau de sécurité à forte granularité qui n'est pas compatible avec le SQL normalisé. Ainsi dans Paradox on peut placer des droits au niveau des tables, mais aussi de chaque champ et le moteur crypte les données dès qu'un mot de passe est défini (SQL Base de Centura permet aussi de crypter les données à l'aide des plus récents algorithmes de chiffrage)
Point très négatif pour Access dans sa catégorie : il pratique le verrouillage de pages !
Enfin les vues n'existent pas dans Access, mais elles sont présentes dans Paradox sous une forme non SQL appelée « vue de requête reliée » (QBE).
En matière de serveur SQL C/S, le SGBDR Sybase se révèle très proche de SQL Server ce qui n'est pas absurde puisqu'ils sont parents. Oracle possède une bonne diversité de types, mais sa conformité à la norme laisse à désirer (pas de JOIN par exemple, pauvreté des fonctions temporelles). En revanche Oracle possède un type de champ bien utile et intégré à toutes les tables, le ROWID qui donne le n° de la ligne dans la table et qui est toujours unique, même si la ligne a été supprimée. On retrouve des mécanismes similaires dans SQL Server sous le nom de GUID ou bien avec l'auto-incrémentation via « identity ».