




Préambule▲
NOTA : La structure de la base de données exemple, ainsi qu'une version des principales bases utilisées sont disponibles dans la page « La base de données exemple »
1. La clause GROUP BY▲
Vous trouverez des compléments d'information sur le sujet aux pages 153 à 154 de l'ouvrage « SQL », collection « La Référence », Campus Press éditeur.
La clause GROUP BY est nécessaire dès que l'on utilise des fonctions de calculs statistiques avec des données brutes. Cette clause groupe les lignes sélectionnées en se basant sur la valeur de colonnes spécifiées pour chaque ligne et renvoie une seule ligne par groupe.
On peut la comparer à une opération de découpage de sous-ensemble un peut à la manière des « niveaux de rupture » lorsque l'on réalise des états imprimés.
Cherchons à compter le nombre de chambres par étage de notre hôtel :
Exemple 1
SELECT COUNT(CHB_ID) AS NOMBRE, CHB_ETAGE
FROM T_CHAMBRELa requête, telle que présentée ci-dessus n'est pas calculable. En effet comment décider si le comptage doit se faire pour chaque chambre ou pour un groupe de chambre et notamment les groupes formés par chacun des étages ?
Si la requête se faisait pour chaque chambre, le résultat serait :
NOMBRE CHB_ETAGE
----------- ---------
1 RDC
1 RDC
1 RDC
1 RDC
1 1er
1 1er
1 1er
1 1er
1 1er
...Et n'aurait pas beaucoup de sens !
En revanche, un regroupement par étage, donne tout son sens à la requête :
NOMBRE CHB_ETAGE
----------- ---------
8 1er
8 2e
4 RDCPour réaliser un tel regroupement, il faut introduire une clause de groupage dans la requête. Pour cela SQL fournit la clause GROUP BY :
Exemple 1 bis
SELECT COUNT(*) AS NOMBRE, CHB_ETAGE
FROM T_CHAMBRE
GROUP BY CHB_ETAGENOTA
- La présence de la clause GROUP BY est nécessaire dès que la clause de sélection, ou le filtre WHERE, ou encore les jointures comportent simultanément des calculs d'agrégation et la présence de colonnes de table hors de calculs d'agrégation.
- De plus, toutes les colonnes représentées hors des calculs d'agrégation doivent figurer dans la clause GROUP BY.
La plupart du temps, le moteur de requête vous avertira d'une probable incohérence de calcul des agrégats à l'aide d'un message d'erreur (avant exécution de la requête), du genre : « La colonne … est incorrecte dans la liste de sélection parce qu'elle n'est pas contenue dans une fonction d'agrégation et qu'il n'y a pas de clause GROUP BY » (SQL Server).
Cherchons maintenant à compter le couchage de chaque étage :
Exemple 2
|
Sélectionnez |
Sélectionnez |
Un peu plus compliqué, cherchons à savoir quel a été le nombre de nuitées pour chaque chambre au cours de l'année 1999 (une nuitée étant une personne passant une nuit dans une chambre. Si deux personnes occupent la même chambre, cela fait deux nuitées) :
Exemple 3
|
Sélectionnez |
Sélectionnez |
Partant de là, nous pouvons rechercher le taux d'occupation de chaque chambre dans cette période.
Le nombre maximal de nuitées étant le nombre de couchages de chaque chambre multiplié par toutes les dates de l'année, ce calcul s'obtient par :
Exemple 4
|
Sélectionnez |
Sélectionnez |
Il ne suffit plus que de « raccorder » les requêtes des exemples 3 et 4 :
Exemple 5
|
Sélectionnez |
Sélectionnez |
Nous allons voir, maintenant que la clause GROUP BY est souvent utilisée avec la clause HAVING…
2. La clause HAVING▲
Vous trouverez des compléments d'information sur le sujet aux pages 153 à 154 de l'ouvrage « SQL », collection « La Référence », Campus Press éditeur.
La clause HAVING agit comme le filtre WHERE, mais permet de filtrer non plus les données, mais les opérations résultant des regroupements, c'est-à-dire très généralement toute expression de filtre devant introduire un calcul d'agrégation.
Pour tenter de comprendre l'utilité de la clause having, nous allons procéder par un exemple simple : recherchons un étage de l'hôtel capable de coucher au moins 20 personnes.
