




Préambule▲
Ma réflexion ne date pas d'aujourd'hui — j'ai commencé ce genre de travail avant que SQL Server ne propose ce genre de service — et ai continué récemment avec des projets dans mon entreprise.
Voici donc ces éléments rassemblés dans le présent document et j'espère que vous prendrez plaisir à cette lecture.
Quelques définitions
Syntaxe
Tous les développeurs connaissent le sens du mot syntaxe (enfin, les bons développeurs… !).
Je ne ferai donc pas l'injure à nos lecteurs de recopier la notice du Petit Robert ni du grand Larousse…
Sémantique
La connaissance du sens du mot sémantique est moins répandue, d'autant qu'elle dépend du sens des mots donc de la sémantique… Loin d'être une tautologie et bien que ce charabia tende inéluctablement à vous faire sourire, je viens de vous faire pointer de l'intellect toute la difficulté à exercer une distinction entre sémantique et syntaxe…
Je ne donnerai qu'une définition par opposition de la sémantique, en indiquant que si la syntaxe s'occupe de la grammaire, la sémantique, elle, s'occupe du sens, c'est-à-dire de ce que mes mots et les phrases veulent dirent, autrement dit, des idées qu'ils véhiculent.
1. Indexation de base▲
1-1. Mots clefs et index▲
Il s'agit là d'une vieille méthode largement en usage dans les documents publiés sous forme papier. On y trouve deux modes différents : l'abstract et l'index encore appelé thésaurus.
Les abstracts sont en général utilisés dans la documentation juridique et sont placés en tête du document souvent sous le titre. Ils permettent, avant de lire la publication, de connaître le contexte juridique, c'est-à-dire quels sujets sont traités. Il s'agit essentiellement de mots ou d'expressions, rarement de phrases.
|
|
|
exemple d'abstract en entête de résumé de jugement, bulletin du SNPI |

L'index est en général une liste de certains mots savamment choisis, ou bien la totalité des noms propres cités dans un document, avec un renvoi pour chaque page où se trouve ce mot ou ce nom propre.
|
|
|
index de l'ouvrage « Introduction aux bases de données » de Chris Date |

À l'origine, les abstracts et index sont créés manuellement et de toutes pièces, soit par les auteurs, soit par les éditeurs des publications.
Avec l'apparition de l'informatique, certains mécanismes de création d'index ont vu le jour. Par exemple Word de Microsoft permet de créer un index à condition de marquer chaque mot du texte à indexer. Inconvénient : un même mot situé à différents endroits du texte doit faire l'objet d'une marque spécifique pour chaque occurrence (fastidieux). Avantage : grande latitude dans le choix des mots à indexer (précision).
Dans tous les cas (abstract ou index) nous avons des mots clefs, c'est-à-dire des mots possédant un sens fort… En effet il ne viendrait pas à l'esprit des auteurs d'indexer des mots comme « le », « mais » ou encore « je », « de » !
Une indexation manuelle d'un document électronique, lorsqu'elle est faite sérieusement reste encore un choix basique, mais excellent par sa simplicité…
1-2. Indexation automatique▲
Mais la tentation est forte de se servir de l'informatique pour indexer de manière automatique des documents à forte contenance textuelle…
Nous allons donc étudier la problématique de l'indexation dite « plain texte »…
1-2-1. Le problème▲
Soit un ensemble de textes que l'on aura, pour simplifier nos propos, stockés dans une base de données sous le format suivant :
create table TEXTE
( TXT_ID INTEGER not null primary key,
TXT_TEXTE TEXT not null)TXT_ID permettant d'identifier de quel texte il s'agit et TXT_TEXTE contenant le texte à indexer.
Voici les données qui nous serviront d'exemple pour notre démonstration :
insert into TEXTE (TXT_ID, TXT_TEXTE)
values (1, 'Le petit chat est mort.');
insert into TEXTE (TXT_ID, TXT_TEXTE)
values (2, 'Il fait beau, le soleil brille, les oiseaux chantent.');
insert into TEXTE (TXT_ID, TXT_TEXTE)
values (3, 'Comprendre et entreprendre sont les deux mamelles du commerce.');
insert into TEXTE (TXT_ID, TXT_TEXTE)
values (4, 'Prendre le temps de vivre, pour soi, mais aussi pour les autres.');
insert into TEXTE (TXT_ID, TXT_TEXTE)
values (5, 'Dans la vie il y a des hauts et des bas.');
insert into TEXTE (TXT_ID, TXT_TEXTE)
values (6, 'Ne pas confondre la basse, en fait une guitare, et la contrebasse, en fait un gros violon.');
insert into TEXTE (TXT_ID, TXT_TEXTE)
values (7, 'Il faut manger pour vivre et non vivre pour manger!');
insert into TEXTE (TXT_ID, TXT_TEXTE)
values (8, 'Partir c''est mourir un peu.');
insert into TEXTE (TXT_ID, TXT_TEXTE)
values (9, 'La mort n''est pas une fin en soi!');
insert into TEXTE (TXT_ID, TXT_TEXTE)
values (10, 'Prudence est mère de sûreté. N'est-ce pas les garçons ?');Le premier élément est de constituer une table contenant tous les mots de tous nos textes, mais sans redondance. Voici le format de cette table :
create table MOT
( MOT_ID INTEGER not null primary key,
MOT_MOT CHAR(32) not null)MOD_ID étant l'identifiant du mot et MOT_MOT le mot lui-même.
Il faut bien entendu créer une table de jointure afin de lier un mot à un texte. Appelons par exemple cette table INDEX :
create table INDEX
( TXT_ID INTEGER not null,
MOT_ID INTEGER not null,
constraint PK_INDEX primary key (MOT_ID, TXT_ID))Si nous regroupons tous les textes en un seul bloc :
Le petit chat est mort.
Il fait beau, le soleil brille, les oiseaux chantent.
Comprendre et entreprendre sont les deux mamelles du commerce.
Prendre le temps de vivre, pour soi, mais aussi pour les autres.
Dans la vie il y a des hauts et des bas.
Ne pas confondre la basse, en fait une guitare, et la contrebasse, en fait un gros violon.
Il faut manger pour vivre et non vivre pour manger!
Partir c'est mourir un peu.
La mort n'est pas une fin en soi!
