


III. Solutions - 3° partie▲
III-A. Solution au problème n° 21 - Ordonner et réordonner▲
III-A-1. Solution question 1 : Un UPDATE combiné à un CASE permet de solutionner le problème▲
UPDATE T_PAYS_PAY
SET PAY_POSITION = CASE
WHEN PAY_POSITION = 5
THEN 1
WHEN PAY_POSITION >= 1 AND PAY_POSITION < 5
THEN PAY_POSITION + 1
ELSE PAY_POSITION
END ;Le résultat après exécution de cette requête est :
SELECT *
FROM T_PAYS_PAY
ORDER BY PAY_POSITION ;PAY_NOM PAY_POSITION
---------------- ------------
France 1
Allemagne 2
Belgique 3
Croatie 4
Espagne 5
Grèce 6Attention cependant si les items à échanger consiste à déplacer une valeur vers le bas il faut inverser le fonctionnement de cet UPDATE. Par exemple si nous voulons faire glisser l'Allemagne du 2e au 5e rang, il faut construire l'UPDATE comme suit :
UPDATE T_PAYS_PAY
SET PAY_POSITION = CASE
WHEN PAY_POSITION = 2
THEN 5
WHEN PAY_POSITION > 2 AND PAY_POSITION <= 5
THEN PAY_POSITION - 1
ELSE PAY_POSITION
END ;III-A-2. Solution question 2 : Écrivons maintenant cette requête de manière générique▲
Notons : ORIGINE la position originale de l'item à échanger et : DESTINATION la valeur finale. La requête s'écrit alors :
UPDATE T_PAYS_PAY
SET PAY_POSITION = CASE
WHEN :ORIGINE - :DESTINATION > 0
THEN
CASE
WHEN PAY_POSITION>= :DESTINATIONAND PAY_POSITION< :ORIGINE
THEN PAY_POSITION+ 1
WHEN PAY_POSITION= :ORIGINE
THEN :DESTINATION
ELSE PAY_POSITION
END
WHEN :ORIGINE - :DESTINATION < 0
THEN
CASE
WHEN PAY_POSITION= :ORIGINE
THEN :DESTINATION
WHEN PAY_POSITION> :ORIGINE AND PAY_POSITION<= :DESTINATION
THEN PAY_POSITION- 1
ELSE PAY_POSITION
END
ELSE PAY_POSITION
END ;Exemple pour MS SQL Server - la requête paramétrée sous forme de procédure stockée :
CREATE PROCEDURE P_ECHANGE_POSITION @ORIGINE INTEGER, @DESTINATION INTEGER
AS
UPDATE T_PAYS_PAY
SET PAY_POSITION = CASE
WHEN @ORIGINE - @DESTINATION > 0
THEN
CASE
WHEN PAY_POSITION >= @DESTINATION AND PAY_POSITION < @ORIGINE
THEN PAY_POSITION + 1
WHEN PAY_POSITION = @ORIGINE
THEN @DESTINATION
ELSE PAY_POSITION
END
WHEN @ORIGINE - @DESTINATION < 0
THEN
CASE
WHEN PAY_POSITION = @ORIGINE
THEN @DESTINATION
WHEN PAY_POSITION > @ORIGINE AND PAY_POSITION <= @DESTINATION
THEN PAY_POSITION - 1
ELSE PAY_POSITION
END
ELSE PAY_POSITION
END;III-A-3. Solution question 3 : Renuméroter l'ordre en partant de 1 avec continuité▲
Avec le nouveau jeu d'essai, comment donc passer de :
PAY_NOM PAY_POSITION
---------------- ------------
Espagne 5
Grèce 7
Belgique 8
Croatie 9
Allemagne 11
France 12
à :
PAY_NOM PAY_POSITION
---------------- ------------
Espagne 1
Grèce 2
Belgique 3
Croatie 4
Allemagne 5
France 6
L'idée est de faire une non équi jointure pour exécuter un comptage :
SELECT T1.PAY_NOM, COUNT(T2.PAY_POSITION) NEW_POSITION
FROM T_PAYS_PAY T1
LEFT OUTER JOIN T_PAYS_PAY T2
ON T1.PAY_POSITION <= T2.PAY_POSITION
GROUP BY T1.PAY_NOM ;PAY_NOM NEW_POSITION
---------------- ------------
Allemagne 2
Belgique 4
Croatie 3
Espagne 6
France 1
Grèce 5Le calcul de la nouvelle position doit se faire en conservant l'ancienne en référence pour que l'UPDATE puisse se faire. Une telle requête le permet :
SELECT T1.PAY_NOM, T1.PAY_POSITION,
(SELECT COUNT(*) FROM T_PAYS_PAY) - COUNT(*) + 1 AS NEW_POSITION
FROM T_PAYS_PAY T1
LEFT OUTER JOIN T_PAYS_PAY T2
ON T1.PAY_POSITION <= T2.PAY_POSITION
GROUP BY T1.PAY_NOM, T1.PAY_POSITION ;PAY_NOM PAY_POSITION NEW_POSITION
---------------- ------------ ------------
Espagne 5 1
Grèce 7 2
Belgique 8 3
Croatie 9 4
Allemagne 11 5
France 12 6Requête qu'il faut maintenant corréler dans l'update de cette manière :
UPDATE T_PAYS_PAY
SET PAY_POSITION = (SELECT (SELECT COUNT(*) FROM T_PAYS_PAY) - COUNT(*) + 1 AS NEW_POSITION
FROM T_PAYS_PAY T1
LEFT OUTER JOIN T_PAYS_PAY T2
ON T1.PAY_POSITION <= T2.PAY_POSITION
WHERE T1.PAY_POSITION = T_PAYS_PAY.PAY_POSITION
id="" GROUP BY T1.PAY_NOM, T1.PAY_POSITION) ;III-B. Solution au problème n° 22 - Jointure hétérogène multiple▲
Plusieurs solutions sont possibles. Il suffit d'isoler par des extractions de sous chaîne les valeurs numériques. On utilise le SUBSTRING combiné au LIKE :
SELECT *
FROM T_PUBLIC_PBL PBL
INNER JOIN T_PRESTATION_PST PST
ON PST.PST_P id=""UBLIC LIKE '%[' +CAST(PBL.PBL_ID AS VARCHAR(16))+']%'
ORDER BY PBL_ID, PST_ID ;III-C. Solution au problème n° 23 - Insertion conditionnelle▲
On peut toujours insérer des données en utilisant une sous requête :
INSERT INTO...
SELECT ...
Dans la sous requête SELECT on peut placer des constantes comme 1, toto !
Le problème est de trouver la bonne requête SELECT qui retourne une seule fois la ligne 1, toto si cette ligne n'est pas déjà dans la table, sinon, aucune ligne, si ces données sont déjà dans la table. L'idée est d'utiliser le prédicat EXISTS, ou plutôt NOT EXISTS pour piloter l'apparition de la ligne à insérer.
En fait, le problème est plus compliqué qu'il n'y paraît. Il faut étudier deux cas bien distincts :
- il n'y a rien dans la table
- il y a des lignes dans la table.
