




Préambule▲
Un petit rappel valant mieux qu'un bon débat, voici les huit opérations de base de l'algèbre relationnelle du Docteur CODD et leur transcription en SQL.
|
PROJECTION |
Sélectionnez |
|
SELECTION |
Sélectionnez |
|
JOINTURE |
Sélectionnez |
|
DIVISION |
Sélectionnez |
|
UNION |
Sélectionnez |
|
INTERSECTION |
Sélectionnez |
|
DIFFERENCE |
Sélectionnez |
|
PRODUIT |
Sélectionnez |
1. Définition du problème▲
Un bon exemple valant mieux qu'une explication tarabiscotée, voici la question que nous allons nous poser.
Nous sommes dans une entreprise de la grande distribution possédant des entrepôts dans différentes villes de France. Ces entrepôts peuvent abriter les produits de différents rayons. La question est : quels sont les entrepôts capables de servir TOUS les rayons ? Bien entendu nous avons une table des entrepôts et une autre des rayons…
Pour toucher du doigt la problématique de cette question, le plus simple est de visualiser ce concept ensembliste sous forme de diagrammes de Wen. Oui, je vois, cela ne vous rappelle rien hélas… mais si : les patates !
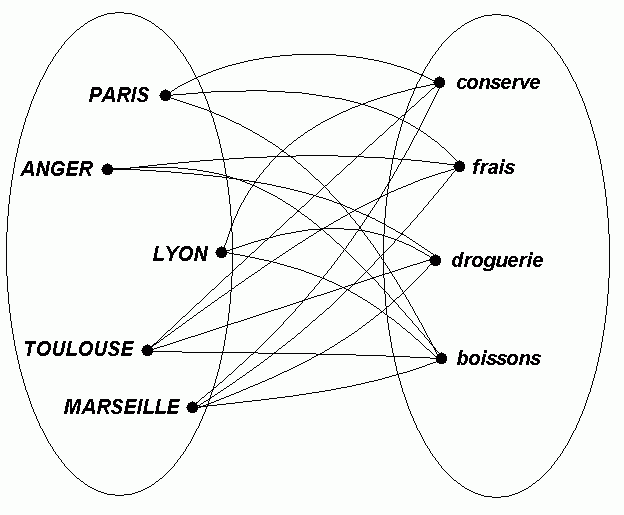
Rien de plus simple que de visualiser la réponse : il suffit de trouver les entrepôts qui sont reliés à TOUS les rayons.
La réponse est ici évidente, seules TOULOUSE et MARSEILLE satisfont aux critères de la question (comme quoi, le sud est en avance sur le nord dans notre exemple !).
Voyons maintenant le schéma tabulaire et la réponse que nous voulons obtenir…
Pour nous aider, voici le script de création de la base de données et des données :
/*************************************************/
/* LA DIVISION RELATIONNELLE, MYTHE OU RÉALITÉ ? */
/* Frédéric BROUARD brouardf@club-internet.fr */
/*************************************************/
/***********************/
/* CRÉATION DES TABLES */
/***********************/
/* table des rayons */
CREATE TABLE T_RAYON
(
RAYON_RYN CHAR(16)
)
/* tables des entrepôts */
CREATE TABLE T_ENTREPOT
(
VILLE_ETP CHAR(16,
RAYON_RYN CHAR(16)
)
/***************************/
/* ALIMENTATION DES TABLES */
/***************************/
/* alimentation de la table des rayons */
INSERT INTO T_RAYON
(RAYON_RYN) VALUES ('frais')
INSERT INTO T_RAYON
(RAYON_RYN) VALUES ('boisson')
INSERT INTO T_RAYON
(RAYON_RYN) VALUES ('conserve')
INSERT INTO T_RAYON
(RAYON_RYN) VALUES ('droguerie')
/* alimentation de la table des entrepôts */
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('PARIS', 'boisson')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('PARIS', 'frais')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('PARIS', 'conserve')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('LYON', 'boisson')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('LYON', 'conserve')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('LYON', 'droguerie')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('MARSEILLE', 'boisson')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('MARSEILLE', 'frais')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('MARSEILLE', 'conserve')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('MARSEILLE', 'droguerie')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('ANGER', 'boisson')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('ANGER', 'frais')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('ANGER', 'droguerie')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('TOULOUSE', 'boisson')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('TOULOUSE', 'frais')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('TOULOUSE', 'conserve')
INSERT INTO T_ENTREPOT
(VILLE_ETP, RAYON_RYN) VALUES ('TOULOUSE', 'droguerie')Et la vue tabulaire de cette division :
|
Dividende
|
|
Pour « prouver » que notre division est correcte il suffit de savoir que le produit cartésien du résultat avec le diviseur donne un nombre de lignes valide de la table dividende.
