




Préambule▲
Voici un arbre dont les données représentent des familles de véhicules :
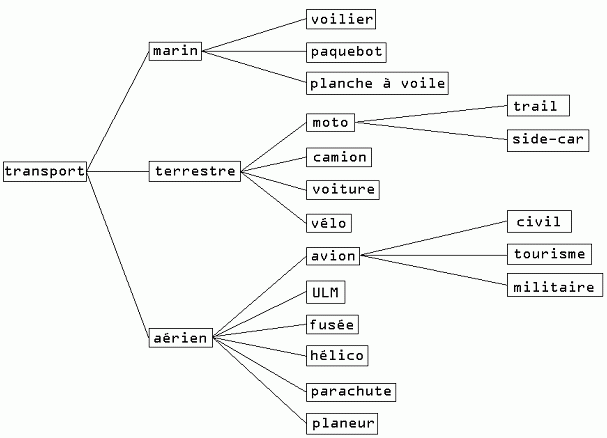
I. Représentation classique par autojointure▲
Une manière habituelle de représenter un tel arbre est de prévoir une autojointure de la table sur elle-même :
|
Sélectionnez |
|
Sélectionnez |
Ici, c'est la colonne FAM_PERE qui permet de joindre l'élément de l'arbre à son ancêtre.
Trouver le supérieur direct d'un élément n'est pas une chose difficile. Prenons par exemple le Parachute (ID = 12) ; la recherche du père s'effectue par la requête :
|
Sélectionnez |
Sélectionnez |
Mais la recherche de tous les ascendants relève d'une autre paire de manches. En général elle passe par une procédure récursive du genre :
Procedure RecherchePeres (in id integer, inout reponse string)
begin
reponse = reponse + ', ' + (SELECT FAM_LIB
FROM FAMILLE
WHERE FAM_ID = ID)
if id = 0
then
return
else
id = (SELECT FAM_PERE
FROM FAMILLE
WHERE FAM_ID = ID)
endOr, non seulement la récursivité est très coûteuse, mais certains langages de procédures stockées, comme le Transact SQL de SQL Server de Microsoft ne savent pas la gérer !
C'est pourquoi ce modèle est à proscrire lorsque :
- l'arbre est profond (plus de 5 niveaux) ;
- l'arbre est large (plus de 100 éléments sur un même niveau) ;
- l'arbre contient beaucoup de valeurs (à partir de 200 à 300 éléments) ;
- la majorité des requêtes sont des requêtes d'interrogation - SELECT (au moins 50 % des requêtes).
Et personnellement, je vous conseille de passer au modèle par intervalle dès que l'un de ces quatre critères est vrai !
II. Représentation intervallaire des arborescences▲
Une manière élégante et particulièrement performante de représenter les hiérarchies de type arborescentes est de créer des intervalles adjacents et recouvrants. Le principe est simple :
- des feuilles situées au même niveau ont des intervalles adjacents ;
- des nœuds englobant des feuilles ou d'autres nœuds ont des intervalles recouvrants.
Rappelons aussi qu'un intervalle est constitué de deux valeurs : la borne basse et la borne haute.
Nous avons alors tout dit sur cette représentation hiérarchique… Mais quel en est l'intérêt ?
Si l'insertion ou la suppression dans une telle représentation est un peu coûteuse, l'interrogation et notamment la recherche s'exprime la plupart du temps en une seule requête, comme nous allons le voir…
Pour cette modélisation, nous devons donc attribuer à toutes les entrées de notre table arborescente les deux bornes de l'intervalle que nous appellerons BG (Borne Gauche) et BD (Borne Droite). L'attribution des valeurs de ces bornes se faisant en parcourant l'arbre comme si l'on traçait une ligne pour l'entourer au plus près sans jamais croiser cette ligne avec une branche et en numérotant séquentiellement chaque feuille ou nœud une première fois par le bord gauche et une seconde fois par le bord droit (ou par analogie avec une feuille sur le recto puis le verso). En fait, on trace autour de l'arbre une ligne l'enveloppant au plus juste, comme ceci :
|
|
|
(Vous voudrez bien m'excuser pour avoir découpé cet arbre en deux, mais ce n’était pas facile de travailler ce dessin en un seul plan !) |
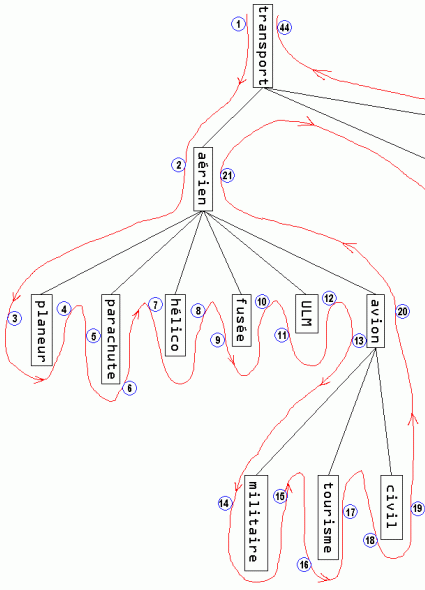
Sur cette figure, on peut déjà constater que :
- le nombre de numéros attribués est le double du nombre d'éléments ;
- toutes les feuilles ont un intervalle de longueur 1 (borne droite - borne gauche = 1) ;
- a contrario, tous les nœuds ont un intervalle de longueur supérieur à 1 (borne droite - borne gauche > 1)
Nous pouvons donc immédiatement savoir si tel ou tel élément de l'arborescence est un nœud ou une feuille.
