




Préambule▲
NOTA : la structure de la base de données exemple, ainsi qu'une version des principales bases utilisées sont disponibles dans la page « La base de données exemple ».
Si les SGBDR sont dotés d'un optimiseur, cela n'empêche pas ce dernier de se tromper ou d'être limité par le carcan de votre expression de requête. De plus l'optimiseur étant interne au SGBDR, il n'a aucune influence sur le SGBDR lui-même, la machine ni l'infrastructure du réseau, élément décisif en matière de rapidité de traitement des flux de données.
Voici donc, point par point, les éléments qu'il faut prendre en considération pour « booster » votre SGBDR et l'exécution des requêtes SQL !
1. L'environnement▲
L'environnement informatique, c'est-à-dire l'architecture globale du SI, a une influence déterminante sur les performances du SGBDR et donc sur la vitesse à laquelle vos utilisateurs vont accéder aux données.
L'indispensable est un serveur dédié pour le SGBDR surtout s'il est en Client/Serveur. L'utile est de paramétrer l'OS du serveur sur lequel travaille le SGBDR de façon à ce que le serveur dispose de ressources adéquates.
On veillera à mettre des dispositifs d'accès adéquats en fonction du nombre d'utilisateurs simultanés et de la charge qu'ils induisent. Le mieux étant un réseau déterministe, ce que hélas Ethernet n'est pas. Mais on pourra par exemple employer plusieurs cartes réseau pour un même serveur pour des groupes d'utilisateurs ou sous-réseaux distincts.
On peut aussi employer des dispositifs accélérant le débit comme de la connexion fibre optique, ou des switch plutôt que des hubs. Dans ce dernier cas, des switch administrables présentent un intérêt majeur, celui de pouvoir répartir la charge…

Voici un tableau dont on peut s'inspirer :
|
utilisateurs simultanés |
15 |
15 |
50 |
50 |
300 |
300 |
|
débit |
faible |
fort |
faible |
fort |
faible |
fort |
|
architecture |
10 Mo/s, 1 carte réseau |
100 Mo/s, 1 carte réseau |
100 Mo/s, 1 à 2 cartes réseau |
100 Mo/s, 1 à 4 cartes réseau + switch frontal |
1 Go/s, 1 carte réseau FO + switch frontal |
1 Go/s, 2 à 4 cartes réseau en FO + switch frontal cascadé |
FO : fibre optique
Au-delà, la répartition de charge passe par des techniques de clustering. Dans ce cas entrent en compte les phénomènes de réplication et il vaut mieux prévoir un développement en mode « client serveur déconnecté ».
Des adresses fixes des ressources du réseau sont préférables.
CE QUI FAIT GAGNER DU TEMPS…
Une infrastructure réseau adaptée à la charge, où le nombre de collisions va être minime, voire nul… C'est-à-dire :
- des interfaces réseau rapides (fibre, switch…) ;
- des sous-réseaux parallélisés ;
- un protocole réseau déterministe (100 VG anylan, SPX/IPX…) ;
- la répartition de la charge par les dispositifs d'interface administrables et/ou un ensemble de serveurs.
2. Le serveur physique ou « la machine »▲
Un SGBDR ne fonctionne correctement que sur une machine qui lui est dédiée. Toute autre solution d'exploitation est à proscrire.
La machine est donc un PC de type serveur.
ATTENTION : un PC de base ne peut en aucun cas être reconverti en serveur, car l'architecture interne d'un serveur n'a rien à voir avec un PC destiné à une utilisation personnelle. Ainsi un serveur est taillé pour paralléliser des flux de données et accéder rapidement aux ressources disque, tandis qu'un PC personnel est plutôt conçu pour traiter rapidement des routines graphiques…

On vérifiera que le serveur choisi possède au moins les caractéristiques et équipements suivants :
- alimentation redondante, répartissant la charge et extractible à chaud (hot swap et hot plug) ;
- mémoire RAM autocorrective (ECC) ;
- cartes réseau redondantes (IPSEC) ;
- ondulation électrique (UPS) ;
- disques durs redondants (RAID) ;
- système de sauvegarde des données sur support physique externe.
L'alimentation redondante permet de continuer l'exploitation du serveur malgré une panne de ce sous-système, ainsi que son remplacement à chaud. Il est particulièrement recommandé de disposer d'une alimentation de secours de dépannage.