Autrement dit le résultat de :
SELECT * FROM T_RESULTAT, T_RAYONest entièrement inclus dans T_ENTREPOT.
2. Essai primaire▲
Une première implémentation qui vient immédiatement à l'esprit est de compter le nombre d'occurrences des rayons et de le faire coïncider avec le dénombrement des rayons des différents entrepôts :
SELECT VILLE_ETP FROM T_ENTREPOT
GROUP BY VILLE_ETP
HAVING COUNT(*) = (SELECT COUNT(*) FROM T_RAYON)Qui donne pour résultat : MARSEILLE, TOULOUSE
Cette solution, apparemment bonne, ne marche que dans des cas relativement limités :
- lorsqu'il n'y a aucune redondance de données dans la table diviseur ;
- lorsqu'il n'y a pas de rayon en sus pour un entrepôt, non recensé dans la table T_ENTREPOT.
CONTRE-EXEMPLES.
a) si la table T_RAYON contient :
T_RAYON
|
RAYON_RYN |
|---|
|
boisson |
|
frais |
|
conserve |
|
droguerie |
|
conserve |
après avoir fait par exemple :
INSERT INTO T_RAYON VALUES ('conserve')La requête précédente donne un résultat vide.
b) Si la table T_ENTREPOT contient la ligne supplémentaire suivante :
INSERT INTO T_ENTREPOT (VILLE_ETP, RAYON_RYN) VALUES ('MARSEILLE', 'boucherie')La requête donne pour résultat : TOULOUSE et 'oublie' MARSEILLE !
c) Si nous avons à la fois le cas 1 et 2, nous obtenons pour résultat TOULOUSE, ce qui est complètement faux !
d) Si nous changeons l'un des rayons des entrepôts de Marseille ou Toulouse en un rayon non référencé dans la table des T_RAYON :
UPDATE T_ENTREPOT SET RAYON_RYN = 'poissonnerie' WHERE VILLE_ETP = 'MARSEILLE' AND RAYON_RYN = 'conserve'Notre requête donne bien évidemment le même résultat, ce qui est faux, puisque seul l'entrepôt de Toulouse satisfait désormais à notre demande.
Notons qu'au sens de Codd, l'introduction du T-uple (« MARSEILLE », « boucherie ») ne fait pas obstacle ni à la définition de la division, ni au résultat que nous attendons. Nous voulons bien savoir quels sont les entrepôts capables de servir tous les rayons de la table T_RAYONS, même si certains entrepôts peuvent servir quelques rayons de plus…
De manière générale il ne faut jamais présupposer que les tables soient cohérentes, et en particulier que tous les rayons de la table des entrepôts soient recensés dans la table des rayons, ni même qu'il n'y a pas de redondance dans l'une quelconque des tables. D'autant que nos données peuvent venir de tables intermédiaires ou de vues.
Autrement dit, il peut y avoir un ou plusieurs rayons en sus dans un ou plusieurs entrepôts, cela ne doit affecter ni la division ni le résultat.
Avec les changements proposés dans les contre-exemples, voici donc le nouveau jeu de données pour tester nos requêtes :
|
Dividende
|
|
3. Raffinements▲
Nous pouvons facilement supprimer le contre-exemple a en introduisant dans notre requête un mot clef supplémentaire du SQL, le mot clef DISTINCT :
SELECT VILLE_ETP FROM T_ENTREPOT
GROUP BY VILLE_ETP
HAVING COUNT(*) =
(SELECT COUNT(DISTINCT RAYON_RYN) FROM T_RAYON)Mais cela n'élimine pas pour autant le contre-exemple b…
Pour retrouver la boucherie, et pouvoir éliminer du résultat les occurrences d'entrepôts qui disposent d'un rayon boucherie ou de tout autre rayon ne figurant pas dans la table des rayons, nous pouvons faire la requête suivante :
|
Requête |
Résultat |
|---|---|
|
Sélectionnez |
Sélectionnez |
qui dans notre jeu test retrouve le rayon boucherie.