Mais il y a aussi plus fort : nous pouvons en une seule requête ramener :
- tous les éléments, nœuds et feuilles confondus, dépendant de l'élément de référence (c'est-à-dire le sous-arbre dont la racine est l'élément de référence) ;
- tous les éléments indépendants de l'élément de référence (le ou les sous-arbres complémentaires) ;
- tous les pères d'un élément de référence.
Une autre façon de « voir » cet arbre est de le représenter par tranches englobantes. La racine est la tranche la plus large, et chaque feuille est une tranche fine :
|
|
|
représentation par tranches d'un arbre modélisé de façon intervallaire |
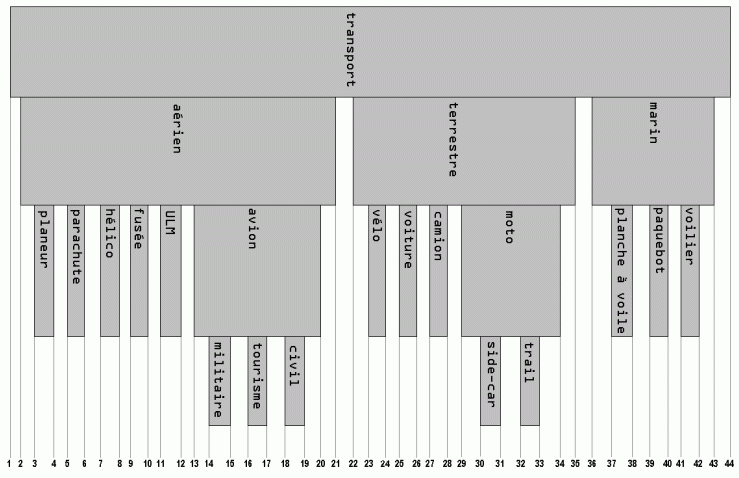
Construisons le jeu d'essai pour tester nos requêtes :
|
Sélectionnez |
|
Sélectionnez |
Voici maintenant comment s'expriment les principales requêtes de gestion de ce modèle d'arbre.
II-A. Rechercher toutes les feuilles▲
Il s'agit simplement de rechercher les éléments dont la longueur de l'intervalle vaut un :
|
Sélectionnez |
Sélectionnez |
II-B. Toutes les feuilles sous un élément de référence▲
Dans ce cas, il faut restreindre la plage de recherche des bords à ceux de l'élément, toujours en recherchant les intervalles de longueur un.
Exemple : toutes les feuilles sous l'élément 'Terrestre' dont les bords droit et gauche sont : NFM_BG = 22 et NFM_BD = 35
|
Sélectionnez |
Sélectionnez |
II-C. Rechercher tous les nœuds▲
Il suffit de rechercher tous les éléments dont la longueur de l'intervalle est supérieure à un :
|
Sélectionnez |
Sélectionnez |
II-D. Tous les nœuds sous un élément de référence▲
En plus de chercher les éléments dont la longueur de l'intervalle est supérieure à un, il faut aussi restreindre la plage de recherche des bords à ceux de l'élément considéré.
Exemple : tous les nœuds sous l'élément 'Transport' dont NFM_BG vaut 1 et NFM_BD vaut 44
|
Sélectionnez |
Sélectionnez |
II-E. Tous les éléments dépendant d'un élément de référence (sous-arbre)▲
Il s'agit simplement de rechercher des éléments dont les bords gauche et droit sont inclus dans les bords gauche et droite de l'élément considéré.
Exemple : tous les éléments dépendant de l'élément 'Terrestre' dont NFM_BG vaut 22 et NFM_BD vaut 35
|
Sélectionnez |
Sélectionnez |
Cette requête retient les éléments hiérarchiquement dépendants de l'élément 'Terrestre', mais en l'excluant, tandis que la requête suivante :
|
Sélectionnez |
Sélectionnez |
Retient même l'élément de référence qui devient alors la racine de ce sous-arbre.