Partant de notre exemple 2, nous serions tentés d'écrire :
Exemple 6
SELECT SUM(CHB_COUCHAGE) AS NOMBRE, CHB_ETAGE
FROM T_CHAMBRE
WHERE SUM(CHB_COUCHAGE) >= 20
GROUP BY CHB_ETAGEMais cette requête va immanquablement provoquer une erreur avant exécution du fait de la clause WHERE. En effet, souvenons-nous que le filtre WHERE agit sur les données des tables et permet de filtrer ligne après ligne. Or le filtrage ne porte plus sur la notion de lignes, mais sur une notion de sous-ensemble de la table. En d'autres termes, le filtre, ici, doit porter sur chacun des groupes. C'est pourquoi SQL introduit le filtre HAVING qui porte, non pas sur les données, mais sur les calculs résultants des regroupements.
En l'occurrence, dans notre exemple, nous devons déporter le filtre WHERE dans la clause HAVING et l'opération deviendra possible :
Exemple 6 bis
|
Sélectionnez |
Sélectionnez |
Autre exemple :
Partant de la requête vue à l'exemple 6, essayons de ne retenir que les chambres occupées à plus de 2/3, soit 66.666666… % ?
Une première tentative consisterait à écrire :
Exemple 7
|
Sélectionnez |
Sélectionnez |
Un autre exemple intéressant est de rechercher quelles sont les chambres qui ont été inoccupées plus de 10 jours au cours du mois de janvier 2000…
Pour calculer le nombre de jours où les chambres ont été occupées au cours de janvier 2000, il suffit de faire :
Exemple 8
|
Sélectionnez |
Sélectionnez |
Mais nous voulons le complément de cette colonne NOMBRE avec le nombre de jours du mois de janvier 2000, ce qui représente 31 jours. La requête devient donc :
Exemple 9
|
Sélectionnez |
Sélectionnez |
Dès lors il ne suffit plus que de filtrer le calcul :
31 - COUNT(C.CHB_ID)
pour ne retenir que les valeurs supérieures à 10. Comme cette expression contient une fonction d'agrégation, ce qui suppose un groupage, il est nécessaire d'utiliser le filtre WHERE :
Exemple 10
|
Sélectionnez |
Sélectionnez |
Pour dernier exemple, nous allons nous placer dans un contexte plus proche de la réalité. Voici notre directeur qui souhaite inciter les clients avec lesquels il a peu travaillé à venir plus souvent. L'idée lui prend d'offrir un bon de réduction de 15 % sur l'ensemble des prestations hôtelières pour tous les clients ayant eu un chiffre d'affaires inférieur à 15 000 F HT au cours de l'année 2000.
Une première approche consisterait par exemple à rechercher toutes les chambres libres entre les deux dates :
Exemple 11
|
Sélectionnez |
Sélectionnez |
Les clients 1, 37, 39, 40, 52, 61, 87 étant bien les personnes visées par la promotion.
Mais poussons notre raisonnement… Imaginons une personne ayant été cliente en 1999 et pas en 2000. Pour cela, rajoutons les lignes suivantes dans notre jeu de données :
INSERT INTO T_CLIENT (CLI_ID, CLI_NOM) VALUES (101, 'DUGUDU')
INSERT INTO T_FACTURE (FAC_ID, CLI_ID, FAC_DATE, FAC_PMT_DATE) VALUES (2375, 101, '25/03/1999', '15/04/1999')
INSERT INTO T_LIGNE_FACTURE (LIF_ID, FAC_ID, LIF_QTE, LIF_MONTANT, LIF_TAUX_TVA) VALUES (16791, 2375, 1, 320, 18.6)L'exécution de la requête de l'exemple 10, nous délivre le même résultat, alors que nous aimerions récupérer le client 101… Quelle erreur avons-nous commise ?
Le fait est que nous avons à nouveau fait l'hypothèse du monde clos ! (voir à la page Le SQL de A à Z, 3e partie, le paragraphe 2.4) Il faut impérativement remonter jusqu'à la table des clients et réaliser des jointures externes sur les tables des factures et des lignes de facture :
Exemple 12
|
Sélectionnez |
Sélectionnez |
Or et pour aussi bizarre que cela puisse paraître, cette requête ne nous donne toujours pas le client 101… Pourquoi ? Il persiste en fait deux raisons à cela :
- Nous avons supposé que le calcul du CA retournait une valeur… ;
- Nous avons filtré sur l'année 2000, après avoir effectué la jointure.
