


I. Qu'est-ce qu'un index ?▲
Dans la vie courante, nous sommes entourés d'index : un code postal, le n° d'un immeuble dans une rue, les numéros de téléphone sont des index. Autrefois, lorsque le téléphone fit son apparition (Clémenceau aurait dit du téléphone « Quoi ? On vous sonne comme un laquais ??? ») il n'y avait pas de numéro. On agitait une manivelle qui avait pour effet de réveiller l'opératrice du standard auquel on était physiquement relié. Puis on demandait à cette personne de nous connecter avec Monsieur le Marquis de Carabas à Toledo. Il s'ensuivait un échange de bons procédés entre les opératrices des différents relais afin d'établir une liaison physique entre ces deux clients. Puis vint une première numérotation… Elle était faite ville par ville. On vit alors Fernand Raynaud dans son célèbre sketch demander désespérément le 22 à Asnières et n'obtenir que New York ! Dans les années 50, l'automatique fit son apparition et l'on pouvait appeler en interurbain une personne en composant directement son numéro. Ainsi le commissaire Maigret fut-il joignable à PELLEPORT 38 52. Puis l'automatique fut étendu à toutes les régions de France. Depuis quelques années seulement on peut joindre n'importe qui sur terre avec un simple numéro. Mais les numéros se sont allongés. Le mien, complet, est 00 33 6 11 86 40 66.
Remarquez la structure de ce numéro. Il commence par un double zéro qui indique que l'on va s'intéresser à l'international. Puis le second groupe de chiffres indique le pays. Enfin le suivant indique la nature du réseau (ici le réseau de téléphones cellulaires). Chacun des groupes de chiffres précise un peu plus les informations.
Une chose importante des index est leur structuration. On convient à l'évidence que si les numéros des immeubles étaient distribués au hasard sur chaque bâtiment[1], il serait difficile (mais pas impossible) de trouver le 68 avenue des Champs Élysées. En fait, il suffirait – au pire – de parcourir toute l'avenue pour trouver le bon bâtiment.
On comprend donc que l'organisation des données dans un index est primordiale pour accélérer les recherches. En fait, les données d'un index sont systématiquement triées et les données stockées dans une structure particulière favorisant les recherches : liste ordonnée ou arbre, le plus souvent.
II. Index et norme SQL▲
Comme nous le savons tous, le langage SQL est fortement normalisé. La norme la plus actuelle, en cours de finalisation, portera le nom de SQL:2008 (ISO/IEC 9075).
Aussi curieux que cela paraisse, la norme passe sous silence la notion d'index[2]. En effet, ces derniers ne sont que des artifices destinés à résoudre une problématique physique. Or, SQL ne s'intéresse qu'à des concepts logiques…
Pour autant, la plupart des éditeurs se sont accordés pour définir un ordre pseudoSQL, CREATE INDEX[3], afin de proposer des méthodes de manipulation des index.
III. Structure logique d'un index▲
Nous avons dit que les données d'un index sont triées. Si un index est multicolonne, le tri de la clef d'index fait que l'information y est vectorisée. En effet, chaque colonne supplémentaire précise la colonne précédente. De ce fait, la recherche dans un index multicolonne n'est accélérée que si les données cherchées sont un sous-ensemble ordonné du vecteur. Voyons cela en termes pratiques à l'aide d'un exemple…
CLI_NOM CLI_PRENOM CLI_DATE_NAISSANCE
--------- ----------- ------------------
DUPONT Alain 21/01/1930
DUPONT Marcel 21/01/1930
DUPONT Marcel 01/06/1971
DUPONT Paul 21/01/1930
MARTIN Alain 11/02/1987
MARTIN Marcel 21/01/1930
...Dans cet index composé d'un nom d'un prénom et d'une date de naissance, la recherche sera efficace pour les informations suivantes :
- CLI_NOM
- CLI_NOM + CLI_PRENOM
- CLI_NOM + CLI_PRENOM + CLI_DATE_NAISSANCE
En revanche, la recherche sur une seule colonne CLI_PRENOM ou CLI_DATE_NAISANCE et a fortiori sur ces deux colonnes n'aura aucune efficacité du fait du tri relatif des colonnes entre elles (vectorisation)… En effet chercher « Paul » revient à parcourir tout l'index (balayage ou scan) alors que chercher « MARTIN », revient à se placer très rapidement par dichotomie au bon endroit (recherche ou seek).