Prudence est mère de sûreté. N'est-ce pas les garçons ?Nous devons constater qu'il serait souhaitable de retirer tous les signes de ponctuation afin d'isoler les mots les uns des autres… Retirons donc les virgules, points, points d'exclamation, tirets, etc.
Mettons aussi tous les caractères en minuscules (ou en majuscules !).
le petit chat est mort
il fait beau le soleil brille les oiseaux chantent
comprendre et entreprendre sont les deux mamelles du commerce
prendre le temps de vivre pour soi, mais aussi pour les autres
dans la vie il y a des hauts et des bas
ne pas confondre la basse en fait une guitare et la contrebasse en fait un gros violon
il faut manger pour vivre et non vivre pour manger
partir c est mourir un peu
la mort n est pas une fin en soi
prudence est mère de sûreté n est ce pas les garçonsUn autre problème est posé par les accents… Devons-nous les laisser ?
Le débat est plus délicat qu'il n'y paraît. Une excellente manière de procéder serait de conserver le mot avec ses accents et caractères spéciaux et une version allégée. Dans notre exemple nous retirerons toutes les lettres en dehors du jeu [a .. z] plus le caractère espace.
Notez que certains auteurs conseillent de conserver le tiret afin de préserver les mots composés…
le petit chat est mort
il fait beau le soleil brille les oiseaux chantent
comprendre et entreprendre sont les deux mamelles du commerce
prendre le temps de vivre pour soi, mais aussi pour les autres
dans la vie il y a des hauts et des bas
ne pas confondre la basse en fait une guitare et la contrebasse en fait un gros violon
il faut manger pour vivre et non vivre pour manger
partir c est mourir un peu
la mort n est pas une fin en soi
prudence est mere de surete n est ce pas les garconsNous constatons maintenant que nous avons des lettres isolées, comme « c » et « n » qui sont difficilement interprétable. Il n'y a aucun intérêt à les conserver. De même, certains mots comme « le », « il », « les », « et », c'est-à-dire, les articles, les pronoms, les conjonctions de coordination… n'ont pas un grand intérêt pour la compréhension du texte. On peut donc les retirer :
petit chat est mort
fait beau soleil brille oiseaux chantent
Comprendre entreprendre sont deux mamelles commerce
Prendre temps vivre soi autres
Dans vie hauts bas
confondre basse fait guitare contrebasse fait gros violon
faut manger vivre vivre manger
Partir est mourir peu
mort est fin soi
prudence est mere surete est garconsNous remarquons en sus que certains mots reviennent fréquemment, comme le mot « est » (verbe être conjugué). On peut aussi le retirer.
1-2-2. Les mots noirs▲
L'ensemble des mots que l'on retire s'appelle des « mots noirs »…
Dans notre exemple, ont été considérés comme mots noirs : « le », « est », « il », « les », « et », « sont », « du », « de », « pour », « mais », « aussi », « des », « pas », « non »
Une idée consiste alors à créer une table des mots noirs afin de paramétrer le retrait de ces mots noirs. Elle pourrait avoir la forme :
create table MOTS_NOIRS
(MOT_NOIR CHAR(32) not null primary key)Qui pourrait être alimentée comme suit :
insert into MOTS_NOIRS (MOT_NOIR) values ('a')
insert into MOTS_NOIRS (MOT_NOIR) values ('assez')
insert into MOTS_NOIRS (MOT_NOIR) values ('au')
insert into MOTS_NOIRS (MOT_NOIR) values ('autre')
insert into MOTS_NOIRS (MOT_NOIR) values ('autres')
insert into MOTS_NOIRS (MOT_NOIR) values ('aux')
insert into MOTS_NOIRS (MOT_NOIR) values ('avec')
insert into MOTS_NOIRS (MOT_NOIR) values ('b')
insert into MOTS_NOIRS (MOT_NOIR) values ('c')
insert into MOTS_NOIRS (MOT_NOIR) values ('ca')
insert into MOTS_NOIRS (MOT_NOIR) values ('ce')
insert into MOTS_NOIRS (MOT_NOIR) values ('cela')
insert into MOTS_NOIRS (MOT_NOIR) values ('celle')
insert into MOTS_NOIRS (MOT_NOIR) values ('celles')
insert into MOTS_NOIRS (MOT_NOIR) values ('celui')
insert into MOTS_NOIRS (MOT_NOIR) values ('ces')
insert into MOTS_NOIRS (MOT_NOIR) values ('cet')
insert into MOTS_NOIRS (MOT_NOIR) values ('cette')
insert into MOTS_NOIRS (MOT_NOIR) values ('ceux')
insert into MOTS_NOIRS (MOT_NOIR) values ('ci')
insert into MOTS_NOIRS (MOT_NOIR) values ('comme')
insert into MOTS_NOIRS (MOT_NOIR) values ('comment')
insert into MOTS_NOIRS (MOT_NOIR) values ('d')
insert into MOTS_NOIRS (MOT_NOIR) values ('dans')
insert into MOTS_NOIRS (MOT_NOIR) values ('de')
insert into MOTS_NOIRS (MOT_NOIR) values ('deja')
insert into MOTS_NOIRS (MOT_NOIR) values ('des')
insert into MOTS_NOIRS (MOT_NOIR) values ('donc')
insert into MOTS_NOIRS (MOT_NOIR) values ('dont')
insert into MOTS_NOIRS (MOT_NOIR) values ('e')
insert into MOTS_NOIRS (MOT_NOIR) values ('elle')
insert into MOTS_NOIRS (MOT_NOIR) values ('elles')
insert into MOTS_NOIRS (MOT_NOIR) values ('en')
insert into MOTS_NOIRS (MOT_NOIR) values ('enfin')
insert into MOTS_NOIRS (MOT_NOIR) values ('et')
insert into MOTS_NOIRS (MOT_NOIR) values ('f')
insert into MOTS_NOIRS (MOT_NOIR) values ('g')