La mémoire RAM autocorrective ECC (Error Checking and Correction) est une mémoire qui isole les parties abimées de l'espace mémoire et en interdit l'accès dynamiquement, ce qui empêche la survenance des erreurs. Elle doit être en quantité suffisante par rapport à la taille de la base. Il n'est pas rare de définir une taille de RAM d'au moins 256 Mo + taille de la base pour le serveur. Si par exemple votre base de données fait 800 Mo, une RAM de plus de 1 Go est souhaitable. Ainsi la quasi-totalité des données servies pourront être montées en mémoire afin d'assurer un temps d'accès bien inférieur à la lecture du disque.
On a tout intérêt à prévoir au moins une carte réseau redondante et lui affecter une adresse logique supplémentaire. C'est plus facile lorsque la carte tombe en panne de dévier le trafic vers une carte déjà installée que d'éteindre le serveur pour remplacer la carte !
Un onduleur est un dispositif électronique permettant de pallier un défaut d'alimentation électrique pendant un temps restreint. Contrairement à une idée reçue, les onduleurs ne sont pas destinés à filtrer le courant électrique et en principe ne protègent pas de la surtension ou des parasites. Pour cela il faut un dispositif complémentaire à l'onduleur, et c'est pourquoi il existe des onduleurs « on line » et « off line ». Pour un serveur il faut toujours utiliser un onduleur « on line » doté d'une sortie logique afin d'informer le serveur d'une panne de courant, pour que l'extinction du serveur se fasse dans de bonnes conditions, ou bien qu'un groupe électrogène, qui doit prendre le relai, soit démarré.

REMARQUE : le talon d'Achille d'un serveur est les disques et sur ces disques se trouve le capital « savoir » de l'entreprise, c'est-à-dire les données. La plupart des défaillances matérielles des systèmes informatiques viennent des alimentations et des disques durs des PC qui fonctionnent 24 heures/24… C'est donc sur ces éléments qu'il convient d'être le plus exigeant.
En ce qui concerne les disques, tous les éditeurs de SGBDR un tant soit peu sérieux, recommandent une technologie de contrôleur disque de type RAID en SCSI.
Rappelons la définition du système RAID (Redundant Array of Inexpensive Disks) : un ensemble de disques dans lesquels une partie de la capacité physique est utilisée pour y stocker de l'information redondante. Cette information redondante permet la régénération des données perdues. Les systèmes RAID se caractérisent par différents niveaux dont les plus connus sont numérotés de 0 à 10 (en fait, 0, 1, 3, 4, 5, 6 7 et 10). Le niveau RAID 5 constitue une bonne sécurité combinée à une bonne tolérance à la panne, puisqu'en principe, un disque endommagé peut être remplacé « à chaud », c'est-à-dire sans interruption du fonctionnement du serveur.
Le SCSI (Small Computer System Interface ) est particulièrement intéressant parce qu'il s'agit d'un système « intelligent » de gestion de l'espace disque et de ses antémémoires qui sollicite notablement moins le processeur que les technologies classiques comme l'IDE. Le débit des périphériques SCSI est plus important et il est multitâche alors que l'IDE est monotâche.
Un dispositif physique de sauvegarde des données : une mauvaise habitude consiste à croire qu'il suffit de se doter de la technologie RAID pour d'être à l'abri de tout problème et donc de faire l'impasse sur un dispositif de sauvegarde. C'est une hérésie !
Une sauvegarde implique une réelle délocalisation des données pour parer à tout problème grave (dégâts des eaux, incendie, malveillance…), mais aussi tout incident d'exploitation comme la suppression malencontreuse ou malintentionnée des données.
NOTA : il ne faut pas confondre la sauvegarde logique des données que la plupart des éditeurs de SGBDR proposent dans leur package et une sauvegarde physique. En effet les SGBDR fonctionnant en permanence il n'est bien souvent pas possible de « fermer » le ou les fichiers constituant la base de données à des fins de copie lors d'une sauvegarde. Pour pallier cela, les éditeurs proposent un mécanisme qui écrit un jeu de données intègres de la base dans un fichier externe à des fins de stockage et d'archivage (sauvegarde logique). Il convient toujours d'utiliser ce principe associé à la sauvegarde physique.