IV. Des index créés automatiquement▲
La plupart des SGBDR créent automatiquement des index lors de la pose des contraintes PRIMARY KEY et UNIQUE. En effet, le travail de vérification de l'unicité d'une clef primaire ou candidate s'avérerait extrêmement long sans un index.
En revanche la plupart des SGBD relationnels ne prévoient pas de créer des index sous les clefs étrangères (FOREIGN KEY), ni sous les colonnes auto-incrémentées. Il y a à cela différentes raisons, que nous allons expliquer plus en détail un peu plus loin dans cet article…
V. Création manuelle d'un index▲
CREATE INDEX #nom_index
ON #nom_schem.#nom_table
(#colonne1 [ { ASC | DESC } ] [, #colonne2 [, ... #colonneN ] ] ] )Les colonnes spécifiées dans la parenthèse constituent la clef d'index, c'est-à-dire les informations recherchées.
La plupart des SGBDR acceptent des paramètres tels que :
- la clusterisation des données (CLUSTERED, NONCLUSTERED) [4], c'est-à-dire l'imbrication de l'index au sein de la table ;
- le facteur de remplissage des pages d'index (FILL_FACTOR ou PCT_FREE) ;
- la nature de la structure de données (TREE, HASH, BITMAP) ;
- la spécification d'un emplacement physique de stockage.
CREATE UNIQUE CLUSTERED INDEX X_CLI_PRENOMDTN
ON S_COM.T_CLIENT (CLI_NOM ASC,
CLI_PRENOM,
CLI_DATE_NAISSANCE DESC)
INCLUDE (CLI_TEL)
WITH (FILLFACTOR = 80,
SORT_IN_TEMPDB = ON,
ALLOW_ROW_LOCKS = ON,
MAXDOP = 3)
ON STORAGE_IDXDans cet exemple, un index unique de type CLUSTER, de nom X_CLI_PRENOMDTN est créé sur la table T_CLIENT du schéma S_COM et comporte les colonnes CLI_NOM (ordre ascendant explicite), CLI_PRENOM (ordre ascendant implicite) et CLI_DATE_NAISSANCE (ordre descendant explicite). En sus, les informations de la colonne CLI_TEL sont ajoutées de façon surnuméraire, mais elles ne sont pas indexées, donc pas « triées ».
Techniquement cet index est doté d'un facteur de remplissage de 80 %, le tri pour le construire devra s'effectuer dans la base tempdb qui sert pour SQL Server à tous les objets temporaires. Enfin cet index est autorisé à faire du verrouillage de ligne et ne peut pas utiliser plus de trois threads en parallèle pour une même recherche. Pour terminer les données de cet index figureront dans l'espace de stockage STORAGE_IDX.
VI. Quels index créer ?▲
On devrait créer des index derrière toutes les clefs étrangères, afin d'accélérer les jointures ainsi que pour les principales colonnes fréquemment recherchées. Cependant ceci appelle plusieurs remarques…
VI-A. Indexation des clefs étrangères▲
Si l'intention d'indexer les clefs étrangères est bonne, elle n'est pourtant pas nécessaire pour toutes les clefs étrangères.
En effet, pour les clefs étrangères qui naissent d'une association de type 1:1 (un à un) ou de type 1:n (un à plusieurs) ceci est parfait. Il n'en va pas de même pour les tables de jointure qui découlent de la transformation du modèle conceptuel en modèle physique.