insert into MOTS_NOIRS (MOT_NOIR) values ('h')
insert into MOTS_NOIRS (MOT_NOIR) values ('i')
insert into MOTS_NOIRS (MOT_NOIR) values ('il')
insert into MOTS_NOIRS (MOT_NOIR) values ('ils')
insert into MOTS_NOIRS (MOT_NOIR) values ('j')
insert into MOTS_NOIRS (MOT_NOIR) values ('je')
insert into MOTS_NOIRS (MOT_NOIR) values ('k')
insert into MOTS_NOIRS (MOT_NOIR) values ('l')
insert into MOTS_NOIRS (MOT_NOIR) values ('la')
insert into MOTS_NOIRS (MOT_NOIR) values ('le')
insert into MOTS_NOIRS (MOT_NOIR) values ('les')
insert into MOTS_NOIRS (MOT_NOIR) values ('leur')
insert into MOTS_NOIRS (MOT_NOIR) values ('leurs')
insert into MOTS_NOIRS (MOT_NOIR) values ('lors')
insert into MOTS_NOIRS (MOT_NOIR) values ('lui')
insert into MOTS_NOIRS (MOT_NOIR) values ('m')
insert into MOTS_NOIRS (MOT_NOIR) values ('ma')
insert into MOTS_NOIRS (MOT_NOIR) values ('malgre')
insert into MOTS_NOIRS (MOT_NOIR) values ('me')
insert into MOTS_NOIRS (MOT_NOIR) values ('mes')
insert into MOTS_NOIRS (MOT_NOIR) values ('mon')
insert into MOTS_NOIRS (MOT_NOIR) values ('n')
insert into MOTS_NOIRS (MOT_NOIR) values ('ne')
insert into MOTS_NOIRS (MOT_NOIR) values ('ni')
insert into MOTS_NOIRS (MOT_NOIR) values ('non')
insert into MOTS_NOIRS (MOT_NOIR) values ('nos')
insert into MOTS_NOIRS (MOT_NOIR) values ('notre')
insert into MOTS_NOIRS (MOT_NOIR) values ('nous')
insert into MOTS_NOIRS (MOT_NOIR) values ('o')
insert into MOTS_NOIRS (MOT_NOIR) values ('on')
insert into MOTS_NOIRS (MOT_NOIR) values ('ou')
insert into MOTS_NOIRS (MOT_NOIR) values ('oui')
insert into MOTS_NOIRS (MOT_NOIR) values ('p')
insert into MOTS_NOIRS (MOT_NOIR) values ('par')
insert into MOTS_NOIRS (MOT_NOIR) values ('pendant')
insert into MOTS_NOIRS (MOT_NOIR) values ('pour')
insert into MOTS_NOIRS (MOT_NOIR) values ('puis')
insert into MOTS_NOIRS (MOT_NOIR) values ('q')
insert into MOTS_NOIRS (MOT_NOIR) values ('qu')
insert into MOTS_NOIRS (MOT_NOIR) values ('quand')
insert into MOTS_NOIRS (MOT_NOIR) values ('quant')
insert into MOTS_NOIRS (MOT_NOIR) values ('que')
insert into MOTS_NOIRS (MOT_NOIR) values ('quel')
insert into MOTS_NOIRS (MOT_NOIR) values ('quelle')
insert into MOTS_NOIRS (MOT_NOIR) values ('quelles')
insert into MOTS_NOIRS (MOT_NOIR) values ('quelque')
insert into MOTS_NOIRS (MOT_NOIR) values ('quelques')
insert into MOTS_NOIRS (MOT_NOIR) values ('quels')
insert into MOTS_NOIRS (MOT_NOIR) values ('qui')
insert into MOTS_NOIRS (MOT_NOIR) values ('quoi')
insert into MOTS_NOIRS (MOT_NOIR) values ('r')
insert into MOTS_NOIRS (MOT_NOIR) values ('s')
insert into MOTS_NOIRS (MOT_NOIR) values ('sa')
insert into MOTS_NOIRS (MOT_NOIR) values ('sans')
insert into MOTS_NOIRS (MOT_NOIR) values ('se')
insert into MOTS_NOIRS (MOT_NOIR) values ('si')
insert into MOTS_NOIRS (MOT_NOIR) values ('sous')
insert into MOTS_NOIRS (MOT_NOIR) values ('sur')
insert into MOTS_NOIRS (MOT_NOIR) values ('t')
insert into MOTS_NOIRS (MOT_NOIR) values ('ta')
insert into MOTS_NOIRS (MOT_NOIR) values ('tandis')
insert into MOTS_NOIRS (MOT_NOIR) values ('tant')
insert into MOTS_NOIRS (MOT_NOIR) values ('te')
insert into MOTS_NOIRS (MOT_NOIR) values ('tel')
insert into MOTS_NOIRS (MOT_NOIR) values ('telle')
insert into MOTS_NOIRS (MOT_NOIR) values ('telles')
insert into MOTS_NOIRS (MOT_NOIR) values ('tels')
insert into MOTS_NOIRS (MOT_NOIR) values ('tes')
insert into MOTS_NOIRS (MOT_NOIR) values ('toi')
insert into MOTS_NOIRS (MOT_NOIR) values ('ton')
insert into MOTS_NOIRS (MOT_NOIR) values ('toujours')
insert into MOTS_NOIRS (MOT_NOIR) values ('tous')
insert into MOTS_NOIRS (MOT_NOIR) values ('tout')
insert into MOTS_NOIRS (MOT_NOIR) values ('toute')
insert into MOTS_NOIRS (MOT_NOIR) values ('toutes')
insert into MOTS_NOIRS (MOT_NOIR) values ('trop')
insert into MOTS_NOIRS (MOT_NOIR) values ('tu')
insert into MOTS_NOIRS (MOT_NOIR) values ('u')
insert into MOTS_NOIRS (MOT_NOIR) values ('un')
insert into MOTS_NOIRS (MOT_NOIR) values ('une')
insert into MOTS_NOIRS (MOT_NOIR) values ('v')
insert into MOTS_NOIRS (MOT_NOIR) values ('voici')
insert into MOTS_NOIRS (MOT_NOIR) values ('voila')
insert into MOTS_NOIRS (MOT_NOIR) values ('vos')
insert into MOTS_NOIRS (MOT_NOIR) values ('votre')
insert into MOTS_NOIRS (MOT_NOIR) values ('vous')
insert into MOTS_NOIRS (MOT_NOIR) values ('w')
insert into MOTS_NOIRS (MOT_NOIR) values ('x')
insert into MOTS_NOIRS (MOT_NOIR) values ('y')
insert into MOTS_NOIRS (MOT_NOIR) values ('z')Mais attention ! Ne pas placer dans cette table tous les mots qui vous paraissent inintéressants… En effet certains mots qui paraissent de faible intérêt peuvent avoir un sens très précis. Voici quelques exemples de mots à ne pas faire figurer en mots noirs : « car », « or », « mais », « est », « du », « pas », « son ». Pourquoi ? Lisez la phrase suivante, qui, je vous l'avoue est un peu tirée par les cheveux :
CAR de transport couleur OR, roulant vers l'EST contenant du MAÏS ayant payé son DÛ et fait quelques PAS dans la neige au SON de la cornemuse.