Cette première requête fonctionne s'il y a des lignes dans la table :
INSERT INTO MATABLE (COL1, COL2)
SELECT DISTINCT 1, 'titi'
FROM MATABLE AS M
WHERE NOT EXISTS(SELECT *
FROM MATABLE
WHERE COL1 = 1
AND COL2 = 'titi') ;La difficulté maintenant c'est d'améliorer cette requête si la table est vide. Dans ce cas on ne peut faire appel à un filtre sur la table elle même car tout interrogation sur une table vide renvoie par principe aucune ligne ! L'idée étant alors d'utiliser une autre table. Dans ce cas, le mieux est d'utiliser une table du dictionnaire que l'on sait contenir au moins une ligne. Prenons par exemple la vue d'information de schéma INFORMATION_SCHEMA.TABLES :
INSERT INTO MATABLE (COL1, COL2)
SELECT DISTINCT 1, 'titi'
FROM INFORMATION_SCHEMA.TABLES
WHERE NOT EXISTS (SELECT *
FROM MATABLE) ;Le tout peut être aggloméré à l'aide de l'opérateur ensembliste UNION :
INSERT INTO MATABLE (COL1, COL2)
SELECT DISTINCT 1, 'tutu'
FROM MATABLE AS M
WHERE NOT EXISTS(SELECT *
FROM MATABLE
WHERE COL1 = 1
AND COL2 = 'tutu')
UNION
SELECT DISTINCT 1, 'titi'
FROM INFORMATION_SCHEMA.TABLES
WHERE NOT EXISTS (SELECT *
FROM MATABLE) ;Si votre SGBDR le supporte, utilisez le constructeur de lignes valuées :
INSERT INTO MATABLE (COL1, COL2)
SELECT DISTINCT 1, 'tutu'
FROM MATABLE AS M
WHERE NOT EXISTS(SELECT *
FROM MATABLE
WHERE (COL1 , COL2) = (1, 'tutu')
UNION
SELECT DISTINCT 1, 'titi'
FROM INFO id=""RMATION_SCHEMA.TABLES
WHERE NOT EXISTS (SELECT *
FROM MATABLE) ;III-D. Solution au problème n° 24 - Un arbre à deux niveaux▲
Fastoche avec une union :
SELECT ETP_ID, (SELECT MIN(EMP_ID) FROM T_EMPLOYEE_EMP) -1 AS EMP_ID, ETP_NOM AS NOM
FROM T_ENTREPRISE_ETP
UNION
SELECT ETP_ID AS EMP_ID, EMP_ID, ' ' +EMP_NOM AS NOM
FROM T_EMPLOYEE_EMP
ORDER BY ETP_ID, EMP_ID ;Mais ne pas oublier la clause de tri !
ETP_ID EMP_ID NOM
----------- ----------- -----------------
1 0 IBM
1 1 Durand
1 2 Dupont
1 3 Dubois
1 4 Duval
2 0 EDF
2 id="" 5 Dupond
2 6 Duhamel
2 7 DufourIII-E. Solution au problème n° 25 - Éclater des lignes▲
Comme souvent dans ce genre de problème, il faut passer par une table de nombre pour éclater les lignes dans la table réponse. Mais ici la difficulté c'est que cet éclatement doit se faire avec une double condition : valeur unique de ID_REF et continuation en séquence même si ID_LIGNE varie...
Construisons tout d'abord notre table des nombres :
CREATE TABLE NUMBERS (N INT NOT NULL);INSERT INTO NUMBERS VALUES (0);
INSERT INTO NUMBERS VALUES (1);
INSERT INTO NUMBERS VALUES (2);
INSERT INTO NUMBERS VALUES (3);
INSERT INTO NUMBERS VALUES (4);
INSERT INTO NUMBERS VALUES (5);
INSERT INTO NUMBERS VALUES (6);
INSERT INTO NUMBERS VALUES (7);
INSERT INTO NUMBERS VALUES (8);
INSERT INTO NUMBERS VALUES (9);INSERT INTO NUMBERS
SELECT N1.N + 10 * N2.N + 100 * N3.N + 1000 * N4.N
FROM NUMBERS N1
CROSS JOIN NUMBERS N2
CROSS JOIN NUMBERS N3
CROSS JOIN NUMBERS N4
WHERE N1.N + 10 * N2.N + 100 * N3.N + 1000 * N4.N > 9 ;ALTER TABLE NUMBERS
ADD CONSTRAINT PK_NUMBERS PRIMARY KEY (N) ;Constatez que j'y ai ajouté une contrainte de clef primaire assurant l'unicité. Mais cela n'était pas nécessaire...
Une première idée est de calculer la somme des quantités par ID_REF afin de préparer cet éclatement :
SELECT *, (SELECT SUM(QUANTITE)
FROM LIGNE L1
WHERE L1.ID_REF = L.ID_REF ) AS S
FROM LIGNE L
ORDER BY ID_REF, ID_LIGNE ;ID_LIGNE ID_REF QUANTITE S
----------- ----------- ----------- -----------
1 1 4 5
4 1 1 5
2 2 1 3
5 2 2 3
3 3 2 2
6 4 2 2Cependant, nous constatons que S devrait valoir 4 pour la première ligne et non 5. De plus pour la seconde ligne S devrait soit valoir 1, soit être cadré entre 5 et 5. Dans ce dernier cas S devrait être cadré entre 1 et 4 pour la première ligne... Ajoutons au filtre WHERE une condition sur la valeur de la ligne :
SELECT *, (SELECT SUM(QUANTITE)
FROM LIGNE L1
WHERE L1.ID_REF = L.ID_REF
AND L1.ID_LIGNE <= L.ID_LIGNE) AS SI
FROM LIGNE L
ORDER BY ID_REF, ID_LIGNE ;ID_LIGNE ID_REF QUANTITE SI
----------- ----------- ----------- -----------
1 1 4 4
4 1 1 5
2 2 1 1
5 2 2 3
3 3 2 2
6 4 2 2Notez que j'ai appelé cette colonne SI pour "somme itérative". Transformons cette requête en vue SQL afin de pouvoir l'interroger à nouveau :
CREATE VIEW V_L1
AS
SELECT *, (SELECT SUM(QUANTITE)
FROM LIGNE L1
WHERE L1.ID_REF = L.ID_REF
AND L1.ID_LIGNE <= L.ID_LIGNE) AS SI
FROM LIGNE L ;Une nouvelle idée serait de prévoir la plage de variation de l'éclatement. Dans ce cas la plage MIN - MAX d'éclatement devrait valoir 1 - 4 pour la 1ere ligne et 5 - 5 pour la seconde. pouvons nous calculer cette plage avec les données présentent ? Oui :
SELECT ID_LIGNE, ID_REF, QUANTITE, SI - QUANTITE + 1 AS MAX, SI AS MIN
FROM V_L1 VL1
ORDER BY ID_REF, ID_LIGNE ;ID_LIGNE ID_REF QUANTITE MAX MIN
----------- ----------- ----------- ----------- -----------
1 1 4 1 4
4 1 1 5 5
2 2 1 1 1
5 2 2 2 3
3 3 2 1 2
6 4 2 1 2Dès lors, nous disposons de tous les éléments pour éclater ces lignes avec notre table de numérotation :
SELECT ID_LIGNE, ID_REF, N as SERIE
FROM V_L1 VL1
INNER JOIN NUMBERS
ON N BETWEEN SI - QUANTITE + 1 AND SI
ORDER BY ID_REF, ID_LIGNE ;ID_LIGNE ID_REF SERIE
----------- ----------- -----------
1 1 1
1 1 2
1 1 3
1 1 4
4 1 5
2 2 1
5 2 2
5 2 3
3 3 1
3 3 2
6 4 1
6 4 2La dernière étape consiste à ajouter une numération en séquence des lignes de notre table basé sur l'ordre ID_REF, SERIE. Ceux qui possèdent une fonction de fenêtrage seront avantagés : il suffit d'ajouter à la requête précédente, la colonne :
RANK() OVER (ORDER BY ID_REF, SERIE) AS ID_ARTICLE.