ATTENTION : il ne faut jamais dépasser un taux d'occupation de l'ordre de 67 % de l'espace disque. En effet, en exploitation, votre base de données « grossit », et occupe donc une place de plus en plus grande sur le disque. Plus le disque se remplit et plus les temps d'accès sont longs. Le phénomène n'est pas linéaire. S'il est insensible lorsque le disque est faiblement rempli, il peut devenir sensible lors des lectures lorsque le disque arrive à saturation. Il peut même bloquer totalement le SGBDR en cas de modification des données. Certains OS réseau permettent de définir des alertes administratives en cas de dépassement de quotas d'espace disque. Elles sont absolument nécessaires pour une exploitation sereine et performante du SGBDR.
CE QUI FAIT GAGNER DU TEMPS…
- Un PC qui est un véritable serveur.
- De la RAM en quantité suffisante.
- Des disques SCSI.
- Un taux d'occupation d'espace disque toujours inférieur à 67 %.
3. Le Serveur logique ou SGBDR▲
Nous avons déjà dit que le SGBDR doit être installé sur une machine dédiée. Il est même conseillé de n'installer qu'une seule base en exploitation par machine. Ainsi dans le cadre de l'organisation de votre système informatique, si vous disposez d'une base de données « front-office » et d'une autre « back-office », il vous faudra opter pour deux machines indépendantes (pensez simplement à prendre exactement les mêmes, car en cas de panne de l'une il est plus facile de redémarrer l'ensemble des services sur l'autre…).
Les paramètres de l'installation du serveur peuvent avoir une grande influence sur les temps de réponse, mais aussi sur le comportement de vos requêtes. Par exemple le choix d'un jeu de caractères combiné à une collation compatible dont le tri est binaire sera bien plus rapide et efficace qu'une collation insensible à la casse et aux caractères diacritiques. Lire à ce sujet « Une question de caractères ».
Mais l'ensemble de ces paramètres étant spécifiques à chaque éditeur il est difficile d'en dire plus…
CE QUI FAIT GAGNER DU TEMPS…
- Une base exploitée, sur une machine dédiée.
- Des paramètres SGBDR adaptés (collation binaire, taille des buffers…).
4. La base de données▲
Lors de la création d'une base, il est possible de demander la création d'un fichier doté d'une taille précise. Il convient de toujours créer le fichier de la base de données avec la taille qu'aura la base de données au cours de son exploitation. Ainsi, si votre base de données doit faire à terme 3 Go, lors de la création de la base, donnez cette valeur comme taille du fichier. Les dispositifs d'autoadaptation de la taille de la base font généralement perdre du temps par le fait qu'ils fragmentent le fichier constituant la base.
Placez le fichier des données de la base sur un disque à part en évitant le disque système. Placez le fichier du journal sur un disque à part en évitant le disque système et celui contenant les données de la base.
Ceci retarde la saturation des disques et fait gagner du temps du fait de la parallélisation des tâches d'écriture du système SCSI sur deux disques physiques différents.
Si vous le pouvez, répartissez les données de votre base sur plusieurs disques par exemple en plaçant les données les plus lourdes (BLOB) sur les disques les moins performants.
Choisissez bien la taille de la page de données (c'est la granule de base pour le stockage des données de votre SGBDR). Cela se calcule en fonction de la taille de la base adulte, de la taille des disques et de la taille de la RAM…
On peut donner à titre indicatif l'échelle suivante (mieux vaut consulter la documentation de votre SGBDR) : si la taille préconisée par votre SGBDR est 8 Ko pour une base de quelques Go avec 1 Go de RAM sur des disques de 9 Go avec un OS 32 bits… alors :
|
RAM |
256 Mo |
512 Mo |
1 Go |
2 Go |
4 Go |
|
Disque |
4Go |
4Go |
9 Go |
18Go |
36Go |
|
Base |
600 Mo |
1 Go |
3 Go |
8 Go |
25 Go |
|
Page |
2 Ko |
4 Ko |
8 Ko |
16 Ko |
32 Ko |
Réglez les paramètres des structures de stockage en fonction de la place disque et du pourcentage de mise à jour.
Par exemple, les structures d'arbres pour stocker les index utilisent le plus souvent un paramètre, le « fill factor » (facteur de remplissage) qui peut être ajusté. La plupart du temps ce « fill factor » est de l'ordre de 92 à 98 %. Plus il est faible, plus l'accès à l'index sera rapide, mais plus le volume de données occupé par cet index sera important et donc couteux en termes de mise à jour. À vous de décider si vous voulez optimiser les lectures ou les écritures sur la base de données.
CE QUI FAIT GAGNER DU TEMPS…
- Créez la base de données avec une taille de fichier calculé sur le volume à l'âge adulte de la base.