Enfin, parmi les mots noirs, on peut rajouter les chiffres romains, qui sont souvent utilisés pour numéroter des paragraphes de textes :
Voici donc quelques ajouts de plus :
insert into MOTS_NOIRS (MOT_NOIR) values ('ii')
insert into MOTS_NOIRS (MOT_NOIR) values ('iii')
insert into MOTS_NOIRS (MOT_NOIR) values ('iv')
insert into MOTS_NOIRS (MOT_NOIR) values ('vi')
insert into MOTS_NOIRS (MOT_NOIR) values ('vii')
insert into MOTS_NOIRS (MOT_NOIR) values ('viii')
insert into MOTS_NOIRS (MOT_NOIR) values ('ix')
insert into MOTS_NOIRS (MOT_NOIR) values ('xi')
insert into MOTS_NOIRS (MOT_NOIR) values ('xii')
insert into MOTS_NOIRS (MOT_NOIR) values ('xiii')
insert into MOTS_NOIRS (MOT_NOIR) values ('xiv')
insert into MOTS_NOIRS (MOT_NOIR) values ('xv')
insert into MOTS_NOIRS (MOT_NOIR) values ('xvi')
insert into MOTS_NOIRS (MOT_NOIR) values ('xvii')
insert into MOTS_NOIRS (MOT_NOIR) values ('xviii')
insert into MOTS_NOIRS (MOT_NOIR) values ('xix')
insert into MOTS_NOIRS (MOT_NOIR) values ('xx')
insert into MOTS_NOIRS (MOT_NOIR) values ('xxi')
insert into MOTS_NOIRS (MOT_NOIR) values ('xxii')
insert into MOTS_NOIRS (MOT_NOIR) values ('xxiii')
insert into MOTS_NOIRS (MOT_NOIR) values ('xxiv')
insert into MOTS_NOIRS (MOT_NOIR) values ('xxv')
insert into MOTS_NOIRS (MOT_NOIR) values ('xxvi')
insert into MOTS_NOIRS (MOT_NOIR) values ('xxvii')
insert into MOTS_NOIRS (MOT_NOIR) values ('xxviii')
insert into MOTS_NOIRS (MOT_NOIR) values ('xxix')
insert into MOTS_NOIRS (MOT_NOIR) values ('xxx')
...et ainsi de suite en considérant que les lettres L, C, D et M représentent respectivement cinquante, cent, cinq cents et mille. Exemple : 1953 = MDCCCCLIII.
On pourrait aussi élargir notre table des mots noirs, à quelques mots supplémentaires comme :
certains
certaines
aucun
aucune
soit
moins
plus
avant
arriere
devant
derriere
rien
fois
mi
es
ex
...Pour mémoire, SQL Server de Microsoft utilise un fichier de mots noirs, pour son indexation textuelle qui est le suivant :
II
1
III
2
IV
3
VI
4
VII
5
VIII
6
XI
7
XII
8
XIII
9
XIV
0
XIX
$
XV
a
b
c
d
e
f
g
h
i
j
k
l
m
n
o
p
q
r
s
t
u
v
w
x
y
z
XVI
XVII
XVIII
XX
XXI
XXII
XXIII
XXIV
XXIX
XXV
XXVI
XXVII
XXVIII
XXX
XXXI
XXXII
XXXIII
XXXIV
XXXIX
XXXV
XXXVI
XXXVII
XXXVIII
a
adieu
afin
ah
ai
aie
aient
aies
ait
al.
alerte
allô
alors
apr.
après
arrière
as
attendu
attention
au
aucun
aucune
aucunes
aucuns
audit
auquel
aura
aurai
auraient
aurais
aurait
auras
aurez
auriez
aurions
aurons
auront
autant
autre
autres
autrui
aux
auxdites
auxdits
auxquelles
auxquels
avaient
avais
avait
avant
avec
avez
aviez
avions
avoir
avons
ayant
ayante
ayantes
ayants
ayez
ayons
aïe
bah
barbe
basta
beaucoup
bernique
bien
bigre
billiard
bis
bof
bon
bougre
boum
bravissimo
bravo
car
ce
ceci
cela
celle
celles
celui
centième
centièmes
cents
cependant
certaines
certains
ces
cet
cette
ceux
chacun
chacune
chaque
chez
chic
chiche
chouette
chut
ciao
ciel
cinq
cinquante
cinquantième
cinquantièmes
cinquième
cinquièmes
clac
clic
comme
comment
concernant
contre
corbleu
coucou
couic
crac
cric
crénom
da
dame
damnation
dans
de
debout
depuis
derrière
des
desdites
desdits
desquelles
desquels
deux
deuxième
deuxièmes
devaient
devais
devait
devant
devante
devantes
devants
devez
deviez
devions
devoir
devons
devra
devrai
devraient
devrais
devrait
devras
devrez
devriez
devrions
devrons
devront
dia
diantre
dix
dixième
dixièmes
dois
doit
doive
doivent
doives
donc
dont
doucement
douze
douzième
douzièmes
du
dudit
due
dues
duquel
durant
durent
dus
dussent
dut
dès
dû
dût
eh
elle
elles
en
encontre
endéans
entre
envers
es
et
eu
eue
eues
euh
eurent
eurêka
eus
eusse
eussent
eusses
eussiez
eussions
eut
eux
excepté
eûmes
eût
eûtes
fi
fichtre
fixe
flûte
foin
fors
fouchtra
furent
fus
fusse
fussent
fusses
fussiez
fussions
fut
fûmes
fût
fûtes
gare
grâce
gué
ha
halte
hardi
hein
hem
hep
heu
ho
holà
hop
hormis
hors
hou
hourra
hue
huit
huitante
huitantième
huitième
huitièmes
hum
hurrah
hé
hélas
il
ils
jarnicoton
je
jusque
la
ladite
laquelle
las
le
ledit
lequel
les
lesdites
lesdits
lesquelles
lesquels
leur
leurs
lorsque
lui
là
ma
made
mais
malgré
mazette
me
merci
merde
mes
mien
mienne
miennes
miens
milliard
milliardième
milliardièmes
millionième
millionièmes
millième
millièmes
mince
minute
miséricorde
moi
moins
mon
morbleu
motus
moyennant
mâtin
na
ne
neuf
neuvième
neuvièmes
ni
nonante
nonantième
nonantièmes
nonobstant
nos
notre
nous
nul
nulle
nulles
nuls
nôtre
nôtres
octante
octantième
oh
ohé
olé
on
ont
onze
onzième
onzièmes
or
ou
ouais
ouf
ouille
oust
ouste
outre
ouïe
où
paix
palsambleu
pan
par
parbleu
parce
pardi
pardieu
parmi
pas
passé
patatras
pechère
pendant
personne
peu
peuchère
peut
peuvent
peux
plein
plouf
plus
plusieurs
point
pouah
pour
pourquoi
pourra
pourrai
pourraient
pourrais
pourrait
pourras
pourrez
pourriez
pourrions
pourrons
pourront
pourvu
pouvaient
pouvais
pouvait
pouvant
pouvante
pouvantes
pouvants
pouvez
pouviez
pouvions
pouvoir
pouvons
premier
premiers
première
premières
psitt
pst
pu
pue
pues
puis
puisque
puisse
puissent
puisses
puissiez
puissions
purent
pus
pussent
put
pécaïre
pût
qq.