Pour contrer le cas n° 1, nous ne devons pas oublier que les NULL se propagent dans les calculs et que le marqueur NULL ne peut être comparée à aucune valeur. Il faut donc réaliser le filtre HAVING en retenant l'expression si elle vaut moins de 15 000, mais aussi si elle vaut NULL.
Pour contrer le cas n° 2, et c'est beaucoup plus subtil, il faut inclure dans la condition de jointure entre les tables T_CLIENT et T_FACTURE l'expression située dans la clause WHERE.
La requête ainsi corrigée devient :
Exemple 13
|
Sélectionnez |
Sélectionnez |
Nous pourrions ainsi passer encore plusieurs cas en revue tant le mélange des clauses WHERE et HAVING associées aux jointures externes peut devenir passionnant, mais ce site n'a pas pour but de vous poser des pièges, mais plutôt de vous faire toucher du doigt la problématique de ce type de requête et la logique ensembliste sous-jacente.
Dans la suite du site et notamment lorsque vous aborderez les sous-requêtes, de nouveaux exemples utilisant la clause HAVING et le groupage, sont présentés.
3. Les opérateurs ensemblistes▲
Vous trouverez des compléments d'information sur le sujet aux pages 180 à 187 de l'ouvrage « SQL », collection « La Référence », Campus Press éditeur.
C'est une des parties les plus simples de l'ordre SELECT. À la fois par sa syntaxe, mais aussi par sa compréhension facile. Il s'agit ni plus ni moins que de réaliser des opérations sur les ensembles représentés par des tables ou des extraits de table. Les opérations ensemblistes du SQL sont l'union, l'intersection et la différence.
3-1. L'UNION▲
Pour faire une union, il suffit de disposer de deux ensembles de données compatibles et d'utiliser le mot clef UNION. La syntaxe est alors :
SELECT ...
UNION
SELECT ...Bien entendu il est indispensable que les deux ordres SELECT :
- produisent un même nombre de colonnes ;
- que les types de données de chaque paire ordonnée de colonnes soient de même type (ou d'un type équivalent).
3-2. L'INTERSECTION▲
La démarche est la même pour faire une intersection, que pour le mécanisme de l'union. La syntaxe utilisant le mot clef INTERSECT :
SELECT ...
INTERSECT
SELECT ...Avec les mêmes contraintes d'ordre syntaxique.
3-3. LA DIFFÉRENCE▲
La différence de deux ensembles s'obtient de la même manière, en utilisant le mot clef EXCEPT :
SELECT ...
EXCEPT
SELECT ...3-4. Considérations diverses sur les opérations ensemblistes du SQL▲
3-4-1. Le mot clef ALL peut qualifier l'opérateur ensembliste▲
ALL récupérera tous les doublons des ensembles considérés.
ATTENTION : l'opérateur par défaut opère le dédoublonnage contrairement à la clause SELECT de l'ordre SELECT.
Ainsi lorsque l'on va utiliser une telle construction pour des opérations comptable récupérant des sommes financières en utilisant l'opérateur UNION, on devra impérativement utiliser le mot clef ALL sinon les sommes identiques disparaîtrons.
3-4-2. On peut restreindre l'intersection à certaines colonnes en utilisant le filtre CORRESPONDING BY▲
Ainsi on pourra récupérer dans le résultat plus de colonnes que celles qui opèrent la véritable intersection.
3-4-3. Les opérateurs UNION et INTERSECT sont réflexifs, mais EXCEPT ne l'est pas▲
Ainsi l'ordre des requêtes de sélection n'a pas d'importance pour les opérations d'union et d'intersection, mais pour la différence cet ordre est essentiel et ne donne pas le même résultat en cas de permutation (c'est le propre de la soustraction et de la division).
3-4-4. On peut utiliser la clause ORDER BY▲
La clause ORDER BY doit être la clause finale, car il ne peut y en avoir qu'une.
3-4-5. Le nom des colonnes du résultat est celui du premier des ordres SELECT composant la globalité de la requête▲
Autrement dit si les noms des colonnes sont différents entre les divers ordres SELECT s'enchainant avec des opérateurs ensemblistes, ceux qui ont prépondérance sont ceux des colonnes de la première requête SELECT.