Dans le cas contraire, il faut s'inspirer de la technique du "row value constructor" pour piloter un comptage à l'aide d'une non équi jointure qui réalisera ce comptage.
Transformons d'abord la requête précédente en une seconde vue :
CREATE VIEW V_L2
AS
SELECT ID_LIGNE, ID_REF, N as SERIE
FROM V_L1 VL1
INNER JOIN NUMBERS
ON N BETWEEN SI - QUANTITE + 1 AND SI
ORDER BY ID_REF, ID_LIGNE ;Dès lors, cette numération de la colonne ID_ARTICLE s'exprime :
SELECT ID_REF, ID_LIGNE, SERIE,
(SELECT COUNT(*)
FROM V_L2 VL22
WHERE (VL22.ID_REF < VL21.ID_REF)
OR (VL22.ID_REF = VL21.ID_REF AND VL22.SERIE <= VL21.SERIE)) as ID_ARTICLE
FROM V_L2 VL21
ORDER BY ID_REF, ID_LIGNE ;ID_REF ID_LIGNE SERIE ID_ARTICLE
----------- ----------- ----------- -----------
1 1 1 1
1 1 2 2
1 1 3 3
1 1 4 4
1 4 5 5
2 2 1 6
2 5 2 7
2 5 3 8
3 3 1 9
3 3 2 10
4 6 1 11
4 6 2 12Si l'on veut exprimer le tout en une seule requête, il suffit de ré encapsuler chacune des vues dans les requêtes d'origine à la manière des poupées russes :
SELECT (SELECT COUNT(*)
FROM (SELECT ID_REF, N AS SERIE, ID_LIGNE
FROM (SELECT *, (SELECT SUM(QUANTITE)
FROM LIGNE L1
WHERE L1.ID_REF = L.ID_REF
AND L1.ID_LIGNE <= L.ID_LIGNE) AS SI
FROM LIGNE L) VL1
INNER JOIN NUMBERS
ON N BETWEEN SI - QUANTITE + 1 AND SI) VL22
WHERE (VL22.ID_REF < VL21.ID_REF)
OR (VL22.ID_REF = VL21.ID_REF AND VL22.SERIE <= VL21.SERIE)) AS ID_ARTICLE,
ID_REF, SERIE, ID_LIGNE
FROM (SELECT ID_REF, N AS SERIE, ID_LIGNE
FROM (SELECT *, (SELECT SUM(QUANTITE)
FROM LIGNE L1
WHERE L1.ID_REF = L.ID_REF
AND L1.ID_LIGNE <= L.ID_LIGNE) AS SI
FROM LIGNE L) VL1
INNER JOIN NUMB id=""ERS
ON N BETWEEN SI - QUANTITE + 1 AND SI) VL21
ORDER BY ID_REF, ID_LIGNE ;III-F. Solution au problème n° 26 - Noms incrémentés▲
Bien évidemment, pour numéroter il faut avoir une table de nombres. Construisons-la :
CREATE TABLE T_NUM
(NUM INT NOT NULL PRIMARY KEY);INSERT INTO T_NUM VALUES (0);
INSERT INTO T_NUM VALUES (1);
INSERT INTO T_NUM VALUES (2);
INSERT INTO T_NUM VALUES (3);
INSERT INTO T_NUM VALUES (4);
INSERT INTO T_NUM VALUES (5);
INSERT INTO T_NUM VALUES (6);
INSERT INTO T_NUM VALUES (7);
INSERT INTO T_NUM VALUES (8);
INSERT INTO T_NUM VALUES (9);INSERT INTO T_NUM
SELECT DISTINCT T1.NUM + 10 * T2.NUM + 100 * T3.NUM
FROM T_NUM T1
CROSS JOIN T_NUM T2
CROSS JOIN T_NUM T3
WHERE T1.NUM + 10 * T2.NUM + 100 * T3.NUM BETWEEN 10 AND 999 ;
L'idée est de prévoir toutes les combinaisons possible de NOM + n° et de retenir la première qui n'est pas dans le lot ! mais nous allons voir que cette idée possède un petit effet de bord...
Exemple :
SELECT 'DUPOND' + CAST(NUM AS VARCHAR(3)) AS NEW_NOM,
NUM
FROM T_NUM
WHERE NOT EXISTS (SELECT *
FROM T_UTILISATEUR_USR
WHERE USR_NOM = 'DUPOND'+ CAST(NUM AS VARCHAR(3))) ;NEW_NOM NUM
--------- -----------
DUPOND0 0
DUPOND1 1
DUPOND2 2
DUPOND3 3
DUPOND4 4
DUPOND5 5
DUPOND6 6
DUPOND7 7
DUPOND8 8
DUPOND9 9
DUPOND10 10
DUPOND11 11
DUPOND12 12
DUPOND13 13
...Mais dans notre table comme il n'y a pas de DUPOND avec un D, il faudrait insérer ce DUPOND sans numéro ! Comment faire ?
Tout simplement en transformant le zéro en chaine vide à l'aide de la structure CASE :
SELECT 'DUPOND' + CASE
WHEN NUM = 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END AS NEW_NOM,
NUM
FROM T_NUM
WHERE NOT EXISTS (SELECT *
FROM T_UTILISATEUR_USR
WHERE USR_NOM = 'DUPOND' + CASE
WHEN NUM = 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END) ;NEW_NOM NUM
--------- -----------
DUPOND 0
DUPOND1 1
DUPOND2 2
DUPOND3 3
...Il faut maintenant récupérer le premier. Ce premier est donné par la requête suivante :
SELECT MIN(NUM)
FROM T_NUM
WHERE NOT EXISTS (SELECT *
FROM T_UTILISATEUR_USR
WHERE USR_NOM = 'DUPOND' + CASE
WHEN NUM = 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END) ;En raboutant ces deux requêtes, on obtient la formule d'insertion suivante :
INSERT INTO T_UTILISATEUR_USR
SELECT 4, 'DUPOND' + CASE
WHEN NUM = 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END AS NEW_NOM
FROM T_NUM
WHERE NOT EXISTS (SELECT *
FROM T_UTILISATEUR_USR
WHERE USR_NOM = 'DUPOND' + CASE
WHEN NUM = 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END)
AND NUM = (SELECT MIN(NUM)
FROM T_NUM
WHERE NOT EXISTS (SELECT *
FROM T_UTILISATEUR_USR
WHERE USR_NOM = 'DUPOND' + CASE
WHEN NUM = 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END)) ;Voici une autre formulation plus concise, qui possède l'avantage de ne nécessiter qu'une seule fois l'usage du nom à insérer :
INSERT INTO T_UTILISATEUR_USR
SELECT 4, NOM + CASE NUM
WHEN 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END
FROM (SELECT MIN(NOM) AS NOM, MIN(NUM) AS NUM
FROM (SELECT 'DUPOND' AS NOM, NUM
FROM T_NUM) AS T
WHERE NOM + CASE NUM
WHEN 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END NOT IN (SELECT USR_NOM
FROM T_UTILISATEUR_USR)) AS TT ;Attention cependant, si vous voulez numéroter au delà de 999, prévoyez une table plus remplie et modifiez le transtypage de VARCHAR(3) pour l'adapter à votre problématique.