II-F. Tous les éléments indépendants d'un élément de référence (complément au sous-arbre)▲
Il s'agit simplement de retenir tous les éléments dont le bord gauche est inférieur au bord gauche de l'élément de référence ainsi que ceux dont le bord droit est supérieur au bord droit de l'élément de référence.
Exemple : tous les éléments indépendants de l'élément terrestre dont NFM_BG vaut 22 et NFM_BD vaut 35
|
Sélectionnez |
Sélectionnez |
On peut remarquer qu'en inversant les critères de recherche, on obtient les compléments aux sous-arbres en excluant tous les pères de l'élément considéré :
|
Sélectionnez |
Sélectionnez |
II-G. Tous les pères d'un élément de référence▲
En fait, on recherche tous les éléments incluant à la fois les bords gauche et droit de l'élément de référence.
Exemple : tous les pères de l'élément 'Moto' dont le NFM_BG vaut 29 et le NFM_BD vaut 34
|
Sélectionnez |
Sélectionnez |
II-H. Recherche de la racine de l'arbre▲
Si toutes les insertions sont toujours faites par la droite, la racine possède un intervalle dont le bord gauche vaut un :
SELECT *
FROM NEW_FAMILLE
WHERE NFM_BG = 1Dans le cas contraire, on peut retrouver la racine par la requête, c'est-à-dire que l'on recherche l'élément dont la longueur de l'intervalle à une unité près est le double du nombre d'éléments :
|
Sélectionnez |
Sélectionnez |
On peut aussi, plus simplement, rechercher l'élément qui a la plus grande longueur d'intervalle :
SELECT *
FROM NEW_FAMILLE
WHERE (NFM_BD - NFM_BG) = (SELECT MAX(NFM_BD - NFM_BG)
FROM NEW_FAMILLE)Qui, bien entendu, conduit au même résultat.
II-I. Compter les feuilles▲
Il s'agit de compter les éléments pour lesquels la longueur de l'intervalle vaut un :
|
Sélectionnez |
Sélectionnez |
NOTA : ici nous avons fait une petite variante dans le filtre WHERE. Plutôt que de préciser NFM_BD - NFM_BG = 1, nous avons passé l'élément NFM_BD du côté droit du signe égal, ce qui ne change rien à la valeur de l'équation, mais permet d'activer l'index de la colonne NFM_BG, si index il y a, ce que l'on peut supposer puisqu'il faut bien une clef à cette table !
II-J. Compter les nœuds▲
Compter les nœuds procède de l'énumération des lignes dont la valeur de l'intervalle est supérieure ou différente de un :
|
Sélectionnez |
Sélectionnez |
II-K. Insertion d'un élément dans cette arborescence▲
La particularité de cette représentation arborescente est qu'il s'agit d'un arbre orienté pour lequel nous pouvons choisir d'insérer à gauche ou à droite de l'élément père. Si cela n'a pas d'importance, choisissons systématiquement l'insertion à droite qui permet de ne pas avoir besoin de générer des valeurs négatives pour nos bornes et laisse la racine avec un bord gauche valant un ce qui permet de retrouver la racine instantanément.
Tentons d'insérer l'élément 'Roller' en liaison directe avec son père l'élément 'Terrestre'. Dans ce cas, la borne droite de l'élément 'Terrestre' servira de référence puisque nous insérons à droite. Cette borne droite vaut 35.
Les ordres d'insertion sont alors les suivants :
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
En fait, on décale de deux unités tous les bords, droits ou gauches, sans distinction aucune, dont la valeur est supérieure ou égale à la borne droite du père visé par l'insertion.
Une autre façon de voir les choses est de dire que l'intervalle du père visé par l'élément à insérer, grossit de deux unités pour absorber le nouveau fils et que cela conduit tous les bords situés à droite du père à un décalage de deux unités.
Il n'est pas possible de réaliser l'update en une seule requête. De plus si vous avez mis une contrainte d'unicité sur les bornes, il est impératif de commencer par la mise à jour des bornes de droite, puis celles de gauche et enfin l'insertion.
Bien entendu, il vaut mieux gérer ces ordres SQL au sein d'une transaction.
II-L. Suppression d'un élément de cette arborescence▲
On peut y arriver simplement en supprimant la ligne correspondant à l'élément considéré.
Exemple : suppression de l'élément 'ULM' (dont le NFM_BG vaut 11) :
DELETE FROM NEW_FAMILLE
WHERE NFM_BG = 11Néanmoins cela laisse un arbre avec des trous dans la gestion unitaire des intervalles. Cela n'est pas beau, mais surtout cela peut affecter certaines des requêtes que nous avons vues. La correction de ce défaut est d'une grande simplicité. Il s'agit de renuméroter une partie de l'arbre. Cela se fait en considérant la valeur du bord gauche de l'élément à supprimer et par conséquent de décaler tous les bords (gauches ou droits) supérieurs à cette valeur de deux unités vers la gauche (soit -2).