Étudions un cas pratique… Soit deux entités représentant des commandes et des produits en association plusieurs à plusieurs :

Le modèle physique qui en découle est le suivant :
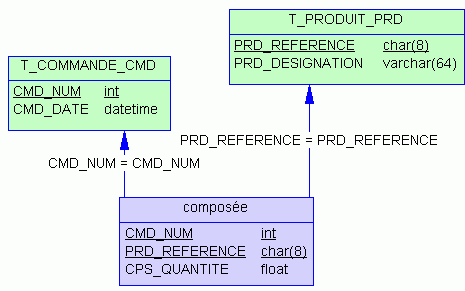
Ce modèle conduit à la base de données suivante :
create table T_COMMANDE_CMD (
CMD_NUM int not null PRIMARY KEY,
CMD_DATE datetime not null)
create table T_PRODUIT_PRD (
PRD_REFERENCE char(8) not null PRIMARY KEY,
PRD_DESIGNATION varchar(64) not null)
create table T_J_COMPOSEE_CPS (
CMD_NUM int not null
foreign key (CMD_NUM) references T_COMMANDE_CMD (CMD_NUM),
PRD_REFERENCE char(8) not null
foreign key (PRD_REFERENCE) references T_PRODUIT_PRD (PRD_REFERENCE),
CPS_QUANTITE float not null,
constraint PK_T_J_COMPOSEE_CPS primary key (CMD_NUM, PRD_REFERENCE))Dans cette base de données, on a de fait les index suivants à cause des PRIMARY KEY
- T_COMMANDE_CMD (CMD_NUM)
- T_PRODUIT_PRD (PRD_REFERENCE)
- T_J_COMPOSEE_CPS (CMD_NUM, PRD_REFERENCE)
Si l'on devait obéir à la règle qui veut que l'on crée systématiquement un index sous toutes les clefs étrangères, il faudrait donc rajouter à cette base, les objets suivants :
CREATE INDEX X_CPS_CMD ON T_J_COMPOSEE_CPS (PRD_REFERENCE)
CREATE INDEX X_CPS_CMD ON T_J_COMPOSEE_CPS (CMD_NUM)Or, l'un de ces index est totalement inutile parce que redondant. En effet, l'index sur la seule colonne CMD_NUM est déjà inclus dans l'index de clef primaire de cette même table. Il n'y a donc pas lieu de le créer.
En revanche, le second index est parfaitement utile, car la vectorisation de l'information contenue dans les clefs d'index rend inefficace la recherche sur la partie PRD_REFERENCE dans l'index de clef primaire.
VI-B. Indexation des colonnes les plus recherchées▲
Là aussi, il est inutile de se précipiter sur la création d'index sur chacune des colonnes figurant dans une clause WHERE. En effet, certaines expressions de recherche pourront activer la recherche dans l'index, d'autres pas.
Les anglophones ont inventé un terme afin de définir qu'un prédicat est « recherchable » ou pas. C'est le terme sargable (Search ARGument).
Voyons cela à l'aide d'un exemple.
SELECT *
FROM T_CLIENT_CLI
WHERE CLI_NOM LIKE '%ONT'
AND SUBSTRING(CLI_PRENOM, 2, 2) = 'au'
AND MONTH(CLI_DATE_NAISSANCE) = 1
AND YEAR(CLI_DATE_NAISSANCE) = 1930La première expression du filtre WHERE recherche un client dont le nom se termine par ONT. À l'évidence un index sur le nom du client ne sert à rien, car les index ordonnent les données dans le sens de lecture des lettres c'est-à-dire de gauche à droite. Si vous voulez que cette recherche particulière soit « sargable » alors vous pouvez indexer le nom recomposé à l'envers soit à l'aide d'une colonne calculée persistante qui reprend le nom et le renverse, soit utiliser une fonction dans la création de l'index.