Si l'on analyse les plans d'exécution de ces différentes requêtes, voici ce que cela donne :
1) Solution avec NOT EXISTS :
SELECT 4, 'DUPOND' + CASE
WHEN NUM = 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END AS NEW_NOM
FROM T_NUM
WHERE NOT EXISTS (SELECT *
FROM T_UTILISATEUR_USR
WHERE USR_NOM = 'DUPOND' + CASE
WHEN NUM = 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END)
AND NUM = (SELECT MIN(NUM)
FROM T_NUM
WHERE NOT EXISTS (SELECT *
FROM T_UTILISATEUR_USR
WHERE USR_NOM = 'DUPOND' + CASE
WHEN NUM = 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END)) ;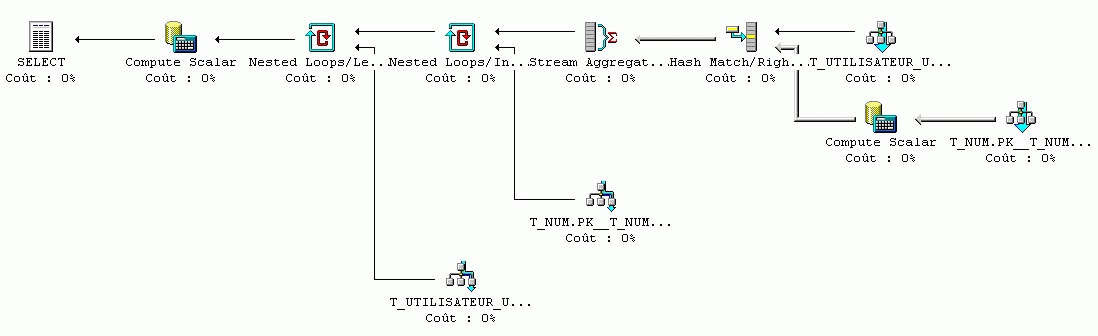
2) Solution avec sous requêtes dans la clause FROM
SELECT 4, NOM + CASE NUM
WHEN 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END
FROM (SELECT MIN(NOM) AS NOM, MIN(NUM) AS NUM
FROM (SELECT 'DUPOND' AS NOM, NUM
FROM T_NUM) AS T
WHERE NOM + CASE NUM
WHEN 0 THEN ''
ELSE CAST(NUM AS VARCHAR(3))
END NOT IN (SELECT USR_NOM
FROM T_UTILISATEUR_USR)) AS TT ;
Mais il faut prendre en compte les lectures dans les tables....
D'autres solutions existent notamment si vous pouvez générer un select sans table ce qui est possible sous SQL Server, ou encore si vous disposez d'une table d'une seule ligne faite pour cela, comme c'est le cas chez ORACLE avec la célèbre table DUAL. De toutes façon, vous pouvez toujours créer une telle table ou bien même une vue suivant ce principe, par exemple :
CREATE TABLE DUAL (DUMMY NVARCHAR(1)); INSERT INTO DUAL VALUES ('X');
Comme nous avons déjà rajouté une table de nombres, je vous propose une vue comme ceci :
CREATE VIEW LIGNE
AS
SELECT SQRT(NUM) AS COLONNE
FROM T_NUM
WHERE NUM = 1
L'intérêt d'avoir fait une racine carrée de 1 est que la vue ne peut plus être mise à jour !
Voici maintenant quelques autres expressions de requêtes résolvant cet exercice :
SELECT MIN(NOUVEAU_NOM)
FROM (SELECT RTRIM(USR_NOM) + CAST(NUM AS VARCHAR(34)) NOUVEAU_NOM
FROM T_UTILISATEUR_USR U
CROSS JOIN T_NUM N
WHERE USR_NOM = 'DUPOND'
AND NUM > 0
UNION
SELECT 'DUPOND'
FROM LIGNE) AS T
WHERE NOUVEAU_NOM NOT IN (SELECT USR_NOM
FROM T_UTILISATEUR_USR);
SELECT MIN(NOUVEAU_NOM)
FROM (SELECT RTRIM(USR_NOM) + CAST(NUM AS VARCHAR(34)) NOUVEAU_NOM
FROM T_UTILISATEUR_USR U
CROSS JOIN T_NUM N
WHERE USR_NOM = 'DUPOND'
AND NUM > 0
UNI id=""ON
SELECT 'DUPOND'
FROM LIGNE) AS T
EXCEPT
SELECT USR_NOM
FROM T_UTILISATEUR_USR;III-G. Solution au problème n° 27 - Une lettre un nom▲
III-G-1. Solution brute :▲
SELECT SUBSTRING(CTC_NOM FROM 1 FOR 1) AS LETTRE, MIN(CTC_NOM) AS CTC_NOM
FROM T_CONTACT_CTC
GROUP BY SUBSTRING(CTC_NOM, 1, 1) ;
Autre solution avec création d'une table des lettres : cette solution est intéressantes si nous voulons toutes les lettres de A à Z et qu'il n'y a pas de noms commençant en W par exemple...
CREATE TABLE T_ALPHABET_ALB
(ALB_LETTRE CHAR(1) NOT NULL PRIMARY KEY);INSERT INTO T_ALPHABET_ALB VALUES ('A');
INSERT INTO T_ALPHABET_ALB VALUES ('B');
INSERT INTO T_ALPHABET_ALB VALUES ('C');
INSERT INTO T_ALPHABET_ALB VALUES ('D');
INSERT INTO T_ALPHABET_ALB VALUES ('Z');SELECT ALB_LETTRE AS LETTRE, MIN(CTC_NOM) AS CTC_NOM
FROM T_CONTACT_CTC CTC
INNER JOIN T_ALPHABET_ALB ALB
ON UPPER(SUBSTRING(CTC_NOM FROM 1 FOR 1)) = UPPER(ALB_LETTRE)
GROUP BY ALB_LETTREIII-G-2. Variante 1 : obtenir les noms des "secondes" personnes▲
SELECT LETTRE, CTC_NOM
FROM (SELECT SUBSTRING(T1.CTC_NOM, 1, 1) AS LETTRE, T1.CTC_NOM AS CTC_NOM, COUNT(*) AS N
FROM T_CONTACT_CTC T1
LEFT OUTER JOIN T_CONTACT_CTC T2
ON SUBSTRING(T1.CTC_NOM FROM 1 FOR 1) = SUBSTRING(T2.CTC_NOM FROM 1 FOR 1)
AND T1.CTC_NOM >= T2.CTC_NOM
GROUP BY SUBSTRING(T1.CTC_NOM FROM 1 FOR 1), T1.CTC_NOM ) AS T
WHERE N = 2III-G-3. Variante 2 : obtenir les noms des niemes personnes▲
Dans la requête précédente, remplacez 2 par le chiffre voulu !