3-4-6. Mis à part l'union, les opérations ensemblistes d'intersection et de différence peuvent être construites à partir de requêtes de base▲
Exemples :
L'intersection peut être établie par :
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
La différence peut être établie par :
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
3-5. Quelques exemples▲
Pour présenter des exemples significatifs, voici le jeu de test que nous allons utiliser :
CREATE TABLE T_OBJET
(OBJ_NOM CHAR(16),
OBJ_PRIX DECIMAL(16,2))
CREATE TABLE T_MACHINE
(MAC_NOM VARCHAR(20),
MAC_PRIX FLOAT (16),
MAC_REF CHAR(8))
INSERT INTO T_OBJET (OBJ_NOM, OBJ_PRIX) VALUES ('MOTO', 43528)
INSERT INTO T_OBJET (OBJ_NOM, OBJ_PRIX) VALUES ('ASSIETTE', 26.5)
INSERT INTO T_OBJET (OBJ_NOM, OBJ_PRIX) VALUES ('LIVRE', 128)
INSERT INTO T_OBJET (OBJ_NOM, OBJ_PRIX) VALUES ('TABLE', 5600)
INSERT INTO T_OBJET (OBJ_NOM, OBJ_PRIX) VALUES ('PERCEUSE', 259.99)
INSERT INTO T_MACHINE (MAC_NOM, MAC_PRIX, MAC_REF) VALUES ('AVION', NULL, 'A320 ')
INSERT INTO T_MACHINE (MAC_NOM, MAC_PRIX, MAC_REF) VALUES ('VENTILATEUR', 250, 'VTL 1200' )
INSERT INTO T_MACHINE (MAC_NOM, MAC_PRIX, MAC_REF) VALUES ('MOTO', 43528, 'YAM R1 ')
INSERT INTO T_MACHINE (MAC_NOM, MAC_PRIX, MAC_REF) VALUES ('RÉVEIL', 128, 'LIP-STAR')
INSERT INTO T_MACHINE (MAC_NOM, MAC_PRIX, MAC_REF) VALUES ('PERCEUSE', 260, 'BD 450A ')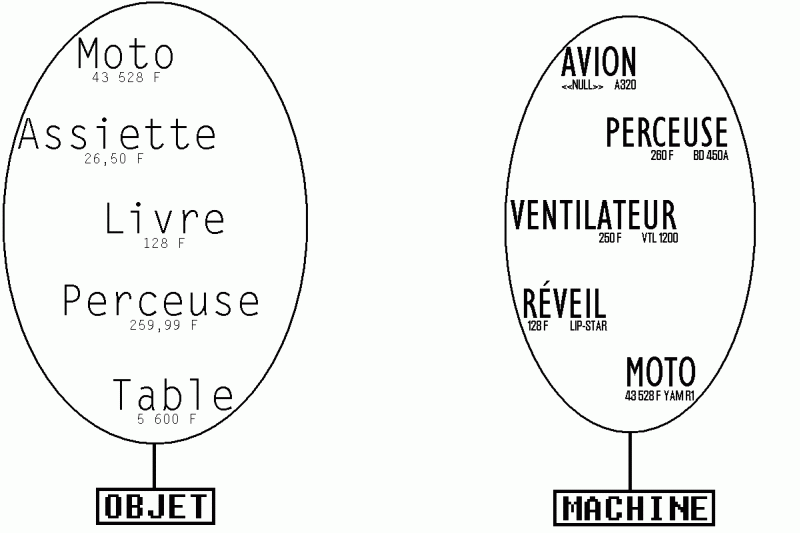
3-5-1. Exemple d'UNION▲
Commençons par la basique union des noms des objets et machines de nos deux tables :
Exemple 14
|
Sélectionnez |
Sélectionnez |
Remarquons que la moto, comme la perçeuse ne figurent qu'une seule fois dans le résultat. Ce défaut peut être corrigé par l'emploi du mot clef ALL :