CREATE INDEX X_CLI_NOM_REVERSE ON S_COM.T_CLIENT_CLI (REVERSE(CLI_NOM))La seconde expression du filtre WHERE recherche à l'intérieur d'un prénom le motif 'au'. Aucun index conventionnel ne permet de rendre sargable une telle expression. Seule l'implantation de structures de données comme des index rotatifs permet d'être efficace sur ce sujet, mais cela est un autre débat !
Les troisième et quatrième expressions de ce filtre WHERE recherchent les données du mois de janvier de l'année 1930. Dès qu'une fonction est appliquée sur une colonne, elle en déforme le contenu et aucun index n'est activable. Or une telle expression peut parfaitement être « sargable » à condition d'exposer la colonne sans aucune déformation de l'information.
AND MONTH(CLI_DATE_NAISSANCE) = 1
AND YEAR(CLI_DATE_NAISSANCE) = 1930AND CLI_DATE_NAISSANCE BETWEEN '1930-01-01' AND'1930-01-31'Dès lors, un index sur la colonne CLI_DATE_NAISSANCE pourra être utilisé.
Il y aurait beaucoup de choses encore à dire sur ce qui est indexable et ce qui n'a pas d'intérêt de l'être, ou encore comment transformer des expressions non « sargables » en expressions « cherchables »…
Disons simplement que :
Un index sur de nombreuses colonnes, comme un index dont la clef est démesurée, ou encore un index pour une expression non « cherchable » n'offrent en général aucun intérêt !
Comme tout index coûte en temps de traitement, un index inutile est contre-performant.
VII. Index multicolonne et longueur des clefs d'index▲
Comme nous l'avons déjà vu, un index multicolonne ne sera efficace que pour des recherches dans le sens du vecteur constitué par les colonnes dans l'ordre positionnel. Il est donc inefficace de créer un index multicolonne pour des requêtes qui filtrent alternativement sur l'une ou l'autre colonne exclusivement. Néanmoins lorsque l'on est en mesure de tirer bénéfice d'un index multicolonne, il est intéressant de bien choisir l'ordre des colonnes dans le vecteur.
En effet, on obtiendra une efficacité plus grande en posant en premier les colonnes ayant la plus forte dispersion.
Par exemple s'il faut créer un index sur le sexe, le prénom et le nom, il y a fort à parier que la meilleure combinaison sera nom + prenom + sexe (dans cet ordre précis).
En fait, la dispersion des données est plus forte pour un nom qu'un prénom (il y a moins de prénoms différents que de noms de famille différents) et bien plus encore par rapport au sexe qui ne présente généralement que deux valeurs.
Quant à la longueur de la clef d'index, c'est-à-dire au nombre d'octets qui composent l'information vectorisée, mieux vaut qu'elle soit la plus petite possible. En effet un index dont la clef est petite occupe peu de place et donc permet une recherche bien plus rapide qu'un index de quelques centaines d'octets. À mon sens, on doit s'intéresser à ne jamais faire en sorte que la clef d'index dépasse quelques dizaines d'octets.
Il est à noter que certains développeurs pensent naïvement qu'en créant un index sur une colonne de type « texte » (BLOB) on peut activer une recherche mot par mot. Compte tenu de la structure que nous avons indiquée, il ne sera jamais possible de rechercher un mot précis à l'intérieur des informations d'une colonne par le biais d'un index ordinaire. Cela est en revanche possible si votre SGBDR accepte la création d'index de type « plein texte » (Full text) et donc le prédicat de recherche normatif qui va avec (CONTAINS).
VIII. Index couvrant▲
La notion d'index couvrant est intéressante. Arrêtons-nous sur un index classique et regardons comment sont traitées les données.
SELECT CLI_ID, CLI_NOM, CLI_DATE_NAISSANCE
FROM T_CLIENT_CLI
WHERE CLI_NOM = 'DUPONT'À l'évidence, un index sur la seule colonne CLI_NOM va rendre efficace la recherche. Cependant, cet index ne contient pas les données de CLI_ID [5] ni de CLI_DATE_NAISSANCE. Pour fournir toutes les informations, le moteur SQL est donc dans l'obligation, une fois qu'il a trouvé les clients de nom DUPONT dans l'index, de se reporter vers la table afin de compléter les données avec le CLI_ID et la date de naissance. Cela oblige bien évidemment à lire des données supplémentaires.