- Répartissez les fichiers de données et du journal sur des disques différents, en évitant le disque système.
- Répartissez les données sur plusieurs disques, notamment les BLOBS sur les disques les moins rapides.
- Précisez une taille de page de données adaptée à la structure physique du système et au volume des données.
- Réglez les paramètres des structures de stockage des index.
5. Le modèle de données▲
Normalisez au maximum… Créez des tables les plus petites possible en externalisant dans des tables de références toutes les informations susceptibles d'être utilisées plusieurs fois.
Exemple :
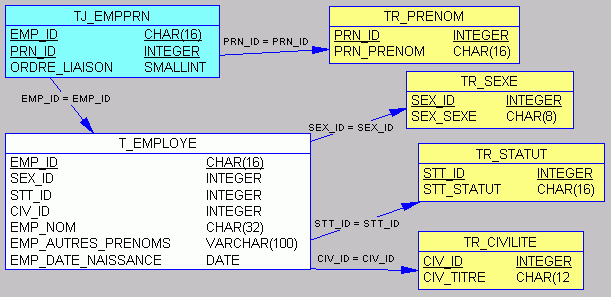
Standardisez vos types de données et leur format en utilisant des domaines. Voir définir les domaines et les utiliser… Vous n'aurez donc pas d'effort à demander au SGBDR lors de comparaisons sur des colonnes de contenu similaire (trantypage implicite). En effet si vous voulez comparer le nom d'un client défini comme VARCHAR(32) au nom d'un prospect défini comme NCHAR(25), le SGBDR devra fournir un effort supplémentaire pour homogénéiser les types de colonnes avant d'opérer la comparaison.
Choisisez des clefs dont la taille soit exactement la taille du mot du processeur (par exemple CHAR(4), INTEGER dans un OS 32 bits comme Win95, 98, NT, 2000…). Préférez des clefs purement informatiques pour vos jointures plutôt que les clefs naturelles qui découlent de votre analyse.
|
MAUVAIS |
BON |
|---|---|
|
|
|


Évitez les clefs composites. Préférez encore une fois une clef purement informatique !
Évitez les colonnes « nullables » (c'est-à-dire pouvant posséder une valeur nulle) lorsque ces dernières doivent être calculées. En particulier les données comptables et les colonnes représentant des données booléennes. Préférez mettre la valeur par défaut 0, sinon il vous faudra utiliser un opérateur COALESCE ou CASE dans les requêtes effectuant une opération arithmétique afin que les marqueurs NULL soient pris en compte en tant que 0.
Préférez les types fixes (CHAR, NCHAR…) plutôt que les types variables (VARCHAR…) chaque fois que la colonne sera sollicitée en recherche et jointure.
Utilisez au maximum les contraintes prévues dans la clause CREATE avant de passer à une programmation de triggers. Par exemple préférez le ON DELETE SET NULL et un batch de nuit pour une suppression en cascade plutôt que d'utiliser un trigger.
Modélisez vos relations de manière performante. Ainsi une hiérarchie sera avantageusement modélisée par un arbre représenté par intervalle plutôt que par une autoréférence. Évitez les jointures trop complexes en particulier sur plus de deux tables.
Indexez l'essentiel, c'est-à-dire, les clefs primaires et étrangères, les colonnes les plus sollicitées en recherche et jointure, etc. Jamais les colonnes de type BLOB ou texte libre !
Ajoutez à votre base une table des dates, plutôt que d'utiliser des fonctions de calculs temporelles.
Dénormalisez à bon escient si tout le reste a échoué dans votre recherche de gain de temps.
CE QUI FAIT GAGNER DU TEMPS…
- Normalisez vos données, entités et relations.
- Standardisez le format et le type de vos colonnes.
- Utiliser des clefs composées d'une colonne unique d'un type 32 bits et purement informatique (un entier c'est parfait).
- Évitez les colonnes nullables surtout si elles doivent être calculées.
- Préférez les types fixes (CHAR au lieu de VARCHAR) pour les colonnes fréquemment sollicitées en recherche et jointure.
- Utilisez des modèles performants pour vos relations complexes (héritage, arbres… ).
- Indexez l'essentiel, pas le superflu !
- Ajoutez une table des dates plutôt que d'utiliser des fonctions de calcul temporel.
- Dénormalisez vos relations lorsque tout le reste a échoué !