III-G-4. Variante 3 : obtenir les noms des niemes personnes, mais si elle n'existe pas, alors la dernière ! ▲
SELECT LETTRE, MIN(CTC_NOM) AS CTC_NOM
FROM (-- les nieme noms :
SELECT LETTRE, CTC_NOM
FROM (SELECT SUBSTRING(T1.CTC_NOM FROM 1 FOR 1) AS LETTRE, T1.CTC_NOM AS CTC_NOM, COUNT(*) AS N
FROM T_CONTACT_CTC T1
LEFT OUTER JOIN T_CONTACT_CTC T2
ON T1.CTC_NOM >= T2.CTC_NOM
AND SUBSTRING(T1.CTC_NOM FROM 1 FOR 1) = SUBSTRING(T2.CTC_NOM FROM 1 FOR 1)
GROUP BY SUBSTRING(T1.CTC_NOM FROM 1 FOR 1), T1.CTC_NOM) AS T
WHERE N = 2
UNION ALL
-- les derniers noms
SELECT ALB_LETTRE AS LETTRE, MAX(CTC_NOM) AS CTC_NOM
FROM T_CONTACT_CTC CTC
INNER JOIN T_ALPHABET_ALB ALB
ON UPPER(SUBSTRING(CTC_NOM FROM 1 FOR 1)) = UPPER(ALB_LETTRE)
GROUP BY ALB_LETTRE) AS TT
GROUP BY LETTRE ;III-G-5. Solutions avec fonctions analytiques de fenêtrage (norme SQL:2003)▲
SELECT LETTRE, CTC_NOM
FROM (SELECT SUBSTRING(CTC_NOM, 1, 1) AS LETTRE, CTC_NOM,
RANK() OVER (PARTITION BY SUBSTRING(CTC_NOMFROM 1 FOR 1) ORDER BY CTC_NOM) AS N
FROM T_CONTACT_CTC) AS T
WHERE N = 2
-- pour la rendre générique, remplacer 2 par la valeur voulue dans le filtre WHERESELECT COALESCE(T1.LETTRE, T2.LETTRE) AS LETTRE,
COALESCE(T1.CTC_NOM, T2.CTC_NOM) AS CTC_NOM
FROM (SELECT LETTRE, CTC_NOM
FROM (SELECT SUBSTRING(CTC_NOM FROM 1 FOR 1) AS LETTRE, CTC_NOM,
RANK() OVER (PARTITION BY SUBSTRING(CTC_NOM FROM 1 FOR 1) ORDER BY CTC_NOM) AS N
FROM T_CONTACT_CTC) AS T
WHERE N = 2) AS T1
RIGHT OUTER JOIN (SELECT SUBSTRING(CTC_NOM FROM 1 FOR 1) AS LETTRE, MAX(CTC_NOM) AS CTC_NOM
FROM T_CONTACT_CTC
GRO id=""UP BY SUBSTRING(CTC_NOM FROM 1 FOR 1)) AS T2
ON T1.LETTRE = T2.LETTREIII-H. Solution au problème n° 28 - Filtrer les adresses IP▲
La table proposée viole notablement la première forme normale qui indique que tout attribut doit être atomique, c'est à dire non décomposable. Or le moins que l'on puisse dire c'est qu'une adresse IP est au moins composée de 4 parties, et devrait l'être de 6 dès que la norme IPV6 sera en place.
Qu'à cela ne tienne... Il suffit de substituer à la table une autre rectifiant l'erreur de modélisation. Voici donc dans un premier temps une requête faisant ce travail. Requête qui gagnerait à être transforme en vue !
SELECT TIP_ID, SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR1
FROM TIPTIP_ID BIP_ADR1
----------- ---------------
1 10
2 10
3 10
4 10SELECT TIP_ID,
SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR1,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TIP_ADR
FROM TIPTIP_ID BIP_ADR1 TIP_ADR
----------- --------------- ---------------
1 10 120.12.1
2 10 130.23.1
3 10 130.201.1
4 10 13.11.1
p
uis recommencer le processus par imbrication des requêtes.
SELECT TIP_ID, BIP_ADR1, SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR2,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TIP_ADR
FROM (SELECT TIP_ID,
SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR1,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TIP_ADR
FROM TIP) TTIP_ID BIP_ADR1 BIP_ADR2 TIP_ADR
----------- --------------- --------------- ---------------
1 10 120 12.1
2 10 130 23.1
3 10 130 201.1
4 10 13 11.1SELECT TIP_ID, BIP_ADR1, BIP_ADR2,
SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR3,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TIP_ADR
FROM (SELECT TIP_ID, BIP_ADR1, SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR2,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TIP_ADR
FROM (SELECT TIP_ID,
SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR1,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TIP_ADR
FROM TIP) T) TTTIP_ID BIP_ADR1 BIP_ADR2 BIP_ADR3 TIP_ADR
----------- --------------- --------------- --------------- ---------------
1 10 120 12 1
2 10 130 23 1
3 10 130 201 1
4 10 13 11 1SELECT TIP_ID, BIP_ADR1, BIP_ADR2,
SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR3,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS BIP_ADR4
FROM (SELECT TIP_ID, BIP_ADR1, SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR2,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TIP_ADR
FROM (SELECT TIP_ID,
SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR1,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TIP_ADR
FROM TIP) T) TTTIP_ID BIP_ADR1 BIP_ADR2 BIP_ADR3 BIP_ADR4
----------- --------------- --------------- --------------- ---------------
1 10 120 12 1
2 10 130 23 1
3 10 130 201 1
4 10 13 11 1SELECT TIP_ID,
CAST(BIP_ADR1 AS TINYINT) AS BIP_ADR1,
CAST(BIP_ADR2 AS TINYINT) AS BIP_ADR2,
CAST(SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS TINYINT) AS BIP_ADR3,
CAST(SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TINYINT) AS BIP_ADR4
FROM (SELECT TIP_ID, BIP_ADR1, SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR2,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TIP_ADR
FROM (SELECT TIP_ID,
SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR1,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TIP_ADR
FROM TIP) T) TTTIP_ID BIP_ADR1 BIP_ADR2 BIP_ADR3 BIP_ADR4
----------- -------- -------- -------- --------
1 10 120 12 1
2 10 130 23 1
3 10 130 201 1
4 10 13 11 1CREATE VIEW VIP
AS
SELECT TIP_ID,
CAST(BIP_ADR1 AS TINYINT) AS BIP_ADR1,
CAST(BIP_ADR2 AS TINYINT) AS BIP_ADR2,
CAST(SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS TINYINT) AS BIP_ADR3,
CAST(SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TINYINT) AS BIP_ADR4
FROM (SELECT TIP_ID, BIP_ADR1, SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR2,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TIP_ADR
FROM (SELECT TIP_ID,
SUBSTRING(TIP_ADR, 1, CHARINDEX('.', TIP_ADR) - 1) AS BIP_ADR1,
SUBSTRING(TIP_ADR, CHARINDEX('.', TIP_ADR) + 1, LEN(TIP_ADR) - CHARINDEX('.', TIP_ADR)) AS TIP_ADR
FROM TIP) T) TT
À
ce stade, la requête devient triviale pour les SGBDR utilisant le concept de ROW VALUE CONSTRUCTOR :
SELECT *
FROM VIP
WHERE (BIP_ADR1, BIP_ADR2, BIP_ADR3, BIP_ADR4) BETWEEN (10, 120, 12, 1)