qqch.
qqn
quand
quant
quarante
quarantième
quarantièmes
quatorze
quatorzième
quatorzièmes
quatre
quatrième
quatrièmes
que
quel
quelle
quelles
quelqu'un
quelqu'une
quels
qui
quiconque
quinze
quinzième
quinzièmes
quoi
quoique
rataplan
revoici
revoilà
rien
sa
sacristi
salut
sans
saperlipopette
sapristi
sauf
savoir
se
seize
seizième
seizièmes
selon
sept
septante
septantième
septième
septièmes
sera
serai
seraient
serais
serait
seras
serez
seriez
serions
serons
seront
ses
si
sien
sienne
siennes
siens
sinon
six
sixième
sixièmes
soi
soient
sois
soit
soixante
soixantième
soixantièmes
sommes
son
sont
sous
soyez
soyons
stop
suis
suivant
sur
ta
tandis
tant
taratata
tayaut
taïaut
te
tel
telle
telles
tels
tes
tien
tienne
tiennes
tiens
toi
ton
touchant
tous
tout
toute
toutes
treize
treizième
treizièmes
trente
trentième
trentièmes
trois
troisième
troisièmes
tu
tudieu
turlututu
un
une
unième
unièmes
v'lan
va
vers
versus
veuille
veuillent
veuilles
veuillez
veuillons
veulent
veut
veux
via
vingt
vingtième
vingtièmes
vivement
vlan
voici
voilà
vos
votre
voudra
voudrai
voudraient
voudrais
voudrait
voudras
voudrez
voudriez
voudrions
voudrons
voudront
voulaient
voulais
voulait
voulant
voulante
voulantes
voulants
voulez
vouliez
voulions
vouloir
voulons
voulu
voulue
voulues
voulurent
voulus
voulussent
voulut
voulût
vous
vs
vu
vôtre
vôtres
y
zut
à
ç'a
ç'aura
ç'aurait
ç'avait
ça
çà
ès
étaient
étais
était
étant
étante
étantes
étants
étiez
étions
évohé
évoé
êtes
être
ô
ôtéOn peut constater au passage que SQL Server est fâché avec les transports en commun puisqu'il élimine le car !!!
Juste une suggestion en passant, vous pouvez aussi mettre en mots noirs les chiffres exprimés sous forme de littéraux : deux, trois quatre… onze, treize, vingt, cent, mille, etc.
Le modèle relationnel complet de notre petite application est donc le suivant :
|
|
|
Modèle conceptuel de Données (MCD) |

|
|
|
Modèle Physique de Données (MPD) |
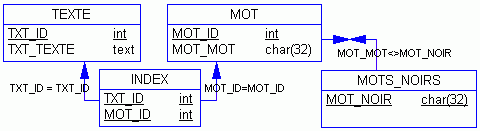
Nous pouvons maintenant procéder à l'alimentation de la table des mots, par les seuls mots retenus :
insert into MOT (MOT_ID, MOT_MOT) values (1, 'petit');
insert into MOT (MOT_ID, MOT_MOT) values (2, 'chat');
insert into MOT (MOT_ID, MOT_MOT) values (3, 'est');
insert into MOT (MOT_ID, MOT_MOT) values (4, 'mort');
insert into MOT (MOT_ID, MOT_MOT) values (5, 'fait');
insert into MOT (MOT_ID, MOT_MOT) values (6, 'beau');
insert into MOT (MOT_ID, MOT_MOT) values (7, 'soleil');
insert into MOT (MOT_ID, MOT_MOT) values (8, 'brille');
insert into MOT (MOT_ID, MOT_MOT) values (9, 'oiseaux');
insert into MOT (MOT_ID, MOT_MOT) values (10, 'chantent');
insert into MOT (MOT_ID, MOT_MOT) values (11, 'comprendre');
insert into MOT (MOT_ID, MOT_MOT) values (12, 'entreprendre');
insert into MOT (MOT_ID, MOT_MOT) values (13, 'mamelles');
insert into MOT (MOT_ID, MOT_MOT) values (14, 'commerce');
insert into MOT (MOT_ID, MOT_MOT) values (15, 'prendre');
insert into MOT (MOT_ID, MOT_MOT) values (16, 'temps');
insert into MOT (MOT_ID, MOT_MOT) values (17, 'vivre');
insert into MOT (MOT_ID, MOT_MOT) values (18, 'soi');
insert into MOT (MOT_ID, MOT_MOT) values (19, 'autres');
insert into MOT (MOT_ID, MOT_MOT) values (20, 'vie');
insert into MOT (MOT_ID, MOT_MOT) values (21, 'hauts');
insert into MOT (MOT_ID, MOT_MOT) values (22, 'bas');
insert into MOT (MOT_ID, MOT_MOT) values (23, 'confondre');
insert into MOT (MOT_ID, MOT_MOT) values (24, 'basse');
insert into MOT (MOT_ID, MOT_MOT) values (25, 'guitare');
insert into MOT (MOT_ID, MOT_MOT) values (26, 'contrebasse');
insert into MOT (MOT_ID, MOT_MOT) values (27, 'violon');
insert into MOT (MOT_ID, MOT_MOT) values (28, 'faut');
insert into MOT (MOT_ID, MOT_MOT) values (29, 'manger');
insert into MOT (MOT_ID, MOT_MOT) values (30, 'partir');
insert into MOT (MOT_ID, MOT_MOT) values (31, 'mourir');
insert into MOT (MOT_ID, MOT_MOT) values (32, 'peu');
insert into MOT (MOT_ID, MOT_MOT) values (33, 'fin');
insert into MOT (MOT_ID, MOT_MOT) values (34, 'prudence');
insert into MOT (MOT_ID, MOT_MOT) values (35, 'mere');
insert into MOT (MOT_ID, MOT_MOT) values (36, 'surete');
insert into MOT (MOT_ID, MOT_MOT) values (37, 'garcons);Dernière phase de notre algorithme, saisir les correspondances entre les mots et les textes dans la table INDEX :