Dès lors éliminer le rayon boucherie des occurrences de rayon figurant dans la table des entrepôts n'est plus qu'un jeu d'enfant…
|
Requête |
Résultat |
|---|---|
|
Sélectionnez |
Sélectionnez |
En imbriquant les deux requêtes, nous avons :
|
Requête |
Résultat |
|---|---|
|
Sélectionnez |
Sélectionnez |
On peut d'ailleurs éliminer le DISTINCT le plus imbriqué qui n'a plus d'importance :
|
Requête |
Résultat |
|---|---|
|
Sélectionnez |
Sélectionnez |
On obtient donc une liste restreinte des entrepôts dont les rayons figurent dans la table T_RAYON.
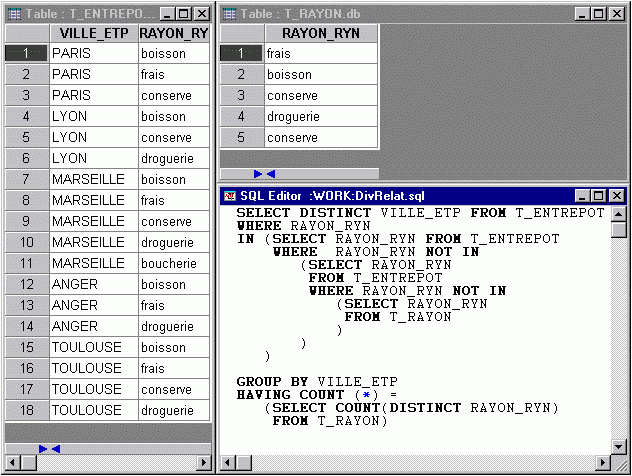
Maintenant, si nous revenons à notre requête de base, il suffit de spécifier que le rayon doit impérativement figurer dans le résultat précédent et le tour est joué !
|
Requête |
Résultat |
|---|---|
|
Sélectionnez |
Sélectionnez |
Soit, en imbriquant les deux requêtes :
4. Une solution▲
|
Requête |
Résultat |
|---|---|
|
Sélectionnez |
Sélectionnez |
Ouf ! Cela fait quand même cinq SELECT avec quatre niveaux d'imbrication pour trouver notre solution.
5. Une bonne solution▲
Joe CELKO, l'un des grands maîtres du SQL, spécialiste des requêtes les plus tordues nous livre différentes autres manières de fabriquer la division relationnelle.
Voici une implémentation un peu plus simple ne nécessitant que trois requêtes imbriquées, ce qui semble d'ailleurs être le minimum. Elle fait quand même appel à l'opérateur EXISTS qui teste l'existence de lignes d'une table dans une autre ainsi qu'à la corrélation des sous-requêtes, ce qui s'avère couteux en termes d'exécution :
SELECT DISTINCT VILLE_ETP
FROM T_ENTREPOT AS ETP1
WHERE NOT EXISTS
(SELECT *
FROM T_RAYON RYN
WHERE NOT EXISTS
(SELECT *
FROM T_ENTREPOT AS ETP2
WHERE ETP1.VILLE_ETP = ETP2.VILLE_ETP
AND (ETP2.RAYON_RYN = RYN.RAYON_RYN)))Cette requête est d'ailleurs un grand classique repris dans la plupart des manuels traitant de l'algèbre relationnelle et leur implémentation en SQL.
Voyons comment cette requête peut être traduite en langage naturel…
Pour bien la comprendre, il suffit de se mettre à la place de chacun des responsables d'entrepôt. Le responsable de l'entrepôt reçoit la liste des rayons qu'il doit servir et déclare d'un ton dédaigneux « il n'y a aucun rayon que je ne puisse pas fournir ». Évidemment les responsables capables d'une telle affirmation sont ceux des entrepôts de Marseille et Toulouse !
De manière directe, cette requête recherche les entrepôts pour qui il n'existe pas de rayon qu'ils ne peuvent pas fournir… il s'agit là, à l'évidence, d'une double négation.
6. Une solution audacieuse▲
Si votre implémentation de SQL possède l'opérateur relationnel de base permettant la différence entre deux tables, alors la solution est bien plus rapide…
SELECT DISTINCT VILLE_ETP
FROM T_ENTREPOT AS ETP1
WHERE
(SELECT RAYON_RYN
FROM T_RAYON
INTERSECT
SELECT RAYON_RYN
FROM T_ENTREPOT AS ETP2
WHERE ETP1.VILLE_ETP = ETP2.VILLE_ETP
) IS NULLMais peu de serveurs SQL disposent d'un tel opérateur hélas, alors qu'il est décrit dans le jeu de commandes de base de SQL2 (1992).