Exemple 15
|
Sélectionnez |
Sélectionnez |
Voici symbolisé par un dessin, le principe de l'union tel que décrit dans les deux requêtes précédentes :
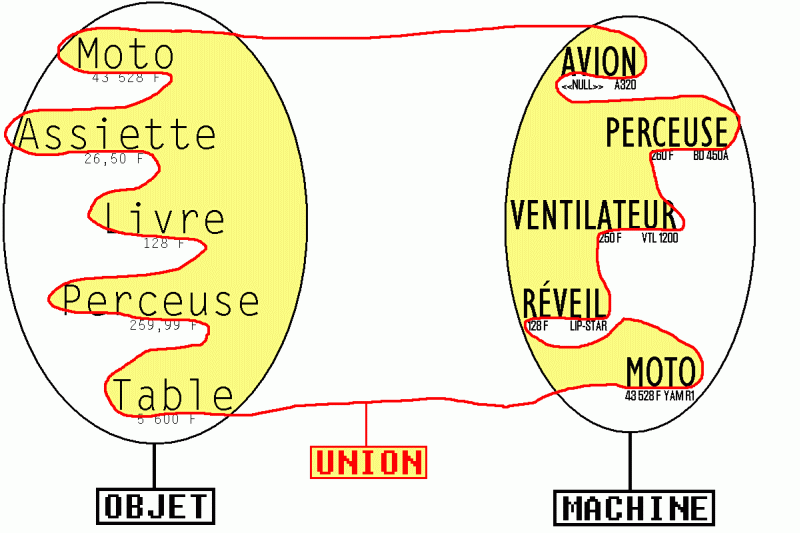
union de l'ensemble des noms (OBJ_NOM + MAC_NOM) des tables OBJET et MACHINE
3-5-2. Exemple de DIFFÉRENCE▲
La différence de l'ensemble des noms des objets par rapport à celui des noms de machine, nous donnera :
Exemple 16
|
Sélectionnez |
Sélectionnez |
Elle peut aussi être exprimée en l'absence d'opérateur EXCEPT, par :
Exemple 17
|
Sélectionnez |
Sélectionnez |
Ou encore :
Exemple 18
|
Sélectionnez |
Sélectionnez |
Voici le diagramme de Venn correspondant à la différence tel que les requêtes que nous venons de voir l'expriment :
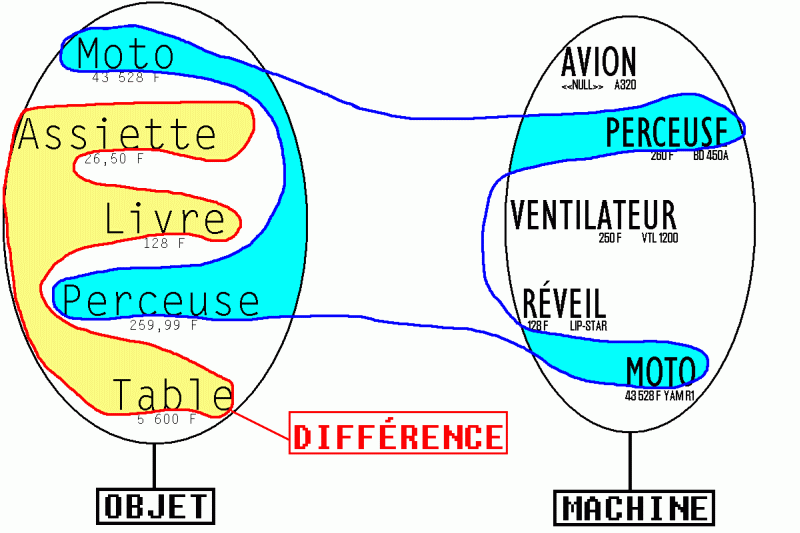
différence entre les noms des objets et ceux des machines
3-5-3. Exemple d'INTERSECTION▲
Quant à l'intersection, celle-ci n'est pas plus difficile :
Exemple 19
|
Sélectionnez |
Sélectionnez |
Que l'on peut exprimer par l'équivalence logique :
Exemple 20
|
Sélectionnez |
Sélectionnez |
Ou encore :
Exemple 21
|
Sélectionnez |
Sélectionnez |
Et par un dessin reprenant les célèbres patates, le principe de l'intersection tel qu'exprimé décrit dans les requêtes ci-dessus :
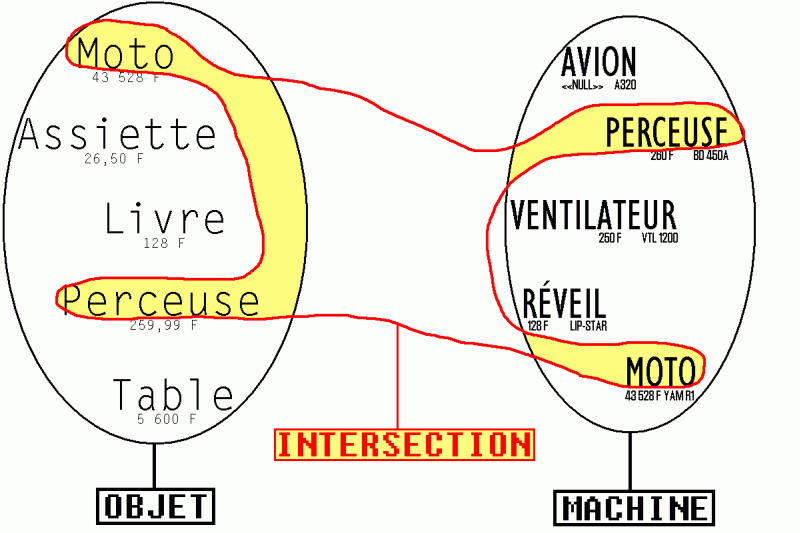
intersection de l'ensemble des noms (OBJ_NOM + MAC_NOM) des tables OBJET et MACHINE
Un petit dernier exemple sera consacré à l'intersection avec correspondance. Pour cela nous avons besoin de modifier nos deux tables (ou au moins l'une d'entre elles) de façon à ce que les noms des colonnes des tables soient identiques.