insert into INDEX (TXT_ID, MOT_ID) values (1, 1);
insert into INDEX (TXT_ID, MOT_ID) values (1, 2);
insert into INDEX (TXT_ID, MOT_ID) values (1, 3);
insert into INDEX (TXT_ID, MOT_ID) values (1, 4);
insert into INDEX (TXT_ID, MOT_ID) values (2, 5);
insert into INDEX (TXT_ID, MOT_ID) values (2, 6);
insert into INDEX (TXT_ID, MOT_ID) values (2, 7);
insert into INDEX (TXT_ID, MOT_ID) values (2, 8);
insert into INDEX (TXT_ID, MOT_ID) values (2, 9);
insert into INDEX (TXT_ID, MOT_ID) values (2, 10);
insert into INDEX (TXT_ID, MOT_ID) values (3, 11);
insert into INDEX (TXT_ID, MOT_ID) values (3, 12);
insert into INDEX (TXT_ID, MOT_ID) values (3, 13);
insert into INDEX (TXT_ID, MOT_ID) values (3, 14);
insert into INDEX (TXT_ID, MOT_ID) values (4, 15);
insert into INDEX (TXT_ID, MOT_ID) values (4, 16);
insert into INDEX (TXT_ID, MOT_ID) values (4, 17);
insert into INDEX (TXT_ID, MOT_ID) values (4, 18);
insert into INDEX (TXT_ID, MOT_ID) values (4, 19);
insert into INDEX (TXT_ID, MOT_ID) values (5, 20);
insert into INDEX (TXT_ID, MOT_ID) values (5, 21);
insert into INDEX (TXT_ID, MOT_ID) values (5, 22);
insert into INDEX (TXT_ID, MOT_ID) values (6, 23);
insert into INDEX (TXT_ID, MOT_ID) values (6, 24);
insert into INDEX (TXT_ID, MOT_ID) values (6, 25);
insert into INDEX (TXT_ID, MOT_ID) values (6, 26);
insert into INDEX (TXT_ID, MOT_ID) values (6, 27);
insert into INDEX (TXT_ID, MOT_ID) values (7, 17);
insert into INDEX (TXT_ID, MOT_ID) values (7, 28);
insert into INDEX (TXT_ID, MOT_ID) values (7, 29);
insert into INDEX (TXT_ID, MOT_ID) values (8, 30);
insert into INDEX (TXT_ID, MOT_ID) values (8, 31);
insert into INDEX (TXT_ID, MOT_ID) values (8, 32);
insert into INDEX (TXT_ID, MOT_ID) values (9, 4);
insert into INDEX (TXT_ID, MOT_ID) values (9, 18);
insert into INDEX (TXT_ID, MOT_ID) values (9, 33);
insert into INDEX (TXT_ID, MOT_ID) values (10, 3);
insert into INDEX (TXT_ID, MOT_ID) values (10, 34);
insert into INDEX (TXT_ID, MOT_ID) values (10, 35);
insert into INDEX (TXT_ID, MOT_ID) values (10, 36);
insert into INDEX (TXT_ID, MOT_ID) values (10, 37);1-2-3. Les requêtes▲
Il s'agit maintenant de trouver les requêtes à mettre en œuvre pour répondre à la recherche textuelle.
Une bonne manière de résoudre la chose serait de trouver une seule requête capable de traiter la majorité des cas de figure. Par exemple, paramétrer une seule requête capable de rechercher un texte contenant :
- un mot ou un autre ('VIVRE' ou 'MANGER' ou les deux) ;
- un mot et l'autre ('VIVRE' et 'MANGER') ;
- trois mots ou plus ('BASSE' et 'GUITARE' et 'CONTREBASSE') ;
- au moins deux mots sur trois (parmi 'MORT', 'SOI', 'VIVRE') ;
- etc.
requête OU
recherche de texte contenant un mot ou un autre : 'VIVRE' ou 'MANGER' (ou les deux)
select distinct t.TXT_ID
from TEXTE t join INDEX d on t.TXT_ID = d.TXT_ID
join MOT m on d.MOT_ID = m.MOT_ID
where m.MOT_MOT in ('VIVRE', 'MANGER')requête ET
recherche de texte contenant un mot et l'autre : 'VIVRE' et 'MANGER'
La requête est basée sur la même requête que précédemment, avec en plus une clause d'agrégation avec un groupage :
select distinct t.TXT_ID
from TEXTE t join INDEX d on t.TXT_ID = d.TXT_ID
join MOT m on d.MOT_ID = m.MOT_ID
where m.MOT_MOT in ('VIVRE', 'MANGER')
group by t.TXT_ID
having count(*) >= 2recherche de texte contenant trois mots : 'BASSE' et 'GUITARE' et 'CONTREBASSE'
select distinct t.TXT_ID
from TEXTE t join INDEX d on t.TXT_ID = d.TXT_ID
join MOT m on d.MOT_ID = m.MOT_ID
where m.MOT_MOT in ('BASSE', 'GUITARE', 'CONTREBASSE')
group by t.TXT_ID
having count(*) >= 3requête combinant des OU et des ET
Recherche de texte contenant au moins deux mots sur trois, parmi 'MORT', 'SOI', 'VIVRE'
select distinct t.TXT_ID
from TEXTE t join INDEX d on t.TXT_ID = d.TXT_ID
join MOT m on d.MOT_ID = m.MOT_ID
where m.MOT_MOT in ('MORT', 'SOI', 'VIVRE')
group by t.TXT_ID
having count(*) >= 2requête généralisée paramétrable
De manière générale :
select distinct t.TXT_ID
from TEXTE t join INDEX d on t.TXT_ID = d.TXT_ID
join MOT m on d.MOT_ID = m.MOT_ID
where m.MOT_MOT in ( :param1 )
group by t.TXT_ID
having count(*) >= :param2où :
- :param1 est la liste de mots séparés par des virgules ;
- :param2 le nombre d'occurrences de mot requis simultanément.