6. En développement▲
Prévoyez le formatage de vos données avant toute insertion ou mise à jour. Par exemple, assurez-vous qu'un nom de personne soit toujours en majuscules sans blanc parasite ni début ni en fin (TRIM + UPPER).
Exemple - pour ma part j'utilise systématiquement une routine de formatage comprenant les modèles suivants :
|
Format |
Règles |
|---|---|
|
DateFr |
retire tous les caractères autres que chiffres et pose des barres JJ/MM/AAAA |
|
Téléphone |
formate une chaine de chiffres en téléphone : |
|
Prénom |
ne retient que les caractères a à z (minuscule) accent, et lettres diacritiques et les caractères [' ', '-', '''] (espace, tiret, apostrophe) avec capitalisation des initiales |
|
|
formatage d'une adresse mail : |
|
IDENTIFIANT |
ne retient que les caractères A à Z (majuscule) et le caractère '_' (blanc souligné) transforme les accents et lettres diacritiques. Tous les autres caractères sont rejetés |
|
09 |
ne retient que les caractères 0 à 9 sans espace |
|
AZ_maj |
ne retient que les caractères A à Z (majuscule), transforme les accents et lettres diacritiques. Tous les autres caractères sont rejetés |
|
AZ09_maj |
ne retient que les caractères A à Z (majuscule) et 0 à 9, transforme les accents et lettres diacritiques. Tous les autres caractères sont rejetés |
|
az_min |
ne retient que les caractères a à z (minuscule), transforme les accents et lettres diacritiques. Tous les autres caractères sont rejetés |
|
az09_min |
ne retient que les caractères a à z (minuscule) et 0 à 9, transforme les accents et lettres diacritiques. Tous les autres caractères sont rejetés |
|
AZ_maj_plus |
ne retient que les caractères A à Z (majuscule) et les caractères [' ', '-', '''] (espace, tiret, apostrophe) sans aucun autre caractère (ni accent, ni lettres diacritiques) |
|
AZ09_maj_plus |
ne retient que les caractères A à Z (majuscule) et 0 à 9 et les caractères [' ', '-', '''] (espace, tiret, apostrophe) sans aucun autre caractère (ni accent, ni lettres diacritiques) |
|
az_min_plus |
ne retient que les caractères a à z (minuscule) et les caractères [' ', '-', '''] (espace, tiret, apostrophe) sans aucun autre caractère (ni accent, ni lettres diacritiques) |
|
az09_min_plus |
ne retient que les caractères a à z (minuscule) et 0 à 9 t les caractères [' ', '-', '''] (espace, tiret, apostrophe) sans aucun autre caractère (ni accent, ni lettres diacritiques) |
|
Az09plusplus |
convertit les accents et diacritiques en lettres non accentuées non diacritées |
Dès lors les recherches et comparaisons n'ont pas besoin d'être effectuées avec un paramétrage de type « insensible à la casse » + « insensible aux accents », car les données sont toujours formatées de la même façon. Ce qui accélère notablement les recherches.
Prévenez les doublons en cherchant avant insertion si la ligne n'a pas déjà été saisie. Pour des noms propres, utiliser les recherches phonétiques comme le Soundex. Voir L'art des « Soundex ».
Interdisez les orphelins… Utiliser l'intégrité référentielle et les triggers pour l'étendre afin de prévenir toute ligne orpheline.
Indexer les mots de vos textes longs s'ils doivent faire l'objet d'une recherche interne. Voir L'indexation textuelle.
CE QUI FAIT GAGNER DU TEMPS…
- Un bon formatage des données saisies et mises à jour permet des recherches plus rapides.
- L'absence de doublons évite le double comptage et l'emploi du mot clef DISTINCT.
- Une indexation textuelle évite les recherches longues et fastidieuses.
7. En exploitation▲
Surveillez le volume des données : la base est-elle trop grosse ? Pourquoi ? Le fichier du journal trop grand ? Pouvez-vous le tronquer ? La place libre du disque est-elle assez importante (au moins 33 %) ?…
Si votre SGBDR est doté d'un optimiseur statistiques, mettez à jour régulièrement les statistiques.
Réindexez de temps à autre la base, surtout après d'importantes mises à jour par lot.
Réorganisez votre base, afin d'optimiser le nombre de pages réellement utiles.
Surveillez la charge en accès et le volume du trafic : identifiez les gros consommateurs et optimisez-leur les « tuyaux ».
CE QUI FAIT GAGNER DU TEMPS…
- Ne descendez jamais en dessous de 33 % de place vide sur les disques.