Dans le cadre de notre exemple, le bord gauche valant 11, il convient d'exécuter les requêtes de modification suivante :
|
Sélectionnez |
|
Sélectionnez |
De la même façon, il n'est pas possible de réaliser les updates en un seul ordre et la suppression doit intervenir en premier sinon il y a risque de télescopage des valeurs de bornes. De plus si vous avez mis une contrainte d'unicité sur les bornes, il est impératif de commencer par la mise à jour des bornes de gauche, puis celles de droite.
II-M. Suppression d'un sous-arbre▲
La suppression d'un sous-arbre complet n'est pas plus difficile que la suppression d'une feuille. On peut donc y arriver en une seule requête ou encore, choisir de faire propre et renuméroter l'arbre.
Supprimons par exemple le sous-arbre ayant pour racine l'élément 'Terrestre' de borne gauche 22 et de borne droite 35 :
DELETE FROM NEW_FAMILLE
WHERE NFM_BG >= 22
AND NFM_BD <= 35Renumérotons alors les bornes situées à droite du sous-arbre supprimé, avec un décalage de : 35 - 22 + 1, soit 14
|
Sélectionnez |
|
Sélectionnez |
Bien entendu l'insertion d'un sous-arbre (opération beaucoup plus rare) est aussi simple qu'est la suppression d'un sous-arbre.
II-N. La cerise sur le gâteau !▲
Quelques requêtes peuvent encore apparaître plus difficiles, notamment lorsqu'il s'agit de chercher des éléments relatifs à un niveau de l'arbre. Par exemple la recherche des feuilles situées au niveau n-1 par rapport au niveau n de l'élément de référence. Mais si ce type de requête risque d'être votre pain quotidien, rien n'empêche de modéliser le niveau de l'élément au sein même de la table contenant l'arbre. Dans ce cas, la table devient :
CREATE TABLE NEW_FAMILLE
(NFM_BG INTEGER,
NFM_BD INTEGER,
NFM_NV INTEGER,
NFM_LIB VARCHAR(16))NFM_NV contenant le niveau de l'élément, en commençant par le niveau zéro, c'est-à-dire l'élément racine de l'arbre. Dès lors les modifications à effectuer pour que les requêtes vues tiennent compte du niveau des éléments deviennent triviales.
Par exemple, pour la recherche des feuilles de niveau n + 1 par rapport à l'élément 'Terrestre', la requête s'écrit :
SELECT *
FROM NEW_FAMILLE
WHERE NFM_BD - NFM_BG = 1
AND NFM_BG > 22
AND NFM_BD < 35
AND NFM_NV = 2Je vous laisse deviner l'écriture des autres requêtes…
IMPORTANT
Pour tester l'unicité des valeurs des bornes qui se trouvent dans deux colonnes distinctes, on peut utiliser des contraintes de table telles que :
CONSTRAINT UNI_BORNE CHECK BORNE_DROITE
(VALUE NOT IN
(SELECT BORNE_DROITE AS BORNE
FROM MaTable
UNION ALL
SELECT BORNE_GAUCHE AS BORNE
FROM MaTable))
et :
CONSTRAINT UNI_BORNE CHECK BORNE_GAUCHE
(VALUE NOT IN
(SELECT BORNE_DROITE AS BORNE
FROM MaTable
UNION ALL
SELECT BORNE_GAUCHE AS BORNE
FROM MaTable))Mais peu de SGBDR acceptent des contraintes si complexes et il est souvent nécessaire de passer par des triggers pour appliquer une telle intégrité.
PROCÉDURES STOCKÉES DE MANIPULATION DES ARBRES
On trouvera sur le site un exemple des principales procédures stockées écrites en Transact SQL (MS) pour gérer les insertions et suppression dans un tel arbre.
Voici un exemple (pour SQL Server) de gestion d'un arbre de nomenclature avec niveau :
- ordre de création de la table ;
- les deux procédures pour insérer et pour supprimer ;
- la vue simplifiant la présentation des données.
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
La cerise sur le gâteau…
Voici une vue permettant de réaliser un flux XML de l'arbre :
|
Sélectionnez |
|
Sélectionnez |
|
Sélectionnez |
III. Procédures complémentaires▲
Pour passer d'une table modélisant un arbre par autoréférence en arbre intervallaire, vous pouvez utiliser la procédure stockée décrite dans cet article du blog SQLpro : « Arbres intervallaires : procédure de dérécursivation ».
Pour déplacer un sous-arbre ou un élément d'un arbre modélisé par intervalle, vous pouvez utiliser la procédure stockée décrite dans cet article du blog SQLpro : « Arbres intervallaires : procédure de déplacement d'un sous-arbre ».