7. Une solution étrange▲
Une autre approche consiste à effectuer le produit cartésien des entrepôts distincts avec celui des différents rayons, puis de comparer avec la table T_ENTREPOT, et de sélectionner les lignes qui correspondent avec ce produit cartésien.
Le produit cartésien peut être réalisé avec le code SQL suivant :
SELECT DISTINCT ETP.VILLE_ETP, RYN.RAYON_RYN
FROM T_RAYON RYN, T_ENTREPOT ETPQui donne pour résultat :
|
VILLE_ETP |
RAYON_RYN |
|---|---|
|
ANGER |
boisson |
|
ANGER |
conserve |
|
ANGER |
droguerie |
|
ANGER |
frais |
|
LYON |
boisson |
|
LYON |
conserve |
|
LYON |
droguerie |
|
LYON |
frais |
|
MARSEILLE |
boisson |
|
MARSEILLE |
conserve |
|
MARSEILLE |
droguerie |
|
MARSEILLE |
frais |
|
PARIS |
boisson |
|
PARIS |
conserve |
|
PARIS |
droguerie |
|
PARIS |
frais |
|
TOULOUSE |
boisson |
|
TOULOUSE |
conserve |
|
TOULOUSE |
droguerie |
|
TOULOUSE |
frais |
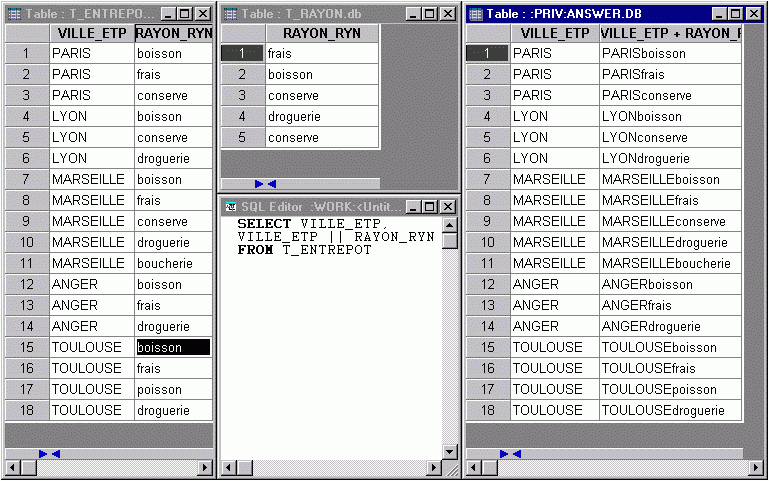
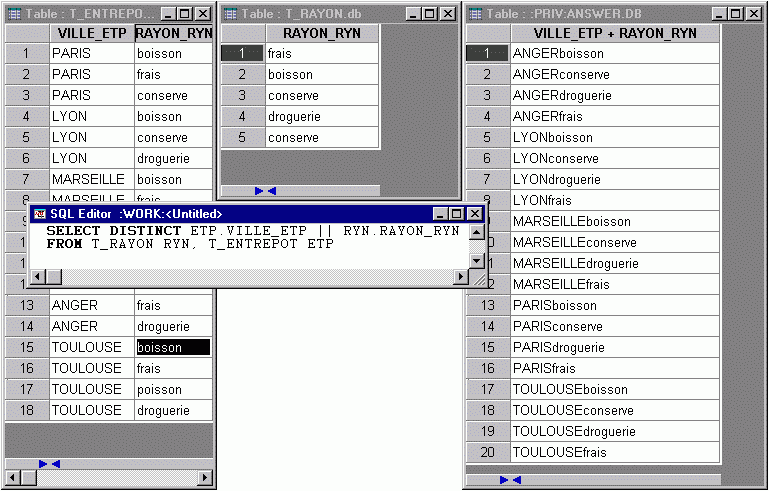
Ensuite il faut ne conserver que les entrepôts dont toutes les lignes se retrouvent de la table T_ENTREPOT par rapport à la table contenant le produit cartésien ainsi généré. En principe nous devrions utiliser une commande EXISTS, mais je vous propose une solution originale, assez concise faisant appel à la fonction standard du SQL permettant la concaténation des données en remplacement de la clause EXISTS…
SELECT VILLE_ETP
FROM T_ENTREPOT
WHERE VILLE_ETP || RAYON_RYN
IN
(SELECT DISTINCT ETP.VILLE_ETP || RYN.RAYON_RYN
FROM T_RAYON RYN, T_ENTREPOT ETP)
GROUP BY VILLE_ETP
HAVING COUNT(VILLE_ETP) =
(SELECT COUNT(DISTINCT RAYON_RYN)
FROM T_RAYON RYN)Voici maintenant une décomposition du fonctionnement de cette requête…
a) La première requête, avant le IN génère les données suivantes :
b) La seconde requête, juste après le IN, génère les données suivantes :
c) enfin le dénombrement ramène :
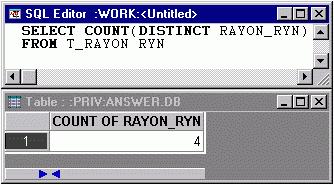
CQFD !