- Mettez à jour les statistiques.
- Réorganisez votre base régulièrement et réindexez si besoin est.
- Surveillez la charge et adaptez les tuyaux.
8. Optimiseurs et plan de requêtes▲
La plupart des SGBDR sont dotés d'un optimiseur qui analyse de façon logique ou statistique la meilleure façon d'exécuter la requête. Il n'est pas rare que vous puissiez intervenir sur la façon dont le SGBDR et son optimiseur prétendent opérer.
La façon dont il va opérer s'appelle le « plan de requête » et montre les opérations simplistes qu'il va réaliser pour répondre à votre demande. Des SGBDR comme Oracle, MS SQL Server ou encore DB2 possèdent un outil permettant de visualiser ce plan.
Voici l'exemple de l'outil de visualisation des plans de requêtes de MS SQL Server :
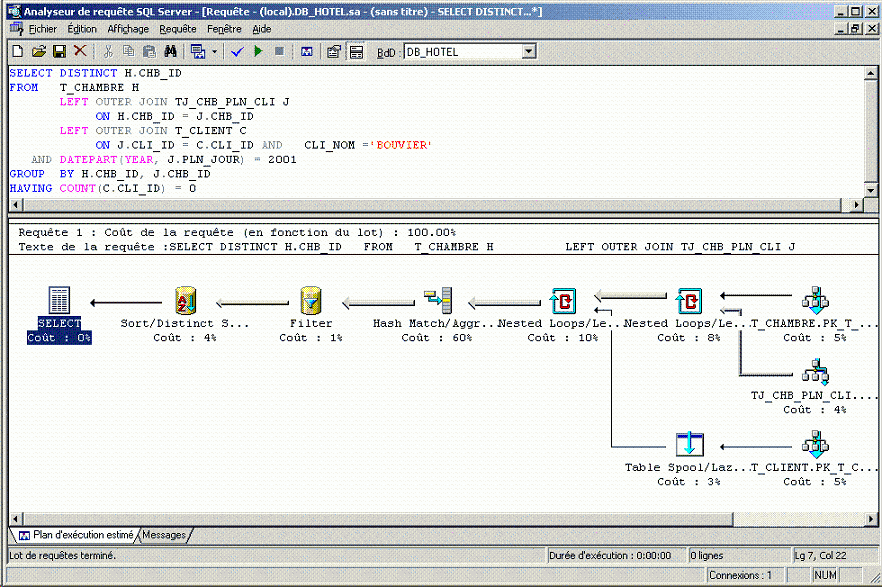
Il est certes très beau, mais la principale information manque : le temps d'exécution de chaque étape ainsi que le nombre d'entrées/sorties effectuées sur le disque… Pour cela il faut faire un clic droit sur chaque emblème, ce qui ne s'avère pas très pratique…
Suivant les éditeurs, vous pouvez intervenir directement sur le plan de requête ou bien préciser les index à utiliser ou encore vous pouvez n'être autorisé qu'à réécrire votre requête différemment afin de trouver l'optimisation la plus économe en temps et en ressources…
CE QUI FAIT GAGNER DU TEMPS…
- Choisissez le bon plan !
9. Transformations usuelles▲
Voici quelques transformations usuelles qu'il convient d'avoir à l'esprit afin d'optimiser vos requêtes.
ATTENTION : vérifiez bien que la transformation opère une réduction du temps de traitement, car cela n'est pas toujours le cas et peut dépendre de votre indexation, du type de données, des paramètres de votre SGBDR et des ressources de votre machine… Il n'y a pas de miracle, seuls des tests peuvent vous convaincre de l'efficacité d'écrire votre requête de telle ou telle manière.