AND (10, 130, 23, 1) ;Si ce n'est pas le cas, alors il faudra faire avec la décomposition suivante :
SELECT *
FROM VIP
WHERE (BIP_ADR1 > 10
OR BIP_ADR1 = 10 AND BIP_ADR2 > 120
OR BIP_ADR1 = 10 AND BIP_ADR2 = 120 AND BIP_ADR3 > 12
OR BIP_ADR1 = 10 AND BIP_ADR2 = 120 AND BIP_ADR3 = 12 AND BIP_ADR4 >= 1)
AND (BIP_ADR1 < 10
OR BIP_ADR1 = 10 AND BIP_ADR2 < 130
OR BIP_ADR1 = 10 AND BIP_ADR2 = 130 AND BIP_ADR3 < 23
OR BIP_ADR1 = 10 AND BIP_ADR2 = 130 AND BIP_ADR3 = 23 AND BIP_ADR4 <= 1) ;Avec un petite astuce de mathématicien, on peut arriver à une formulation plus concise... En effet, les différentes parties d'une adresse étant codées sur un entier limité à 256 positions, cela revient à une énumération en base 256 que l'on peut transformer en base 10 de la sorte :
CREATE VIEW DIP
AS
SELECT BIP_ADR1 * POWER(256, 3) + BIP_ADR2 * POWER(256, 2) + BIP_ADR3 * POWER(256, 1) + BIP_ADR4 * POWER(256, 0) AS ADR_IP,
BIP_ADR1, BIP_ADR2, BIP_ADR3, BIP_ADR4
FROM VIP ;Dès lors, la requête devient on ne peut plus simple :
SELECT BIP_ADR1, BIP_ADR2, BIP_ADR3, BIP_ADR4
FROM DIP
WHERE ADR_IP BETWEEN 10 * POWER(256, 3) id="" + 120 * POWER(256, 2) + 12 * 256 + 1
AND 10 * POWER(256, 3) + 130 * POWER(256, 2) + 23 * 256 + 1 ;III-I. Solution au problème n° 29 - Calculer l'adresses IP suivante▲
Une première approche consiste à calculer cette adresse à l'aide d'addition et de modulo afin de produire les éléments de l'adresse IP suivante.
Voici cette première solution :
SELECT MAC_ID, MAC_NOM, MAC_ADRIP1, MAC_ADRIP2, MAC_ADRIP3, MAC_ADRIP4,
MOD(MAC_ADRIP1 + (MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + 1) / 256) / 256) / 256, 256) AS NEW_ADRIP1,
MOD(MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + 1) / 256) / 256, 256) AS NEW_ADRIP2,
MOD(MAC_ADRIP3 + (MAC_ADRIP4 + 1) / 256, 256) AS NEW_ADRIP3,
MOD(MAC_ADRIP4 + 1, 256) AS NEW_ADRIP4
FROM T_MACHINE_MAC ;MAC_ID MAC_NOM MAC_ADRIP1 MAC_ADRIP2 MAC_ADRIP3 MAC_ADRIP4 NEW_ADRIP1 NEW_ADRIP2 NEW_ADRIP3 NEW_ADRIP4
----------- ---------------- ---------- ---------- ---------- ---------- ----------- ----------- ----------- -----------
1 PC 123 12 1 200 123 12 1 201
2 PC 123 12 1 255 123 12 2 0
3 PC 123 12 255 255 123 13 0 0
4 PC 123 13 0 0 123 13 0 1
5 PC 123 255 255 255 124 0 0 0Elle pose cependant un problème de taille : l'adresse suivante de la machine 3 est en fait celle attribuée à la machine 4 ! Comment dès lors résoudre ce détail ?
Le calcul effectué pour la machine 3 va violer la contrainte d'unicité, puisque cette adresse IP est déjà utilisée par la machine 4.
Si notre ajout avait été de 2, il n'y aurait pas eût ce problème. D'où l'idée d'incrémenter avec un pas variable et de sélectionner le première place libre...
Pour incrémenter d'un pas variable, il faut une table des pas...
CREATE TABLE T_NUM (NUM_I INT NOT NULL PRIMARY KEY);
INSERT INTO T_NUM VALUES (1);
INSERT INTO T_NUM VALUES (2);
INSERT INTO T_NUM VALUES (3);
...
La requête avec pas variable devient :
SELECT MAC_ID, MAC_NOM, MAC_ADRIP1, MAC_ADRIP2, MAC_ADRIP3, MAC_ADRIP4,
MOD(MAC_ADRIP1 + (MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256) / 256) / 256, 256) AS NEW_ADRIP1,
MOD(MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256) / 256, 256) AS NEW_ADRIP2,
MOD(MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256, 256) AS NEW_ADRIP3,
MOD(MAC_ADRIP4 + NUM_I, 256) AS NEW_ADRIP4
FROM T_MACHINE_MAC
CROSS JOIN T_NUM
ORDER BY 1, 3, 4, 5, 6 ;MAC_ID MAC_NOM MAC_ADRIP1 MAC_ADRIP2 MAC_ADRIP3 MAC_ADRIP4 NEW_ADRIP1 NEW_ADRIP2 NEW_ADRIP3 NEW_ADRIP4
----------- ---------------- ---------- ---------- ---------- ---------- ----------- ----------- ----------- -----------
1 PC 123 12 1 200 123 12 1 201
1 PC 123 12 1 200 123 12 1 202
1 PC 123 12 1 200 123 12 1 203
2 PC 123 12 1 255 123 12 2 0
2 PC 123 12 1 255 123 12 2 1
2 PC 123 12 1 255 123 12 2 2
3 PC 123 12 255 255 123 13 0 0
3 PC 123 12 255 255 123 13 0 1
3 PC 123 12 255 255 123 13 0 2
4 PC 123 13 0 0 123 13 0 1
4 PC 123 13 0 0 123 13 0 2
4 PC 123 13 0 0 123 13 0 3
5 PC 123 255 255 255 124 0 0 0
5 PC 123 255 255 255 124 0 0 1
5 PC 123 255 255 255 124 0 0 2
Il faut maintenant restreindre ce résultat aux seuls valeurs non déjà présente, par exemple à l'aide de NOT EXISTS :
SELECT MAC_ID, MAC_NOM, MAC_ADRIP1, MAC_ADRIP2, MAC_ADRIP3, MAC_ADRIP4,
MOD(MAC_ADRIP1 + (MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256) / 256) / 256, 256) AS NEW_ADRIP1,
MOD(MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256) / 256, 256) AS NEW_ADRIP2,
MOD(MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256, 256) AS NEW_ADRIP3,
MOD(MAC_ADRIP4 + NUM_I, 256) AS NEW_ADRIP4
FROM T_MACHINE_MAC M1
CROSS JOIN T_NUM N
WHERE NOT EXISTS (SELECT *
FROM T_MACHINE_MAC M2
WHERE M2.MAC_ADRIP1 = MOD(M1.MAC_ADRIP1 + (M1.MAC_ADRIP2 + (M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256) / 256) / 256, 256)
AND M2.MAC_ADRIP2 = MOD(M1.MAC_ADRIP2 + (M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256) / 256, 256)
AND M2.MAC_ADRIP4 = MOD(M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256, 256)
AND M2.MAC_ADRIP4 = MOD(M1.MAC_ADRIP4 + N.NUM_I, 256))
ORDER BY 1, 3, 4, 5, 6 ;MAC_ID MAC_NOM MAC_ADRIP1 MAC_ADRIP2 MAC_ADRIP3 MAC_ADRIP4 NEW_ADRIP1 NEW_ADRIP2 NEW_ADRIP3 NEW_ADRIP4
----------- ---------------- ---------- ---------- ---------- ---------- ----------- ----------- ----------- -----------
1 PC 123 12 1 200 123 12 1 201
1 PC 123 12 1 200 123 12 1 202
1 PC 123 12 1 200 123 12 1 203
2 PC 123 12 1 255 123 12 2 0
2 PC 123 12 1 255 123 12 2 1
2 PC 123 12 1 255 123 12 2 2
3 PC 123 12 255 255 123 13 0 1
3 PC 123 12 255 255 123 13 0 2
4 PC 123 13 0 0 123 13 0 1
4 PC 123 13 0 0 123 13 0 2
4 PC 123 13 0 0 123 13 0 3
5 PC 123 255 255 255 124 0 0 0
5 PC 123 255 255 255 124 0 0 1
5 PC 123 255 255 255 124 0 0 2
Il faut maintenant rechercher parmi ces lignes, celles ayant les poids d'IP les moins forts afin de n'avoir qu'une seule ligne par machine.