8. Une solution exemplaire▲
Lors d'une discussion par Internet interposé, Didier BOULLE, m'a donné une solution qu'il élabore comme suit.
« Pour ton exemple sur les entrepôts, que dirais-tu de ne pas chercher à éliminer les entrepôts qui disposent d'un rayon boucherie, mais plutôt de garder les entrepôts qui disposent des rayons de la table T_RAYON ? »
Et d'exprimer sa requête SQL ainsi :
SELECT VILLE_ETP
FROM T_ENTREPOT
WHERE RAYON_RYN IN
(SELECT RAYON_RYN
FROM T_RAYON)
GROUP BY VILLE_ETP
HAVING COUNT(*) =
(SELECT COUNT(DISTINCT RAYON_RYN)
FROM T_RAYON)Elle possède un grand mérite, celui de ne pas utiliser d'opérateur de négation ni de référence entre des SELECT imbriqués.
9. Un pas de plus▲
Un dernier raffinement peut être apporté en exigeant que la division soit « exacte », c'est-à-dire que la table dividende corresponde exactement avec les valeurs du diviseur, ni plus ni moins.
Dans le cas de notre jeu de test, cela revient à trouver quels sont les entrepôts qui disposent de tous les rayons de la table T_RAYON, mais aussi d'aucun autre. Cela pourrait être par exemple, pour des raisons d'optimisation de la distribution que de choisir un entrepôt dont tous les chefs de service seraient occupés et non seulement une partie d'entre eux.
Une première approche consiste à effectuer le produit cartésien des entrepôts avec celui des rayons, puis de comparer avec la table T_ENTREPOT, et de sélectionner les lignes qui correspondent exactement avec ce produit cartésien, ni plus ni moins.
Encore une fois, Joe Celko vient à notre rescousse en nous proposant une version harmonieuse et propre de la division exacte basée sur la double négation :
SELECT VILLE_ETP
FROM T_ENTREPOT ETP1
WHERE NOT EXISTS
(SELECT *
FROM T_RAYON
WHERE NOT EXISTS
(SELECT *
FROM T_ENTREPOT ETP2
WHERE (ETP1.VILLE_ETP = ETP2.VILLE_ETP)
AND (ETP2.RAYON_RYN = T_RAYON.RAYON_RYN)))
GROUP BY VILLE_ETP
HAVING COUNT (*) =
(SELECT COUNT(*)
FROM T_RAYON)Notons qu'elle nécessite quatre SELECT dont trois imbriqués !!!
Par exemple nous pourrions avoir une table comportant des appareils et les composants nécessaires pour fabriquer l'appareil en question, et une table des composants en stock.
Pour fabriquer un appareil, il faut impérativement disposer de tous les composants. C'est dans ce sens que l'on dit que la division doit être exacte. La question est donc : quels appareils puis-je donc fabriquer en utilisant tous les composants que j'ai en stock ?