|
N° |
ÉVITEZ |
PRÉFÉREZ |
|---|---|---|
|
1 |
évitez d'employer l'étoile dans la clause SELECT… Sélectionnez |
…préférez nommer les colonnes une à une Sélectionnez |
|
2 |
évitez d'employer DISTINCT dans la clause SELECT… Sélectionnez |
…lorsque cela n'est pas nécessaire Sélectionnez |
|
3 |
n'employez pas de colonne dans la clause SELECT… Sélectionnez |
…utilisez l'étoile ou une constante Sélectionnez |
|
4 |
évitez de compter une colonne… Sélectionnez |
…quand il suffit de compter les lignes Sélectionnez |
|
5 |
évitez d'utiliser le LIKE… Sélectionnez |
…si une fourchette de recherche le permet Sélectionnez |
|
6 |
évitez les jointures dans le WHERE… Sélectionnez |
…préférez l'opérateur normalisé JOIN Sélectionnez |
|
7 |
évitez les fourchettes < et > pour des valeurs discrètes… Sélectionnez |
…préférez le BETWEEN Sélectionnez |
|
8 |
évitez le IN avec des valeurs discrètes recouvrantes… Sélectionnez |
…préférez le BETWEEN Sélectionnez |
|
9 |
évitez d'employer le DISTINCT… Sélectionnez |
…si une sous-requête EXISTS vous offre le dédoublonnage Sélectionnez |
|
10 |
évitez les sous-requêtes… Sélectionnez |
…quand vous pouvez utiliser les jointures Sélectionnez |
|
11 |
évitez les sous-requêtes avec IN… Sélectionnez |
…lorsque vous pouvez utiliser EXISTS Sélectionnez |
|
12 |
transformez les COALESCE… Sélectionnez |
…en UNION Sélectionnez |
|
13 |
transformez les CASE… Sélectionnez |
…en UNION Sélectionnez |
|
14 |
transformez les EXCEPT… Sélectionnez |
…en jointures Sélectionnez |
|
15 |
transformez les INTERSECT… Sélectionnez |
…en jointure Sélectionnez |
|
16 |
transformez les UNION… Sélectionnez (l'exemple complet se trouve dans : les techniques des SGBDR) |
…en jointure Sélectionnez |
|
17 |
transformez les sous-requêtes <> ALL … Sélectionnez |
… en NOT IN Sélectionnez |
|
18 |
transformez les sous-requêtes = ANY … Sélectionnez |
… en IN Sélectionnez |
|
19 |
transformez les sous-requêtes ANY / ALL … Sélectionnez |
…en combinant sous-requêtes et agrégats Sélectionnez |
|
20 |
évitez les sous-requêtes corrélées… Sélectionnez (l'exemple complet se trouve dans : la division relationnelle…) |
…préférez des sous-requêtes sans corrélation Sélectionnez |
|
21 |
évitez les sous-requêtes corrélées… Sélectionnez |
…préférez des jointures Sélectionnez |
|
22 |
n'utilisez pas de nombre dans la clause ORDER BY… Sélectionnez |
…spécifiez de préférence les noms des colonnes, y compris dans la clause SELECT Sélectionnez |
REMARQUE : toutes les transformations ne répondent pas de la même manière à la charge. Autrement dit, en fonction du volume des données telle ou telle transformation peut s'avérer gagner du temps puis en faire perdre lorsque le volume des données s'accroit.
CE QUI FAIT GAGNER DU TEMPS…
- Transformez vos requêtes et choisissez après tests.
- Réévaluez le cout à la charge.
10. Quelques trucs▲
Filtrez au maximum en utilisant la clause WHERE, moins il y a de lignes retournées, mieux le SGBDR traitera vite les données.
Si votre SGBDR le supporte, ajoutez une clause limitant le nombre de lignes renvoyées (TOP, LIMIT…), surtout lorsque vous testez ou mettez au point votre code et que la base est exploitée. Moins le SGBDR a de données à servir, plus il sera véloce.
Projetez au minimum en utilisant la clause SELECT et des colonnes nommées. Moins il y a de colonnes retournées, mieux le SGBDR traitera rapidement votre requête.
Surnommez vos tables avec des alias les plus courts possible. Évitez de préfixer les colonnes non ambigües.
Exemple :
|
Sélectionnez |
|
Sélectionnez |
Dans un batch répétant cette requête 2000 fois, le volume de caractères inutiles aurait été de 100 Ko…
N'utilisez pas de jointure inutile pour un filtrage.
Exemple :
|
Sélectionnez |
|
Sélectionnez |
Dans une expression filtrée, placez toujours une colonne seule d'un côté de l'opérateur de comparaison.
Exemple :
|
Sélectionnez |
|
Sélectionnez |
N'utilisez pas de joker en début de mot dans le cadre d'une recherche LIKE. Si le besoin est impératif, ajoutez une colonne contenant la chaine de caractères à l'envers.
Exemple :
|
Sélectionnez |
|
Sélectionnez |
Évitez la recherche de négation (NOT) ou de différence (<>), préférez la recherche positive.
Exemple :
|
Sélectionnez |
|
Sélectionnez |
Créez des vues pour simplifier vos requêtes.