Il est possible d'éviter cette double lecture (index + table) en utilisant la notion d'index couvrant.
Un index est dit couvrant, si la seule lecture de l'index suffit à récupérer toutes les informations nécessaires au traitement de la requête.
CREATE INDEX X_CLI_NOMIDDN ON T_CLIENT_CLI (CLI_NOM, CLI_ID, CLI_DATE_NAISSANCE)N'oblige plus à cette double lecture. On économise ainsi du temps et l'optimisation qui en ressort est meilleure.
Certains SGBDR, comme SQL Server, permettent de créer des index dont certaines colonnes sont incluses en redondance bien que ne faisant pas partie de la clef d'index.
CREATE INDEX X_CLI_NOMIDDN ON T_CLIENT_CLI (CLI_NOM) INCLUDE (CLI_ID, CLI_DATE_NAISSANCE)IX. Qualité d'un index▲
IX-A. Index une étoile▲
Est qualifié d'une étoile un index qui :
- rend le filtre WHERE « cherchable »
SELECT *
FROM T_CLIENT_CLI
WHERE CLI_NOM = 'DUVAL'
AND CLI_PRENOM = 'Paul'
CREATE INDEX X_CLI_NOMPRE ON T_CLIENT_CLI (CLI_NOM, CLI_PRENOM)IX-B. Index deux étoiles▲
Est qualifié de deux étoiles un index qui :
- est un index une étoile
- couvre le SELECT
SELECT CLI_NOM, CLI_PRENOM
FROM T_CLIENT_CLI
WHERE CLI_NOM = 'DUVAL'
AND CLI_PRENOM = 'Paul'
CREATE INDEX X_CLI_NOMPRE ON T_CLIENT_CLI (CLI_NOM, CLI_PRENOM)Il s'agit bien de la notion de couverture à l'aide d'un index de la clause SELECT (index couvrant).
IX-C. Index trois étoiles▲
Est qualifié de trois étoiles un index qui :
- est un index deux étoiles
- assure le tri
SELECT CLI_NOM, CLI_PRENOM
FROM T_CLIENT_CLI
WHERE CLI_NOM = 'DUVAL'
AND CLI_PRENOM BETWEEN 'A' AND 'M'
ORDER BY CLI_NOM, CLI_PRENOM
CREATE INDEX X_CLI_NOMPRE ON T_CLIENT_CLI (CLI_NOM, CLI_PRENOM)Comme on le voit, cet index propose déjà les données triées afin d'accomplir la clause ORDER BY. Aucun effort supplémentaire ne devra être fait pour assurer le tri.
IX-D. Index quatre étoiles▲
Est qualifié de quatre étoiles un index qui :
- est un index trois étoiles
- assure le regroupement (clause GROUP BY)
SELECT CLI_NOM, CLI_PRENOM, COUNT(*)
FROM T_CLIENT_CLI
WHERE CLI_NOM = 'DUVAL'
AND CLI_PRENOM BETWEEN 'A' AND 'M'
GROUP BY CLI_NOM, CLI_PRENOM
ORDER BY CLI_NOM, CLI_PRENOM
CREATE INDEX X_CLI_NOMPRE ON T_CLIENT_CLI (CLI_NOM, CLI_PRENOM)La clause GROUP BY nécessite elle aussi une forme de tri. Si l'index est trié dans le sens du regroupement, le moteur n'aura aucun effort à faire pour assurer cette clause.
X. Index de vue▲
Certains SGBDR (Oracle, SQL Server) proposent de créer des vues indexées, c'est-à-dire des vues qui contiennent des données. En fait, il s'agit tout simplement d'offrir un mécanisme automatisé de précalcul synchrone ou asynchrone. Bien qu'il y ait redondance, les données peuvent souvent être concentrées, notamment lorsqu'il y a d'importants calculs d'agrégation (SUM, AVG, COUNT…).