Pour nous aider, voici le jeu de test :
CREATE TABLE T_COMPOSANT
( COMPOSANT_CPS CHAR(16) )
CREATE TABLE T_APPAREIL
( NOM_APR CHAR(16),
COMPOSANT_CPS CHAR(16) )
INSERT INTO T_COMPOSANT (COMPOSANT_CPS) VALUES ('alimentation')
INSERT INTO T_COMPOSANT (COMPOSANT_CPS) VALUES ('boîtier')
INSERT INTO T_COMPOSANT (COMPOSANT_CPS) VALUES ('tuner')
INSERT INTO T_COMPOSANT (COMPOSANT_CPS) VALUES ('moteur')
INSERT INTO T_APPAREIL (NOM_APR, COMPOSANT_CPS) VALUES ('téléviseur', 'tuner')
INSERT INTO T_APPAREIL (NOM_APR, COMPOSANT_CPS) VALUES ('téléviseur', 'alimentation')
INSERT INTO T_APPAREIL (NOM_APR, COMPOSANT_CPS) VALUES ('téléviseur', 'tube cathodique')
INSERT INTO T_APPAREIL (NOM_APR, COMPOSANT_CPS) VALUES ('téléviseur', 'boîtier')
INSERT INTO T_APPAREIL (NOM_APR, COMPOSANT_CPS) VALUES ('magnétoscope', 'alimentation')
INSERT INTO T_APPAREIL (NOM_APR, COMPOSANT_CPS) VALUES ('magnétoscope', 'tuner')
INSERT INTO T_APPAREIL (NOM_APR, COMPOSANT_CPS) VALUES ('magnétoscope', 'moteur')
INSERT INTO T_APPAREIL (NOM_APR, COMPOSANT_CPS) VALUES ('magnétoscope', 'boîtier')
INSERT INTO T_APPAREIL (NOM_APR, COMPOSANT_CPS) VALUES ('lecteur DVD', 'alimentation')
INSERT INTO T_APPAREIL (NOM_APR, COMPOSANT_CPS) VALUES ('lecteur DVD', 'boîtier')
INSERT INTO T_APPAREIL (NOM_APR, COMPOSANT_CPS) VALUES ('lecteur DVD', 'moteur')
INSERT INTO T_APPAREIL (NOM_APR, COMPOSANT_CPS) VALUES ('lecteur DVD', 'laser')La solution :
SELECT NOM_APR
FROM T_APPAREIL APR1
WHERE NOT EXISTS
(SELECT *
FROM T_COMPOSANT
WHERE NOT EXISTS
(SELECT *
FROM T_APPAREIL APR2
WHERE (APR1.NOM_APR = APR2.NOM_APR)
AND (APR2.COMPOSANT_CPS = T_COMPOSANT.COMPOSANT_CPS)))
GROUP BY NOM_APR
HAVING COUNT (*) =
(SELECT COUNT(*)
FROM T_COMPOSANT)10. Conclusion▲
Sans doute avez-vous déjà utilisé la division relationnelle sans le savoir. En tous les cas on peut regretter l'absence d'un opérateur spécifique du standard SQL qui pourrait s'appeler : DIVIDE. Dans ce cas nos requêtes s'écriraient par exemple :
SELECT *
FROM T_ENTREPOT
DIVIDE [EXACTLY] T_ENTREPOT ETP BY T_RAYON RYN
ON ETP.RAYON_RYN = RYN.RAYON_RYNDont la syntaxe serait :
SELECT liste des colonnes
FROM liste des tables
DIVIDE [EXACTLY] table dividende BY table diviseur
ON condition de référence du diviseur
WHERE ...11. Pour en savoir plus sur le sujet▲
|
SQL Avancé, Joe Celko, Vuibert |
Chapitre 20, paragraphes 2 et suivants |
|
Relational Division : Four Algorithms and Their Performance. Goetz Graefe. |
ICDE 1989: 94-101 |
|
Learning Division in Elementary School. Relational division primer even your kids could understand. Joe Celko. |
DBMS on line, Page 72 January, 1994 (Volume 7, Number 1) |
|
Fuzzy relations, ill-known values and the relational division. Patrick Bosc. |
IRISA / ENSSAT, France |
|
Fuzzy Division in Fuzzy Relational Databases. An approach. J. Galindo, J.M. Medina, M.C. Aranda |
International Journal of Fuzzy Sets and Systems, 2000 |
|
Fuzzy Identification In Fuzzy Databases. The nuanced Relational Division. N. Mouaddib. |
International Journal of Intelligent Systems, 9 (5), pp. 461-473, May 1994 |
|
Database management systems, Ramakrishnan, R |
Mac Graw Hill 2000 (second edition) p 137 |
|
Introduction aux bases de données, Chris Date Vuibert 1998 |
(6e édition) - ISBN: 2711786404 |