Exemple :
|
Sélectionnez |
|
Sélectionnez |
Essayez de ne jamais utiliser de BLOB (TEXT, BLOB, CLOB…) stockez vos images, vos longs textes et vos fichiers de ressources associés directement dans les fichiers de l'OS, cela désencombre la base de données qui traitera les données les plus utiles plus vite. Voir par exemple l'article « Des images dans ma base ».
Essayez de ne jamais utiliser le CASE dans les requêtes. Utilisez les transformations en UNION ou jointures au pire faites cette cuisine dans le code de l'interface cliente (voir ci-dessus n° 13).
N'utilisez pas de type UNICODE pour vos chaines de caractères si votre application n'a pas d'intérêt à être internationalisée. En effet des colonnes UNICODE (NCHAR, NVARCHAR) sont deux fois plus longues et coutent donc le double en temps de traitement par rapport à des colonnes de type CHAR ou VARCHAR…
Précisez toujours la liste de colonnes dans un ordre INSERT.
Exemple :
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
Remaniez vos requêtes de façon à lire les tables toujours dans le même ordre (par exemple l'ordre alphabétique des noms des tables) de façon à prévenir les verrous mortels et les temps d'attente trop longs dus à des interblocages.
Déchargez le serveur des tâches basiques que vous pouvez aisément faire sur le client. Par exemple si vous devez présenter l'initiale d'un nom, inutile de la demander au serveur, rapatriez les noms et sélectionnez la première lettre dans le code de l'interface cliente.
Évitez l'emploi systématique d'une clause ORDER BY.
Si l'ordre que vous voulez activer est complexe, ajoutez une colonne ORDRE et spécifiez-le manuellement.
Exemple :
|
Sélectionnez |
|
Sélectionnez |
Utilisez UNION ALL si vous ne souhaitez pas le dédoublonnage dans le résultat, cela pénalise moins le serveur.
Essayez de vous affranchir de la clause HAVING par exemple en imbriquant une sous-requête dans la clause FROM.
Un index créé sur deux colonnes ne peut pas être utilisé pour filtrer la seconde colonne, car il stocke en principe les données sur la concaténation des deux colonnes. Restructurez les index en évitant les index composites.
CREATE INDEX NDX_CLI_NOM_PRENOM ON T_CLIENT (CLI_NOM, CLI_PRENOM)
SELECT *
FROM T_CLIENT
ORDRE BY PRENOM
-- l'index ne peut être activé sur la seule colonne CLI_PRENOM, car il contient :
AIACHAlexandre
ALBERTChristian
AUZENATMichel
BACQUEMichel
BAILLYJean-François
...Activez le calcul des statistiques après des mises à jour massives.
Faites des transactions les plus courtes possible, validez vos transactions dès que possible, mettez des points de sauvegarde partiels.
Lorsqu'une requête devient trop importante, pensez à en faire une procédure stockée paramétrée, surtout si votre SGBDR prépare les requêtes.
Évitez autant que faire se peut d'utiliser des CURSOR. Préférez des requêtes mêmes complexes. Bannissez les CURSOR parcourus en arrière (une clause ORDER BY … DESC le remplace aisément). Interdisez-vous les CURSOR parcourus par bond de plus d'une ligne.
CE QUI FAIT GAGNER DU TEMPS…
- Évitez les gros pièges.
- Ajoutez de l'information : des tables, des vues, des index pour faciliter le requêtage.
11. CONCLUSION▲
Désolé, il n'y a pas de recettes miracles pour l'optimisation des requêtes. Simplement quelques grosses fautes à éviter. L'essentiel est un bon paramétrage de la machine et son environnement, du serveur et de l'OS. Le reste est spécifique à chaque SGBDR et nécessite un peu d'huile de coude et beaucoup de prudence.
Mais n'oubliez surtout pas que des tests en charge sont indispensables afin de trancher entre telle ou telle expression de requête avec le volume probable de votre base en exploitation.
À LIRE :
RAID :
- http://froverio.free.fr/raid/raid.htm
- http://www-igm.univ-mlv.fr/~dr/XPOSE/IntroductionRAID/
- http://www.gsefr.org/dossiers/db2b/pg-soft/sld052.htm
- http://www.e-c.qc.ca/fr/produits/raid.php
SCSI :
- http://www.presence-pc.com/hardware/tests/stockage/SCSIIDE/page1.shtml
- http://www.byc.ch/scsi/scsibus.html
- http://www.alyon.org/InfosTechniques/SCSI/
Onduleurs :