L'avantage d'un tel concept, c'est que certaines requêtes vont devenir extrêmement rapides, même sur de très forts volumes de données, puisque le calcul de l'index de la vue se fait au fil de l'eau.
Pour un exemple de l'efficacité extrême de cette technique, voir le papier que j'ai écrit sur l'indexation : https://sqlpro.developpez.com/optimisation/indexation/.
XI. Index et statistiques▲
Derrière chaque index figurent des statistiques qui aident le moteur relationnel à décider quel index il doit utiliser en fonction de la valeur des données recherchées.
Ainsi lorsque plusieurs index sont candidats à traiter une même requête, le moteur relationnel estime le nombre de lignes qui vont être récupérées s'il utilise tel ou tel index. Grâce à ce choix, il permet d'économiser du volume ce qui se traduit en temps d'exécution.
C'est bien évidemment le rôle primordial de l'optimiseur.
XII. Métadonnées d'index▲
Certains SGBDR permettent d'interroger de nombreuses vues système afin de connaître la qualité des index, leur utilisation, voire les index manquants. C'est intéressant pour rapidement remédier à un déficit d'indexation.
Par exemple, pour SQL Server, on peut s'intéresser aux vues et fonctions tables suivantes.
Pour connaître les index et les colonnes indexées :
- sys.indexes ;
- sys.index_columns.
Pour connaître les index xml :
- sys.xml_indexes.
Pour connaître les index plein texte :
- sys.fulltext_index_catalog_usages ;
- sys.fulltext_indexes ;
- sys.fulltext_index_columns.
Pour rendre compte de la fragmentation des index :
- sys.dm_db_index_physical_stats() ;
- sys.dm_db_index_operational_stats().
Pour connaître les index manquants :
- sys.dm_db_missing_index_groups ;
- sys.dm_db_missing_index_group_stats ;
- sys.dm_db_missing_index_columns() ;
- sys.dm_db_missing_index_details.
DECLARE @SQL NVARCHAR(max)
SET @SQL = ''
SELECT @SQL = @SQL +
'CREATE INDEX X_' + REPLACE(CAST(NEWID() AS VARCHAR(64)), '-', '_')
+ ' ON ' + statement +' ('
+ CASE WHEN equality_columns IS NOT NULL
AND inequality_columns IS NOT NULL
THEN equality_columns + ', ' + inequality_columns
WHEN equality_columns IS NOT NULL THEN equality_columns
WHEN inequality_columns IS NOT NULL THEN inequality_columns
END + ') '
+ CASE WHEN included_columns IS NOT NULL
THEN ' INCLUDE (' + included_columns +') '
END
+ ';'
FROM sys.dm_db_missing_index_details m
EXEC (@SQL);Cette procédure crée tous les index manquants dans une base de données SQL Server.
XIII. NOTES▲
- Rudi Bruchez m'a fait remarquer qu'au Japon, les immeubles d'une même rue, sont numérotés par ordre de construction, ce qui ne facilite pas la recherche !
- À l'exception des index textuels qui font l'objet d'un module particulier de la norme SQL : ISO/IEC 13249-2:2003 (Information technology -- Database languages -- SQL multimedia and application packages -- Part 2: Full-Text).
- Mais aussi ALTER INDEX, DROP INDEX…
- Pour la définition d'un index cluster, voir http://blog.developpez.com/sqlpro?title=index_cluster_qu_est_ce_que_c_est.
- Pour ce qui est de la colonne CLI_ID, elle peut être contenue dans l'index sur CLI_NOM. Tout dépend de votre SGBDR. En effet, si votre SGBDR utilise la clef primaire de la table comme index cluster, il y a fort à parier que c'est cette information qui servira de repère pour retrouver les lignes de la table.
- Sous Oracle, elles sont appelées vues matérialisées.