Pour cela, nous pouvons ajouter la valeur de l'incrément dans le résultat :
SELECT MAC_ID, MAC_NOM, NUM_I, MAC_ADRIP1, MAC_ADRIP2, MAC_ADRIP3, MAC_ADRIP4,
MOD(MAC_ADRIP1 + (MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256) / 256) / 256, 256) AS NEW_ADRIP1,
MOD(MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256) / 256, 256) AS NEW_ADRIP2,
MOD(MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256, 256) AS NEW_ADRIP3,
MOD(MAC_ADRIP4 + NUM_I, 256) AS NEW_ADRIP4
FROM T_MACHINE_MAC M1
CROSS JOIN T_NUM N
WHERE NOT EXISTS (SELECT *
FROM T_MACHINE_MAC M2
WHERE M2.MAC_ADRIP1 = MOD(M1.MAC_ADRIP1 + (M1.MAC_ADRIP2 + (M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256) / 256) / 256, 256)
AND M2.MAC_ADRIP2 = MOD(M1.MAC_ADRIP2 + (M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256) / 256, 256)
AND M2.MAC_ADRIP4 = MOD(M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256, 256)
AND M2.MAC_ADRIP4 = MOD(M1.MAC_ADRIP4 + N.NUM_I, 256))
ORDER BY 1, 3, 4, 5, 6, 7 ;MAC_ID MAC_NOM NUM_I MAC_ADRIP1 MAC_ADRIP2 MAC_ADRIP3 MAC_ADRIP4 NEW_ADRIP1 NEW_ADRIP2 NEW_ADRIP3 NEW_ADRIP4
----------- ---------------- ----------- ---------- ---------- ---------- ---------- ----------- ----------- ----------- -----------
1 PC 1 123 12 1 200 123 12 1 201
1 PC 2 123 12 1 200 123 12 1 202
1 PC 3 123 12 1 200 123 12 1 203
2 PC 1 123 12 1 255 123 12 2 0
2 PC 2 123 12 1 255 123 12 2 1
2 PC 3 123 12 1 255 123 12 2 2
3 PC 2 123 12 255 255 123 13 0 1
3 PC 3 123 12 255 255 123 13 0 2
4 PC 1 123 13 0 0 123 13 0 1
4 PC 2 123 13 0 0 123 13 0 2
4 PC 3 123 13 0 0 123 13 0 3
5 PC 1 123 255 255 255 124 0 0 0
5 PC 2 123 255 255 255 124 0 0 1
5 PC 3 123 255 255 255 124 0 0 2Dés lors la réponse est données par chaque ligne pour laquelle la valeur de NUM_I est minimum pour chaque MAC_ID, ce qui s'écrit :
SELECT MAC_ID, MAC_NOM, NUM_I, MAC_ADRIP1, MAC_ADRIP2, MAC_ADRIP3, MAC_ADRIP4,
MOD(MAC_ADRIP1 + (MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256) / 256) / 256, 256) AS NEW_ADRIP1,
MOD(MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256) / 256, 256) AS NEW_ADRIP2,
MOD(MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256, 256) AS NEW_ADRIP3,
MOD(MAC_ADRIP4 + NUM_I, 256) AS NEW_ADRIP4
FROM T_MACHINE_MAC M1
CROSS JOIN T_NUM N
WHERE NOT EXISTS (SELECT *
FROM T_MACHINE_MAC M2
WHERE M2.MAC_ADRIP1 = MOD(M1.MAC_ADRIP1 + (M1.MAC_ADRIP2 + (M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256) / 256) / 256, 256)
AND M2.MAC_ADRIP2 = MOD(M1.MAC_ADRIP2 + (M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256) / 256, 256)
AND M2.MAC_ADRIP4 = MOD(M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256, 256)
AND M2.MAC_ADRIP4 = MOD(M1.MAC_ADRIP4 + N.NUM_I, 256))
AND NUM_I = (SELECT MIN(NUM_I)
FROM T_MACHINE_MAC M3
CROSS JOIN T_NUM N2
WHERE NOT EXISTS (SELECT *
FROM T_MACHINE_MAC M4
WHERE M4.MAC_ADRIP1 = MOD(M3.MAC_ADRIP1 + (M3.MAC_ADRIP2 + (M3.MAC_ADRIP3 + (M3.MAC_ADRIP4 + N2.NUM_I) / 256) / 256) / 256, 256)
AND M4.MAC_ADRIP2 = MOD(M3.MAC_ADRIP2 + (M3.MAC_ADRIP3 + (M3.MAC_ADRIP4 + N2.NUM_I) / 256) / 256, 256)
AND M4.MAC_ADRIP4 = MOD(M3.MAC_ADRIP3 + (M3.MAC_ADRIP4 + N2.NUM_I) / 256, 256)
AND M4.MAC_ADRIP4 = MOD(M3.MAC_ADRIP4 + N2.NUM_I, 256))
AND M3.MAC_ID = M1.MAC_ID
GROUP BY M3.MAC_ID )
ORDER BY 1, 4, 5, 6, 7 ;MAC_ID MAC_NOM NUM_I MAC_ADRIP1 MAC_ADRIP2 MAC_ADRIP3 MAC_ADRIP4 NEW_ADRIP1 NEW_ADRIP2 NEW_ADRIP3 NEW_ADRIP4
----------- ---------------- ----------- ---------- ---------- ---------- ---------- ----------- ----------- ----------- -----------
1 PC 1 123 12 1 200 123 12 1 201
2 PC 1 123 12 1 255 123 12 2 0
3 PC 2 123 12 255 255 123 13 0 1
4 PC 1 123 13 0 0 123 13 0 1
5 PC 1 123 255 255 255 124 0 0 0
Cette requête possède encore un dernier petit inconvénient... Essayez donc de voir ce qui se passe si une machine est ajoutée à la table et possède la dernière adresse IP ?