Ainsi la première requête (OU avec deux mots) peut s'exprimer :
select distinct t.TXT_ID
from TEXTE t join INDEX d on t.TXT_ID = d.TXT_ID
join MOT m on d.MOT_ID = m.MOT_ID
where m.MOT_MOT in ('VIVRE', 'MANGER')
group by t.TXT_ID
having count(*) >= 1ANNEXE : primitive en Pascal (Delphi) des fonctions de base :
Nettoyage de la chaîne de caractères, découpage de la chaîne en mots et suppression des mots noirs.
type
CelMot = record
mot : string;
idm : integer;
cle : boolean;
end;
TabMot = array of CelMot;
var
TabMotNoir : TabMot;
// ce tableau est alimenté avec la requête suivante :
// select MNR_MOT_NOIR
// from T_MOT_NOIR
// order by MNR_MOT_NOIR
// mot noir le plus long
i_mot_noir_maxi_long : integer;
//**********************************************************************//
// NETTOYAGE DE LA CHAINE DE CARACTERES //
//**********************************************************************//
function CleanStr(var aString : string) : boolean;
// en entrée, la chaîne doit être en caractères minuscules
var
i : integer;
newStr : string;
begin
CleanStr := false;
newStr := '';
for i:=1 to length(aString) do
CASE aString[i] of
// accepte tels quels les caractères de a à z et de 0 à 9
'a' .. 'z' : newStr := NewStr + aString[i];
'0' .. '9' : newStr := NewStr + aString[i];
// nettoyage des caractères accentués et divers
'à', 'â', 'ä', 'ã', 'á', 'å', 'À', 'Á', 'Â', 'Ã', 'Ä', 'Å' :
newStr := newStr + 'a';
'æ', 'Æ' :
newStr := newStr + 'ae';
'ç', 'Ç' :
newStr := newStr + 'c';
'é', 'è', 'ê', 'ë', 'É', 'È', 'Ê', 'Ë' :
newStr := newStr + 'e';
'î', 'ï', 'ì', 'í', 'Ì', 'Í', 'Î', 'Ï' :
newStr := newStr + 'i';
'ñ', 'Ñ' : newStr := newStr + 'n';
'ô', 'ö', 'ð', 'ò', 'ó', 'Ò', 'Ó', 'Ô', 'Õ', 'Ö' :
newStr := newStr + 'o';
'œ', 'Œ' : newStr := newStr + 'oe';
'ù', 'ú', 'û', 'ü', 'Ù', 'Ú', 'Û', 'Ü' :
newStr := newStr + 'u';
'ý', 'ÿ', 'Ý', 'Ÿ' : newStr := newStr + 'y';
ELSE
// dans tous les autres cas, remplacement par un espace sauf si
// espace déjà présent dans la chaîne résultat...
if newStr[length(newStr)] <> ' '
then
newStr := newStr + ' ';
END;
aString := newStr;
CleanStr := true;
end;
//**********************************************************************//
// DECOUPAGE DE LA CHAINE DE CARACTERES EN MOTS //
//**********************************************************************//
function BreakStr(aString : string; var mots : TabMot; supMotNoir : boolean; supLet : boolean) : boolean;
var
i : integer;
mot : string;
car : string;
begin
BreakStr := false;
mot := '';
// on la débarrasse de ses caractères parasites en début ou fin
aString := trim(aString);
// analyse caractère par caractère de la chaine nettoyée
for i:=1 to length(aString)
do
begin
car := copy(aString,i,1);
// c'est un espace
if car = ' '
then
begin
// pas de mot précédemment stocké
if length(mot) = 0
then
continue;
// mot d'une lettre, mais pas retenu
if (length(mot) = 1) and supLet
then
begin
mot := '';
continue;
end;
if isMotNoir(mot)
then
begin
mot := '';
continue;
end;
// mot retenu
setLength(mots,length(mots)+1);
mots[length(mots)-1].mot := mot;
mot := '';
end
else
mot := mot + car;
end;
// traitement de l'éventuel mot final
if length(mot) > 0
then
if not ((length(mot) = 1) and supLet)
then
begin
setLength(mots,length(mots)+1);
mots[length(mots)-1].mot := mot;
end;
BreakStr := true;
end;
//**********************************************************************//
// EST-CE UN MOT NOIR ? //
// (recherche dichotomique dans le tableau des mots noirs) //
//**********************************************************************//
function IsMotNoir(unMot : string) : boolean;
var
iCel : integer;
bMax, bMin : integer;
begin
IsMotNoir := false;
if length(unMot) > i_mot_noir_maxi_long
then
exit;
// recherche dichotomique dans le tableau des mots noirs.
bMin := 0;
bMax := length(TabMotNoir)-1;
while bMax <> bMin
do
begin
iCel := (bMax + bMin) div 2;
if unMot = TabMotNoir[iCel].mot
then
begin
// c'est un mot noir !!!