Par exemple, notre nouveau jeu de données pourrait être :
CREATE TABLE T_OBJET2
(NOM CHAR(16),
PRIX DECIMAL(16,2))
CREATE TABLE T_MACHINE2
(NOM VARCHAR(20),
PRIX FLOAT (16),
REF CHAR(8))
INSERT INTO T_OBJET2 (NOM, PRIX) VALUES ('MOTO', 43528)
INSERT INTO T_OBJET2 (NOM, PRIX) VALUES ('ASSIETTE', 26.5)
INSERT INTO T_OBJET2 (NOM, PRIX) VALUES ('LIVRE', 128)
INSERT INTO T_OBJET2 (NOM, PRIX) VALUES ('TABLE', 5600)
INSERT INTO T_OBJET2 (NOM, PRIX) VALUES ('PERCEUSE', 259.99)
INSERT INTO T_OBJET2 (NOM, PRIX) VALUES ('ORDINATEUR', 7000)
INSERT INTO T_MACHINE2 (NOM, PRIX, REF) VALUES ('AVION', NULL, 'A320 ')
INSERT INTO T_MACHINE2 (NOM, PRIX, REF) VALUES ('VENTILATEUR', 250, 'VTL 1200' )
INSERT INTO T_MACHINE2 (NOM, PRIX, REF) VALUES ('MOTO', 43528, 'YAM R1 ')
INSERT INTO T_MACHINE2 (NOM, PRIX, REF) VALUES ('RÉVEIL', 128, 'LIP-STAR')
INSERT INTO T_MACHINE2 (NOM, PRIX, REF) VALUES ('PERCEUSE', 260, 'BD 450A ')
INSERT INTO T_MACHINE2 (NOM, PRIX, REF) VALUES ('ORDINATEUR', 7000, 'PC PII1G')Dès lors, la requête suivante :
Exemple 22
|
Sélectionnez |
Sélectionnez |
Le mot clef CORRESPONDING se comporte un peu à la manière du NATURAL JOIN et de son mot clef USING, c'est-à-dire qu'en le précisant, SQL va chercher la correspondance des colonnes par leurs position, nom et type.
On peut en outre préciser sur quelles colonnes la correspondance va porter, à l'aide du mot clef BY :
Exemple 23
|
Sélectionnez |
Sélectionnez |
À noter que l'usage du mot clef CORRESPONDING [BY (liste de colonne)] est accepté dans l'intersection comme dans l'union. Cependant, rares sont les moteurs SQL à l'accepter !
4. Résumé▲
Voici les différences entre les moteurs des bases de données :
|
Paradox |
Access |
Sybase |
SQL Server |
Oracle |
|
|---|---|---|---|---|---|
|
GROUP BY |
Oui |
Oui |
Oui |
Oui |
Oui |
|
HAVING |
Oui |
Oui |
Oui |
Oui |
Oui |
|
UNION |
Oui |
Oui |
Oui |
Oui |
Oui |
|
INTERSECT |
Non |
Non |
Non |
Non |
? |
|
EXCEPT |
Non |
Non |
Non |
Non |
MINUS |
|
CORRESPONDING BY |
Non |
Non |
Non |
Non |
Non |