INSERT INTO T_MACHINE_MAC VALUES (6, 'PC', 255, 255, 255, 255) ;
C'est ce que l'on appelle un effet de bord. Comment le résoudre ?
En fait de nombreuses adresses IP sont particulières comme 0, 0, 0, 0 ou 127, 0, 0, 1, ou encore 127, 0, 0, 0 et 255,255,255,255.
Il suffit donc de rajouter à notre modèle de données, une table des adresses IP à éviter, comme ceci :
CREATE TABLE T_BAD_IP_ADRESSE_BIA
(BIA_IP1 SMALLINT NOT NULL CHECK(BIA_IP1 BETWEEN 0 AND 255),
BIA_IP2 SMALLINT NOT NULL CHECK(BIA_IP2 BETWEEN 0 AND 255),
BIA_IP3 SMALLINT NOT NULL CHECK(BIA_IP3 BETWEEN 0 AND 255),
BIA_IP4 SMALLINT NOT NULL CHECK(BIA_IP4 BETWEEN 0 AND 255),
BIA_POURQUOI VARCHAR(256),
CONSTRAINT PK_BIA PRIMARY KEY (BIA_IP1, BIA_IP2, BIA_IP3, BIA_IP4));INSERT INTO T_BAD_IP_ADRESSE_BIA VALUES (0, 0, 0, 0, 'interface réseau générique') ;
INSERT INTO T_BAD_IP_ADRESSE_BIA VALUES (127, 0, 0, 1, 'bouclage') ;
INSERT INTO T_BAD_IP_ADRESSE_BIA VALUES (127, 0, 0, 0, 'locale') ;
INSERT INTO T_BAD_IP_ADRESSE_BIA VALUES (255, 255, 255, 255, 'diffusion') ;La requête prend alors la forme :
SELECT MAC_ID, MAC_NOM, NUM_I, MAC_ADRIP1, MAC_ADRIP2, MAC_ADRIP3, MAC_ADRIP4,
MOD(MAC_ADRIP1 + (MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256) / 256) / 256, 256) AS NEW_ADRIP1,
MOD(MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256) / 256, 256) AS NEW_ADRIP2,
MOD(MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256, 256) AS NEW_ADRIP3,
MOD(MAC_ADRIP4 + NUM_I, 256) AS NEW_ADRIP4
FROM T_MACHINE_MAC M1
CROSS JOIN T_NUM N
WHERE NOT EXISTS (SELECT *
FROM T_MACHINE_MAC M2
WHERE M2.MAC_ADRIP1 = MOD(M1.MAC_ADRIP1 + (M1.MAC_ADRIP2 + (M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256) / 256) / 256, 256)
AND M2.MAC_ADRIP2 = MOD(M1.MAC_ADRIP2 + (M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256) / 256, 256)
AND M2.MAC_ADRIP4 = MOD(M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256, 256)
AND M2.MAC_ADRIP4 = MOD(M1.MAC_ADRIP4 + N.NUM_I, 256))
AND NUM_I = (SELECT MIN(NUM_I)
FROM T_MACHINE_MAC M3
CROSS JOIN T_NUM N2
WHERE NOT EXISTS (SELECT *
FROM T_MACHINE_MAC M4
WHERE M4.MAC_ADRIP1 = MOD(M3.MAC_ADRIP1 + (M3.MAC_ADRIP2 + (M3.MAC_ADRIP3 + (M3.MAC_ADRIP4 + N2.NUM_I) / 256) / 256) / 256, 256)
AND M4.MAC_ADRIP2 = MOD(M3.MAC_ADRIP2 + (M3.MAC_ADRIP3 + (M3.MAC_ADRIP4 + N2.NUM_I) / 256) / 256, 256)
AND M4.MAC_ADRIP4 = MOD(M3.MAC_ADRIP3 + (M3.MAC_ADRIP4 + N2.NUM_I) / 256, 256)
AND M4.MAC_ADRIP4 = MOD(M3.MAC_ADRIP4 + N2.NUM_I, 256))
AND M3.MAC_ID = M1.MAC_ID
GROUP BY M3.MAC_ID )
AND NOT EXISTS(SELECT *
FROM T_BAD_IP_ADRESSE_BIA BAD
WHERE BAD.BIA_IP1 = MOD(M1.MAC_ADRIP1 + (M1.MAC_ADRIP2 + (M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256) / 256) / 256, 256)
AND BAD.BIA_IP2 = MOD(M1.MAC_ADRIP2 + (M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256) / 256, 256)
AND BAD.BIA_IP3 = MOD(M1.MAC_ADRIP3 + (M1.MAC_ADRIP4 + N.NUM_I) / 256, 256)
AND BAD.BIA_IP4 = MOD(M1.MAC_ADRIP4 + N.NUM_I, 256))
ORDER BY 1, 4, 5, 6, 7Voici une requête candidate à être synthétisée par une vue :
CREATE VIEW V_NIP -- pour New IP
AS
SELECT MAC_ID, MAC_NOM, NUM_I, MAC_ADRIP1, MAC_ADRIP2, MAC_ADRIP3, MAC_ADRIP4,
MOD(MAC_ADRIP1 + (MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256) / 256) / 256, 256) AS NEW_ADRIP1,
MOD(MAC_ADRIP2 + (MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256) / 256, 256) AS NEW_ADRIP2,
MOD(MAC_ADRIP3 + (MAC_ADRIP4 + NUM_I) / 256, 256) AS NEW_ADRIP3,
MOD(MAC_ADRIP4 + NUM_I, 256) AS NEW_ADRIP4
FROM T_MACHINE_MAC M1
CROSS JOIN T_NUM NLa requête finale allégée (et notablement plus lisible), s'écrit :
SELECT *
FROM V_NIP AS M1
WHERE NOT EXISTS (SELECT * -- pas dans les adresses déjà attribuées aux machines
FROM T_MACHINE_MAC AS M2
WHERE M2.MAC_ADRIP1 = M1.NEW_ADRIP1
AND M2.MAC_ADRIP2 = M1.NEW_ADRIP2
AND M2.MAC_ADRIP4 = M1.NEW_ADRIP3
AND M2.MAC_ADRIP4 = M1.NEW_ADRIP4)
AND NUM_I = (SELECT MIN(NUM_I) -- recherche du plus petit n° de nouvelle adresse
FROM V_NIP M3
WHERE NOT EXISTS (SELECT *
FROM T_MACHINE_MAC M4
WHERE M4.MAC_ADRIP1 = M3.NEW_ADRIP1
AND M4.MAC_ADRIP2 = M3.NEW_ADRIP2
AND M4.MAC_ADRIP4 = M3.NEW_ADRIP3
AND M4.MAC_ADRIP4 = M3.NEW_ADRIP4)
AND M3.MAC_ID = M1.MAC_ID
GROUP BY M3.MAC_ID )
AND NOT EXISTS(SELECT * -- les nouvelles adresse ne doivent pas être dans les adresses IP interdites
FROM T_BAD_IP_ADRESSE_BIA BAD
WHERE BAD.BIA_IP1 = M1.NEW_ADRIP1
AND BAD.BIA_IP2 = M1.NEW_ADRIP2
id="" AND BAD.BIA_IP3 = M1.NEW_ADRIP3
AND BAD.BIA_IP4 = M1.NEW_ADRIP4)
ORDER BY 1, 4, 5, 6, 7 ;