IsMotNoir := true;
exit;
end;
if unMot < TabMotNoir[iCel].mot
then
bMax := iCel
else
bMin := iCel;
if bMax = bMin+1
then
begin
if (unMot = TabMotNoir[bMax].mot) or (unMot = TabMotNoir[bMin].mot)
then
IsMotNoir := true;
exit;
end;
end;
end;
//**********************************************************************//
// TRI DU TABLEAU avec comptage des occurrences //
// on utilise temporairement un TStringList //
//**********************************************************************//
// Exemple, MOTS comporte les mots suivants en entrée :
// Mots[0].mot = 'perdu', Mots[0].idm = null
// Mots[1].mot = 'trouve', Mots[1].idm = null
// Mots[2].mot = 'retrouve', Mots[2].idm = null
// Mots[3].mot = 'trouve', Mots[3].idm = null
// a la sortie, on obtient :
// Mots[0].mot = 'perdu', Mots[0].idm = 1
// Mots[2].mot = 'retrouve', Mots[2].idm = 1
// Mots[1].mot = 'trouve', Mots[1].idm = 2
function SortTab(var lesMots : TabMot) : boolean;
var
ListMot : TStringList;
i,j : integer;
begin
SortTab := false;
ListMot := TStringList.create();
try
ListMot.sorted := true;
// alimentation du StringList
for i:= 0 to length(lesmots)-1
do
ListMot.add(lesmots[i].mot);
// vidage du tableau
setlength(lesmots,0);
// le tableau prend la taille du nombre de lignes du TStringList
setlength(lesmots,ListMot.count);
j := 0;
// recopie du TStrinList dans le tableau avec comptage des doublons
for i:= 0 to ListMot.count-1
do
if j = 0
then
begin
lesmots[j].mot := ListMot.strings[i];
lesmots[j].idm := 1;
j := 1;
end
else
begin
if lesmots[j].mot = ListMot.strings[i]
then
lesmots[j].idm := lesmots[j].idm +1
else
begin
j := j+1;
lesmots[j].mot := ListMot.strings[i];
lesmots[j].idm := 1;
end;
end;
finally
ListMot.free();
end;
setlength(lesmots,j+1);
SortTab := true;
end;2. Recherches sémantiques▲
Mais notre travail n'en est pas pour autant fini. En effet il est souhaitable que si dans notre index, le mot voiture n’est pas présent, mais qu'en revanche on y trouve véhicule, automobile, bagnole ou encore voitures (au pluriel), la requête effectuée nous trouve des résultats par similitude du concept. C'est la recherche sémantique…
Apparentement sémantique d'un mot
Un mot peut être apparenté à un autre de quatre manières :
- le mot est une forme fléchie (pluriel, féminin, conjugaison…) ;
- le mot est un synonyme plus ou moins proche ;
- le mot est un mot parent construit sur la même racine ;
- il s'agit d'une expression synonyme.
|
Exemple : |
hôpital |
|
formes fléchies : |
hôpitaux… |
|
synonymes : |
clinique, hospice, asile, dispensaire, polyclinique… |
|
parents : |
hospitaliser, hospitalier, hospitalisation, hospice… |
|
expression synonyme : |
établissement de santé, centre de soins, maison médicalisée… |
Il convient donc de définir dans la base de données un lien entre divers mots, lien que l'on qualifiera (forme fléchie, synonyme, parent…).
Bien entendu il faudra enrichir le « dictionnaire » de ces apparentements sémantiques ou bien acheter un tel dictionnaire sous forme de fichier électronique.
3. Mots mal orthographiés▲
Une autre problématique de la recherche est que l'utilisateur peut avoir mal orthographié un mot.
Les études menées à ce sujet ont montré que les principales anomalies d'écriture résidaient soit dans l'inversion des lettres d'un mot, soit dans une erreur de frappe ou d'orthographe.
3-1. Erreur de frappe▲
Pour retrouver un mot dont certaines lettres ont été inversées, il suffit de prendre toutes les lettres de ce mot et de les placer dans un ordre défini, l'ordre alphabétique en l'occurrence semble le plus indiqué.
Par exemple, notre utilisateur voulant trouver le mot guitare, tape malencontreusement le mot guitrae.
En conservant dans la base de données, pour chaque mot la liste de ses lettres dans l'ordre alphabétique, nous aurions stocké aegirtu. En cas d'échec de la recherche directe du mot, on peut alors lister ses lettres dans l'ordre alphabétique et tenter de retrouver un mot contenant les mêmes lettres.
Bien évidemment cette technique n'est pas une panacée, car deux mots comme portes et poster comportent les mêmes lettres, mais sont dénués de sens commun !
3-2. Orthographe défectueuse▲
Donal Knuth, a proposé il y a maintenant plusieurs décennies, une méthode simple pour tenter de retrouver un mot mal orthographié.
Il est parti du fait que si un mot était mal orthographié, il y avait fort à parier qu'en coupant le mot en deux, alors l'erreur avait toutes les chances de se trouver soit dans le demi-mot de droite, soit dans le demi-mot de gauche. Suivant cette hypothèse, il en concluait que l'autre demi-mot restait bien orthographié. Il recherchait alors dans son dictionnaire les mots commençant par le demi de gauche et ceux finissant par le demi-mot de droite. La liste de mots ainsi retrouvés devait alors comporter le mot correctement orthographié.
Par exemple, notre utilisateur voulant trouver le mot guitare, l'orthographie guithare.
L'algorithme ci-dessus présenté permettra de retrouver les mots commençant par guit… et ceux finissant par …hare, dont voici la liste :
guitare
guitariste
guitoune
cithare
4. Mesure de pertinence▲
La plupart des moteurs de recherche associés aux bases de connaissance affectent un poids aux résultats présentés, afin de proposer, en premier les résultats les plus pertinents, et en fin de liste les moins pertinents.
Sans entrer dans les détails, on peut concevoir que le poids peut être considéré comme une logique floue ou la correspondance est parfaite (valeur 1) ou vide (valeur 0). Entre les deux, différentes valeurs réelles sont possibles afin de qualifier la pertinence de la recherche.
On attribuera une valeur 1 à l'indice de pertinence lorsque tous les mots auront été trouvés exactement tels que saisis.
Pour les autres correspondances, on pourra par exemple évaluer la diminution de l'indice de chaque mot à l'aide du tableau ci-dessous :
|
correspondance |
exacte |
forme fléchie (sexe, pluriel) |
synonyme |
forme fléchie (conjuguées) |
parent |
erreur de frappe |
mauvaise orthographe |
|
100 % |
90 % |
80 % |
70 % |
60 % |
40 % |
30 % |
Exemple : L'utilisateur recherche « hôpital » et « guitare »
Résultats :
guitare, hôpital 1
guitare, hôpitaux 0,95
guitare, clinique 0,9
guitare, hospitaliser 0,8Exemple 2 : L'utilisateur recherche « hôpital » et « guithare » (erreur d'orthographe)
Résultats :
guitare, hôpital 0,65
guitare, hôpitaux 0,6
guitare, clinique 0,55
guitare, hospitaliser 0,5